How to Improve Data Quality: A Practical Guide to Clean, Trusted Data
Discover how to improve data quality with a practical, step-by-step guide to assessment, cleansing, and governance that builds trust in your data.
Improving your data quality isn’t a one-and-done project. It’s a deliberate cycle: you have to assess where you are, remediate what’s broken, operationalize your fixes for the long haul, and establish governance to keep standards high. This turns quality management from a reactive headache into a proactive, strategic advantage that fuels reliable business decisions.
Why Data Quality Is Your Most Valuable Asset
Let’s be blunt—poor data quality is the silent killer of strategic initiatives. It undermines business intelligence, poisons AI models, and quietly drains resources. It’s the reason why so many promising data projects end up as frustrating, expensive dead ends. This isn’t just a technical problem; it’s a fundamental business challenge that hits the bottom line hard.
The issue is everywhere, and it’s not getting better. Data quality is still the number one challenge impacting data integrity, with a staggering 64% of organizations calling it their primary concern. This has shattered confidence across the board; 67% of leaders now admit they don’t fully trust their data for making critical decisions.
To fix this, we need a shift in mindset. Data quality isn’t about chasing some mythical, “perfect” dataset. It’s about making data fit for purpose. Is it reliable enough for your executive dashboards? Is it accurate enough to train a trustworthy AI? Is it consistent enough to keep operations running smoothly?
A Framework for Lasting Improvement
The only way to win is with a continuous cycle, not a one-time cleanup job. This process breaks down into four core stages that build on each other to improve and maintain data quality over time.
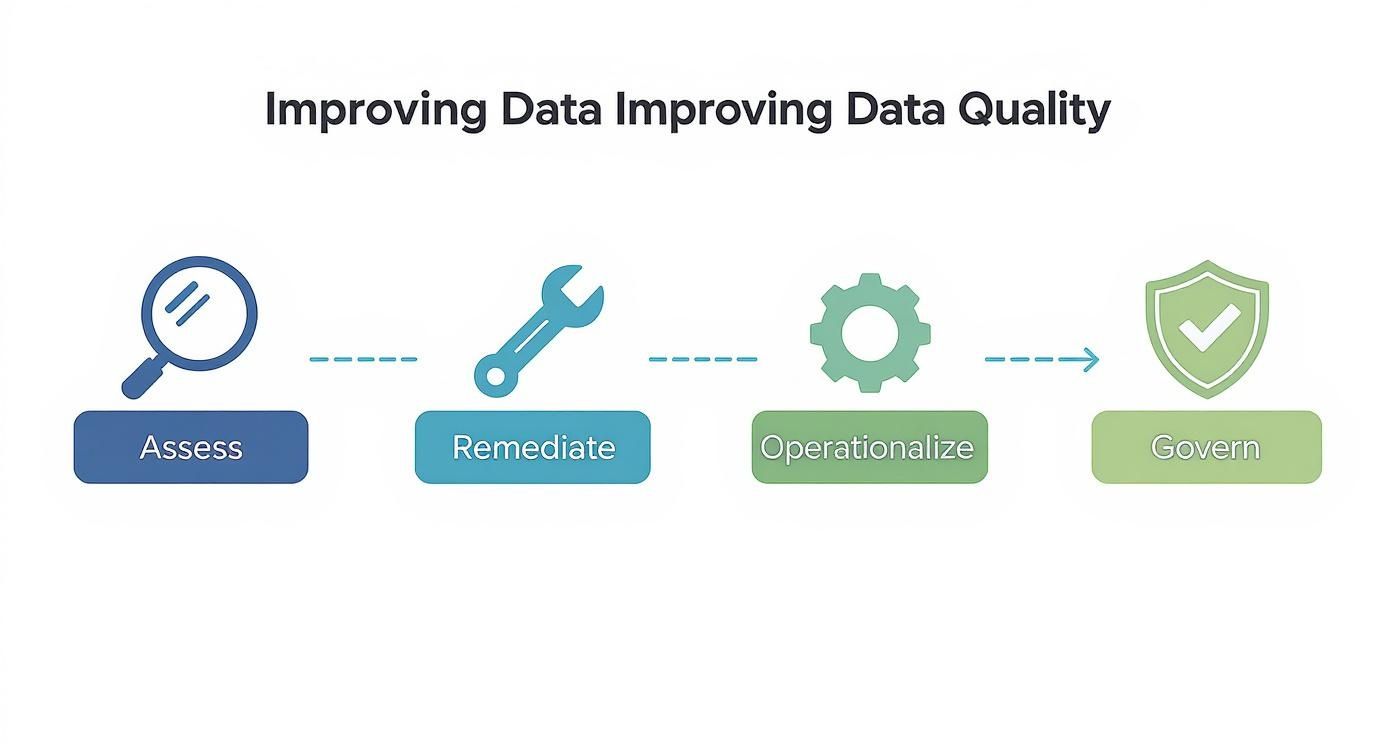
It all starts with a thorough assessment, which then guides remediation. From there, you operationalize the solutions and wrap it all in a governance framework, creating a feedback loop that drives continuous improvement.
The Real-World Impact of Poor Data
Talking about data quality can feel abstract, but the consequences are very real. When you ignore the core dimensions of quality, you create tangible business problems that hurt everything from customer relationships to financial reporting. For instance, the high stakes involved in fixing data quality in healthcare show just how critical it is for improving patient safety and streamlining operations.
“Bad data is often worse than no data at all. It gives you the confidence to make poor decisions, creating a ripple effect of errors that can take months or even years to unwind.”
To make this crystal clear, let’s break down the six critical dimensions of data quality. The table below shows what each one means and the tangible business risks you face when it’s neglected. This is why investing in data quality isn’t just an IT task—it’s a core business necessity.
The Six Dimensions of Data Quality and Their Business Impact
Data Quality DimensionDescriptionImpact of Poor QualityAccuracyDoes the data correctly reflect the real-world object or event?Inaccurate customer addresses lead to failed deliveries. Flawed financial data causes compliance failures and bad forecasts.CompletenessAre there any missing values or data gaps?Incomplete customer profiles prevent effective marketing personalization. Missing sales data skews performance reports.ConsistencyIs data uniform across all systems? For example, is “USA” always “USA” and not “United States” or “US”?Inconsistent product names create duplicate SKUs and inventory chaos. Contradictory customer data leads to a fragmented view.TimelinessIs the data available when it’s needed?Stale inventory data results in stockouts or overstocking. Delayed fraud alerts allow more fraudulent transactions to occur.UniquenessAre there any duplicate records for the same entity?Duplicate customer records lead to sending multiple marketing emails, wasting resources and annoying customers.ValidityDoes the data conform to a specific format or rule (e.g., email format, date format)?Invalid email formats make marketing campaigns bounce. Incorrectly formatted phone numbers break down sales outreach efforts.
Understanding these dimensions is the first step. When you can pinpoint exactly where your data is falling short, you can start building a targeted plan to fix it.
Diagnosing Your Current Data Health
You can’t fix a problem you don’t fully understand. Before you even think about cleansing data or applying fixes, you need to conduct a thorough health check. It’s about diagnosing precisely where and why your data quality is suffering. This goes way beyond just running a query for null values; it’s time to become a data detective and uncover the hidden symptoms pointing to larger, systemic issues.
The first step on this journey is data profiling. Think of it as a comprehensive medical exam for your datasets. Profiling dives deep into the statistical and structural characteristics of your data, giving you a solid baseline of its current state. It helps you answer the fundamental questions that will guide your entire quality improvement effort.
Uncovering Hidden Patterns With Data Profiling
Effective data profiling is all about systematically examining your data to spot anomalies that aren’t immediately obvious. You’re looking for patterns—or a lack thereof—that signal trouble.
For your most critical data columns, start by analyzing the basics:
- Value Frequencies: How often does each value appear? A high frequency of “Unknown” or “N/A” in a field that’s supposed to be required is a massive red flag.
- Statistical Summaries: For numeric fields, what are the min, max, mean, and standard deviation? An “age” field with a maximum value of 200 instantly tells you something is deeply wrong.
- Format Consistency: Do all values in a column stick to the expected format? A
customer_idcolumn shouldn’t be a mix of integers, UUIDs, and email addresses. - Null Value Analysis: What percentage of values are null? Even more important, is there a correlation between nulls in one column and specific values in another?
This process almost always turns up surprising insights. For instance, you might discover a state field containing both “CA” and “California”—a classic consistency issue. Or maybe a sudden spike in nulls for a transaction_amount field lines up perfectly with a recent software update, pointing you directly toward a potential bug.
Performing A Root-Cause Analysis
Once profiling has revealed what is wrong, the next critical step is to understand why. This is where you conduct a root-cause analysis, tracing the data quality issue all the way back to its origin. If you skip this, any fixes you apply will just be temporary patches on a problem that’s guaranteed to return.
Tracing a data problem to its source is the difference between perpetually cleaning up messes and preventing them from happening in the first place. The goal is to fix the leaky pipe, not just keep mopping the floor.
Common culprits usually fall into a few key categories. A flawed data entry form on your website might be missing proper validation, allowing users to enter phone numbers with letters. An overnight ETL job could be failing silently, leading to incomplete data loads that completely skew your morning reports. Or perhaps a third-party API you depend on changed its schema without warning, causing your data pipeline to misinterpret everything coming in. Investigating these sources is essential for resolving the many data integrity problems that can silently corrupt your systems.
To guide your investigation, start asking targeted questions to zero in on the source:
- Origin Point: Where does this data first enter our ecosystem? Is it a user-facing app, a batch file upload, or a real-time stream?
- Transformations: What logic gets applied to the data after it arrives? Could a transformation be incorrectly handling certain edge cases or data types?
- System Changes: Have there been any recent deployments, schema changes, or infrastructure updates that coincide with when the issue started appearing?
- Human Factor: Is manual data entry involved? If it is, are the guidelines clear, and is there enough training to prevent common mistakes?
By systematically working through these questions, you stop just observing symptoms and start diagnosing the underlying disease. This diagnosis is the essential first step before you can prescribe an effective, long-lasting cure.
Getting Your Hands Dirty: Practical Data Remediation Techniques
Once you’ve diagnosed your data health problems, it’s time to roll up your sleeves and start fixing them. This is the remediation phase—moving from just looking at reports to actively correcting the issues you found. This isn’t about running a few generic scripts and hoping for the best; it’s a targeted effort to repair, standardize, and ultimately boost the value of your data.
Think of it like a mechanic’s toolkit. You wouldn’t use a sledgehammer to fix a delicate sensor, and you can’t apply a single, brute-force solution to every data quality problem. Each issue, from messy formatting to missing values, needs its own specific tool.
Data Cleansing and Standardization
The most common starting point for any remediation effort is data cleansing, often called data scrubbing. This is the nitty-gritty work of finding and fixing corrupt, inaccurate, or incomplete records. It almost always goes hand-in-hand with standardization, which is just a fancy way of saying you’re forcing data to follow a consistent format everywhere.
We’ve all seen this problem in the wild. Your company pulls customer data from three different places—the CRM, the e-commerce platform, and the marketing tool. You end up with a mess of addresses that all point to the same place:
- System 1:
123 Main St, Anytown, CA, 90210 - System 2:
123 Main Street, Anytown, California, 90210 - System 3:
123 Main st., an_town, ca
This kind of inconsistency is a silent killer. It leads to failed package deliveries, wasted marketing dollars, and a completely fractured view of your customer. A solid cleansing process would parse and standardize all these variations into one clean, reliable format, like 123 Main Street, Anytown, CA 90210. Problem solved, and now the data is actually trustworthy.
An ounce of prevention is worth a pound of cure, and that’s especially true for data. Fixing an error at the point of entry is trivial. Cleaning up thousands of corrupted records downstream can burn weeks of engineering time.
Implementing Data Validation Rules
While cleansing fixes the mistakes of the past, data validation stops new ones from happening in the first place. Think of it as putting a bouncer at the door of your database. Validation rules check incoming data before it gets written, ensuring it meets the standards you’ve set.
For example, when a new user signs up on your website, you can set up simple but powerful rules to:
- Verify Email Format: Check for an ”@” symbol and a plausible domain. No more
test@test. - Check Phone Number Structure: Enforce a specific numeric format and length. This kills entries like “N/A” or “123-abc-4567”.
- Enforce Required Fields: Simply don’t let the form submit if a critical piece of information, like a last name or consent checkbox, is missing.
By building these checks into your forms, APIs, and ingestion pipelines, you drastically cut down on the amount of junk data your team has to deal with later. It’s a classic “shift-left” strategy that embeds quality right into your day-to-day operations.
Enriching Data for Deeper Insights
Fixing what’s broken is only half the battle. The other half is making what you have even better. That’s where data enrichment comes in—it’s the process of taking your existing data and adding information from other sources to make it more complete and useful.
This is a complete game-changer, especially for sales and marketing. Imagine you’re a B2B company with a CRM full of names, emails, and company names. It’s useful, but limited. By enriching that data with firmographic details from a third-party provider, you can add powerful new context:
- Industry
- Company size (employee count)
- Annual revenue
- Tech stack they use
Suddenly, that simple contact list becomes a strategic weapon. Marketing can now build hyper-targeted campaigns for specific industries, and sales can prioritize their outreach based on which companies have the biggest budgets.
The field of remediation is also getting a lot smarter. By 2025, it’s expected that AI and machine learning will have automated much of the grunt work in detecting and correcting data issues. For instance, ML algorithms can now identify and merge duplicate customer records with incredible accuracy—a task that used to be a massive manual headache. This automation frees up your team and leads to far more reliable data for decision-making. You can get a deeper dive into these advancements and find additional insights on data quality trends.
When you combine cleansing, validation, and enrichment, you’re not just cleaning up old messes. You’re building a resilient data ecosystem that gets more valuable over time and actively fights off quality rot.
Embedding Quality into Your Daily Operations
One-off data fixes are just band-aids. If you want to build lasting trust in your data, you have to weave quality checks into the very fabric of your daily work. This means moving away from reactive, after-the-fact cleanup and toward a proactive, automated discipline.
This is the phase where quality stops being a chore and becomes a core function. The idea is to empower your data engineers to build fireproof systems instead of constantly fighting fires. Your goal should be to catch issues in minutes, not in a quarterly report after the damage is already done.
Setting Up Real-Time Monitoring and Alerting
Let’s be blunt: you can’t fix what you can’t see. Batch jobs that check for errors overnight are a relic from a different era. In a world where business decisions happen in real-time, you need real-time monitoring. It’s non-negotiable.
Imagine finding out about a data corruption issue a week after it happened. Now, imagine getting an alert within minutes. That’s the difference between a minor course correction and a full-blown data crisis.
A solid monitoring setup should keep an eye on key health indicators:
- Freshness: Is data arriving when it’s supposed to? A delay might mean a critical pipeline has failed.
- Volume: Did the number of incoming records suddenly plummet by 90%? That’s a huge red flag for an upstream source issue.
- Distribution: Did the average transaction value suddenly spike? A drastic change in the statistical profile of your data warrants an immediate look.
- Schema Changes: Did someone change a column name or data type without telling anyone? This is a classic pipeline-breaker.
When a monitor spots something out of the ordinary, it should immediately fire off an alert through Slack, PagerDuty, or email. The right people need to know right away.
Defining Data Quality SLAs
To get everyone on the same page, you need to define what “good” data actually looks like in clear, measurable terms. This is where Data Quality Service Level Agreements (SLAs) come in. Think of an SLA as a formal contract between the data team and the business, spelling out specific, quantifiable targets for data quality.
An SLA turns data quality from a vague technical concept into a concrete business commitment. It forces a real conversation about what metrics actually matter and creates clear accountability for hitting those targets.
A good SLA connects technical metrics directly to business impact. For example, a customer data SLA might look something like this:
- Completeness: 98% of new customer records must have a valid shipping address. Why? To minimize failed deliveries and keep customers happy.
- Timeliness: Inventory data must be refreshed every 15 minutes. Why? To ensure the e-commerce site shows accurate stock levels and avoids overselling.
- Uniqueness: The duplicate customer profile rate must stay below 0.5%. Why? To stop wasting marketing dollars and avoid a fragmented view of the customer.
These SLAs also assign ownership. The marketing team is now on the hook for lead data completeness, and the logistics team owns the timeliness of inventory updates.
Integrating Quality into CI/CD Pipelines
The absolute best way to fix data quality problems is to prevent them from happening in the first place. You do this by integrating automated quality checks directly into your Continuous Integration/Continuous Deployment (CI/CD) pipelines. This “shift-left” approach treats data quality like any other piece of critical code.
Before any new data pipeline or transformation gets pushed to production, automated tests run against a staging environment. These tests can check everything from schema integrity to complex business logic, making sure the new code doesn’t break anything. If a test fails, the deployment is automatically blocked.
This simple step is a game-changer for enhancing data quality early in the development cycle, saving countless hours of painful downstream cleanup. When you embed quality into your daily operations like this, you’re not just fixing data—you’re building a self-healing system that people can actually trust.
Choosing the Right Tools for Modern Data Quality
Let’s be honest: trying to manage data quality at scale by hand is a losing battle. Manual fixes and after-the-fact cleanups just can’t keep up with the sheer volume and speed of data flowing through a modern business.
Fortunately, we’re seeing a new generation of tools that are fundamentally changing the game. They help turn data quality from a thankless, reactive chore into an intelligent, automated process. This is about more than just fixing yesterday’s problems; it’s about building a resilient data ecosystem that spots and stops issues before they ever have a chance to corrupt your analytics, poison your AI models, or lead to a bad business decision.
The Rise of Augmented Data Quality Platforms
One of the biggest shifts in this space is the arrival of Augmented Data Quality (ADQ) platforms. These aren’t just fancy dashboards; they use AI and machine learning to automate the most soul-crushing parts of data quality, freeing up your team from manual data scrubbing to focus on work that actually matters.
Think of ADQ platforms as your proactive, tireless data steward. They’re constantly scanning your datasets to:
- Profile data at scale: Instantly see value distributions, flag format inconsistencies, and calculate null rates across billions of rows.
- Discover hidden rules: Use ML to uncover the implicit business rules and relationships in your data, which you can then codify into formal validation checks.
- Detect anomalies in real time: Learn what “normal” data looks like for a given metric and then immediately alert you the moment something deviates from that pattern.
This automation is a huge leap forward. The industry is quickly moving toward systems that can diagnose themselves and even suggest fixes, which drastically cuts down the manual work heaped on data teams. As Gartner’s research on ADQ solutions points out, this change is all about integrating AI to automate critical tasks like profiling and rule discovery. You can learn more about how AI is shaping the future of data management and its projected impact.
Ensuring Freshness with Change Data Capture
Another massive piece of the modern data quality puzzle is timeliness. Stale data is often just as dangerous as wrong data. When you base decisions on information that’s hours or even days old, you’re practically guaranteed to miss opportunities, deliver poor customer experiences, and create operational chaos.
This is where Change Data Capture (CDC) comes in.
Traditional batch ETL is a major source of data latency. A nightly batch job means that by 9 AM the next morning, your data is already up to 24 hours old. If that job fails? Now your dashboards and reports are even older, quickly becoming useless.
CDC flips this old model on its head. Instead of waiting for a scheduled batch run, it captures every single change—every insert, update, and delete—from your source database logs and streams it to your destination in near real time.
The benefits for data quality are immediate and profound:
- Improved Timeliness: Your data warehouse becomes a near-perfect mirror of your production systems, with latency measured in seconds, not hours.
- Enhanced Consistency: By streaming changes in the exact order they happened, CDC preserves transactional integrity and wipes out the consistency headaches common with batch processing.
- Reduced Source Impact: Modern CDC tools read from database transaction logs, which has a negligible performance impact on your critical source systems.
Combining CDC and ADQ for a Complete Solution
This is where you see the true power of a modern data stack. Platforms like Streamkap provide the real-time data movement backbone using CDC, ensuring your data is always fresh and consistent. When you pair this with a powerful ADQ tool, you create a complete, end-to-end data quality framework.
Imagine this scenario:
- A customer updates their shipping address in your production database.
- Streamkap’s CDC instantly captures this event and streams it toward your data warehouse.
- As the data is in flight, an ADQ tool validates the new address against a standardized format, flagging it if it’s incomplete or malformed.
- An alert is automatically routed to the data stewardship team to review the flagged record, all within minutes of the original change.
This combination closes the loop, allowing you to maintain high standards for accuracy, completeness, and timeliness all at once. By adopting tools that automate detection and enable real-time replication, you’re not just improving data quality—you’re building a more agile, reliable, and trustworthy data foundation for your entire organization. For those looking to go deeper, our guide on the different Change Data Capture tools is a great place to explore the available technologies.
Answering Your Toughest Data Quality Questions
Even with a solid plan, the real world always throws a few curveballs. This is where theory hits the pavement, and practical questions bubble up. Let’s tackle some of the most common ones that data leaders and engineers wrestle with when they start getting serious about data quality.
Where Do I Even Begin? Our Data Is a Complete Mess
When you’re staring down a mountain of data debt, the urge to fix everything at once is strong. Resist it. Trying to boil the ocean is a surefire way to get nowhere fast.
My advice? Start small and aim for a high-impact win.
Find one critical business process that’s actively on fire because of bad data. Is the sales team wasting time on duplicate leads? Is finance pulling their hair out over the weekly inventory report that never seems to add up? Pick that one, single problem.
Once you’ve got your target, run a focused assessment on just the datasets feeding that process. Profile the data, figure out what’s actually broken, and concentrate your initial cleanup efforts right there.
A quick, visible win does more than just fix a report. It builds momentum. It shows tangible value to the business, which makes getting buy-in for bigger data quality projects a whole lot easier.
How Can We Actually Measure the ROI of This?
This is the big one. To justify the time and money, you have to connect data quality improvements to the bottom line. The trick is to link your data quality metrics directly to concrete business outcomes—think cost savings and revenue growth.
On the cost-saving side, you can start tracking things like:
- Reduced Rework: How many hours are your analysts saving now that they don’t have to manually scrub spreadsheets before every meeting?
- Fewer Operational Glitches: Count the reduction in costly errors. Think packages shipped to the wrong address or invoices sent to defunct contacts.
- Lower Compliance Risk: In regulated industries, better data accuracy can be directly tied to avoiding six- or seven-figure fines.
And for revenue generation, look for gains in:
- Smarter Marketing Campaigns: Clean, enriched customer data means better segmentation, which leads to higher conversion rates.
- More Efficient Sales Teams: When lead data is accurate, reps spend less time chasing ghosts and more time actually selling.
- Better Customer Retention: Reliable data powers personalization. More personalized experiences lead to happier customers who stick around longer.
When you can put real numbers to these areas, you build an undeniable business case for your data quality program.
So, Who Is Actually Responsible for Data Quality?
Ah, the classic question. The honest answer is that data quality is a shared responsibility, but it crumbles without clear ownership. Think of it as a team sport where everyone has a specific role.
Your data engineers and IT folks are on the hook for the technical plumbing. They build the pipelines, set up the monitoring tools, and manage the data quality platforms. They own the how.
But the business users are the real data owners. The marketing team knows what makes a lead “qualified.” The finance department knows the rules that govern transaction data. They have the context, so they’re the ones who should be defining the quality standards and business rules. They own the what.
A good data governance framework makes this partnership official. It creates roles like Data Stewards—people from the business side who are formally accountable for the data in their domain. This structure gets everyone pulling in the same direction and makes data quality a true company-wide commitment.
Ready to stop dealing with stale, inconsistent data? Streamkap uses real-time Change Data Capture (CDC) to ensure your data is always fresh, accurate, and ready for action. Replace your slow, unreliable batch jobs and see how streaming can transform your data quality.