10 Data Architecture Best Practices for Scalable Systems in 2025
Explore 10 actionable data architecture best practices for building scalable, secure, and modern data systems. Master DDD, streaming, governance, and more.
In today’s data-saturated environment, a robust data architecture is no longer a technical nicety; it’s the foundational blueprint for innovation, scalability, and competitive advantage. Moving beyond outdated batch processing and monolithic designs is critical for any organization looking to leverage real-time insights and maintain agility. However, designing an architecture that is not only powerful but also secure, maintainable, and cost-effective presents a significant challenge. Many teams struggle with data silos, performance bottlenecks, and inflexible systems that hinder growth and analytics.
This guide cuts through the complexity, offering a definitive roundup of 10 essential data architecture best practices that modern data teams must master. We will provide actionable strategies to help you build a resilient and future-proof data ecosystem, focusing on practical implementation over abstract theory. You will learn how to structure your architecture around business capabilities, ensure data integrity from the start, and prepare for future scale.
Specifically, we’ll explore critical concepts including:
- Domain-Driven Design (DDD) to align data models with business functions.
- Real-time streaming and Change Data Capture (CDC) for immediate data availability.
- Data governance and quality frameworks to build trust and ensure compliance.
- Cloud-native patterns for creating scalable and resilient distributed systems.
- Data observability to monitor, troubleshoot, and understand your data’s health.
Each practice is detailed with concrete examples and strategic advice, ensuring you can immediately apply these principles to your projects. This isn’t just a list of ideas; it’s a comprehensive manual for building an architecture that delivers tangible business value and supports long-term strategic goals.
1. Domain-Driven Design (DDD) for Data Architecture
One of the most impactful data architecture best practices is to align your technical design with the business it serves. Domain-Driven Design (DDD), a concept popularized by Eric Evans, provides a powerful framework for achieving this alignment. Instead of structuring data around technology constraints, DDD organizes data models and systems around distinct business concepts, or “domains.” This approach ensures that your architecture directly reflects and supports core business processes, making it more intuitive, maintainable, and scalable.
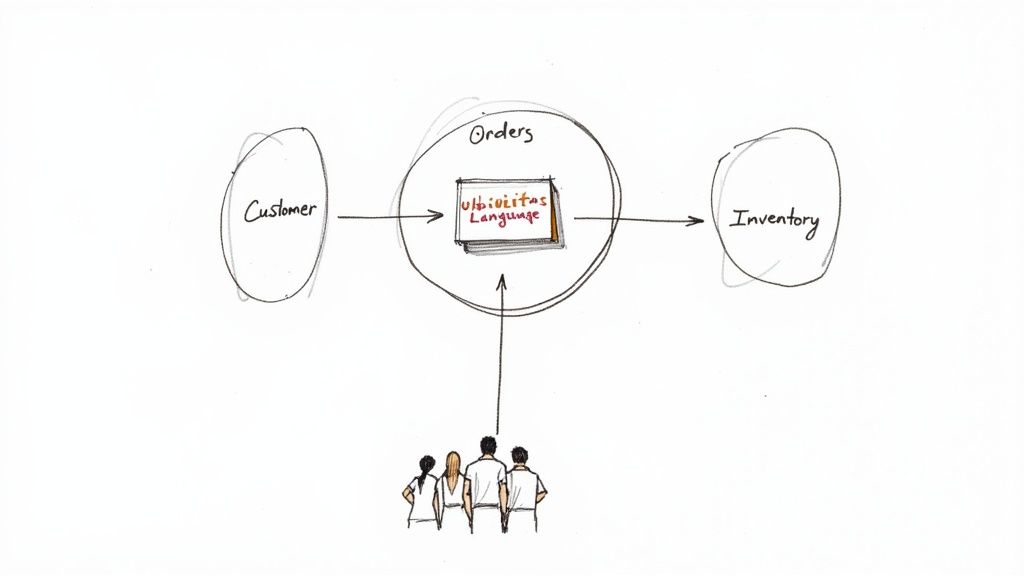
DDD introduces the concept of a “bounded context,” which is a clear boundary within which a specific domain model is defined and applicable. For example, a “customer” in the sales domain (with data like purchase history) is different from a “customer” in the support domain (with data like support tickets). By isolating these contexts, you prevent data model ambiguity and create a more modular system.
Why It’s a Best Practice
Adopting DDD prevents the creation of a monolithic, one-size-fits-all data model that becomes brittle and difficult to change. It allows teams to work autonomously within their own bounded contexts, accelerating development and reducing dependencies. This is why companies like Netflix use it to manage complex services, and Amazon organizes its massive e-commerce platform around domains like Orders, Inventory, and Payments.
Actionable Implementation Tips
To apply DDD to your data architecture, start by collaborating with business stakeholders to map out core processes and identify natural domain boundaries.
- Establish a Ubiquitous Language: Work with domain experts to create a shared, unambiguous vocabulary for all business concepts. This glossary becomes the foundation for naming tables, columns, APIs, and services.
- Identify Bounded Contexts: Define the explicit boundaries where a specific domain model applies. The logic for
Shippingshould be separate from the logic forBilling, even if they both interact with anOrder. - Use Domain Events: When information needs to cross from one context to another (e.g., an
OrderPlacedevent from theOrderscontext triggers an action in theShippingcontext), use asynchronous domain events. This decouples the contexts and improves system resilience.
2. Data Modeling and Normalization
A cornerstone of any robust data architecture is the disciplined practice of data modeling and normalization. This process involves creating a conceptual blueprint, or model, that defines the structure, relationships, and constraints of your data. Normalization, a key part of this process first theorized by Edgar F. Codd, systematically organizes data into tables to reduce redundancy and improve data integrity, ensuring that each piece of information is stored in only one place. This foundational practice prevents data anomalies and simplifies data maintenance.
Proper modeling establishes a clear and efficient structure, much like an architectural plan for a building. It ensures that data is stored logically, queries are efficient, and the system can scale without compromising integrity. By defining entities, attributes, and relationships, you create a stable foundation that supports reliable transactional processing and analytics.
Why It’s a Best Practice
Without proper modeling and normalization, databases become bloated, slow, and prone to error. Redundant data leads to update anomalies, where changing information in one place fails to update it elsewhere, creating inconsistencies. This best practice is critical in systems where data integrity is paramount. For example, financial institutions rely on highly normalized schemas to ensure transaction accuracy, and e-commerce platforms use it to cleanly separate customer, product, and order information.
Actionable Implementation Tips
To effectively implement data modeling and normalization, focus on creating a clear, well-documented, and balanced design.
- Create Entity-Relationship Diagrams (ERDs): Use tools like Lucidchart or MySQL Workbench to visually map out your entities (tables), their attributes (columns), and the relationships between them. This serves as the primary documentation for your data structure.
- Apply Normal Forms Systematically: Aim for at least the Third Normal Form (3NF) for transactional systems to eliminate most redundancy and dependency issues. This ensures that all attributes in a table are dependent only on the primary key.
- Balance Normalization and Performance: While high normalization is great for data integrity, it can sometimes lead to complex queries with many joins. For read-heavy analytical systems, you may intentionally denormalize certain tables to improve query performance.
- Document and Maintain a Data Dictionary: Create a central document that defines every table and column, including data types, constraints, and business context. This is invaluable for onboarding new team members and maintaining the architecture.
3. Data Governance and Quality Management
A sophisticated data architecture is incomplete without a framework to ensure its contents are accurate, secure, and trustworthy. Data governance provides this framework by establishing the policies, standards, and controls for managing data assets across an organization. It’s a holistic discipline that encompasses everything from data quality and metadata management to compliance and security, transforming raw data into a reliable strategic asset.
Effective governance isn’t just about restriction; it’s about enablement. It defines who can take what action, upon what data, in what situations, and using what methods. By clarifying roles, responsibilities, and processes, it builds a foundation of trust that empowers users to confidently leverage data for decision-making. This systematic approach is a core component of modern data architecture best practices, ensuring long-term value and mitigating risk.
Why It’s a Best Practice
Without strong governance, data architectures often devolve into “data swamps” where poor quality and inconsistent definitions render the data unusable. A robust governance program ensures data reliability, facilitates regulatory compliance (like GDPR and CCPA), and enhances security. Financial institutions like JPMorgan Chase rely on it for risk management, while retail giants like Walmart use it to ensure product data consistency across their massive supply chains. It’s the mechanism that makes data truly enterprise-ready.
Actionable Implementation Tips
To implement effective data governance, start small and focus on high-impact areas rather than attempting to boil the ocean.
- Establish Clear Ownership: Assign data stewards and owners for critical data domains. These individuals are responsible for defining quality rules, managing access, and ensuring the data is fit for purpose.
- Start with a High-Value Domain: Begin your governance initiative with a single, high-impact business area, like customer or product data. This allows you to demonstrate value quickly and build momentum. To ensure the integrity, compliance, and strategic value of your data, establishing robust data governance practices is crucial. Discover proven data governance strategies in banking for a real-world model.
- Automate Quality Monitoring: Implement tools and processes to automatically monitor data quality against predefined rules. Set up alerts for anomalies and establish workflows to address common data integrity problems before they impact business operations.
- Create a Governance Council: Form a cross-functional committee with representation from business, IT, and legal teams to oversee the governance program, set priorities, and resolve disputes.
4. Scalable Data Architecture with Microservices
Moving away from monolithic systems, a microservices architecture decomposes an application into a collection of loosely coupled, independently deployable services. This is a crucial data architecture best practice for building resilient and scalable systems. In this model, each service owns its data and logic, communicating with others through well-defined APIs. This decentralization of data ownership prevents the tight coupling and single point of failure common in traditional architectures.
Instead of a single, massive database, each microservice manages its own data store, chosen specifically for its needs. For example, a user profile service might use a document database like MongoDB, while a transaction service might rely on a relational database like PostgreSQL. This polyglot persistence allows teams to select the best technology for the job, optimizing performance and functionality for each specific business capability.
Why It’s a Best Practice
A microservices approach directly enables organizational and technical scalability. Small, autonomous teams can develop, deploy, and scale their services independently, accelerating release cycles. This architectural style is famously used by companies like Netflix and Uber to handle massive, fluctuating workloads. Amazon’s entire retail platform is a prime example of a service-oriented architecture, where services like Cart, Checkout, and Recommendations operate with their own data stores, ensuring the system remains resilient even if one component fails.
Actionable Implementation Tips
Adopting a microservices data architecture requires a deliberate strategy to manage data consistency and communication across distributed services.
- Define Clear Service Boundaries: Use business capabilities to define your microservices. A service should be responsible for a single business function, such as
InventoryManagementorCustomerNotifications. - Implement Event-Sourced Communication: Use an event-driven pattern for inter-service communication. When a service changes its state, it publishes an event (e.g.,
OrderCreated). Other services can subscribe to these events to update their own data stores, promoting eventual consistency. - Design for Failure: In a distributed system, failures are inevitable. Implement patterns like circuit breakers (to prevent a failing service from cascading failures) and retries with exponential backoff to build a resilient architecture.
- Use an API Gateway: An API Gateway acts as a single entry point for all client requests, routing them to the appropriate microservice. This simplifies client interactions and provides a central place to handle cross-cutting concerns like authentication and rate limiting.
5. Cloud-Native and Distributed Data Architecture
A fundamental modern data architecture best practice is to build for the cloud. A cloud-native and distributed data architecture leverages the inherent elasticity, resilience, and scalability of cloud computing services. Rather than lifting and shifting on-premise designs, this approach uses managed services, containerization, and distributed processing frameworks to create systems that can efficiently handle massive data volumes and highly variable workloads while minimizing operational overhead.
This architectural style moves away from monolithic, single-server systems toward a network of decoupled, specialized components. By using services like serverless functions (e.g., AWS Lambda), managed databases (e.g., Amazon DynamoDB or Google Cloud Spanner), and container orchestration (e.g., Kubernetes), you can build systems that automatically scale resources up or down based on real-time demand, ensuring both performance and cost-efficiency.
Why It’s a Best Practice
Adopting a cloud-native architecture provides unmatched scalability and agility. It allows organizations to pay only for the resources they consume and offload the burden of managing underlying infrastructure to cloud providers. This model is why companies like Netflix can deliver petabytes of content globally with high availability, and Slack can process billions of messages daily. The distributed nature of these systems also enhances resilience, as the failure of a single component does not bring down the entire application.
Actionable Implementation Tips
To effectively implement a cloud-native data architecture, focus on automation, managed services, and designing for failure.
- Adopt Infrastructure-as-Code (IaC): Use tools like Terraform or AWS CloudFormation to define and manage your infrastructure programmatically. This ensures your environments are reproducible, consistent, and easily version-controlled.
- Leverage Managed Services: Prioritize using managed services for databases, message queues, and data processing (like Amazon RDS, Google Pub/Sub, or Azure Databricks). This significantly reduces the time your team spends on maintenance, patching, and scaling.
- Design for Multi-Region Resilience: From the outset, architect your systems to operate across multiple geographic regions or availability zones. This strategy provides high availability and disaster recovery capabilities, protecting your data and services from localized outages.
- Implement Robust Cost Monitoring: Cloud costs can escalate quickly if not managed. Use cloud-native tools like AWS Cost Explorer or third-party platforms to monitor spending, set budgets, and optimize resource allocation continuously.
6. Data Warehouse and Data Lake Architecture
A cornerstone of modern data architecture best practices is the strategic use of data warehouses and data lakes. These two storage paradigms serve distinct but complementary analytical needs. A data warehouse stores structured, processed data, meticulously modeled for online analytical processing (OLAP) and business intelligence. In contrast, a data lake is a vast repository for raw, unprocessed data in its native format, providing the flexibility needed for data science and machine learning exploration.
The most effective modern architectures often combine these approaches into a “lakehouse” pattern. This hybrid model leverages the low-cost, scalable storage of a data lake with the performance, reliability, and governance features of a data warehouse. This enables organizations to support both traditional BI reporting and advanced analytics from a single, unified source of truth, balancing structure with unparalleled flexibility.
Why It’s a Best Practice
Adopting a clear strategy for data warehousing and data lakes prevents a chaotic data landscape where analytical and operational systems are poorly delineated. It provides dedicated, optimized environments for different types of workloads. For instance, a retailer can use a data warehouse for precise sales and inventory reporting, while a tech company like Netflix uses its data lake to analyze user behavior patterns for content recommendations. The lakehouse architecture, championed by companies like Databricks and Snowflake, further refines this by reducing data duplication and simplifying management.
Actionable Implementation Tips
To effectively implement this dual architecture, focus on purpose-built design and robust governance. Start by identifying the primary use cases to determine whether a warehouse, lake, or lakehouse is the best fit.
- Design for the User: For data warehouses, design schemas (like star or snowflake) based on direct collaboration with business users to ensure the model answers their most critical questions. You can find more information in our guide to best practices in data warehousing.
- Govern Your Lake: Before populating a data lake, establish strong governance policies for metadata management, access control, and data quality. This prevents it from becoming an unmanageable “data swamp.”
- Leverage Modern Tooling: Use open table formats like Apache Iceberg or Delta Lake to bring ACID transactions and reliability to your data lake. For a lakehouse, consider platforms like Databricks or Snowflake that natively integrate both storage paradigms.
- Optimize for Cost and Scale: Use cost-effective cloud storage like Amazon S3 or Azure Data Lake Storage (ADLS) as the foundation for your data lake, allowing you to store massive datasets affordably.
7. Real-Time Data Architecture and Streaming
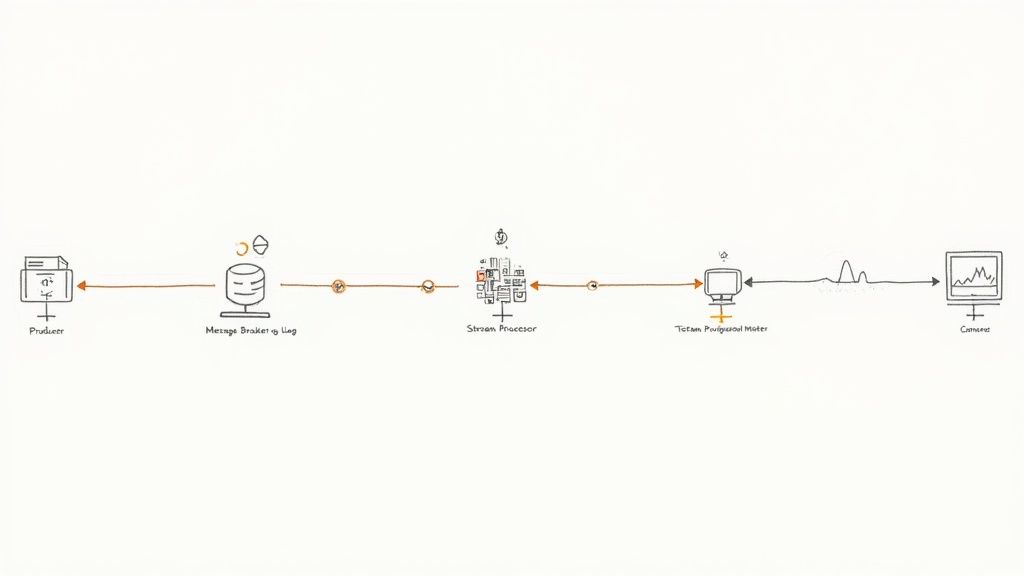
In today’s fast-paced digital environment, waiting hours or days for batch processing is no longer acceptable for many business-critical functions. One of the most transformative data architecture best practices is adopting a real-time, streaming-first approach. This architecture processes and analyzes data as it is generated, enabling immediate insights and responsive actions. It uses a combination of message brokers, stream processors, and event stores to handle continuous data flows, moving from periodic data loads to a constant, low-latency stream of information.
This shift is fundamental for any application requiring instant decision-making. Streaming architectures are designed to ingest, process, and act on high-velocity data from sources like application events, IoT sensors, or log files. Instead of collecting data in a warehouse for later analysis, events are handled on the fly, unlocking capabilities like real-time fraud detection, dynamic pricing, and immediate personalization.
Why It’s a Best Practice
A streaming architecture provides a significant competitive advantage by reducing the time from event to insight to mere seconds. This capability is crucial for modern businesses. Financial institutions use it to detect and block fraudulent transactions the moment they occur. Uber leverages it to process real-time ride data for dynamic pricing and driver dispatch, while Netflix analyzes viewing behavior in real time to power its recommendation engine. This approach makes systems more responsive, resilient, and capable of handling complex event processing at scale.
Actionable Implementation Tips
Implementing a real-time architecture requires a shift in both tooling and mindset. The focus moves from batch-oriented ETL to continuous data flow management.
- Establish a Scalable Message Broker: Start with a durable, high-throughput message broker like Apache Kafka. It acts as the central nervous system for your real-time data, decoupling producers from consumers and providing a reliable buffer for event streams.
- Choose a Stream Processing Framework: Use a powerful stream processor like Apache Flink or Apache Spark Streaming for complex event processing, stateful computations, and windowed aggregations. These frameworks allow you to build sophisticated applications that react to patterns in the data stream. You can learn more about how to implement these patterns in our guide to real-time data streaming.
- Design for Fault Tolerance: Real-time systems must be resilient. Implement state checkpointing to recover from failures without data loss, and use partitions and consumer groups in Kafka to ensure high availability and balanced processing loads.
8. Data Security and Privacy by Design
In modern data architecture best practices, security and privacy can no longer be afterthoughts bolted on at the end of a project. Instead, they must be foundational principles integrated from the very beginning. This proactive approach, known as “Privacy by Design,” ensures that data protection measures are built directly into the fabric of your systems, making security an inherent quality of your architecture.
This methodology involves embedding controls like encryption, access management, data classification, and anonymization into every stage of the data lifecycle. By designing with security and privacy as core requirements, you systematically reduce vulnerabilities and ensure that your architecture is built to comply with stringent regulations like GDPR, CCPA, and HIPAA from day one, rather than trying to retrofit compliance measures later.
Why It’s a Best Practice
Adopting a “by design” approach fundamentally shifts security from being a reactive, often costly, process to a proactive, value-adding one. It protects sensitive data, builds customer trust, and mitigates the immense financial and reputational risks of data breaches and regulatory fines. This is why healthcare systems encrypt all patient data to comply with HIPAA, and financial institutions build their platforms around PCI DSS requirements to protect cardholder information.
Actionable Implementation Tips
To embed security and privacy into your data architecture, focus on implementing controls at multiple layers.
- Encrypt Everything: Use strong encryption standards like AES-256 for data at rest (in databases and storage) and TLS/SSL for data in transit (moving across networks). This is a non-negotiable baseline.
- Implement Least Privilege Access: Grant users and systems the minimum level of access required to perform their functions. Use tools like Apache Ranger or AWS Lake Formation to enforce granular, role-based access policies on your data platforms.
- Anonymize and Mask Data: For non-production environments like development and testing, use data masking or anonymization techniques to protect sensitive information while still providing realistic data for your teams.
- Automate Auditing and Monitoring: Regularly audit and review access logs to detect and respond to suspicious activity. Automating this process helps identify potential threats in real time.
9. API-First and Contract-Driven Architecture
In a modern, distributed data ecosystem, the way services communicate is as important as the services themselves. An API-first approach treats these communication channels as first-class citizens, prioritizing their design and definition before any implementation code is written. This methodology ensures that your data services are well-defined, easily consumable, and consistently managed from the outset.
A core tenet of this approach is contract-driven development, where a formal “contract” like an OpenAPI (formerly Swagger) or AsyncAPI specification defines how data will be exchanged. This contract dictates data schemas, endpoints, and interaction patterns, serving as a single source of truth for both data producers and consumers. By defining this agreement upfront, teams can work in parallel, decouple their development cycles, and reduce integration friction.
Why It’s a Best Practice
Adopting an API-first mindset is a crucial data architecture best practice because it enforces consistency and improves the developer experience across the organization. It prevents the ad-hoc creation of data endpoints that are poorly documented and difficult to integrate. Companies like Stripe and Twilio built their entire businesses on this principle, providing clean, well-documented APIs that developers love to use, fostering a powerful ecosystem around their data products.
Actionable Implementation Tips
To implement an API-first culture, focus on formalizing the design process and using tools that support contract-driven workflows. This shifts the focus from backend implementation to user-centric API design.
- Define Contracts First: Use tools like Stoplight or Swagger Editor to collaboratively design and mock APIs. This allows frontend teams, data consumers, and other stakeholders to provide feedback before any backend work begins.
- Implement Contract Testing: Use consumer-driven contract testing frameworks like Pact. This ensures that any changes to a data-producing service do not break its consumers, maintaining the integrity of the agreed-upon contract.
- Version Your APIs: Plan for evolution by versioning your APIs from day one (e.g.,
/api/v1/data). This allows you to introduce breaking changes in new versions without disrupting existing consumers. - Use an API Gateway: Deploy an API gateway like Kong or AWS API Gateway to centralize concerns such as authentication, rate limiting, and monitoring, ensuring consistent governance across all data services.
10. Observability, Monitoring, and Data Lineage
A robust data architecture is not just about moving data; it’s about understanding its behavior, health, and journey. This is where observability, monitoring, and data lineage become critical. While monitoring tells you when something is wrong (e.g., a pipeline failed), observability tells you why. It provides deep insights into your system’s state through logs, metrics, and traces, enabling you to debug complex issues in distributed environments.
Data lineage complements this by creating a transparent map of the data’s journey from its origin to its consumption. It answers crucial questions like “Where did this data come from?”, “What transformations were applied?”, and “Who is using this report?”. Together, these practices form the foundation of a reliable and governable data ecosystem, which is a core tenet of modern data architecture best practices.
Why It’s a Best Practice
In complex data systems with multiple sources, transformations, and consumers, failures are inevitable. Without observability, troubleshooting becomes a frustrating exercise in guesswork. Data lineage is equally vital for impact analysis, regulatory compliance (like GDPR), and building trust in data assets. Companies like Uber and Netflix have pioneered these practices, using distributed tracing and real-time metric monitoring to manage thousands of microservices and data pipelines, ensuring system reliability and data integrity at a massive scale.
Actionable Implementation Tips
To embed observability and lineage into your data architecture, focus on instrumenting every stage of the data lifecycle. This proactive approach ensures you can diagnose and resolve issues before they impact business operations.
- Implement Structured Logging: Standardize logs across all applications and pipelines. Include correlation IDs to trace a single request or data record as it moves through multiple systems.
- Track Data Lineage: Use tools like Alation, Collibra, or open-source solutions like OpenLineage to automatically map data flows. Documenting lineage helps with impact analysis when a schema change is proposed.
- Deploy Distributed Tracing: For microservices-based or complex streaming architectures, implement distributed tracing with tools like Jaeger or OpenTelemetry to visualize end-to-end data paths and identify performance bottlenecks.
- Establish Key Health Metrics: Monitor pipeline vitals like data latency, throughput, and error rates. Use tools like Prometheus for metrics collection and Grafana for creating dashboards that provide a single view of system health.
- Set Up Proactive Alerting: Configure alerts based on Service Level Objectives (SLOs) for data freshness, quality, and availability. Notify teams immediately when a data product is at risk of violating its promise to consumers.
10-Point Data Architecture Best Practices Comparison
ApproachImplementation complexityResource requirementsExpected outcomesIdeal use casesKey advantagesDomain-Driven Design (DDD) for Data ArchitectureHigh — requires deep domain analysis and coordinationCross-functional teams, domain experts, modeling toolsAligned data models, clear bounded contexts, easier evolutionComplex business domains, large organizations, microservicesStrong business–tech alignment; maintainable, scalable modelsData Modeling and NormalizationMedium — upfront modeling and schema designData modelers, DBAs, ER toolsConsistent schemas, reduced redundancy, improved integrityTransactional systems, relational databases, OLTPData integrity; simplified updates; optimized queriesData Governance and Quality ManagementHigh — policy, process, and organizational changeGovernance teams, cataloging/QC tools, monitoringTrusted data, compliance, improved data discoveryRegulated industries, enterprise-wide data programsCompliance, reliable analytics, reduced operational riskScalable Data Architecture with MicroservicesHigh — distributed data and service coordinationDevOps, distributed databases, orchestration toolsIndependent scaling, service autonomy, resilienceLarge-scale, modular applications with rapid releasesFault isolation; technology diversity; team autonomyCloud-Native and Distributed Data ArchitectureMedium–High — cloud patterns and distributed designCloud services, IaC, cloud engineers, managed servicesElastic, resilient systems with lower ops burdenVariable workloads, big data, SaaS, global servicesAutomatic scaling; managed services; high availabilityData Warehouse and Data Lake ArchitectureMedium — ETL/ELT pipelines and schema planningData engineers, storage, BI/analytics toolsStructured analytics, flexible raw-data explorationBI, analytics, ML initiatives, reporting at scaleOptimized analytics; cost-effective raw storage; lakehouse flexibilityReal-Time Data Architecture and StreamingHigh — streaming frameworks and stateful processingStream platforms (Kafka/Flink), SREs, low-latency infraLow-latency insights, immediate event-driven actionsFraud detection, IoT, real-time monitoring, personalizationImmediate insights; responsive operations; complex event handlingData Security and Privacy by DesignMedium–High — integrated controls and compliance workSecurity experts, encryption, IAM, auditing toolsProtected sensitive data, regulatory compliance, auditabilityHealthcare, finance, consumer data platformsRisk reduction; customer trust; simplified auditsAPI-First and Contract-Driven ArchitectureMedium — upfront API design and contract managementAPI designers, spec tools, contract testing frameworksStable interfaces, parallel development, fewer integrations issuesMulti-team systems, third-party integrations, developer platformsClear contracts; faster integration; improved developer experienceObservability, Monitoring, and Data LineageMedium–High — instrumentation and correlation across systemsLogging/metrics/tracing tools, SREs, storageRapid troubleshooting, lineage visibility, proactive alertsDistributed systems, data pipelines, regulated environmentsFaster incident resolution; impact analysis; compliance evidence
Unifying Your Architecture with Real-Time Data Movement
Navigating the landscape of data architecture best practices can feel like assembling a complex puzzle. From embracing Domain-Driven Design to embedding security by design, each principle we’ve explored serves as a critical piece. Implementing robust data modeling, establishing strong governance, and designing for observability are not just isolated tasks; they are interconnected disciplines that form the bedrock of a resilient, scalable, and value-driven data ecosystem. The goal is to move beyond a fragmented collection of data silos and technologies toward a cohesive, responsive system where data is a current, reliable, and accessible asset.
The common thread weaving these practices together is the seamless and timely flow of information. A perfectly designed data model or a well-governed data lake loses its impact if the data populating it is stale. This is where the architectural shift from traditional batch processing to real-time streaming becomes a non-negotiable component of modern design.
The Real-Time Imperative in Modern Data Architecture
The most sophisticated data architectures are ultimately measured by their ability to deliver timely insights that drive business decisions. Batch ETL processes, which operate on hourly or daily schedules, create an inherent latency gap between when an event occurs and when it becomes available for analysis. This delay can be the difference between proactive intervention and reactive damage control.
Embracing real-time data movement, particularly through Change Data Capture (CDC), directly addresses this challenge. CDC closes the latency gap by capturing changes from source databases (like PostgreSQL, MySQL, or MongoDB) as they happen and streaming them to analytical destinations in milliseconds. This ensures that your data warehouse or data lake is a near-perfect mirror of your operational systems, enabling a host of powerful use cases:
- Real-Time Analytics: Empowering business intelligence teams to build dashboards that reflect current business reality, not yesterday’s summary.
- Operational AI: Fueling machine learning models with the freshest data for fraud detection, dynamic pricing, and personalized recommendations.
- Synchronized Microservices: Ensuring data consistency across distributed services without resorting to complex and brittle point-to-point integrations.
However, the journey to real-time is often fraught with technical complexity. Building and maintaining the underlying streaming infrastructure using open-source tools like Apache Kafka, Debezium, and Apache Flink requires specialized expertise, significant engineering effort, and ongoing operational overhead. This is where managed solutions play a pivotal role.
Bridging the Gap: From Best Practices to Practical Implementation
Adopting these data architecture best practices is not merely an academic exercise; it’s about making strategic choices that reduce complexity and accelerate value delivery. Just as you wouldn’t build your own cloud servers from scratch, building a real-time data pipeline can be vastly simplified by leveraging a fully managed platform.
Solutions like Streamkap abstract away the intricate and costly components of real-time data movement. Instead of wrestling with Kafka cluster management, connector configurations, and schema evolution drift, your team can focus on the core architectural principles. This approach allows you to:
- Reduce Total Cost of Ownership (TCO): By offloading infrastructure management, you eliminate the costs associated with server provisioning, maintenance, and the specialized engineering talent required to run streaming systems at scale.
- Accelerate Time to Value: Data engineers can stand up robust, production-ready pipelines in minutes, not months, drastically shortening the time it takes to get fresh data into the hands of analysts and data scientists.
- Improve Reliability and Scalability: A managed service provides enterprise-grade reliability, fault tolerance, and elastic scalability without requiring your team to become distributed systems experts.
Ultimately, the pinnacle of data architecture is a system that is not only well-designed but also agile and responsive. By integrating real-time streaming as a core tenet, you transform your architecture from a static blueprint into a dynamic, living system that fuels your organization’s intelligence and adaptability. The best practices discussed in this article provide the “what” and the “why,” while modern streaming platforms provide the “how,” making this powerful vision an achievable reality.
Ready to unify your data ecosystem with real-time data movement? See how Streamkap provides a fully managed, serverless platform for streaming CDC from databases like Postgres, MySQL, and SQL Server to destinations like Snowflake and Databricks with sub-second latency. Explore a modern approach to data integration and see our platform in action at Streamkap.
Related resources
Apache Iceberg for CDC: Streaming Upserts, Merge-on-Read, and Small-File Management
How CDC pipelines write into Apache Iceberg using merge-on-read vs copy-on-write strategies, what the small-file problem looks like at streaming scale, and how to configure compaction.
Iceberg Partition Evolution: Schema Changes Without Rewriting Your Data Lake
How to change your Iceberg partition strategy in a running production table: hidden partitioning, spec versioning, the step-by-step migration pattern, and the monitoring signals that warn of skew before it hits query latency.
Bursty Workloads and SLA-Compliant Autoscaling: SaaS vs BYOC Trade-Offs
Navigate autoscaling strategy for bursty CDC workloads with tight SLAs. Compare SaaS elasticity against reserved BYOC capacity, validate latency at production volume, and right-size destination throughput.