Why Apache Iceberg? A Guide to Real-Time Data Lakes in 2025
In 2025, data engineering requires scalable solutions for real-time data lakes. Apache Iceberg, a leading open table format, excels with ACID transactions, schema evolution, and Change Data Capture (CDC) support. This guide, crafted for data engineers, explores the evolution of data storage, Apache Iceberg’s core features, its rising popularity, adoption challenges, and how Streamkap simplifies real-time data lake deployment.
A Quick Introduction to Iceberg
If you’re coming into the world of “open table formats” for the first time, you might feel a bit lost. After all, we’re used to talking about relational databases, data lakes, and perhaps columnar file formats like Parquet. But something magical happens when you combine the freedom and power of a data lake with the structure and reliability of a relational database.
And Apache Iceberg is the open table format that lets you do just that. It’s an open-source way to manage tables—yes, like proper SQL tables—right on top of your cloud storage (think S3, Azure Blob, or your favorite big file lake).
But before we get too deep into Iceberg itself, let’s hop into our data time machine.
The Era of the Data Warehouse
Let’s start around 35 to 40 years ago—that’s going all the way back to the days before the internet as we know it, when the data warehouse ruled the land.
What was a data warehouse?
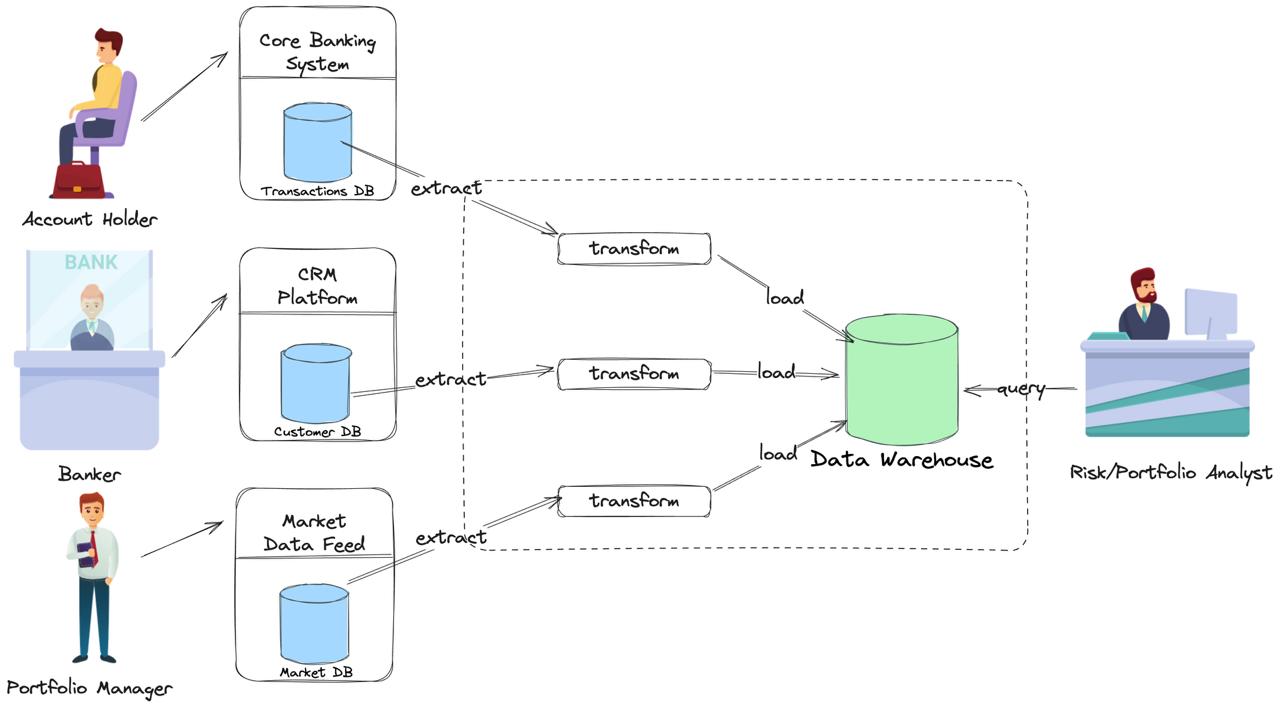
In short, it was a very large database optimized for analytics. It took data out of all the smaller, operational (OLTP) databases—often your classic relational databases spread throughout an enterprise—and brought everything together for unified reporting and analysis.
Why don’t query OLTP directly?- Data lives in silos. The facts you need are usually split across systems (core banking, CRM, market data). Stitching them together in one query is fragile and slow.
- Schemas are OLTP-optimized. Highly normalized schemas, narrow indexes, and write-optimized layouts are great for transactions and terrible for wide scans and star-style joins.
- Expensive queries hurt production. Long, CPU/IO-heavy analytics can contend with critical customer traffic and degrade SLAs.
- Access boundaries exist. OLTP systems often sit on restricted networks; direct analyst access may be blocked for security and compliance.
How did data get in data warehouse? Through the magic (and pain) of ETL:
- Extract- Transform- Load
Each night, the system would extract data from your sources (transactions DB, customer DB and Market DB), transform it to fit a target schema, and load it into the data warehouse. Batch processing was the name of the game. Data became available for reports and queries the next day.
The Shift to Data Lakes
Warehouses were fantastic—until the firehose opened. As web, mobile, and streaming sources came online, teams needed to land raw, high-volume, mixed-format data including semi-structured and unstructured data quickly. Row-oriented, schema-on-write warehouses started to feel tight. The industry response was the data lake: ingest first, model later—swap nightly ETL for ELT on elastic, low-cost object storage. At first, data lakes were all built on Hadoop — think of it as a giant, distributed file system.
How the finance example evolved
In the warehouse era, our bank’s analytics looked like this: nightly ETL pulled transactions, customer updates, and market prices into a star schema for next-day reporting. It worked—until analysts asked for intraday risk, tick-level backtests, fraud detection on streaming events, and ML features built from many domains. At that point, we needed to ingest more (orders, quotes, trades, news, app telemetry, KYC documents), faster (real-time or micro-batches), and in richer forms (CSV, JSON, images, logs). The lake made that possible by landing raw data first and transforming when ready.
The philosophy shifted
- Don’t stress so much about schema upfront
- Ingest everything, transform later
- Work with bigger, messier, unstructured data
Pipelines modernized: CDC from OLTP to Kafka; ELT into the lake’s raw zone; curated “silver/gold” models for risk, compliance, and portfolio analytics.
Workloads diversified:
- Intraday risk & P&L: run joins across trades, positions, and live prices.
- Fraud/AML: score account events and device signals as they arrive.
- Backtesting: replay years of tick data without re-shaping warehouse tables.
Modern data lakes swapped Hadoop for cloud storage like S3, but the idea was the same: throw everything in, then figure it out later.
Why Do We Need Open Table Formats?
The new world of data lakes was a breath of fresh air in terms of flexibility and scale. But as with everything, new problems popped up:
Where’s my schema? Maybe it sounded nice to ignore schema, but eventually, when you want to run real SQL queries or do analytics, you do need structure.
How do I keep things consistent? You might have pieces of a table scattered across dozens of files in a bucket. What’s a transaction? What’s an update? It was tough to have a consistent, atomic view of your data.
Where’s the tooling? Data engineering teams started to miss the convenience and reliability of good old relational databases.
Open table formats, like Apache Iceberg (and its cousins, like Delta Lake and Hudi), were invented to bridge the gap. At the very least, they give us:
- Schema management, so you can know and enforce the structure of your data
- Transactional updates, for reliability and correctness
- Consistent views, snapshots, and more
Apache Iceberg And The Rise of Data Lakehouses
Open table formats let teams keep lake flexibility while regaining database-style guarantees for analytics. This combination gave rise to the new data lakehouse pattern.
- Unified Data Lakes and Warehouses: Apache Iceberg’s ACID transactions enable atomic updates across batch and streaming workloads, consolidating data lakes and warehouses.
- Cloud-Native Design: Optimized for cloud storage like S3, ADLS, and GCS, Apache Iceberg minimizes query latency with metadata pruning, cutting scan times by 50% for large datasets.
- Open Ecosystem: As a vendor-neutral project, Apache Iceberg integrates with Flink, Kafka, Trino and more.
- Streaming-friendly ingestion: CDC streams (e.g., via Kafka/Flink/Debezium) land as upserts/merges into Iceberg tables.
- Real-Time Analytics with CDC: Apache Iceberg’s Change Data Capture (CDC) and streaming support (e.g., Kafka, Flink) enable sub-second latency with the benefits of data residing in S3.
- Flexibility: Hidden partitioning and compaction adapt to evolving needs. Unlike Hive, Apache Iceberg’s metadata-driven partitioning supports seamless evolution (e.g., daily to hourly), with compaction reducing storage costs by 30%. Learn more at Iceberg Maintenance Docs.
Back to our bank: CDC from OLTP systems feeds Iceberg tables for trades, balances, and reference data. Analysts run intraday risk on consistent snapshots; compliance uses time travel for audits; data science builds features from one governed source—without copying data into a separate warehouse. That’s the lakehouse in practice: lake scale with table guarantees.
Examples in the wild
- Netflix: An incremental‑processing pattern built on Iceberg metadata cut a multi‑stage pipeline’s cost to ~10% of the original (re:Invent slide deck; talk coverage).[1][2]
- Airbnb: Migrating large event ingestion to Spark 3 + Iceberg delivered >50% compute savings and ~40% lower job elapsed time; Iceberg-based compaction and partition‑spec changes yielded additional efficiency wins (engineering blog).[3]
- Adobe: Reported read‑path gains via vectorized reads, nested predicate pushdown, and improved manifest tooling, plus near‑constant‑time planning on large tables (engineering write‑ups).[4][5]
- Apple: Public talks confirm broad internal use and active contribution to Iceberg (conference sessions/keynotes).[6][7]
- Expedia Group: Spark + Iceberg patterns such as storage‑partitioned joins showed ~45–70% execution‑time/cost savings on join‑heavy workloads (engineering article with scenarios and configs).[8]
Approach to Adopting Apache Iceberg
Iceberg is gaining traction, but adoption often stalls due to:
- Migration complexity: Rewriting PB-scale datasets and pipelines is expensive.
- Ecosystem maturity: Gaps in legacy BI connectors; new streaming/CDC patterns to learn.
- Performance trade-offs: Small files and growing metadata require compaction, which consumes compute.
- Organizational inertia: Stable legacy systems and risk aversion slow change.
How to startStart simple: dual-write (aka shadow-write).
Write to your existing lake/warehouse and to Iceberg in parallel. This lets you:
- Validate schemas, row counts, and query results against a known-good system—without downtime.
- Prove performance and cost on production traffic.
- Establish compaction, clustering, and partition-evolution policies before cutover.
Operational checklist- Data parity: Row/aggregate diffs, late-arrival handling, CDC merge semantics.
- Performance hygiene: Target file sizes, compaction cadence, clustering/sorting.
- Governance: Schema/partition evolution rules; retention and time-travel windows.
- Cutover plan: Backfill horizon, workload-by-workload read switch, rollback triggers.
When confidence is high, promote selected workloads to read from Iceberg and gradually retire the dual target.
Streamkap and Apache Iceberg: Simplified Real-Time Deployment
With Streamkap’s managed Iceberg connector, adding Iceberg is just a few minutes work. Streamkap enhances Apache Iceberg deployment with automated maintenance and dual-write pipelines, delivering sub-second latency and SOC2 Type 2 compliance with a serverless or BYOC deployment.
Key Benefits- Zero Maintenance: Automates compaction, snapshot expiration, and metadata cleanup.
- Effortless Dual Writes: Configures legacy and Iceberg pipelines via UI.
- Real-Time CDC and Streaming: Supports MoR and equality deletes.
- Scalability and Cost: <100ms latency for 1M events/sec, 3x cost savings vs. ETL.
- Portability: Iceberg’s open format avoids lock-in.
Conclusion
Apache Iceberg is the missing layer that turned “dump it in the lake” into “query reliable tables.” It brings back the guarantees we loved in warehouses—ACID, schema control, and consistent views—without giving up cloud-scale storage and engine choice.
What Iceberg buys you now:- Atomic snapshots & time travel: reproducible analytics, safe backfills, and easy audits.
- Schema & partition evolution: change columns or switch partitioning (e.g., daily → hourly) without table rewrites.
- Streaming-native writes: upserts, merges, MoR/equality deletes for CDC.
- Smarter scans: metadata pruning and hidden partitioning cut unnecessary IO.
- Open interoperability: Spark/Trino/Flink/Kafka today; no vendor lock-in tomorrow.
Start with one well-scoped table, prove correctness and cost, then iterate. If you want to skip the plumbing, tools like Streamkap’s managed Iceberg connector can automate dual writes and table maintenance—but the star of this story is Iceberg itself: open tables, database-grade guarantees, lake-scale economics.
Where to next?
- Tutorial: MySQL → Iceberg – Enable CDC in MySQL, connect it in Streamkap, and stream changes directly into Iceberg tables.
- FAQ Apache Iceberg
- Documentation: Explore the official guides to master every detail of your Streamkap–Iceberg pipeline.
- Sign up: Create your Streamkap account now and start moving data into Iceberg in minutes.
- Netflix @ AWS re:Invent 2024, Efficient incremental processing with Apache Iceberg at Netflix (PDF): https://reinvent.awsevents.com/content/dam/reinvent/2024/slides/nfx/NFX303_Efficient-incremental-processing-with-Apache-Iceberg-at-Netflix.pdf ↩︎
- InfoQ coverage, Efficient Incremental Processing with Netflix Maestro and Apache Iceberg: https://www.infoq.com/presentations/ips-maestro-iceberg/ ↩︎
- Airbnb Engineering, Upgrading Data Warehouse Infrastructure at Airbnb (Spark 3 + Iceberg results): https://medium.com/airbnb-engineering/upgrading-data-warehouse-infrastructure-at-airbnb-a4e18f09b6d5 ↩︎
- Adobe Tech Blog, Taking Query Optimizations to the Next Level with Iceberg (vectorized reads, predicate pushdown, planning): https://medium.com/adobetech/taking-query-optimizations-to-the-next-level-with-iceberg-6c968b83cd6f ↩︎
- Adobe Experience League, Taking Query Optimizations to the Next Level with Iceberg: https://experienceleaguecommunities.adobe.com/t5/adobe-experience-platform-blogs/taking-query-optimizations-to-the-next-level-with-iceberg/ba-p/424145 ↩︎
- YouTube — Keynote Address: Iceberg Development at Apple (Russell Spitzer): https://www.youtube.com/watch?v=kOsJ0cRV4YI ↩︎
- YouTube — Spark and Iceberg at Apple’s Scale — Leveraging differential files for efficient upserts and deletes: https://www.youtube.com/watch?v=IzkSGKoUxcQ ↩︎
- Expedia Group Tech, Turbocharging Efficiency & Slashing Costs: Storage‑Partitioned Join with Spark + Iceberg (45–70% savings): https://medium.com/expedia-group-tech/turbocharge-efficiency-slash-costs-mastering-spark-iceberg-joins-with-storage-partitioned-join-03fdc1ff75c0 ↩︎

PUBLISHED
TL;DR
Related blog posts