Data Lake House vs Data Warehouse: Key Differences Explained
Discover the core differences between data lake house vs data warehouse architectures to choose the best data strategy for your business. Learn more!

The simplest way to think about a data lakehouse vs a data warehouse is to look at what they’re built for. A traditional data warehouse is your go-to for structured data and established business intelligence reporting. A data lakehouse, on the other hand, is a hybrid, blending the structure of a warehouse with the raw flexibility of a data lake. This lets you handle everything—structured, semi-structured, and unstructured data—for both BI and machine learning on one platform, effectively tearing down the walls between different data systems.
Choosing Your Data Architecture Foundation

Picking between a data lakehouse and a data warehouse isn’t just a technical decision anymore; it’s a strategic one that shapes your company’s ability to innovate. The game changed with the explosion of data from places like IoT sensors, social media, and application event logs.
For decades, data warehouses have been the gold standard for structured analytics. They are powerful and reliable, but they weren’t designed for the messy, unpredictable world of unstructured data. This mismatch poses a real problem for any organization wanting to dive into advanced analytics and AI.
The Rise of Unified Platforms
This gap is exactly why the data lakehouse model has gained so much traction. It was built to solve modern data problems by creating a single, reliable source for all data types, not just the clean, structured kind. The market is clearly voting with its dollars.
The global data lakehouse market is already valued at $11.35 billion and is expected to rocket to $74 billion by 2033. This isn’t just slow growth; it’s a massive industry shift. You can dig into the numbers in the full market analysis from Grand View Research.
A data lakehouse isn’t just a technical upgrade; it’s a strategic move to future-proof your data strategy. It enables organizations to run traditional BI reporting and advanced machine learning models on the same data, eliminating redundant data pipelines and reducing complexity.
To help you decide which path is right for your goals, let’s break down the core differences.
Data Lakehouse vs Data Warehouse At a Glance
The following table gives you a quick, high-level summary of how these two architectures stack up on the fundamentals.
AttributeData WarehouseData LakehousePrimary Data TypesStructured (e.g., SQL tables)Structured, semi-structured, unstructuredSchema ModelSchema-on-write (rigid)Schema-on-read (flexible)Ideal WorkloadsBusiness Intelligence (BI), reportingBI, AI, machine learning, streamingCost StructureTightly coupled compute & storageDecoupled compute & storage (lower cost)Data FreshnessTypically batch-loadedSupports real-time and batch
As you can see, the choice isn’t about which one is “better” but which one is the right fit for the job you need to do.
Understanding the Core Architectural Philosophies
When you get down to it, the real difference between a data lakehouse and a data warehouse isn’t just technology—it’s their entire philosophy on how data should be handled. These core principles shape everything from how data gets into the system to how it’s stored and used, which in turn affects performance, flexibility, and cost. Getting a handle on these foundational blueprints is the first step to figuring out which one actually fits what your business needs.
A traditional data warehouse is built on a schema-on-write model. I like to think of it as a meticulously organized library. Before a new book (your data) can be placed on a shelf, it has to be thoroughly cleaned, structured, and cataloged to fit a predefined system.
This means heavy-duty ETL (Extract, Transform, Load) pipelines do all the hard work of cleaning and formatting data before it’s allowed into the warehouse. The big payoff here is predictable speed and reliability. When everything is already structured, business intelligence (BI) tools can crank out reports and dashboards with incredible consistency and performance.
The Warehouse Approach: Built for Structured BI
The schema-on-write model is all about stability. When an analyst needs to pull sales figures for the last quarter, they know the results will be accurate and consistently formatted because that structure was locked in from the start. For organizations that live and die by high-speed, reliable reporting on known business metrics, this rigidity is a feature, not a bug.
But that strength is also its biggest weakness. What happens when you want to analyze something new and messy, like social media chatter or raw data from IoT sensors? You have to stop, design a new schema, and then build a whole new pipeline to force that data into the warehouse’s rigid framework. That process is often slow and expensive, which can kill agility and discourage any kind of exploratory analysis.
Key Takeaway: The data warehouse puts order first. It’s fantastic at answering known questions quickly and reliably, which is why it has been the foundation of corporate BI for decades.
The Lakehouse Approach: Flexibility for the Modern Data Stack
The data lakehouse flips that idea on its head with a schema-on-read philosophy. This is more like a massive digital archive that takes in data in whatever format it comes in—structured tables, raw video, JSON logs, you name it—and stores it all in its native form on cheap object storage.
Instead of forcing a structure on data as it arrives, a lakehouse applies the schema only when someone actually queries or reads the data. This gives you enormous flexibility. Data scientists and ML engineers can get their hands on raw, unfiltered data to train their models without being boxed in by a predefined structure. You can dive deeper into how this model compares to others in this overview of data pipeline architectures.
So, how does it maintain order? A clever metadata layer, powered by open table formats like Apache Iceberg or Delta Lake, sits on top of all the raw files. This layer brings classic warehouse features—like ACID transactions, data versioning, and governance—directly to the data lake environment.
This hybrid approach solves a problem that has plagued data teams for years: data silos. Companies used to need a data warehouse for BI and a completely separate data lake for machine learning. This meant duplicated data, soaring costs, and gnarly pipelines just to shuttle information back and forth. The lakehouse brings both of those worlds together on a single copy of the data.
An e-commerce company, for example, can use the same platform to:
- Run standard BI reports on its structured sales data.
- Train a fraud detection model on semi-structured, real-time transaction streams.
- Analyze customer sentiment by processing unstructured product reviews.
This unified design is a game-changer. It allows organizations to support both their established analytics and their forward-looking AI projects from one cost-effective source of truth.
A Detailed Comparison of Key Capabilities
Once you get past the high-level concepts, the real differences between a data lakehouse and a data warehouse become clear when you look at their core capabilities. The architecture you choose will directly shape your team’s agility, how well specific tasks perform, and what your long-term costs look like. A side-by-side breakdown shows exactly how each one handles the practical demands of a modern business.
The chart below gives a great visual summary of the core differences in schema, data flexibility, and which workloads fit each architecture best.
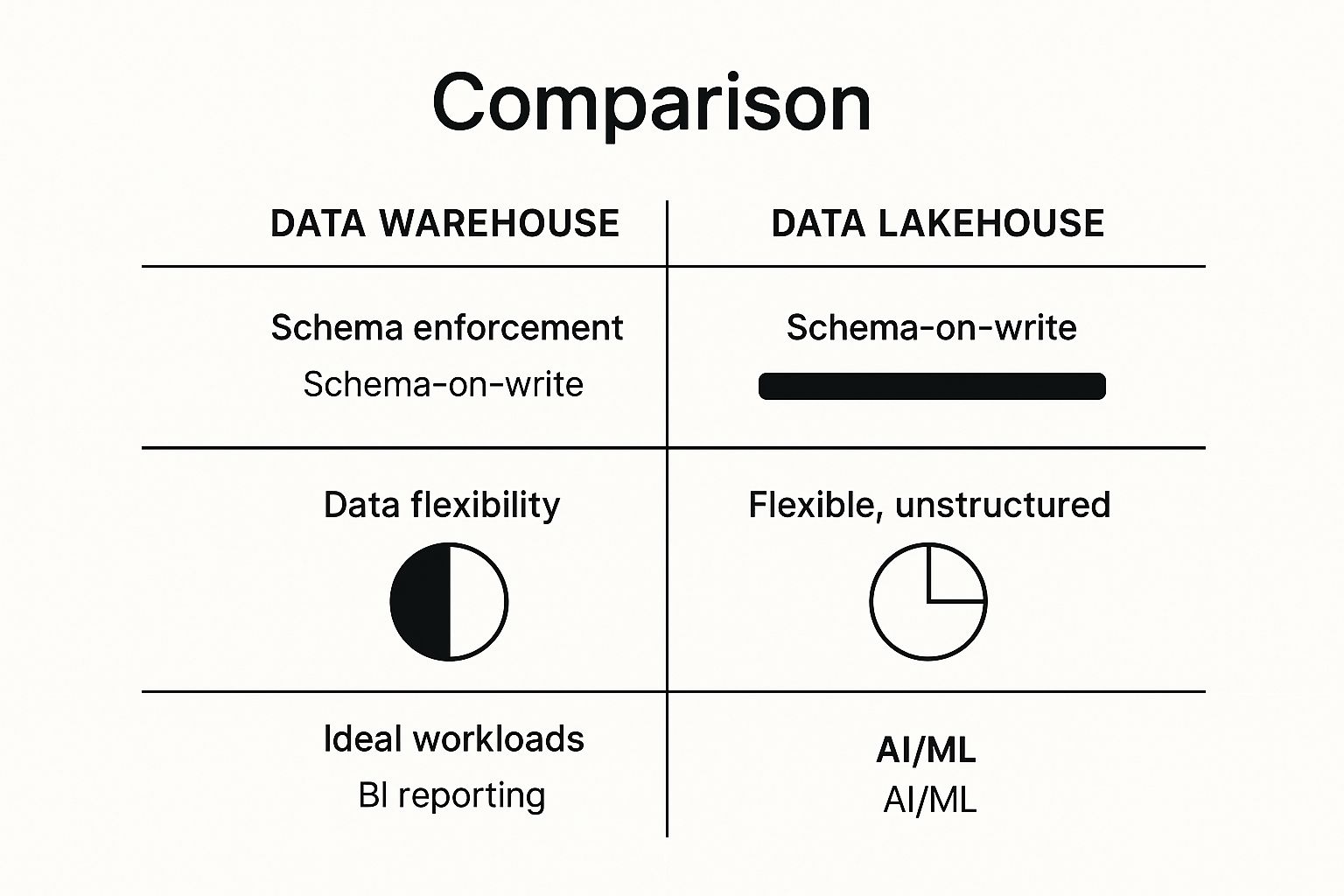
As you can see, it boils down to a fundamental trade-off. The warehouse provides a rigid, reliable structure perfect for BI, while the lakehouse offers the flexibility to handle both BI and emerging AI workloads.
Data Structure and Agility
The most telling difference is how each system approaches data structure. A traditional data warehouse is built on a strict schema-on-write model. Before any data can be stored, it has to be cleaned, transformed, and forced into a predefined structure. This guarantees consistency, which is exactly what you want for BI reporting.
But that rigidity comes at a price: agility. If you need to add a new data source or answer a new analytical question, your data engineers have to design and build a new ETL pipeline. That’s a process that can easily take weeks, sometimes months.
The data lakehouse flips this around with a schema-on-read approach. It ingests raw data in any format—structured, semi-structured, or unstructured—and only applies a schema when someone actually queries the data. This is a game-changer for teams doing exploratory analytics or ML experiments who can’t afford to be boxed in by a fixed structure.
The core value of a lakehouse is agility. By separating storage from schema, it gives teams the freedom to work with diverse data on their own terms, which massively shrinks the time it takes to get from raw data to real insight.
Performance for Different Workloads
Performance isn’t a simple metric; it’s entirely dependent on what you’re trying to do. Data warehouses are purpose-built machines, finely tuned for one primary job: running fast, interactive SQL queries for business intelligence. Their tightly coupled compute and storage architecture is designed to give you sub-second responses for dashboards and reports.
This specialized performance, however, creates limitations. Warehouses often choke on the sheer scale and variety of data required for machine learning and real-time streaming analytics. Their proprietary data formats can also lead to vendor lock-in, making it a headache to use the broad ecosystem of open-source tools your data scientists love.
On the other hand, the data lakehouse, built on open formats like Parquet and ORC, offers much more versatile performance. It can absolutely deliver BI performance that rivals traditional warehouses, but its real power is in handling a mix of workloads on a single copy of data. Data scientists can use Python or R to work on the exact same data that BI analysts are querying with SQL. No more data silos, and no more redundant data copies.
Feature-by-Feature Architectural Breakdown
To truly grasp the technical nuances, it helps to break down the key features of each architecture. The table below provides a direct comparison of how traditional warehouses and modern lakehouses stack up on the most critical components.
FeatureTraditional Data WarehouseModern Data LakehouseCore PhilosophyCentralized, structured repository for BI and reporting.Unified platform for BI, AI, and streaming on a single copy of data.Schema EnforcementSchema-on-write: Rigid schema defined before data loading.Schema-on-read: Flexible schema applied during query time.Supported Data TypesPrimarily structured data.Structured, semi-structured, and unstructured data (e.g., text, images, video).Primary Use CasesBusiness Intelligence (BI), historical reporting, dashboards.BI, data science, machine learning, real-time analytics.Storage LayerProprietary, optimized formats.Open-standard formats (Parquet, ORC, Avro) on low-cost object storage (e.g., S3).Compute & StorageTightly coupled, often leading to higher costs.Decoupled, allowing independent scaling and better cost control.Data ReliabilityStrong ACID transaction guarantees built-in.ACID transactions provided by open table formats like Delta Lake, Iceberg, and Hudi.Tooling EcosystemLimited to vendor-specific or SQL-based tools.Broad support for diverse tools (SQL, Python, R, Spark) from multiple vendors.
This side-by-side view makes it clear: the lakehouse isn’t just a data lake with a new name. It’s a fundamental architectural shift designed for a much broader set of modern data challenges.
Cost and Scalability
Cost is frequently the deciding factor, and this is where the architectural differences really hit the bottom line. Data warehouses have a history of bundling compute and storage costs. This often means you’re paying for expensive processing power even when you’re just storing data, causing costs to balloon as your data volume grows.
The data lakehouse architecture was designed to fix this by fundamentally separating compute and storage. It leverages low-cost object storage (like Amazon S3 or Google Cloud Storage) for the data itself, and you only spin up and pay for compute resources when you need to query or process something. This decoupled model is dramatically more cost-effective, especially when you’re dealing with petabyte-scale data.
This economic advantage is a huge driver behind its adoption. The data lakehouse market is projected to be valued at $14.2 billion, while the data warehouse market is expected to reach $37.4 billion, though it’s growing at a slower annual pace. While the cloud is standard for both, lakehouse platforms are increasingly the go-to for advanced analytics workloads that would be cost-prohibitive on a traditional warehouse.
Data Governance and Reliability
For years, the killer feature of the data warehouse was its rock-solid support for ACID transactions (Atomicity, Consistency, Isolation, Durability), which are essential for guaranteeing data integrity. Data lakes, in contrast, earned a reputation as unreliable “data swamps” precisely because they lacked these guarantees.
That distinction has almost entirely disappeared. The rise of open table formats has brought warehouse-grade reliability and governance directly to the data lakehouse.
- Delta Lake: This open-source storage layer adds ACID transactions, scalable metadata handling, and time travel (data versioning) to data lakes.
- Apache Iceberg: Another powerhouse table format that delivers reliable transactions, safe schema evolution, and performance boosts for massive analytic datasets. Our comprehensive https://streamkap.com/blog/apache-iceberg-guide digs much deeper into its capabilities.
- Apache Hudi: This format is focused on providing fast upserts and incremental data processing, making it ideal for streaming workloads.
These technologies ensure that data in a lakehouse is every bit as reliable and well-governed as data in a warehouse. Of course, technology alone isn’t enough; you still need to follow essential database management best practices to keep your data clean and secure, no matter the architecture. This evolution has leveled the playing field, making the data lakehouse a powerful—and often better—option for a huge range of use cases.
Exploring Real-World Use Cases
All the architectural theory in the world doesn’t mean much until you see how it plays out in practice. This is where the rubber meets the road in the data lakehouse vs. data warehouse debate. The platform you choose has a direct, tangible impact on what your business can actually do with its data.
Looking at specific use cases is the best way to see the distinct strengths of each architecture and figure out which one really lines up with your goals.

When to Use a Data Warehouse
Data warehouses have been the bedrock of business intelligence for decades for a reason. They absolutely excel in situations where data integrity, predictable structure, and lightning-fast query performance are paramount. Their schema-on-write approach is all about reliability, making them the gold standard for core BI.
Think of these classic scenarios where a data warehouse is the clear winner:
- Financial Reporting: A public company preparing quarterly statements for regulators can’t afford any ambiguity. The data has to be structured, validated, and completely auditable. A data warehouse enforces the strict governance needed to make sure every single number is accurate and defensible.
- Executive Dashboards: Your CEO wants a daily “state of the business” dashboard showing KPIs like revenue, sales, and customer acquisition cost. A warehouse is built to power these dashboards with sub-second responses, pulling trusted metrics from structured systems like your CRM and ERP.
- Retail Sales Analytics: A large retail chain needs to analyze historical sales to spot trends and manage inventory across hundreds of locations. The warehouse’s rigid structure ensures that sales data is standardized, enabling quick and reliable analysis for merchandising decisions.
In these cases, the business questions are well-defined, and the data is highly structured. The main objective is to get fast, trustworthy answers to run the business. For these needs, a data warehouse is still an incredibly powerful and dependable choice.
When to Use a Data Lakehouse
The data lakehouse comes into its own where flexibility, massive scale, and a mix of data types are the name of the game. It was built for a world where you need to run traditional BI right alongside forward-looking AI and machine learning work, often using the very same data.
A data lakehouse is a natural fit for these kinds of modern challenges:
- Predictive Maintenance: A manufacturing company is swimming in terabytes of unstructured sensor data from its machinery. Data scientists can land all that IoT data in a lakehouse and use it to build machine learning models that predict equipment failures before they happen, potentially saving millions.
- Real-Time Fraud Detection: An e-commerce site needs to spot and block fraudulent transactions the instant they occur. A lakehouse can ingest and process streaming transaction data, analyzing it alongside historical customer patterns to power sophisticated fraud detection algorithms. This is a classic application of real-time data streaming principles.
- Customer 360 Initiatives: Your marketing team wants a complete picture of every customer. That means combining structured purchase history, semi-structured website clickstreams, and even unstructured social media comments. A lakehouse gives them a single place to store and analyze all of it together.
Trying to tackle these scenarios in a traditional warehouse would be clunky at best, and often downright impossible.
The real magic of a data lakehouse is its ability to support both BI and AI on a single copy of your data. This kills the need for complex, expensive ETL pipelines that shuffle data between a separate warehouse and a data lake.
By breaking down those silos, a lakehouse lets a BI analyst query sales figures with SQL while a data scientist uses Python to build a recommendation engine on the exact same dataset. This unified model doesn’t just cut down on architectural complexity and cost—it speeds up innovation by getting more data into the hands of more people. This is a crucial differentiator in the data lakehouse vs data warehouse comparison for any company building a data strategy for the future.
How to Choose the Right Data Architecture

Choosing between a data lakehouse and a data warehouse isn’t just a technical exercise. It’s a strategic business decision that impacts everything from daily operations to long-term innovation. The best fit really depends on your specific goals, the kind of data you work with, and where you see your company heading.
To get it right, you have to start by asking the right questions. Your answers will naturally point you in the direction of one architecture over the other.
Key Strategic Questions to Ask
Before you commit to a platform, get your team together and hash out the answers to a few core questions. This clarity will tell you whether the rigid structure of a warehouse or the open flexibility of a lakehouse makes more sense for your organization.
- What data types drive your business? If your world revolves around clean, structured data from transactional systems like ERPs and CRMs, a data warehouse is a classic, powerful choice. But if you’re trying to pull insights from a messy mix of structured sales figures, semi-structured clickstream data, and unstructured social media comments, the lakehouse is designed for that variety.
- What are your primary workloads? Are you mainly building executive dashboards and running historical BI reports? A data warehouse is optimized for precisely that. However, if your roadmap includes predictive analytics, real-time fraud detection, or training machine learning models, a lakehouse lets you handle all those different jobs on a single, unified platform.
- How critical are cost and scalability? If you need to separate storage from compute to control costs as you scale into petabytes, the lakehouse architecture is the clear winner. Its foundation in low-cost object storage gives it a major economic edge over the tightly coupled, and often more expensive, design of a traditional data warehouse.
Making the Final Decision
At the end of the day, the decision boils down to your most important use cases. A finance team that needs flawless, high-speed reports for regulatory compliance will lean heavily on the proven reliability of a data warehouse. Its strict schema enforcement guarantees the data integrity needed for those mission-critical tasks.
On the other hand, a company looking to build its next great product with predictive analytics on diverse datasets will find the data lakehouse a much better fit. It provides the flexibility to experiment and the scale to grow without being boxed in by a rigid structure defined years ago.
The decision is less about one replacing the other and more about picking the right tool for the job. Many organizations actually run hybrid models, using both architectures for different business units. This creates a powerful, future-proof data ecosystem.
While the data lakehouse model is gaining ground fast, the traditional data warehousing market is still massive. It was valued at $34.9 billion and is projected to hit $126.8 billion by 2037. North America currently accounts for about 45% of this market, largely driven by a continued need for classic BI. Read more about data warehousing market trends to see the full picture.
Frequently Asked Questions
People often have the same key questions when they start digging into the data lakehouse vs. data warehouse debate. Getting straight answers is the only way to make a smart architectural choice that actually fits what your business needs.
Can a Data Lakehouse Completely Replace a Data Warehouse?
Not necessarily, and it’s really a question of trade-offs. A lakehouse is built to be a jack-of-all-trades, handling everything from standard BI reports to complex AI models. But if your business lives and dies by extremely high-performance, mission-critical BI, a dedicated data warehouse might still have the edge for that one specific job.
For most companies, though, the goal is to break down data silos and create a single source of truth. In that scenario, a lakehouse offers a powerful, flexible, and usually more affordable platform that gets the job done without the complexity of managing multiple systems.
The choice isn’t about total replacement but about finding the right balance. A lakehouse excels at versatility, whereas a warehouse is a specialist in high-performance, structured BI queries.
What Are the Biggest Migration Challenges?
Moving from a well-established data warehouse to a lakehouse is a heavy lift that goes way beyond just copying data. You’re looking at some serious technical hurdles. Think complex schema conversions and the sheer logistics of migrating massive datasets—it all demands meticulous planning.
But the technical side is only half the battle. You also have a huge organizational challenge. Your teams need to get up to speed on new tools, open-source standards like Apache Iceberg, and an entirely different way of thinking about data architecture. This cultural shift is often just as demanding as the technical work.
How Does a Data Lake Fit Into This Comparison?
Think of a data lakehouse as the logical evolution of the data lake. A classic data lake gave us cheap, flexible storage for all our raw data, but it always struggled with the reliability and performance needed for serious business analytics. It was more of a data swamp.
The lakehouse architecture builds directly on that low-cost storage foundation. It adds a crucial metadata and governance layer on top, bringing in critical features like ACID transactions, schema enforcement, and data versioning. This is what lets it combine the massive scale of a data lake with the reliability and structure of a data warehouse.
Ready to break down data silos and enable real-time analytics in your data lakehouse or warehouse? Streamkap provides a fully-managed platform for streaming data with sub-second latency. See how our Change Data Capture (CDC) connectors can transform your data pipelines.
Related resources
Kafka Consumer Lag: Causes, Debugging, and Fixes
Consumer lag is the most common Kafka operational issue. Learn what causes it, how to measure it, and practical strategies to bring it under control.
Kafka on Kubernetes: Real-World Lessons
Running Kafka on Kubernetes sounds like a good idea until you hit storage, networking, and operational challenges. Here's what teams learn the hard way and how to avoid the common pitfalls.
Backpressure in Stream Processing: What It Is and How to Handle It
Learn what backpressure means in streaming pipelines, how to detect it, and practical strategies for handling it in Kafka, Flink, and CDC pipelines without losing data.