Real Time Database Synchronization Explained
A complete guide to real time database synchronization. Learn how modern data pipelines work, from core concepts and architectures to business use cases.

Ever seen a live sports scoreboard update the very instant a team scores? That’s the perfect real-world picture of real time database synchronization. It’s all about capturing a change in one database and immediately reflecting that same change across other systems, making sure everyone is looking at the exact same, up-to-the-second information.
Getting to the Core of Instant Data

At its heart, this technology solves a massive business headache: the expensive problems that come from working with stale, outdated data. For years, companies got by with batch processing, where data was bundled up and updated on a schedule—maybe once a day. This created a huge lag between something happening and the business actually knowing about it.
Think about an e-commerce site. If your inventory only syncs overnight, a hot-ticket item might sell out by 10 AM, but your website will happily keep selling it all day long. The result? You get overselling, angry customers, and a logistical mess of canceled orders. Real-time synchronization closes that gap for good.
The Real-World Value of “Right Now”
This isn’t just some behind-the-scenes technical tweak; it’s a completely different way of doing business. When you can react to events the moment they happen, you gain a serious competitive edge. It’s a shift that produces real, measurable results that fuel both growth and efficiency.
Here’s where it really makes a difference:
- A Better Customer Experience: Customers get live order tracking, see accurate stock levels, and receive personalized offers based on what they’re doing right now.
- Smarter Decision-Making: Business leaders can finally look at a dashboard and see what’s happening at this very moment, not what happened yesterday.
- Smoother Operations: Workflows become automated and seamless. A new sale in one system can instantly trigger an update in the CRM without anyone lifting a finger.
- Powerful Real-Time Analytics: This is what powers sophisticated fraud detection, dynamic pricing engines, and other critical tools that simply can’t function on delayed data.
Real-time data isn’t a “nice-to-have” anymore. It’s the new standard for modern business. Companies still running on yesterday’s information are fundamentally out of sync with their customers and the market.
To get a clearer picture, let’s break down the essential characteristics of real-time synchronization.
Key Aspects of Real Time Synchronization
CharacteristicDescriptionBusiness ImpactImmediacyData changes are propagated from the source to the target in milliseconds or seconds.Enables instant reactions to market changes, customer actions, and operational events.ConsistencyAll synchronized systems reflect the same data state, ensuring a single source of truth.Eliminates data conflicts, reduces errors, and builds trust in business intelligence.ReliabilityThe process is built to be fault-tolerant, with mechanisms to handle failures and ensure no data is lost.Guarantees that critical data pipelines remain active, supporting mission-critical apps.ScalabilityThe architecture can handle growing data volumes and an increasing number of data sources and targets.Supports business growth without requiring a complete system overhaul.
These core principles are what make the whole concept so powerful and essential for modern operations.
The demand for this kind of immediate access is exploding. The market for on-premises real-time databases is expected to climb from USD 10.55 billion in 2024 to USD 17.2 billion by 2032, a surge driven by the intense need for low-latency processing and greater data security.
The engine behind all this is a constant, uninterrupted flow of information. To dig deeper into the mechanics, you can explore our guide on real-time data streaming to see exactly how data moves from point A to point B without delay. In the end, it’s all about making sure every part of your organization is operating from a single, consistent, and completely current version of the truth.
How Instant Data Movement Actually Works
To really get a feel for how real time database synchronization is so fast, think about a courtroom. In the old way of doing things, someone would type up a summary of the day’s events hours after the fact. But with a modern, real-time approach, you have a court reporter transcribing every single word the moment it’s spoken.
That’s pretty much the principle behind Change Data Capture (CDC), the engine that drives instant data movement. Instead of waiting for a batch summary, CDC is your database’s live court reporter. It captures every single event—every new order placed, every customer detail updated, every record deleted—the instant it happens.
This technique is a world away from older, clunkier methods. It means all your other systems aren’t just getting periodic updates; they’re getting a continuous, live feed of every change as it occurs at the source.
The Power of Log-Based Change Data Capture
Now, not all CDC methods are created equal. The gold standard for any modern data pipeline is log-based CDC. Just about every production database keeps a transaction log—you might see it called a write-ahead log (WAL) or a binary log (binlog). This log is the database’s own internal, chronological diary of everything that happens.
Log-based CDC works by simply reading this log file. This is a huge deal because it puts zero extra workload on your live, production database. It’s like listening to a broadcast instead of constantly interrupting the speaker to ask, “What did you just say?”
This hands-off approach comes with some major wins:
- Minimal Performance Impact: It won’t slow down your source database, which is absolutely critical for applications handling live user traffic.
- Complete Data Fidelity: It captures everything, including the tricky stuff like deletes and schema changes that older methods often miss entirely.
- Guaranteed Reliability: Because it reads directly from the database’s own source of truth, you can be confident that no data will ever be lost in transit.
This is a stark contrast to older methods like trigger-based CDC, which bolt extra operations onto your database tables for every single change. That can create serious performance overhead and quickly become a bottleneck as your data volume scales. For a closer look at how this works with a specific database, our guide on Change Data Capture for MySQL breaks it all down.
From Batches to Continuous Data Streams
Once CDC captures an event, it doesn’t just sit there. The real magic happens when these individual events are organized into a data stream—a continuous, unending flow of information. It’s the difference between a river that’s always flowing and a series of buckets (batches) that you fill up and empty on a fixed schedule.
This move from batch processing to event streaming is the heart and soul of any real-time architecture.
Treating data changes as a continuous stream of events is the architectural key to unlocking real-time capabilities. It allows systems to react instantly rather than waiting for a scheduled update.
This is what’s known as an event-driven architecture. Each change in your data is treated as a distinct event. For instance, an order_created event can immediately kick off processes in your inventory, shipping, and customer notification systems all at once. The efficiency of this instant data movement often depends on the hardware supporting it; looking into different underlying storage solutions can be crucial for wringing out every last drop of performance.
By pairing CDC with a powerful streaming platform, you can build data pipelines that move information from source to destination with millisecond latency. This is what makes true, real-time synchronization a reality, not just a buzzword.
Comparing Database Synchronization Architectures
Choosing the right path for real-time database synchronization is a big deal, because not all methods are created equal. The architecture you land on will directly shape your system’s reliability, performance, and how well it can grow with you. Let’s break down three common patterns to see how they really stack up.
Before we jump in, it helps to have a good feel for data storage itself. Understanding the fundamental differences between spreadsheets and databases is a great starting point for appreciating why these advanced architectures are so critical for modern applications.
The Fragile Dual-Write Approach
The most obvious concept is the dual-write method. When a piece of data changes, your application code simply writes that update to two (or more) databases at the same time. Easy, right?
Well, not exactly. Think of it like trying to keep two separate paper calendars perfectly in sync. In theory, you just write every appointment in both. But what if the phone rings right after you write in the first one? You now have two different versions of the truth, and you might not even realize it. This is the core flaw of dual-writes—it has no safety net to guarantee both writes succeed, which inevitably leads to data drift and silent failures.
Dual-writes create a brittle system where data integrity is always at risk. A temporary network hiccup or a minor bug can cause your databases to fall out of sync permanently, often without any warning.
While it seems simple on the surface, this approach pushes a ton of complexity and risk into your application logic. It forces your developers to become experts in distributed transactions, a notoriously difficult problem to solve correctly and reliably.
Inefficient Query-Based Polling
Another common technique is query-based synchronization, often just called polling. In this setup, a separate process repeatedly hits the source database, asking, “Anything new since I last checked? How about now?”
This is the technical equivalent of a child on a road trip asking, “Are we there yet?” every five minutes. It’s not just annoying; it puts a continuous, unnecessary load on the source database. Every single query eats up resources, and if you poll too frequently, you can actually slow down the very applications the database is supposed to be supporting.
Plus, this method is never truly real-time. There’s always a gap—the polling interval—between when a change happens and when your system finally notices it. If you shorten that interval to reduce the delay, you just crank up the pressure on the source system. It’s a constant trade-off between freshness and performance.
The Modern Standard: Log-Based CDC
This brings us to the most efficient and reliable architecture out there: log-based Change Data Capture (CDC). Instead of constantly polling the database or forcing applications to write twice, this method reads changes directly from the database’s own internal transaction log.
It’s like subscribing to a notification feed. You don’t have to keep checking for updates because new information is pushed to you the instant it’s available. Since CDC reads from a log file that the database already maintains for its own recovery purposes, it has a minimal performance impact on the source system.
This diagram shows just how simple and non-intrusive log-based CDC really is.
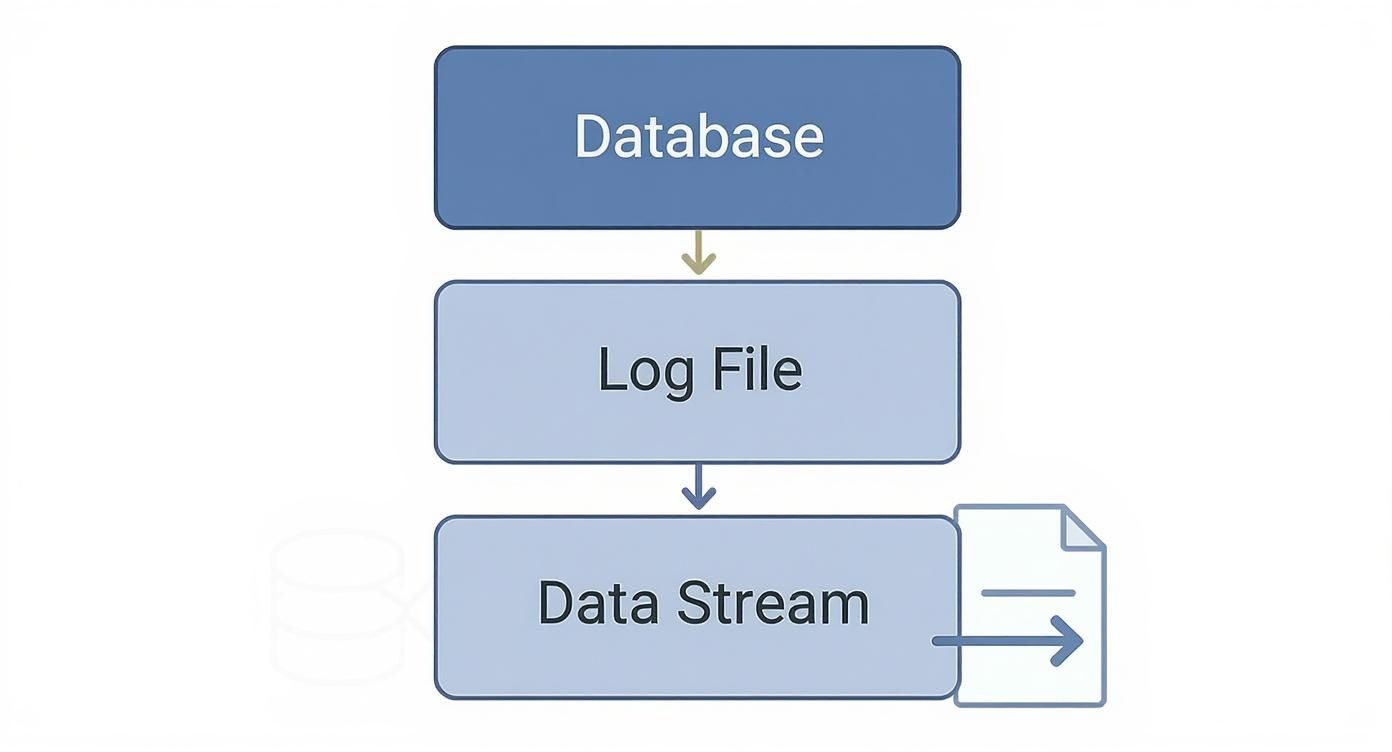
As you can see, the process taps into the log file and turns changes into a data stream without getting in the way of the database’s main job. This clean separation makes the whole system far more robust and scalable. Taking a look at different data pipeline architectures can offer even more insight into building these kinds of resilient systems.
Synchronization Method Comparison
To make the choice crystal clear, this table lays out the key trade-offs between these different approaches. It quickly becomes obvious why modern data teams have standardized on log-based CDC for any serious real-time workload.
ArchitectureHow It WorksProsConsDual-WriteThe application code is responsible for writing data changes to multiple databases simultaneously.Conceptually simple; low latency when it works.Extremely unreliable. Prone to silent data inconsistency if one write fails. Increases application complexity.Query-BasedA separate process repeatedly queries the source database (e.g., using a timestamp column) to look for new or updated rows.Easier to implement than dual-writes; completely decoupled from the application.High latency due to polling interval. Puts a constant, heavy load on the source database, impacting performance.Log-Based CDCTaps into the database’s internal transaction log, reading changes as they are committed and streaming them to consumers.Very low latency (milliseconds). Minimal impact on source system. Guarantees data consistency and no lost events.Can require initial setup for log access and a dedicated CDC platform to manage the stream.
Ultimately, the right choice depends on your specific needs, but the trend is undeniable. While dual-writes and polling might be “good enough” for simple, non-critical tasks, log-based CDC has become the definitive standard for building serious, scalable, and dependable real-time data systems. It delivers the speed businesses demand without compromising the performance and reliability of your most critical databases.
Why Your Business Needs Real-Time Data

It’s one thing to understand the mechanics of real-time database synchronization, but it’s another thing entirely to see what it can actually do for a business. The “why” is pretty straightforward: in a world that moves in an instant, any company running on delayed data is already behind. We’re not talking about small tweaks here; this is about unlocking brand-new capabilities that grow revenue, keep customers happy, and stamp out risk.
Let’s get past the theory and dive into the real-world stories where instant data makes all the difference.
Preventing Stockouts in E-Commerce
Picture this: It’s Black Friday, and a hot-ticket item is flying off your virtual shelves. If your inventory system only syncs up every hour, you might sell thousands of items you don’t actually have. By the time the system catches up, you’re stuck with a customer service disaster—issuing refunds, sending apology emails, and dealing with angry buyers.
Real-time sync completely sidesteps this nightmare.
- Instant Inventory Updates: Every single sale, from any channel, is immediately reflected in the master inventory database.
- Accurate Stock Counts: Your website, app, and internal dashboards all show the exact number of units available, right down to the second.
- Automated “Sold Out” Status: The moment the last item sells, the product page automatically flips to “Sold Out.” No more overselling.
This isn’t just about damage control. It’s about maximizing every sale you can make and building a reputation for being reliable.
Real-time data turns your inventory from a static number into a live, dynamic asset. It ensures you never disappoint a customer by selling them something you don’t actually have.
Detecting Fraud in Financial Services
In finance, speed is everything when it comes to security. A fraudster can rip through an account with dozens of transactions in minutes. If your fraud detection system is looking at data that’s even an hour old, the money is long gone by the time an alert goes off.
This is where real-time synchronization becomes a powerful shield. When transaction data streams from the core banking system to a fraud detection engine in milliseconds, you can spot and stop suspicious activity on the fly.
- Immediate Transaction Blocking: A purchase that fits a known fraudulent pattern can be stopped dead in its tracks, before it even completes.
- Instant Customer Alerts: The bank can instantly send a push notification asking the customer to verify a suspicious purchase the moment it’s attempted.
- Proactive Account Freezing: For serious threats, an account can be temporarily frozen to prevent any further damage, protecting both the customer and the bank.
Powering Personalized User Experiences
Ever wonder how your favorite streaming service knows exactly what to recommend the second you finish an episode? That’s real-time data at work. Your viewing activity is captured and fed into a personalization engine instantly, which then serves up perfectly timed suggestions.
The same magic is happening everywhere. Social media feeds update with live trends, and music apps build playlists that react to what you’re listening to right now. Without real-time data, these experiences would feel clunky, generic, and totally disconnected from your actions.
This demand for immediate, data-driven services is why the global real-time database software market—valued at USD 8 billion in 2024—is expected to explode to USD 20 billion by 2034. You can learn more about this growth by checking out the full market analysis on GlobeNewswire.
Navigating the Inevitable Bumps in the Road
Getting real-time database synchronization right is a game-changer, but let’s be honest—it’s never as simple as flipping a switch. The path is littered with engineering hurdles that can trip up even experienced teams. Knowing what these pitfalls are is the first step to building a data pipeline that’s not just fast, but genuinely resilient.
If you don’t plan for these issues, you’ll end up with a brittle, slow system that can’t keep up as your business expands. These aren’t just minor technical gotchas; they’re major roadblocks that can completely derail your real-time data initiatives if you ignore them.
Keeping Your Data Consistent and Trustworthy
Above all else, your data has to be right. When you’re moving data between systems in the blink of an eye, it’s surprisingly easy for little discrepancies to creep in. Before you know it, your source and target databases are telling two different stories—a problem we often call data drift.
This isn’t just an academic problem. It can poison your analytics, cause automated systems to make bad decisions, and completely destroy any trust your business has in its own data.
The gold standard here is exactly-once processing. This means every single change event is processed one time, and one time only. Anything less introduces chaos—you either lose data (at-most-once) or create duplicates (at-least-once), both of which are terrible for data integrity.
Any serious solution needs to have safeguards built-in to make sure every insert, update, and delete is applied correctly and in the proper sequence, even if the network hiccups or a server goes down.
Don’t Let Your Pipeline Drag Down Production
One of the most insidious problems with data synchronization is the performance hit it can take on your source database. This is usually a production system running a critical application, and the last thing you want is your data pipeline bogging it down for your actual users.
Old-school methods are notorious for this. Query-based polling, for instance, constantly batters the database with “anything new yet?” requests, eating up precious CPU and I/O. Trigger-based approaches tack on extra work to every single write, which can add noticeable lag. A poorly designed sync process can literally bring a production app to its knees. That’s why modern methods like log-based Change Data Capture (CDC) are so popular—they have a minimal impact because they read changes from the database’s transaction log, completely separate from the main workload.
Are You Ready to Scale?
A solution that works perfectly for a thousand transactions an hour might completely melt down when faced with a million. Scalability isn’t something you can bolt on later; you have to plan for it from the get-go. As your company grows, your data volume will too.
Your synchronization architecture has to be built to handle that growth without breaking a sweat. You need to ask a few key questions:
- Throughput: Can the system push through a massive number of events per second without creating a traffic jam?
- Elasticity: How easily can you scale up resources to handle a sudden spike in activity, like during a Black Friday sale?
- Fault Tolerance: If one component fails, does the whole thing stop? Or is there enough redundancy to keep the data flowing?
Handling Schema Changes Without Everything Breaking
Databases evolve. It’s a fact of life. Developers will add new columns, change data types, or rename tables to support new features. This schema evolution is a classic pipeline killer.
Many synchronization tools are rigid and fragile. The moment a table structure changes in the source, the pipeline breaks because the data no longer fits the mold the target expects. This often leads to frantic, late-night manual fixes. A modern platform needs to be smarter, automatically detecting these schema changes and propagating them downstream so the data flow never has to stop.
Modern Tools for Real-Time Data

After wading through the weeds of real-time database synchronization, one thing becomes crystal clear: building a reliable system from the ground up is a massive engineering undertaking. This is precisely where modern, managed Change Data Capture (CDC) platforms like Streamkap come into play. They’re designed to hide all that messy complexity behind a clean, powerful solution that just works.
Instead of your team burning months battling low-level connectors, finicky stream processors, and tricky schema management, a managed platform gives you a ready-made answer. It handles all the heavy lifting behind the scenes, freeing up your engineers to stop wrangling infrastructure and start building products that actually use the real-time data.
The Cornerstones of a Modern Platform
A great platform doesn’t just move data fast; it moves it with the kind of guarantees a business can bank on. The best solutions are built on a few core principles that tackle the common pitfalls we’ve already covered head-on.
These platforms are designed from the ground up to deliver:
- Guaranteed Data Integrity: Using exactly-once processing, every single change from the source database lands in the destination once—and only once. This completely gets rid of the risk of lost data or painful duplicates, ensuring your downstream systems are always accurate.
- Ultra-Low Latency: By tapping directly into database transaction logs, these systems capture and send data in milliseconds. This is what enables truly immediate use cases like fraud detection, live dashboards, and instant customer personalization.
- Effortless Scalability: Built on proven, elastic technologies, modern platforms are ready for enterprise-scale workloads right out of the box. Whether you’re pushing a few thousand events per second or millions, the system just scales without anyone needing to intervene.
A managed CDC platform turns real-time data from a complex engineering headache into a straightforward business tool. You get the reliability and speed of a custom-built system without the overhead, risk, and months of development time.
This is a fundamental shift. It lets your most talented engineers step away from the thankless job of pipeline maintenance and focus on what they do best: innovating and building a competitive edge.
Automation That Actually Helps the Business
Maybe the biggest win with a modern platform is its smart automation. Schema evolution—one of the most common reasons data pipelines break—is handled automatically. When a developer adds a new column to a source table, the platform sees the change and adjusts the target accordingly, all without interrupting the flow of data.
This automatic handling of schema changes, combined with a near-zero performance impact on your source databases, creates a resilient, hands-off data infrastructure. It’s no surprise the market for this technology is taking off. Driven by things like disaster recovery and the need for business continuity, the data real-time replication software market is projected to grow at a compound annual rate of over 15% between 2025 and 2033. You can dig deeper into the factors driving this data replication market growth.
At the end of the day, a modern CDC platform is more than just another tool; it’s a strategic advantage. It finally lets you act on your data the moment it’s created, turning critical information into immediate, valuable outcomes.
Frequently Asked Questions
Still have some questions about real-time database synchronization? Let’s clear up a few of the most common ones. This section tackles the practical differences and implementation details you need to know.
What Is The Difference Between Real Time Synchronization and Batch Processing
The biggest difference boils down to timing. Think of it like this: real-time sync is a live video stream, showing you exactly what’s happening the moment it happens. Batch processing is more like getting a highlight reel at the end of the day.
- Real-time synchronization captures and sends each change as it occurs, working on a continuous flow of events with latency measured in milliseconds.
- Batch processing collects changes over a set period—maybe every hour or once a day—and moves them all at once in a single large load.
Ultimately, real-time gives you a constantly up-to-date view of your data, while batch processing always involves a built-in delay between the event and the insight.
How Does Change Data Capture Impact Source Database Performance
This is a great question, and the answer depends entirely on how you do it. Modern, log-based Change Data Capture (CDC) has a very light footprint, often so small it’s hard to measure. It works by reading the database’s own transaction log, which is a passive, non-intrusive process that doesn’t get in the way of your application’s queries.
On the other hand, older methods can really drag down performance. Trigger-based CDC forces the database to do extra work for every single write operation, while query-based polling hammers the database with constant requests to check for new data. Both can create significant production overhead.
Can You Synchronize Data Between Different Database Types
Yes, and this is one of the most powerful reasons to use real-time database synchronization in the first place. You’re not locked into one technology. This ability to replicate data between different systems is known as heterogeneous data replication.
For example, you can easily capture every change from an operational database like PostgreSQL and stream those events to a completely different kind of platform. Some popular scenarios include:
- Cloud Data Warehouses: Keeping analytical platforms like Snowflake or BigQuery fed with fresh data for up-to-the-minute dashboards.
- Search Indexes: Instantly updating search tools like Elasticsearch to reflect new products or content.
- Caching Layers: Ensuring a cache like Redis always has the latest information, preventing stale data from reaching users.
This kind of flexibility lets you build smarter, more responsive systems where every component is working with the most current data available, no matter its format or location.
Ready to eliminate data delays and unlock the power of real-time insights? Streamkap provides a modern, managed CDC platform that simplifies real-time database synchronization, allowing you to build reliable, low-latency pipelines in minutes, not months. Start streaming your data today.
Related resources
Kafka Consumer Lag: Causes, Debugging, and Fixes
Consumer lag is the most common Kafka operational issue. Learn what causes it, how to measure it, and practical strategies to bring it under control.
Kafka on Kubernetes: Real-World Lessons
Running Kafka on Kubernetes sounds like a good idea until you hit storage, networking, and operational challenges. Here's what teams learn the hard way and how to avoid the common pitfalls.
Backpressure in Stream Processing: What It Is and How to Handle It
Learn what backpressure means in streaming pipelines, how to detect it, and practical strategies for handling it in Kafka, Flink, and CDC pipelines without losing data.