<--- Back to all resources
Master DynamoDB Change Data Capture for Real-Time Insights
Learn how DynamoDB change data capture enables real-time data syncing. Discover best practices and use cases for modern applications.

Enabling Real-Time Data with Change Data Capture
Imagine your database could instantly send you a news alert every time a piece of data changes. That’s the core idea behind DynamoDB Change Data Capture (CDC). Instead of periodically checking your database for updates, CDC transforms it from a static repository into a dynamic, event-driven powerhouse that actively informs you of every change as it happens.

Think of it like subscribing to a magazine. Instead of going to the newsstand every month to see if a new issue is out (querying the database), the publisher sends it directly to your mailbox the moment it’s printed (streaming the change). This stream contains an ordered sequence of all inserts, updates, and deletes, allowing other parts of your application to react immediately.
How It Works: A Simple Overview
This process is fundamental for building modern, responsive applications. It provides a time-ordered sequence of events, ensuring you can process modifications chronologically. This capability has become essential for applications requiring swift reactions to data modifications. For instance, a mobile app can process thousands of updates per second and stream them to another system for immediate metric calculations. You can learn more about how AWS enables near-real-time data processing with this feature.
This real-time flow opens up several powerful capabilities:
- Event-Driven Architectures: Trigger serverless functions or other microservices automatically whenever data is modified.
- Data Synchronization: Keep secondary data stores, like search indexes or analytics databases, perfectly in sync with your primary DynamoDB table.
- Real-Time Analytics: Feed a continuous stream of changes into a data warehouse for up-to-the-second business intelligence.
Key Takeaway: DynamoDB CDC turns your database into an active participant in your architecture. It pushes change notifications to you, eliminating the need for constant, inefficient polling and enabling reactive, real-time workflows.
AWS provides two native tools to support this process: DynamoDB Streams and Amazon Kinesis Data Streams. Each serves as a channel for these data-change events, though they cater to different use cases, which we will explore later. Understanding these tools is the first step toward building powerful data pipelines, a concept you can explore further in our guide on change data capture for streaming ETL.
Why DynamoDB CDC Transforms Your Apps
Let’s move past the technical jargon for a moment. The real magic of DynamoDB change data capture isn’t just about moving data from point A to point B; it’s about what you can build with it. We’re talking about creating applications that are smarter, faster, and can react to things as they happen. This goes well beyond an incremental improvement and can give you a serious competitive advantage.
Think about a classic e-commerce headache: a flash sale. The old way of managing inventory involved constantly checking the database, which is slow and clunky. In the lag time between checks, an item could get sold to five different people after you’ve already run out.
With CDC, every single purchase instantly triggers a “change event.” This event stream updates everything in near real-time, from the stock level on the website to the packing list in the warehouse. The moment that last item sells, it’s marked “out of stock” everywhere. No overselling, no angry customers.
Powering Real-Time Experiences
This same idea works wonders in other areas, too. Imagine a mobile game with a global leaderboard. If you had to query the main database every time someone got a new high score, the whole system would grind to a halt under the load of millions of players. It’s inefficient and expensive.
Instead, with CDC, each new high score is captured as an event. That tiny event can trigger a simple, lightweight serverless function to update a separate leaderboard that’s built for fast reads. The result? A perfectly fluid, real-time leaderboard that feels instantaneous to the player, all without putting any strain on your core game database.
The Real Advantage: DynamoDB CDC flips your architecture on its head. You stop asking the database “what’s new?” over and over again. Instead, the database proactively tells your applications exactly what changed, the second it happens. This allows your systems to react instead of just request.
The infographic below paints a clear picture of this. It shows how a feature like live inventory, driven by CDC, gives a shopper immediate, accurate feedback right in their cart.
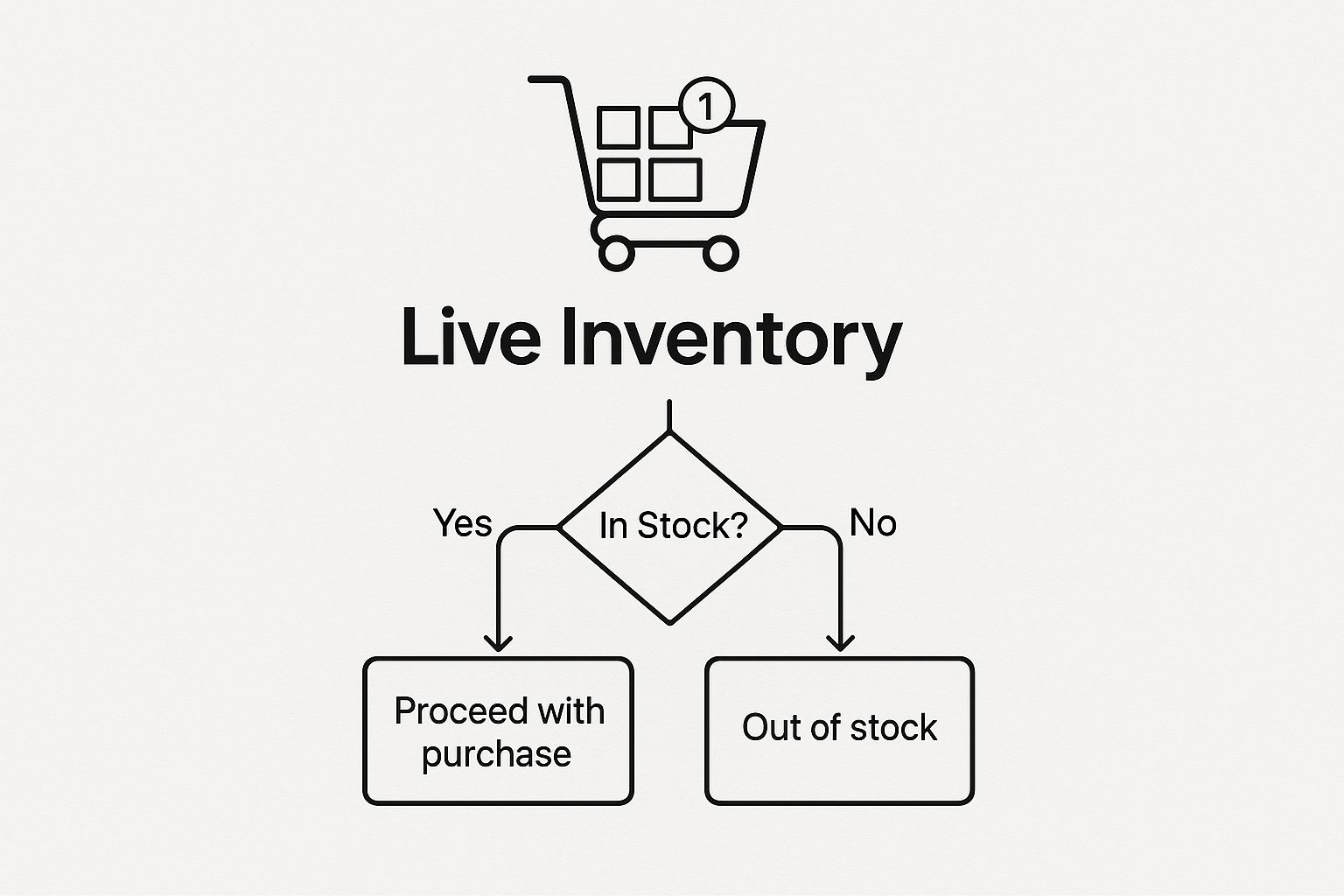
It’s a perfect example of how a behind-the-scenes technology like change data capture directly creates a better, more trustworthy experience for the end-user.
Key Use Cases Enabled by CDC
Once you start thinking in terms of events, you realize just how many problems CDC can solve. Here are a few of the most common applications:
- Real-Time Analytics: You can stream data changes straight into analytics tools like Amazon Redshift or Snowflake. This means your business intelligence dashboards are always showing what’s happening right now, not what happened yesterday.
- Microservices Synchronization: In a complex system with many microservices, keeping data consistent is a huge challenge. With CDC, different services can simply “listen” for changes from other services they depend on, ensuring everyone is always on the same page.
- Data Replication and Auditing: Need a bulletproof audit trail of every change made to your data? CDC provides that automatically. It’s also fantastic for replicating data to other geographic regions for lower latency or for building effective IT disaster recovery plans by keeping a hot backup in sync.
Choosing Your CDC Method: DynamoDB Streams vs. Kinesis
When you decide to implement change data capture in DynamoDB, you’ll quickly hit a fork in the road. AWS gives you two primary, built-in options: DynamoDB Streams and Kinesis Data Streams. This isn’t just a minor technical setting; it’s a foundational architectural decision that will shape how your application scales, what it costs, and how complex it is to manage.
Think of it this way: DynamoDB Streams is like having a dedicated courier service attached directly to your warehouse. It’s fast, incredibly efficient for point-to-point deliveries, and perfectly integrated with your operations. On the other hand, Kinesis is like building a full-scale logistics network. It’s designed for massive volume, long-distance transport, and servicing countless destinations simultaneously. Both move packages, but they’re built for entirely different problems.
Understanding DynamoDB Streams
DynamoDB Streams is the most straightforward path to capturing changes. It’s baked right into DynamoDB, making it the go-to choice for simple, serverless workflows and a fantastic starting point for most projects.
Here’s what you need to know about it:
- 24-Hour Data Retention: The clock is always ticking. Stream records vanish after 24 hours, making it perfect for use cases that need to process data right away, like firing off an AWS Lambda function.
- Simplicity and Low Overhead: Getting started is as easy as flipping a switch in your table settings. DynamoDB handles all the management, so there’s no extra infrastructure to provision or worry about.
- Limited Consumers: A single stream shard can only be processed by two consumers at the same time. This works great for simple, one-to-one integrations but can become a bottleneck if you need to “fan-out” data to many services.
Because of these characteristics, DynamoDB Streams really shines when you just need to react to a change once, and quickly. The classic example is a serverless app that triggers a Lambda to send a welcome email moments after a new user signs up and their record is added to your table.
When to Choose Kinesis Data Streams
When your application’s needs start to outgrow that simple model, it’s time to look at Kinesis Data Streams. Kinesis offers the muscle and flexibility needed for high-throughput, enterprise-level data pipelines. It effectively decouples the change stream from DynamoDB, transforming it into a powerful, standalone data bus that can serve your entire organization.
You should seriously consider Kinesis when your requirements look like this:
- Extended Data Retention: Kinesis can hold onto your data for up to 365 days. This is a major advantage for compliance, auditing, or if you ever need to replay historical events to rebuild a system’s state.
- Multiple Consumers: It’s built for fan-out. Kinesis allows many different applications to read from the same stream independently and at their own pace. This is essential for modern microservices architectures where analytics, notifications, and search indexing services all need to react to the same event.
- High Throughput: Kinesis is engineered to handle an enormous firehose of data, making it the right choice for applications with intense write patterns.
The Core Difference: Your choice really boils down to your application’s architecture. As AWS experts often explain, DynamoDB Streams is perfect for many event-driven tasks, while Kinesis Data Streams provides a far more scalable backbone for complex data pipelines or when multiple applications need to consume the same change events. You can dive deeper into this topic by exploring AWS’s own guide on change data capture strategies.
Before we move on, let’s break down the key differences in a simple table. This should help you visualize which tool fits which job.
DynamoDB Streams vs Kinesis Data Streams for CDC
FeatureDynamoDB StreamsKinesis Data StreamsData Retention24 hours (fixed)Up to 365 days (configurable)Primary Use CaseServerless triggers, simple event processingData lakes, analytics, complex fan-outConsumer Model2 concurrent readers per shardMany concurrent readers (enhanced fan-out)ManagementFully managed by DynamoDBSeparate, provisioned service to manageIntegrationTightly coupled with DynamoDBDecoupled, acts as a central data busComplexityVery low, just enable on the tableHigher, requires managing a Kinesis stream
Ultimately, there’s a trade-off. DynamoDB Streams gives you simplicity for straightforward, single-purpose patterns. Kinesis gives you powerful features like long-term retention and multi-consumer fan-out, but it comes with the added operational overhead and cost of managing a separate AWS service. Your best bet is to choose the tool that fits not just your immediate needs, but where you see your application going in the near future.
Common Architectural Patterns for DynamoDB CDC
It’s one thing to understand the theory behind DynamoDB’s change data capture, but it’s another thing entirely to put it to work solving real-world problems. This is where we get our hands dirty and move from concepts to actual blueprints. By looking at a few proven architectural patterns, you can see exactly how to use DynamoDB CDC to build applications that are more responsive, resilient, and data-aware.
These aren’t just abstract ideas; they’re battle-tested solutions that form the backbone of many modern cloud applications. Each pattern uses the stream of changes from a DynamoDB table as a trigger, kicking off a series of automated actions and creating some seriously powerful workflows. Let’s dig into three of the most common and impactful patterns out there.
Serverless Notification Service
This is often the first pattern developers reach for, mainly because it’s straightforward to set up and delivers immediate value. The idea is simple: you directly connect a DynamoDB Stream to an AWS Lambda function, creating a potent, event-driven trigger.
Think about a user signing up for your service. This action creates a new entry in your Users table. That INSERT event gets captured by DynamoDB Streams and instantly invokes a Lambda function. From there, the function can do almost anything:
- Send a personalized welcome email using Amazon SES.
- Push a notification to a mobile app via Amazon SNS.
- Add the new user’s contact information to a marketing platform.
Key Insight: This pattern brilliantly decouples your core application logic from all the secondary tasks. Your sign-up API only has one job: create the user record. All the notification logic is handled asynchronously and automatically, which boosts both performance and reliability.
Data Replication and Synchronization
Keeping different data stores in sync is a classic, and often painful, engineering challenge. DynamoDB CDC offers a clean, effective solution. A very common use case is maintaining a search index in a service like Amazon OpenSearch Service (which used to be called Elasticsearch).
In this pattern, every change in your DynamoDB table is streamed to a consumer—usually a Lambda function or a Kinesis Data Stream application. That consumer then transforms the data and sends it over to the secondary system. For example, if you UPDATE a product’s description in DynamoDB, that change is almost instantly reflected in the OpenSearch index. This keeps your search results fresh and accurate. This technique is a cornerstone of many reliable data pipeline architectures.
Real-Time Analytics Pipeline
Modern businesses run on timely insights. Waiting for nightly batch jobs to load data into a warehouse just doesn’t cut it anymore. A real-time analytics pipeline built with DynamoDB CDC solves this problem by streaming data changes directly into your analytical environment as they happen.
Here’s a typical flow:
- Capture: DynamoDB Streams or Kinesis Data Streams captures every single item-level change from your operational tables.
- Stream: The change data is then fed into a processing layer. This is often Amazon Kinesis Data Firehose, which is great at batching records for efficiency.
- Load: Finally, Kinesis Data Firehose loads the batched data straight into a destination like Amazon Redshift, Snowflake, or an Amazon S3 data lake.
This kind of architecture gives your analytics platform an up-to-the-minute view of business operations. It enables real-time dashboards, immediate fraud detection, and dynamic reporting—all without bogging down your primary DynamoDB table.
Integrating CDC with Platforms Beyond AWS
Let’s be realistic: while the native AWS ecosystem is powerful, very few data architectures live exclusively within it. Your analytics team might swear by Snowflake, your machine learning models are probably running in Databricks, and your company’s event-streaming backbone could be a self-managed Apache Kafka cluster. This multi-platform reality means you absolutely need a way to get DynamoDB change data capture events out of AWS and into these other systems.
You could build these cross-platform connectors yourself, but that path is paved with engineering headaches. You’d be on the hook for managing complex authentication, dealing with inevitable schema changes, guaranteeing exactly-once delivery, and keeping the whole fragile system running. That’s a huge operational burden that pulls your best engineers away from building the products that actually make you money.
This is exactly why managed CDC platforms have become so popular. They act as a universal translator for your data, making it almost trivial to stream changes from DynamoDB to a whole host of external destinations.
The Role of Managed CDC Connectors
Managed connectors are built to solve this exact problem. Instead of writing custom code to poll a Kinesis stream, reformat the data, and then push it to a third-party API, these tools do all the heavy lifting for you. Think of them as pre-built, industrial-strength data pipelines you can turn on in minutes, not build over months.
Platforms like Streamkap, Debezium, or Confluent offer battle-tested connectors that reliably pipe your DynamoDB change data capture events wherever you need them to go, including destinations like:
- Kafka: Perfect for creating a central, vendor-agnostic event bus for the whole organization.
- Snowflake or BigQuery: To power real-time data warehousing and business intelligence.
- Databricks: For feeding live, operational data directly into your AI and ML training models.
By abstracting away the low-level complexity, these platforms let you focus on what you can do with your data, not the tedious mechanics of moving it. They handle error retries, scaling, and monitoring, which dramatically lowers your total cost of ownership.
This isn’t just a niche requirement; it’s a major trend. Companies everywhere need immediate access to their operational data for things like AI workloads and strict compliance logging. This demand is a key reason why technologies like DynamoDB change data capture are being adopted so quickly. As this need grows, more and more organizations are turning to managed tools to get data out of sources like DynamoDB and into their analytics platforms. You can get a wider view of this trend from statistics on growing CDC adoption at integrate.io.
Ultimately, connecting your DynamoDB CDC stream to platforms outside of AWS turns your data from a siloed asset into a shared, real-time resource that can energize your entire business. To see just how fast this can be done, take a look at our guide on how to stream data from AWS DynamoDB to Databricks using Streamkap in minutes.
Frequently Asked Questions About DynamoDB CDC
Whenever you start working with a new technology like DynamoDB’s change data capture, a few questions always pop up. It’s smart to tackle these common concerns early on, as it helps you build a more reliable system right from the get-go.
Let’s walk through some of the things developers often ask when they first dip their toes into DynamoDB Streams.
What Is the Performance Impact of Enabling Streams?
This is usually the first question on everyone’s mind: “Will turning on DynamoDB Streams slow down my table?”
The short answer is no, not really. The entire change capture process runs asynchronously in the background. This means it doesn’t get in the way of your application’s primary read and write requests, so you won’t see any added latency there.
While there’s a tiny bit of extra write throughput used to record the changes, it’s almost always negligible. AWS designed this to be incredibly efficient so your application’s performance stays rock-solid.
How Do I Handle Errors and Retries?
Error handling is a huge deal, especially when you’re using AWS Lambda to process events from the stream. What happens if your function throws an error?
By default, Lambda will keep trying to process the same batch of records over and over until it either succeeds or the data expires from the stream (which happens after 24 hours). This can be a problem, as a single “poison pill” message could block your entire stream.
The best way to handle this is to set up a Dead-Letter Queue (DLQ). A DLQ is just a destination—usually an SQS queue or an SNS topic—where Lambda sends an event after it has failed a certain number of times. This gets the bad message out of the way so processing can continue, and you can investigate the failure separately.
Can I Get Both Before and After Images of an Item?
Absolutely, and this is where DynamoDB change data capture really shines. When you enable a stream, you get to choose exactly what information it captures for every change.
You have four “Stream view type” options:
- KEYS_ONLY: Just the primary key of the item that changed.
- NEW_IMAGE: The full item as it looks after the change.
- OLD_IMAGE: The full item as it looked before the change.
- NEW_AND_OLD_IMAGES: Both the before and after versions of the item.
Choosing NEW_AND_OLD_IMAGES is valuable for so many use cases. It lets you see precisely what changed, which is perfect for creating detailed audit trails or calculating deltas between states.
Ready to build a truly powerful real-time data pipeline without the usual headaches? Streamkap offers an enterprise-ready solution for DynamoDB CDC, letting you connect to destinations like Snowflake, Databricks, and BigQuery in minutes. Start building your real-time pipeline today.