Understanding the Role of Kafka in Analytics


September 7, 2025
Kafka has become the heartbeat of real-time analytics. Companies now process millions of transactions every second using Kafka’s distributed platform. Most people think this is just about moving data faster. The truth is, Kafka completely changes how organizations discover insights, letting them react instantly instead of waiting for slow, outdated reports.
Table of Contents
- What Is Kafka And Its Purpose In Analytics?
- The Importance Of Real-Time Data Processing In Analytics
- How Kafka Facilitates Data Integration And Stream Processing
- Key Concepts And Features Of Kafka Relevant To Analytics
- Real-World Use Cases Of Kafka In Analytical Applications
Quick Summary
| Takeaway | Explanation |
|---|---|
| Kafka enables real-time data processing. | Kafka allows businesses to handle data streams as they occur, leading to faster decision-making and insights. |
| Kafka’s architecture supports scalability. | Organizations can expand data processing capabilities by adding more servers, enhancing performance and reliability. |
| Real-time analytics drive business agility. | By continuously processing data, companies can quickly respond to trends and issues, improving operational efficiency. |
| Kafka integrates diverse data sources seamlessly. | The platform acts as a central hub, allowing multiple applications to access and process data without interruptions. |
| Kafka supports advanced analytical workflows. | Its features enable detailed event reconstruction and historical data analysis, improving long-term strategic decision-making. |
What is Kafka and Its Purpose in Analytics?
Apache Kafka represents a powerful distributed streaming platform designed to transform how organizations handle real-time data processing and analytics. At its core, Kafka enables businesses to capture, store, and analyze massive streams of data with unprecedented speed and reliability.
Understanding Kafka’s Core Architecture
Kafka operates as a distributed event streaming platform that allows organizations to build robust, scalable data pipelines. Learn more about Kafka’s functionality through its fundamental architectural components. The platform uses a publish-subscribe messaging model where data producers can generate events that are immediately consumed by multiple subscribers in real-time.
Key architectural characteristics include:
- Horizontal scalability across multiple servers
- High-throughput data streaming capabilities
- Fault-tolerance and durability of data transmission
- Low-latency message processing
Kafka’s Role in Modern Analytics
In the analytics ecosystem, Kafka serves as a critical infrastructure for transforming raw data into actionable insights. According to research from NCBI, Kafka enables organizations to handle complex data streams across diverse domains, from bioinformatics to enterprise-level business intelligence.
The platform supports continuous data integration by allowing multiple data sources to stream information simultaneously. This means analytics teams can process events as they occur, enabling proactive decision-making instead of relying on retrospective batch analysis. Kafka’s ability to handle high-volume, real-time data makes it an essential tool for modern data-driven organizations seeking to extract immediate value from their information streams.
The Importance of Real-Time Data Processing in Analytics
Real-time data processing represents a transformative approach in modern analytics, enabling organizations to move beyond traditional retrospective analysis toward dynamic, immediate insights. By processing data as it arrives, businesses can respond to emerging trends, detect anomalies, and make critical decisions with unprecedented speed.
Driving Business Agility Through Instantaneous Insights
The competitive landscape demands rapid response capabilities. Learn more about optimizing real-time analytics workflows to understand how immediate data processing creates strategic advantages. Real-time analytics allows organizations to:
- Monitor operational performance continuously
- Detect potential issues before they escalate
- Personalize customer experiences dynamically
- Optimize resource allocation in near-instantaneous timeframes
Technical Foundations of Real-Time Data Processing
According to research from the National Institute of Standards and Technology, real-time data processing fundamentally transforms how organizations interact with information. The technical infrastructure supporting this approach involves complex distributed systems capable of ingesting, transforming, and analyzing data streams simultaneously.
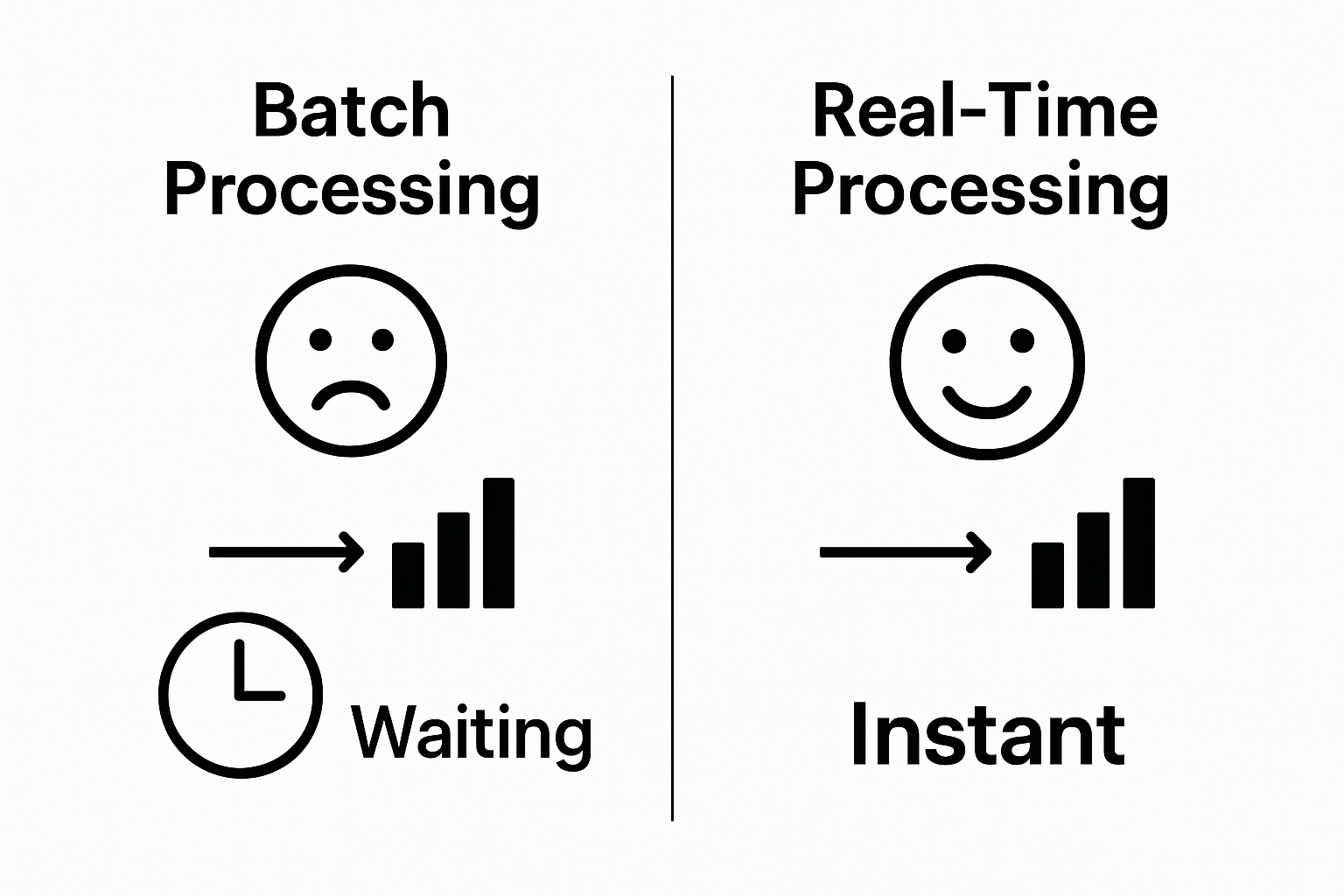
Traditional batch processing models required waiting for complete data sets before analysis, creating significant time lags. In contrast, real-time processing enables continuous data evaluation, allowing organizations to extract value from information moments after its generation.
This table compares traditional batch data processing with real-time data processing as enabled by Kafka, highlighting their main differences and impact on analytics workflows.
| Aspect | Batch Processing | Real-Time Processing (Kafka) |
|---|---|---|
| Timing of Analysis | After data collection is complete | As data arrives (continuous) |
| Responsiveness | Delayed, often hours or days | Instantaneous, within milliseconds |
| Business Impact | Retrospective decisions | Proactive, dynamic decision-making |
| Scalability | Often limited, needs manual scaling | Horizontally scalable by adding servers |
| Example Use Case | End-of-day reporting | Live transaction monitoring |
 This shift represents more than a technological upgrade it is a fundamental reimagining of how businesses leverage data for strategic decision-making.
This shift represents more than a technological upgrade it is a fundamental reimagining of how businesses leverage data for strategic decision-making.
How Kafka Facilitates Data Integration and Stream Processing
Kafka provides a robust framework for seamlessly integrating diverse data sources and enabling complex stream processing capabilities. By creating a unified platform for data movement and transformation, Kafka eliminates traditional integration barriers and enables organizations to build sophisticated, event-driven data architectures.
Data Integration Mechanisms
Learn more about Kafka’s data integration capabilities through its innovative architectural design. Kafka acts as a central messaging hub, allowing multiple data producers and consumers to interact through a distributed, fault-tolerant system. Its publish-subscribe model ensures that data can be simultaneously consumed by different applications without disrupting the original data stream.
Key integration features include:
- Support for multiple data source connections
- Guaranteed message delivery across distributed systems
- Ability to replay and reprocess historical data streams
- Decoupling of data producers from data consumers
Stream Processing Architecture
According to research from the International Journal of Computer Applications, Kafka’s stream processing capabilities extend far beyond traditional data integration. The platform enables real-time data transformation by allowing continuous processing of event streams, making it possible to apply complex transformations, filtering, and aggregation operations directly within the data pipeline.
This approach fundamentally transforms how organizations handle data, shifting from batch-oriented processing to continuous, event-driven analytics. By providing a flexible, scalable infrastructure, Kafka empowers businesses to build responsive data ecosystems that can adapt to changing information requirements in near real-time.

Key Concepts and Features of Kafka Relevant to Analytics
Kafka introduces a powerful set of architectural concepts that transform how organizations approach data processing and analytics. By understanding its core features, businesses can leverage this platform to create sophisticated, scalable data infrastructures that drive intelligent decision-making.
Fundamental Architectural Components
Dive deeper into Kafka’s core functionality to comprehend its analytical capabilities. Kafka’s architecture centers around several critical components that enable seamless data streaming and processing.
The following table summarizes and defines key architectural components of Kafka that are most relevant to analytics, helping clarify their unique roles within the platform.
| Component | Description |
|---|---|
| Topics | Logical channels for organizing and categorizing data streams |
| Partitions | Distributed storage units that enable parallel processing |
| Producers | Systems or applications generating data events |
| Consumers | Applications that read and process data streams |
| Brokers | Servers that manage data storage and transmission |
Key architectural elements include:
- Topics: Logical channels for organizing and categorizing data streams
- Partitions: Distributed storage units that enable parallel processing
- Producers: Systems or applications generating data events
- Consumers: Applications that read and process data streams
- Brokers: Servers that manage data storage and transmission
Advanced Analytics Capabilities
According to Apache Kafka’s official documentation, the platform is engineered to support high-performance data processing with remarkable efficiency. Its distributed architecture allows for horizontal scalability, meaning organizations can expand their data processing capabilities by adding more brokers to the cluster.
Kafka’s design supports complex analytical workflows by providing guarantees such as message persistence, exactly-once processing semantics, and the ability to replay historical data streams. This makes it an invaluable tool for scenarios requiring detailed event reconstruction, trend analysis, and real-time monitoring across various business domains.
Real-World Use Cases of Kafka in Analytical Applications
Kafka has emerged as a transformative technology across multiple industries, enabling organizations to process and analyze complex data streams with unprecedented speed and precision. By providing robust real-time data integration capabilities, Kafka supports critical analytical workflows that drive strategic decision-making.
Financial Services and Transaction Analytics
Learn more about stream processing technologies and their practical applications. In financial services, Kafka enables real-time fraud detection systems by processing transaction data instantaneously. Banks and financial institutions leverage Kafka to monitor millions of transactions simultaneously, identifying suspicious patterns and potential security threats within milliseconds.
Key financial analytics applications include:
- Instant transaction monitoring
- Risk assessment and predictive modeling
- Algorithmic trading signal generation
- Compliance and regulatory reporting
Healthcare and Scientific Research
According to research published in PubMed, Kafka plays a crucial role in processing large-scale bioinformatic datasets. Scientific researchers utilize Kafka’s distributed streaming capabilities to handle complex genomic data, enabling rapid analysis of genetic sequences and supporting breakthrough medical research.
In healthcare, Kafka supports advanced analytical scenarios by facilitating seamless data integration across disparate systems. The platform allows medical institutions to aggregate patient data from electronic health records, medical devices, and research databases, creating comprehensive insights that drive personalized treatment strategies and medical innovation.
Accelerate Real-Time Analytics with Streamkap’s Kafka-Powered Data Integration
Are you struggling with slow analytics, delayed data availability, or complex ETL infrastructure? The article explained how Kafka is revolutionizing analytics by powering real-time, event-driven data processing. Now it is time to put those ideas into action with a solution built specifically for modern data challenges.
Streamkap empowers your team to move past batch processing and unlock the advantages of continuous data pipelines using the leading technologies you read about like Apache Kafka. With features such as automated schema handling and no-code source connectors for PostgreSQL, MySQL, and MongoDB, you can streamline integration, enrichment, and transformation workflows—all in real time. Experience sub-second latency and proactive pipeline development that lets you test and validate data flows early, reducing errors and speeding up delivery. Discover how you can shift left, save costs, and deliver analytics-ready data instantly. Visit Streamkap to start building future-proof pipelines today.
Frequently Asked Questions
What is Kafka and how does it work?
Apache Kafka is a distributed event streaming platform that allows businesses to capture, store, and analyze massive streams of data in real-time. It uses a publish-subscribe messaging model where producers generate events, and multiple subscribers can consume these events simultaneously.
How does Kafka facilitate real-time data processing?
Kafka enables real-time data processing by allowing organizations to handle complex data streams as they occur, resulting in immediate insights and proactive decision-making rather than relying on batch analysis.
What are the key benefits of using Kafka in analytics?
Using Kafka in analytics provides high-throughput data streaming, fault tolerance, low-latency message processing, and the ability to process data continuously, which drives agility and strategically informs business decisions.
Can you explain the role of topics and partitions in Kafka?
In Kafka, topics are logical channels for organizing data streams, while partitions are distributed storage units that allow parallel processing. This combination enables efficient data handling and helps scale the system across multiple servers.
Recommended

Related blog posts
