Choosing Your Data Pipeline Architectures
Explore key data pipeline architectures like batch, streaming, Lambda, and Kappa. Learn how to choose the right model for an efficient and scalable system.
Data pipeline architectures are essentially the master blueprints for your company's data plumbing. They lay out the entire system that dictates how information travels from where it's created to where it needs to go. Getting this right is crucial—it's what ensures your data is reliable, timely, and scalable, preventing the digital equivalent of leaks, blockages, and expensive messes.
The Foundation of a Modern Data Strategy
Think of a data pipeline as an automated factory assembly line. Raw materials (your data) come in at one end, move through a series of processing stations, and come out the other side as a finished product (actionable insights). Without a thoughtfully designed architecture, that assembly line would be pure chaos—inefficient, unreliable, and constantly breaking down.
The whole point of a data pipeline architecture is to bring order to that flow. It provides a strategic framework for moving information from all kinds of places—transactional databases, SaaS apps, IoT sensors—and delivering it to destinations like data warehouses, analytics tools, or machine learning models. A solid architecture answers the tough operational questions before they turn into full-blown problems.
Core Components of a Data Pipeline
No matter how simple or complex a pipeline is, they all share a few fundamental stages. These components work together in a sequence to turn raw data into something valuable.
Here’s a quick breakdown of the core components you'll find in almost any data pipeline:
ComponentRoleCommon TechnologiesSourceThe origin point of the data.PostgreSQL, MySQL, APIs, IoT sensors, event streamsProcessing EngineThe "factory floor" where data is cleaned, transformed, and validated.Spark, Flink, dbt, custom scriptsDestinationThe final stop where processed data is stored and used.Snowflake, BigQuery, Redshift, data lakes, BI tools
Understanding these three pieces is the first step to grasping how different architectural patterns work. Each pattern just arranges and connects these components in a unique way to solve a specific business problem.
Why a Solid Architecture Is Non-Negotiable
A "let's just wing it" approach to moving data simply doesn't cut it anymore, especially when you're dealing with serious scale. Companies are drowning in data while simultaneously being pressured to deliver insights in real-time. To put it in perspective, the global datasphere is projected to hit 175 zettabytes by 2025. That's a staggering amount of information that makes efficient data handling a must-have, not a nice-to-have.
A well-designed data pipeline architecture is the difference between a controlled, efficient flow of information and a costly, unreliable data swamp. It's what turns data from a raw commodity into a true strategic asset.
Ultimately, these architectures are what make advanced, high-value projects possible. We're moving beyond simple data transfers; modern pipelines are now critical for supporting sophisticated AI processing workflows and powering the next wave of data-driven applications.
The Workhorse: Batch Processing Pipelines

Batch processing is the old guard of data pipeline architectures, and for good reason—it’s time-tested and reliable. Think of it like a classic payroll system. You don't process a paycheck every time an employee clocks in or out. Instead, you collect all the timesheet data over a month, and then run one massive job to process it all at once.
That's the core idea of a batch pipeline: it runs on a schedule. Data is collected over a set period—maybe an hour, a day, or even a week—before being processed in one large, discrete chunk. For decades, this has been the backbone of data analytics because it’s incredibly efficient for handling huge volumes of information when you don’t need up-to-the-minute answers.
The Classic ETL Model
Most batch pipelines are built around the classic Extract, Transform, Load (ETL) model. It's a straightforward, three-step assembly line that turns raw data into something structured and ready for analysis.
- Extract: First, the pipeline pulls—or extracts—data from all its sources. This could be anything from transaction records in a PostgreSQL database to customer data from a CRM or web logs from a server.
- Transform: The raw data then gets moved to a staging area for a makeover. This is where the magic happens: data is cleaned up, standardized, checked for errors, and reshaped to fit the schema of whatever system it's heading to.
- Load: Finally, the clean, transformed data is loaded into its destination. This is typically a data warehouse like Snowflake or Google BigQuery, where business analysts can start digging in and running queries.
This predictable, step-by-step process ensures that only high-quality, consistent data makes it into your analytics environment.
When to Use Batch Processing
Batch processing really shines when thoroughness and cost-efficiency matter more than speed. The built-in delay isn't a bug; for many business operations, it's a feature.
Here are a few common scenarios where it's the perfect fit:
- Daily Sales Reporting: A retail company probably doesn’t need to know its sales figures down to the second. A batch job that runs overnight to summarize the previous day's sales gives managers everything they need for their morning meetings.
- Data Warehouse Updates: Most data warehouses are updated on a schedule. Running a nightly batch pipeline to load all the new and updated records is a standard, resource-friendly approach.
- Archiving and Compliance: For long-term data storage or regulatory needs, data is often collected and archived in large chunks. This is a perfect job for a batch pipeline.
The core trade-off with batch processing is simple: you sacrifice immediacy for simplicity and cost-effectiveness. When your business question is "What happened yesterday?" batch processing is often the most reliable and economical answer.
Key Benefits and Drawbacks
The lasting appeal of batch pipelines comes down to a few key advantages. They are generally simpler to design and manage than their real-time cousins. Chewing through massive datasets in one go can also be highly cost-effective, since you can schedule these intensive jobs to run during off-peak hours when computing resources are cheaper.
But there's a big catch: latency. By its very nature, the data is never truly current. If your business needs to react to things as they happen—like flagging a fraudulent transaction in real time or personalizing a website for a user who just landed—a batch pipeline just won't cut it. The insights it provides are always a look in the rearview mirror. In today's fast-moving world, that delay can be a critical limitation, and it's exactly why other data pipeline architectures came into being.
The Real-Time Power of Streaming Pipelines

If batch processing is like getting a monthly bank statement, a streaming pipeline is like watching your account balance update the second you make a purchase. This architecture flips the traditional model on its head. Instead of collecting data and processing it in scheduled chunks, streaming pipelines deal with information as it happens, one event at a time.
Think of it as a constantly flowing river, not a reservoir that fills up and is emptied periodically. Every piece of data is processed the moment it hits the stream. This is the magic behind the ultra-responsive digital experiences we’ve come to expect.
Tools like Apache Kafka and Amazon Kinesis are the engines driving this river, creating a durable, high-speed nervous system for real-time information. They don't just move data fast; they move it reliably.
From Latency to Immediacy
The biggest shift here is moving from analyzing "data at rest" to reacting to "data in motion." The question changes from "What happened last week?" to "What is happening right now?" This immediacy unlocks a whole new world of use cases where insights have an extremely short shelf life.
Consider the global real-time payments market, which is expected to hit $284.49 billion by 2032. That explosion is fueled entirely by the need for instant data processing, and it's only possible because of robust streaming architectures running in the background.
A streaming pipeline treats data not as a static resource to be collected, but as a dynamic stream of events to be acted upon. This changes the operational mindset from reactive analysis to proactive response.
Real-World Applications of Streaming Data
The real power of streaming becomes obvious when you see it in action. These are the kinds of scenarios where a delay of just a few minutes would make the data almost worthless.
- Instant Fraud Detection: A bank can analyze a credit card transaction in milliseconds. If a card is used in New York and then two seconds later in Tokyo, the system can instantly flag it as fraud and block the card before more damage is done.
- Live Social Media Sentiment Analysis: A brand launching a new product can track social media mentions as they happen. This lets the marketing team jump on positive trends or squash negative feedback immediately, not tomorrow morning when it's too late.
- IoT Device Monitoring: In a smart factory, sensors on machinery constantly stream data. A pipeline can process this telemetry on the fly and trigger a predictive maintenance alert if a machine's temperature spikes, helping to prevent a costly breakdown. For a great example, check out this piece on IoT for real-time carbon emissions tracking.
The Trade-Offs of Choosing Speed
For all their power, streaming pipelines aren't a walk in the park. They are significantly more complex to build and manage than their batch counterparts. Keeping data consistent and integral when it's flying through the system at high velocity requires some serious engineering.
Key Challenges to Consider:
- Implementation Complexity: Building a resilient streaming system requires specialized skills. Tools like Apache Flink are incredibly powerful, but they have a steep learning curve.
- Data Ordering: In a distributed system, network hiccups can cause events to arrive out of order. Guaranteeing that you process events in the exact sequence they occurred is a major technical challenge.
- State Management: Many real-time jobs need to remember things, like what a user has in their shopping cart. Managing this "state" in a way that survives system failures adds another layer of complexity.
Despite these hurdles, the competitive advantage you get from immediate insights often makes the effort well worth it. For a closer look at the mechanics, check out our guide to real-time data streaming. For any business that needs to operate at the speed of its customers, a streaming architecture is fast becoming a necessity.
Lambda: The Best of Both Worlds
So far, we've seen a pretty clear trade-off. Batch processing gives you a complete, accurate picture of your historical data, but it’s slow. Streaming, on the other hand, delivers instant insights into what’s happening right now but can struggle with large-scale historical analysis.
What if you absolutely need both?
This is the exact problem the Lambda architecture was built to solve. It’s a hybrid model that cleverly combines the strengths of both batch and streaming into one powerful system. Think of it as having two different specialists working on your data at the same time to give you a complete, up-to-the-minute view.
The Lambda architecture pulls this off by splitting the data flow into two parallel paths, creating a three-layer system.
Understanding The Three Layers
The real genius of the Lambda architecture is how it separates concerns. Every piece of incoming data is sent down two tracks simultaneously, feeding a slow, methodical process and a fast, immediate one.
- Batch Layer: This is your "source of truth." It takes in all the data and stores it in its raw, unchangeable form. On a set schedule, a massive batch job runs against this entire dataset to create comprehensive, highly accurate views. This layer is all about completeness, not speed.
- Speed Layer (or "Hot Path"): This layer only cares about what's new. It processes information in real-time as it arrives, providing low-latency updates and instant insights. The catch is that these views are temporary and might not be as perfectly accurate as what the batch layer produces.
- Serving Layer: This is where the magic happens. The serving layer takes the complete, accurate views from the batch layer and merges them with the real-time updates from the speed layer. When you query the system, this layer gives you a unified answer that combines deep historical context with up-to-the-second information.
The core idea behind Lambda is to get the best of both fault tolerance and speed. The batch layer ensures that even if the real-time system messes up, the data can always be re-crunched and corrected for ultimate accuracy.
When to Use The Lambda Architecture
The Lambda approach is incredibly powerful, but it's also demanding. It's best suited for high-stakes scenarios where you can't compromise on either historical accuracy or real-time responsiveness.
A classic example is a financial analytics platform. The business needs to run complex calculations on years of market data—that’s the batch layer's job. At the same time, it needs to show live stock price changes to traders instantly—the speed layer's job. The serving layer is what lets a trader see both historical trends and live ticks on the same screen.
The widespread adoption of powerful data pipeline architectures like this is a major reason for the market's growth. In North America, the presence of major tech firms has fueled this expansion. The U.S. market alone is projected to hit $12.11 billion by 2030 at a CAGR of 9.1%, a trend that’s only getting faster with mature digital infrastructures. You can discover more about the global data pipeline market forecast on fortunebusinessinsights.com.
The Challenge of Complexity
For all its power, the Lambda architecture has one massive drawback: complexity. You are essentially running two separate data processing systems in parallel. That means you have two different codebases to write, deploy, debug, and maintain.
This dual-system overhead is a major operational headache.
In fact, this complexity was the primary motivation for developing simpler alternatives. To see how the industry evolved to streamline this model, you can read our guide on the evolution from Lambda to Kappa architecture. For many teams, the operational cost of managing two distinct data pipelines just wasn't worth the benefit, pushing them toward more elegant solutions.
Kappa: The Simplified Streaming Approach

Running two parallel pipelines in the Lambda architecture felt clunky and complex to many engineers. The operational overhead of maintaining two different codebases sparked a simple but powerful question: what if we just picked one? The Kappa architecture is the elegant answer, created specifically to simplify data processing by going all-in on streaming.
The core idea is to get rid of the batch layer completely. In a Kappa setup, you handle everything—from real-time dashboards to deep historical analysis—with a single, unified technology stack. All data is treated as an event in a stream, stored in one canonical, replayable log like Apache Kafka.
This is a fundamental shift from the dual-path approach of Lambda. Instead of juggling two systems, your team builds, debugs, and manages just one. The result is a massive reduction in development and operational headaches.
How Kappa Handles Historical Data
You might be wondering: if there's no batch layer, how do you handle historical computations or fix errors? The solution is both clever and surprisingly simple: data replay. Because every event is permanently stored in an immutable log, you can "rewind" the stream and reprocess all of it from the beginning.
Let's say you find a bug in your code that's been producing incorrect results for weeks. In a Kappa world, you don't spin up a separate batch job. You just deploy the fixed code, point it to the start of the data log, and let it run. It will re-process everything, creating a new, corrected output from the same source of truth.
The philosophy behind the Kappa architecture is that a batch process is just a stream process that starts at the beginning of time. With a powerful enough stream processing engine, you can handle both real-time and historical needs in one system.
This unified approach offers huge advantages, especially for teams that need to stay lean and move fast. The benefits are clear:
- One Codebase: Your engineers only need to master one toolset and maintain a single body of code for all data processing.
- Reduced Complexity: There’s no need to merge results from two different layers, making the entire system easier to understand and troubleshoot.
- Architectural Simplicity: The infrastructure is cleaner, with fewer moving parts to monitor, scale, and maintain.
The Major Trade-Off: Cost and Time
Of course, this elegance isn't free. The primary trade-off is the cost and time associated with reprocessing. Replaying a few hours or even a few days of data is usually manageable. But re-running years of historical data from a massive event log can be a slow, computationally expensive undertaking.
Crunching through terabytes or even petabytes of events from scratch requires serious firepower and can take a long time. This makes Kappa a perfect fit for use cases where the total data volume is manageable or the need for a full historical replay is rare.
For businesses that can live with the potential latency and cost of a full reprocessing event, the operational simplicity is a clear win. For those with truly colossal historical archives, the dedicated batch layer of the Lambda architecture might still be the more practical choice.
How to Select the Right Architecture
Alright, let's move from the theoretical to the practical. Choosing the right data pipeline architecture isn’t about picking the “best” one on paper; it's about finding the blueprint that actually fits your business needs, your team's skills, and your budget. This is where you have to get honest about what you truly need versus what sounds impressive.
The first and most important question to ask is about latency. How fast do you need your data-driven answers? If your teams are making strategic decisions based on daily or weekly reports, a classic batch architecture is often more than enough. But if you’re trying to catch fraud as it happens or personalize a customer's experience on your website right now, you’re squarely in streaming territory. There’s no faking it—you need real-time data.
This decision tree gives you a great visual for how latency and the need for fault tolerance can push you toward one architecture over another.
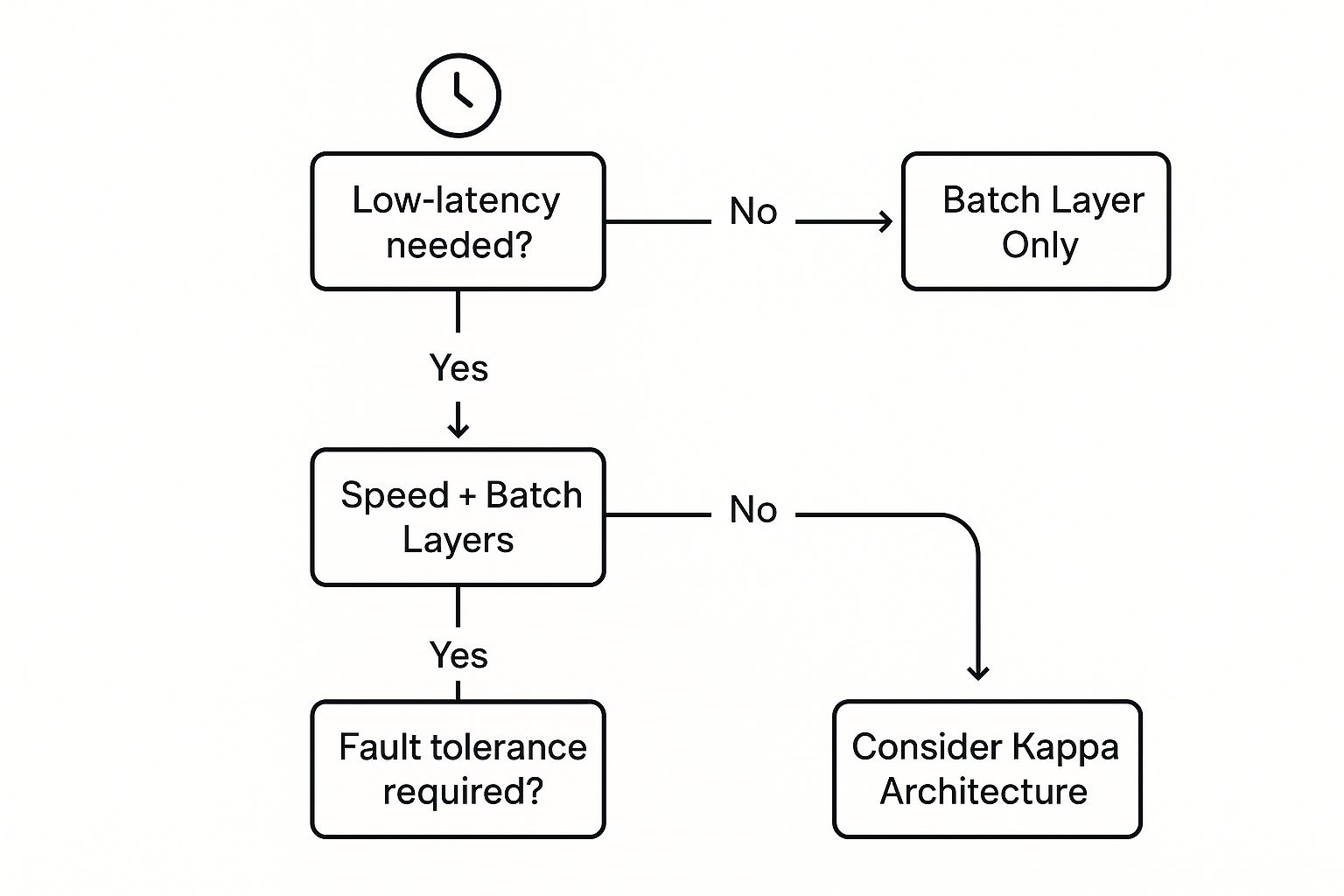
As you can see, when you need both low latency and rock-solid accuracy, something like the Lambda architecture starts to look attractive. For simpler requirements, a more straightforward approach will do the job just fine.
Matching Architecture to Your Needs
Beyond speed, you have to think about complexity. Can your team actually manage the architecture you choose? The Lambda architecture is a perfect example. It's incredibly powerful, giving you both speed and accuracy, but it’s a beast to manage. You're essentially maintaining two separate codebases and systems, which can easily overwhelm a small data engineering team.
On the flip side, a unified streaming approach like the Kappa architecture simplifies things by getting rid of the separate batch layer. The trade-off? If you ever need to reprocess your entire history, you could be looking at a massive, time-consuming, and expensive job, especially if you're dealing with petabytes of data.
To help you decide, here are the core factors to weigh:
- Data Latency: Are you analyzing what happened last week (batch) or what's happening this second (streaming)?
- Team Expertise: Do you have the engineers to juggle parallel batch and speed layers, or is a single, unified pipeline a more realistic goal?
- Data Volume: How much data are we talking about? Reprocessing terabytes of historical data in a pure streaming setup is one thing; reprocessing petabytes is another challenge entirely.
- Budget and Cost: Think beyond the initial setup. Simpler architectures are almost always cheaper to run and maintain over the long haul.
Choosing the right architecture is a balancing act. The following table breaks down the key trade-offs to help you compare your options at a glance.
Comparison of Data Pipeline Architectures
ArchitectureLatencyComplexityUse CaseData HandlingBatchHighLowDaily reporting, historical analysis, BI dashboards.Processes large, scheduled chunks of data.StreamingReal-timeMediumFraud detection, real-time analytics, personalization.Processes data as individual events, continuously.LambdaLow (Hybrid)HighSystems requiring both real-time views and historical accuracy.Maintains separate batch and speed layers.KappaLowMedium-HighReal-time systems where reprocessing is feasible.Treats everything as a stream, unifying the codebase.
Ultimately, this table highlights that there's no single "winner." The best choice depends entirely on which column—latency, complexity, or cost—is most critical for your project.
Thinking About Future Maintenance
Finally, don't forget about the long game: maintenance. Keeping a data pipeline running smoothly is a massive time sink. In fact, some studies show that 60-80% of a data engineer's time is spent just on pipeline upkeep. It's no wonder that by 2025, AI-driven automation is expected to take a huge bite out of that number. As you can discover more insights about the future of ETL on hevodata.com, the industry is moving away from manual firefighting, because human error is still one of the biggest reasons for data downtime.
At the end of the day, the best architecture is the one you can build, maintain, and scale without pulling your hair out. It’s a pragmatic decision that balances the perfect technical solution with the real-world resources you actually have. Always lean toward the simplest model that gets the job done.
Frequently Asked Questions
When you start digging into data pipeline architectures, a few common questions always seem to pop up. Let's tackle them head-on to clear up any confusion and get you on the right track.
What’s the Real Difference Between ETL and ELT?
The easiest way to think about ETL (Extract, Transform, Load) versus ELT (Extract, Load, Transform) is to ask a simple question: When does the data get cleaned up?
With a classic ETL pipeline, the transformation work—all the cleaning, reshaping, and organizing—happens before the data ever touches the data warehouse. You pull the raw data out, process it in a separate staging area, and then load the finished product.
ELT completely flips that script. It yanks the raw data from the source and dumps it straight into a powerful cloud data warehouse like Snowflake or Google BigQuery. All the transformation happens inside the warehouse, taking advantage of its massive parallel processing power. For most modern analytics work, this is a far more flexible and often faster approach.
Where Does Change Data Capture Fit Into All This?
Think of Change Data Capture (CDC) as a super-efficient lookout for your databases. Instead of constantly asking the entire database "Hey, what's new?"—which is slow and a huge drain on resources—CDC just listens for changes as they happen. It taps directly into the database's transaction log.
It’s like getting a real-time notification every time a piece of data changes. The moment a record is added, updated, or deleted, CDC grabs that single event and sends it down the pipeline instantly.
This makes CDC the secret sauce for any serious streaming or real-time data architecture. It lets you keep systems perfectly in sync without bogging down your source databases, powering everything from live dashboards to instant database replication.
What Are the Go-To Tools People Actually Use?
Putting these architectures together means picking the right tools for the job. While the "best" tool always depends on your specific needs, a few major players form the backbone of most modern data stacks.
- Streaming & Messaging: Apache Kafka is the de facto standard for the real-time data backbone. Managed services like Amazon MSK and Confluent Cloud have made it much easier to deploy and manage.
- Processing Frameworks: For crunching the numbers, Apache Spark is the king of large-scale batch processing, while Apache Flink is the go-to for sophisticated stream processing.
- Cloud Data Warehouses: This is where your data ultimately lives. The big three here are Snowflake, Google BigQuery, and Amazon Redshift, each offering incredible scalability for analytics.
Piecing all this together yourself can be a major undertaking. Streamkap was built to solve this exact problem. It’s a unified platform that uses CDC to move data in real-time, letting you ditch slow, painful batch jobs for good. You can build streaming pipelines to destinations like Snowflake and Databricks in a matter of minutes, not months.
See how a modern data architecture should work at https://streamkap.com.