A Practical Guide to Real Time Data Streaming


October 2, 2025
In the world of data, timing is everything. Real-time data streaming is all about processing and analyzing information the very moment it’s created, giving businesses the power to react in milliseconds instead of hours. It’s the difference between watching an event unfold live versus reading about it in tomorrow's newspaper.
The Critical Shift to Instant Data

For a long time, the standard approach was batch processing. Think of it like getting your mail delivered once a day—you get a big bundle of information, but it's already hours, if not a full day, old. By the time you act on it, the moment has likely passed.
Real-time data streaming flips that model on its head. It’s less like daily mail and more like a live, continuous conversation. Data flows in an unending stream, letting you analyze and respond to events as they happen. This isn’t just a small technical tweak; it’s a fundamental shift in how businesses operate.
Why Immediate Action Matters
In so many industries, the value of data is incredibly time-sensitive. A slight delay can mean a lost sale, a preventable security breach, or a massive logistical snarl. Just think about these real-world scenarios:
- E-commerce: When a customer abandons their shopping cart, that’s a critical moment. Real-time streaming can trigger an immediate discount offer or a personalized reminder to try and win back the sale right then and there.
- Finance: Spotting a fraudulent credit card transaction has to happen in the blink of an eye. Streaming analytics can flag a suspicious pattern and block the transaction before any money is lost.
- Logistics: A delivery truck’s route needs to change on a dime based on live traffic data. Real-time updates help drivers avoid jams, saving precious time and fuel.
This urgent need for instant insight is fueling explosive market growth. The global streaming analytics market was valued at $27.84 billion in 2024 and is on track to hit a staggering $176.29 billion by 2032. This incredible expansion is all thanks to organizations figuring out how to squeeze every drop of value from their live data.
Making the move from delayed analysis to immediate action is a massive competitive advantage. To get there, you first have to grasp the core differences in approach. For a deeper look, check out our comparison of batch processing vs. real time stream processing.
Building Your Foundation in Data Streaming
To really get a feel for real time data streaming, we need to move past the buzzwords and look at what makes it tick. Forget thinking about data as a static lake you dip into every now and then. A much better analogy is a constantly flowing river.
This river is made up of an endless series of small, individual pieces of information called events.
An event is just a record of something that happened. A click on a website, a temperature reading from an IoT sensor, a stock trade, a location update from a delivery truck—each one is a tiny snapshot of an action. In a streaming system, these events are created by producers and read by consumers.
- Producers: These are simply the sources of your data. Think of a mobile app sending usage logs, a server logging an error, or an e-commerce platform recording a new sale. They publish events into the stream the moment they happen.
- Consumers: On the other end, you have the applications that need to do something with that data. A fraud detection system, a real-time analytics dashboard, or a recommendation engine are all consumers. They subscribe to the stream and react to events as they arrive.
Connecting these two is the all-important middleman: the broker. The broker, often a platform like Apache Kafka, is basically a high-speed, durable messaging system. It takes in massive volumes of events from all the producers and makes them available to consumers, making sure nothing gets lost along the way.
Core Streaming Architectures
As engineers started building systems around this constant flow of data, two main architectural patterns took shape: Lambda and Kappa. Grasping the philosophy behind each one is key to understanding how modern data pipelines are put together.
The Lambda Architecture was one of the first popular models. It was designed to handle both real-time queries and deep historical analysis by running two data paths at the same time:
- A Speed Layer: This path processes data as it arrives to provide immediate, up-to-the-second views. These results are fast, but sometimes only approximate.
- A Batch Layer: This path processes all data in large, comprehensive batches to create the "source of truth"—highly accurate, historical records.
The results from both layers are then stitched together to give users a complete picture. It works, but as you can imagine, maintaining two separate systems for the same data can get complicated and expensive.
The Kappa Architecture came along and simplified things dramatically. Its core idea is that you can handle everything—real-time processing, historical analysis, and everything in between—with a single, unified streaming pipeline. It argues that batch processing is just a special case of stream processing.
The Unified Philosophy of Kappa
The Kappa Architecture is built on the belief that a well-designed streaming system is all you need. If you ever have to recalculate historical data, you don't need a separate batch system. You just replay the entire stream of events from the beginning through your current processing logic.
This unified approach has largely become the standard for modern real time data streaming because it slashes complexity and operational overhead. Of course, to handle the constant influx of data in either architecture, you need a solid strategy for managing all your different sources. Learning key tactics for efficient financial data integration can help you build a far more robust system.
Now that we've laid this groundwork—from the roles of producers and consumers to the architectural elegance of Kappa—we can start digging into how to choose the right tools and strategies for your own projects.
Choosing the Right Data Streaming Architecture
Picking the right architecture for a real-time data streaming project is a make-or-break decision. It’s not just about chasing the lowest latency; it’s about striking the right balance between speed, data consistency, and the operational headaches you’re willing to take on. You wouldn't use a Formula 1 car to grab groceries, and the same logic applies here—your architecture has to fit the job.
The choice really boils down to three core approaches: the old-school batch processing, the hybrid micro-batching, and the lightning-fast true real-time stream processing. Each one operates on a different clock, and each comes with its own set of trade-offs.
Batch Processing: The Foundation
Batch processing is the original, straightforward method. It’s all about collecting data over a set period—maybe an hour, maybe a full day—and then running one massive job to process everything at once. Think of it like doing payroll at the end of the month. All the timesheets are gathered up and processed together in a single, scheduled run.
This approach is fantastic when you care more about raw throughput than immediate results. It’s the go-to for things like end-of-day financial reporting, customer billing systems, or large-scale data archiving where nobody is waiting for an instant answer. The obvious downside? The built-in delay makes it a non-starter for anything that requires a quick reaction.
Micro-Batch Processing: A Hybrid Approach
Micro-batching splits the difference. Instead of processing data in huge, infrequent chunks, it handles data in tiny, frequent batches—often every few seconds or minutes. It’s clever because it creates the illusion of real-time processing while hanging onto the efficiencies that make batch jobs so reliable.
This is a really popular choice for near-real-time analytics dashboards or monitoring systems where a few seconds of lag is no big deal. For example, a marketing dashboard that refreshes its KPIs every minute is a perfect use case. You get timely insights without diving into the deep end of architectural complexity that true stream processing demands.
True Real-Time Stream Processing: For Instant Insight
This is where things get serious. True real-time data streaming doesn't bother with batches at all, big or small. It processes every single data event the instant it arrives. This event-by-event approach delivers the lowest possible latency, often measured in mere milliseconds.
For some use cases, this is the only way to go. Immediate action is non-negotiable.
- Algorithmic Trading: Financial platforms have to react to market shifts in sub-second timeframes to execute profitable trades.
- Fraud Detection: When someone swipes a credit card, the payment system has to approve or deny the transaction right then and there based on a real-time risk score.
- IoT Sensor Monitoring: A factory floor can't wait for a batch report to know a critical machine is overheating; it needs an instant alert.
These scenarios demand an architecture built from the ground up to ingest, process, and act on data with virtually zero delay.
This chart gives you a sense of what a well-oiled streaming pipeline can achieve.
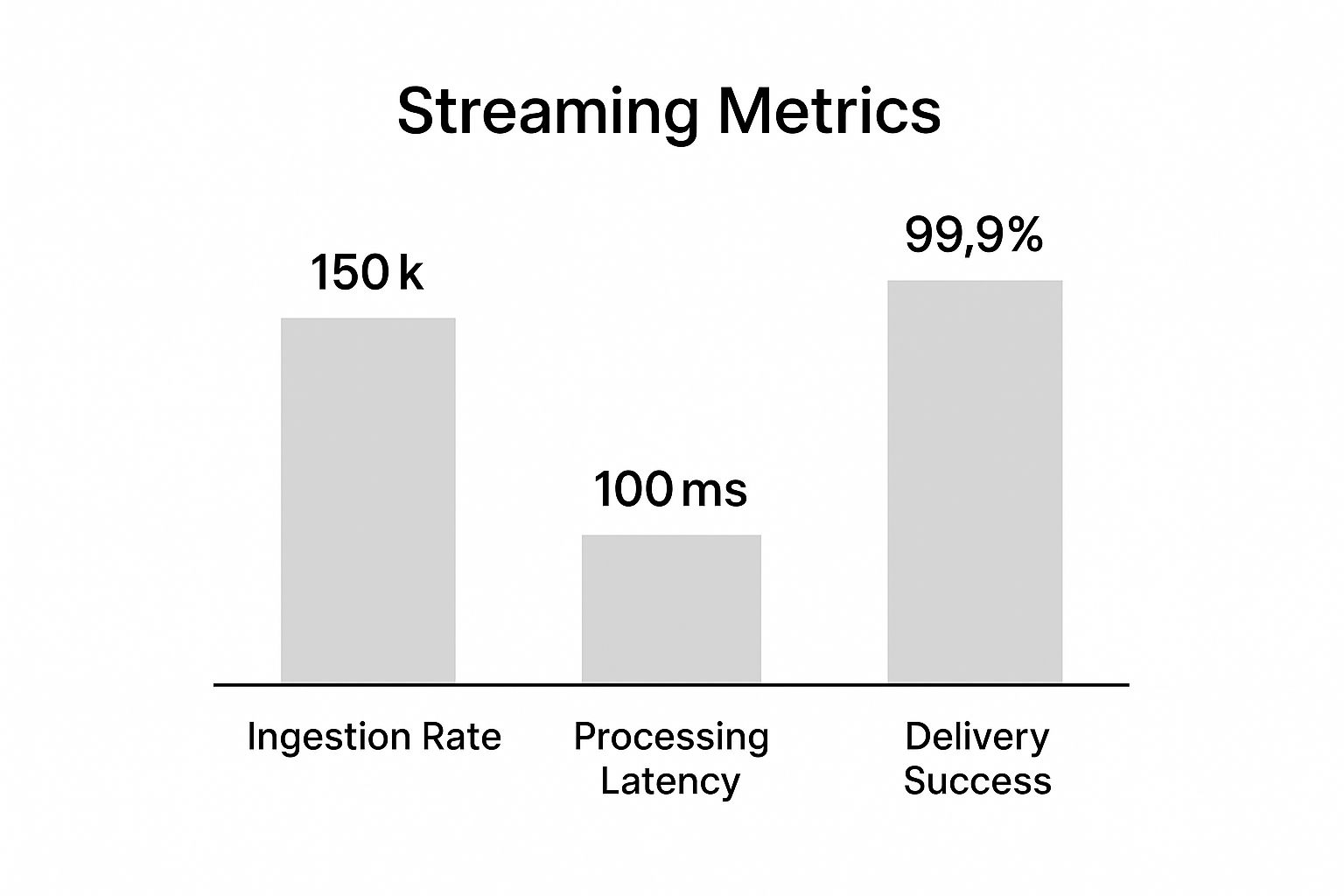
Hitting massive ingestion rates and near-perfect delivery while keeping latency under a second is really the gold standard for an effective real-time system.
The architectural patterns that make this possible, like Lambda and Kappa, provide the blueprints for these powerful systems. While Lambda famously splits data into separate batch and speed layers, the more modern Kappa architecture unifies everything into a single, elegant streaming pipeline.
For a lot of companies, moving from Lambda to Kappa is a huge step toward making their data infrastructure simpler and more efficient. To really get a handle on this trend, check out our guide on the evolution from Lambda to Kappa architecture. It neatly explains the industry-wide shift toward using pure streaming for both immediate and historical analysis.
To help you decide which path is right for you, this table breaks down the key differences between the architectures.
Comparison of Data Processing Architectures
Ultimately, choosing the right architecture comes back to knowing what your business actually needs. Once you're clear on your requirements for latency, data volume, and what your team can support, you can build a system that gets the right information to the right people at the right speed.
Unlocking Databases with Change Data Capture

So much of a company's most critical data is tucked away in operational databases like Postgres, MySQL, and SQL Server. The problem? Getting that data out for real-time analysis has always been a headache. Historically, engineers had to rely on slow, clunky methods that hammered production systems, making true real-time streaming feel more like a dream than a reality.
This is where a brilliant technique called Change Data Capture (CDC) completely changes the game. It’s the key to turning your traditional database into a live, flowing stream of data.
To see why CDC is so powerful, let's look at the old way of doing things: query-based polling. Imagine you need to keep a backup of a massive encyclopedia perfectly in sync. The polling method is like photocopying the entire encyclopedia every single night. You’d then have to spend hours comparing the new copy to yesterday's, just to find the handful of new or changed entries.
It’s slow, incredibly wasteful, and you’d never know if an entry was added and then removed between your nightly checks. This is exactly how older data pipelines work, constantly hitting the database with queries like SELECT * FROM users WHERE last_updated > ?. This puts a heavy, relentless load on the very system you need to keep running smoothly for your actual application. Worse yet, it almost always misses deletions.
A Smarter Way: Log-Based CDC
Instead of brute-forcing the problem, Change Data Capture offers a far more elegant solution. It taps directly into the database’s own internal diary: the transaction log.
Think of this log as the database's private journal. Every single thing that happens—every INSERT, UPDATE, and DELETE—is written down in this log the moment it occurs. This is how the database ensures its own integrity and consistency.
Log-based CDC simply reads this journal. It doesn't interrogate the database over and over again. It just listens, passively observing the log and streaming each event out as it’s written. The impact on the database is almost zero because it's not doing any extra work.
The advantages are huge:
- Minimal Performance Hit: Because it avoids running expensive queries, your production database is free to focus on its real job: serving your application.
- Captures Every Change: Unlike polling, log-based CDC sees everything, including the crucial
DELETEoperations that are so often missed. You get a complete, accurate history. - Guaranteed Data Integrity: By reading events in the exact order they were committed, CDC ensures the data stream is a perfect, sequential replica of what happened in the database.
By tapping into the transaction log, CDC fundamentally transforms a database. It shifts from being a static system you have to repeatedly poll for updates into a live source of events, ready to power a modern, event-driven world.
Putting CDC into Practice
This is precisely the approach modern data platforms like Streamkap take. We use log-based CDC to connect to sources like Postgres or MySQL, streaming every single change into a processing engine like Apache Flink and a message broker like Apache Kafka.
This setup makes it possible to feed real-time analytics dashboards, populate data warehouses, or power other applications with an up-to-the-millisecond view of your data—all done with incredible efficiency.
For anyone building modern data pipelines, getting a handle on this technology is a must. To go deeper, check out our complete guide on Change Data Capture for Streaming ETL. Making the switch from slow batch jobs to low-impact, log-based streaming is the foundation for any company that's serious about using fresh, live data to make decisions.
How Data Streaming Powers Modern Business

It's one thing to understand the architecture and tech behind real-time data streaming, but it’s another to see it in the wild. The ability to process data the instant it’s created isn't just a neat technical trick; it's a genuine business advantage that opens up new revenue, builds better customer experiences, and stops costly failures in their tracks.
Let's look at how different industries are actually putting these concepts to work, turning what sounds like abstract data flows into tangible, bottom-line results. Each of these examples solves a very real business problem by leaning into the speed of streaming data.
Financial Services and Instant Fraud Detection
The world of finance moves in milliseconds, and fraud detection is the perfect example. For a credit card company, the window to catch a bogus transaction is razor-thin—literally the few seconds it takes a payment terminal to say "approved" or "declined." Batch processing is useless here; by the time a nightly report runs, the money is already gone.
The Challenge: A global bank was struggling to identify and block fraudulent transactions in real time across millions of daily purchases. They needed a system that could analyze spending patterns, locations, and merchant data on the fly to flag a transaction before it went through.
The Streaming Solution: They set up a pipeline using Change Data Capture (CDC) to stream transaction data directly from their core banking databases. This live feed was funneled into a processing engine that instantly compared each new event against historical customer behavior and known fraud patterns. If a transaction looked suspicious, an automated alert would block the payment and notify the customer—all in about 200 milliseconds.
The Result: The bank cut its fraudulent losses by over 60% in the first year alone. Just as importantly, customer trust soared because people knew the bank was actively protecting them from unauthorized charges.
E-commerce and Dynamic Personalization
For any online retailer, personalization is the name of the game. Showing a customer the right product at the right time is often the difference between making a sale and watching them bounce. Static, generic recommendations based on old data just don't cut it anymore. Today's e-commerce leaders need to adapt to a customer's behavior as it's happening.
The Challenge: A major e-commerce platform wanted to graduate from basic recommendations. Their goal was to update product suggestions on their homepage and in search results based on what a user was clicking on during their current session.
The Streaming Solution: They built a system that captured every single click, view, and "add to cart" action as an individual event. This constant stream of user activity was processed in real time to update that specific user's profile. A machine learning model, fed by this live data, could then generate fresh, hyper-relevant product recommendations on the spot.
The Result: The company saw a 15% jump in conversion rates and a 25% increase in average order value from customers who interacted with the real-time suggestions.
This is where platforms like Streamkap come in. They provide the connective tissue for these kinds of systems, letting data flow effortlessly from sources like databases to the applications that need it. The screenshot above gives you a sense of how engineers can manage these complex pipelines, connecting a source like Postgres to a destination like Snowflake with just a few clicks.
Logistics and On-The-Fly Route Optimization
In logistics, efficiency is everything. A single traffic jam or an unexpected road closure can create a ripple effect, causing delays and driving up fuel costs. Simply planning routes in the morning and hoping for the best is a recipe for inefficiency; companies need to react to what's happening on the ground, right now.
The Challenge: A national delivery service needed to slash fuel consumption and improve its on-time delivery record. The plan was to dynamically adjust driver routes based on live traffic, weather, and last-minute pickup requests.
The Streaming Solution: They outfitted their entire fleet with GPS trackers that streamed location data every few seconds. This data was then combined with live feeds from traffic APIs and weather services. A central routing engine processed this constant flow of information, automatically pushing optimized routes to drivers' in-cab devices to help them sidestep delays before they even hit them.
The impact of real-time data delivery goes far beyond these examples. Just look at the global video streaming market, which was valued at $129.26 billion in 2024 and is projected to hit $416.8 billion by 2030. This incredible growth is fueled by our demand for live content, from sports to news, all of which is powered by streaming data technology. You can find more on the impact on the global market and what's driving this trend.
Picking Your Real-Time Streaming Platform
Choosing the right platform for real-time data streaming is a huge decision. It really boils down to a classic dilemma: do you want total technical control or do you prefer operational simplicity? On one side, you have incredibly powerful, open-source tools like Apache Kafka and Flink that give you endless flexibility. On the other, you have managed platforms like Streamkap that offer a clean, end-to-end solution to get you up and running in a fraction of the time.
This is the age-old "build versus buy" debate. Building your own custom pipeline gives your team complete control over every single component. But—and it's a big but—it requires a massive investment in engineering resources to not only build it but also to scale and maintain it over time. A managed service handles all that heavy lifting for you, letting your team focus on what the data actually means for the business, not on managing the infrastructure behind it.
What to Look For in a Platform
Before you sign on the dotted line, you need to vet any potential solution against a few core principles. While your specific use case will have its own unique demands, any solid streaming platform has to deliver on these key areas:
- Scalability: What happens when your data volume suddenly triples? The platform needs to handle those spikes without breaking a sweat. Look for systems built for horizontal scaling so you're not painted into a corner when you grow.
- Latency: How fast does data get from point A to point B? For anything that's genuinely real-time, you should be thinking in milliseconds, not seconds.
- Connector Availability: Does the platform already have reliable, pre-built connectors for your tech stack? Think sources like Postgres or MySQL and destinations like Snowflake or BigQuery. Building these from scratch is a major headache.
- Fault Tolerance: If a piece of the system goes down, what happens? A resilient platform ensures you don't lose a single byte of data and can keep processing without someone having to jump in and fix things manually.
- Ease of Use: How quickly can your team actually start using it? A platform with an intuitive interface and features like automated schema handling can save you countless hours in setup and ongoing maintenance.
Going through this checklist helps you figure out if the deep-level control of a custom-built system is truly necessary, or if the speed and reliability of a managed platform make more sense for your goals.
You can see the real-world impact of streaming everywhere. Just look at the live streaming industry—it's become a global giant valued at around $100 billion in 2024 and is expected to hit $345 billion by 2030. That kind of growth shows just how much businesses value getting information delivered instantly. You can check out more stats on the rise of live streaming at Teleprompter.com.
For most companies, the main objective is to get value from real-time data without having to become infrastructure gurus. A managed platform gets you to that value much faster, lowers your total cost of ownership, and frees up your best engineers to work on projects that actually make the company money. It's a strategic choice that lets you build the powerful data pipelines you need, all while staying within your team's technical capacity and budget.
Got Questions? We've Got Answers
Even after covering the basics, it's natural to have a few lingering questions about real-time data streaming. Let's tackle some of the most common ones that come up.
How Is Real-Time Streaming Different From ETL?
The biggest difference boils down to timing and batch size. Think of traditional ETL (Extract, Transform, Load) like a nightly delivery truck—it shows up at a scheduled time, drops off a huge shipment of data, and leaves. It's designed for massive, periodic updates when "yesterday's data" is good enough.
Real-time streaming, on the other hand, is like a constant conveyor belt. Data flows continuously, piece by piece, the moment it's created. This is crucial for anything that needs an immediate response, from fraud detection alerts to updating a live inventory dashboard.
What Does Change Data Capture (CDC) Actually Do for Streaming?
Change Data Capture (CDC) is what makes modern data streaming so powerful and efficient. Instead of constantly hammering your database with queries to ask "what's new?", CDC quietly listens to the database's internal transaction log—the same log the database uses to keep itself consistent.
By tapping into the transaction log, CDC can capture every single insert, update, and delete in the correct sequence, without bogging down the source system. It effectively turns your traditional, static database into a live-fire hose of events, making even legacy systems ready for a real-time world.
Should I Build My Own Streaming System or Use a Managed Service?
This is the classic "build vs. buy" debate, and it really comes down to what your team is built for.
- Building it Yourself: Going the DIY route with open-source tools like Apache Kafka and Flink gives you ultimate control. But be prepared—you're signing up for a massive engineering project that involves development, constant maintenance, scaling, and troubleshooting.
- Buying a Managed Platform: A managed service handles all that heavy lifting for you. It provides the connectors, the scalable infrastructure, and the reliability right out of the box, so you can plug in your sources and start streaming.
Honestly, for most teams, a managed platform is the faster, smarter, and more cost-effective choice. It lets your engineers focus on creating value from the data, not on becoming full-time infrastructure plumbers. You get to market faster and often end up with a lower total cost of ownership.
Ready to build powerful, efficient data pipelines without the operational headache? With Streamkap, you can use log-based CDC to turn your databases into real-time streams in minutes, not months. See how our managed platform can simplify your data streaming at https://streamkap.com.

