A Guide to Streaming Data Pipelines
Discover how streaming data pipelines unlock real-time insights. This guide covers architectures, key components, benefits, and best practices.

Think about it this way: would you rather understand city traffic by looking at a single photo taken once a day, or by watching a live video feed? The photo is like traditional batch processing—a static, outdated snapshot. The live video? That’s a streaming data pipeline. It’s a continuous, real-time flow of information showing you exactly what’s happening, the moment it happens.
What Are Streaming Data Pipelines?

Simply put, a streaming data pipeline is a system built to ingest, process, and deliver a constant, unending flow of data from point A to point B in near real-time. It’s a fundamental departure from old-school batch pipelines, which gather data into large bundles and move them on a fixed schedule.
Streaming pipelines, on the other hand, handle data event-by-event, often within milliseconds of its creation. For a deeper dive into the concept, check out our guide on what is streaming data.
This immediacy is the magic behind many modern digital experiences. Ever had a fraudulent credit card transaction blocked the instant you tried to make it? Or seen an e-commerce site flag an item as “out of stock” just as the last one was sold? Those lightning-fast responses are powered by streaming data pipelines working tirelessly behind the scenes.
This isn’t just a niche technology; it’s a massive shift in how businesses operate. The market reflects this urgency, with global demand for streaming data tools valued at around $15 billion in 2025 and projected to grow at a Compound Annual Growth Rate (CAGR) of 18% through 2033. This boom is driven by the explosion of data from areas like IoT, finance, and security—all fields where immediate action is critical.
The Anatomy of a Streaming Pipeline
At its core, every streaming pipeline has three fundamental stages, working together like a high-speed assembly line for data.
- Sources: This is where the data is born. Sources are incredibly diverse, ranging from database changes captured via Change Data Capture (CDC), to IoT sensor readings, application logs, or even user clicks on a website.
- Processing Engine: This is the brains of the operation. Here, raw data gets transformed into something useful. The engine might filter out noise, enrich the data with other information, or run complex analytics on the fly.
- Sinks (Destinations): This is the final stop. Processed data lands in a sink, which could be a data warehouse like Snowflake for analysis, a real-time dashboard for monitoring, or another application that needs to trigger an immediate action.
By connecting these components, a streaming data pipeline creates a powerful, automated workflow. It ensures that fresh, valuable insights are constantly flowing to the people and systems that need them most, enabling businesses to react to opportunities and threats the moment they arise.
Streaming Pipelines vs. Batch Pipelines at a Glance
To really understand what makes streaming so different, it helps to see it side-by-side with its predecessor, batch processing. While both move data, their approaches and ideal use cases are worlds apart.
CharacteristicStreaming Data PipelineBatch Data PipelineData ScopeIndividual events or micro-batchesLarge, discrete blocks of dataLatencyMilliseconds to seconds (near real-time)Minutes, hours, or even daysTriggerEvent-driven (as data is created)Schedule-driven (e.g., nightly, weekly)AnalysisContinuous queries on data in motionQueries on static, historical dataUse CasesFraud detection, real-time analytics, IoTPayroll processing, end-of-day reportingData StateAlways up-to-date and currentCurrent only up to the last batch run
As you can see, the choice isn’t about one being “better” but about what your business needs. If you need to act on information now, a streaming pipeline is the only way to go. If you’re running historical reports where a delay is acceptable, batch processing still has its place.
The Anatomy of a Streaming Data Pipeline
The best way to think about a streaming data pipeline is to picture a high-tech assembly line, but for data. Raw information comes in one side, gets shaped and refined in the middle, and emerges as something genuinely valuable on the other end. Every stage is separate, yet they all work together seamlessly to keep the data moving at lightning speed.
This digital assembly line has three core stations: the Source (where data is created), the Processing Engine (where it’s transformed), and the Sink (where it’s delivered). Getting a handle on these three parts is the key to understanding how raw events become real-world insights.
The Source: Where It All Begins
Every pipeline has a starting point, a source, where data is born. This is where you gather the raw materials for your analytics. In today’s world, data can come from just about anywhere, often in a relentless, non-stop flood.
Common sources include things like:
- Databases: Using a technique called Change Data Capture (CDC), pipelines can instantly pick up every single change made in databases like PostgreSQL or MySQL without bogging them down.
- Application Logs: Every app, whether on a phone or the web, is constantly spitting out logs about user activity, performance hiccups, and errors.
- IoT Sensors: Think of all the devices in factories, cars, or even smart homes that are continuously sending out data on temperature, location, or status.
- User Interaction Streams: Every click, scroll, and search query on your website is a data point waiting to be captured and analyzed.
The whole idea is to grab this data the second it’s generated, feeding it right into the start of our assembly line.
The Processing Engine: The Brains of the Operation
Once the data is in, it flows to the processing engine. This is the main workstation on the assembly line. Here, the raw, and often messy, data gets cleaned up, restructured, and turned into something useful—all while it’s still moving.
Stream processing tools like Apache Flink or Kafka Streams are the powerhouses here, designed to handle endless data streams on the fly. For instance, a processing engine might:
- Filter out irrelevant noise to focus on what matters.
- Enrich an event by pulling in related customer details from another system.
- Transform data into a standardized format that’s easy to analyze.
- Aggregate data over time, like calculating the average purchase value over the last five minutes.
This is what makes a streaming data pipeline so incredibly powerful. You can run complex analytics while the data is still in motion, instead of waiting for it to finally land in a database somewhere.
The Sink: The Final Destination
The last stop is the sink, or the destination. After being collected and processed, the now-valuable data is sent to a system where it can be used to make a decision or trigger an action. This is where the finished product from our assembly line actually gets used.
Just like sources, sinks can be anything and everything, depending on what you’re trying to achieve:
- Data Warehouses: Processed data is often sent to platforms like Snowflake or Google BigQuery for deep, historical analysis.
- Real-Time Dashboards: You can feed data directly into tools like Tableau or Grafana to get a live, second-by-second view of what’s happening.
- Machine Learning Models: Data can be piped straight to ML models to power fraud detection systems or recommendation engines.
- Triggering Applications: A pipeline could fire off an alert to a messaging app or kick off a workflow in another tool when it spots a specific pattern.
By linking a Source, a Processor, and a Sink, you create a fully automated flow that turns a constant stream of raw data into continuous business value.
Taking a Look at Common Pipeline Architectures
Once you have a handle on the individual pieces of a streaming data pipeline, the next step is seeing how they all fit together. Think of it like building a house—you don’t start laying bricks without an architectural plan. In the data world, two major architectural patterns have really set the standard for how companies manage both real-time and historical information.
These patterns give you a high-level game plan for your data flow. They make sure you can get immediate insights from what’s happening right now while also running deep, accurate analysis on data from the past. Each approach has its own philosophy and comes with different trade-offs in complexity, cost, and how easy it is to keep running.
The infographic below gives a clean visual of how data moves in a typical streaming pipeline, from where it starts to where it ends up.
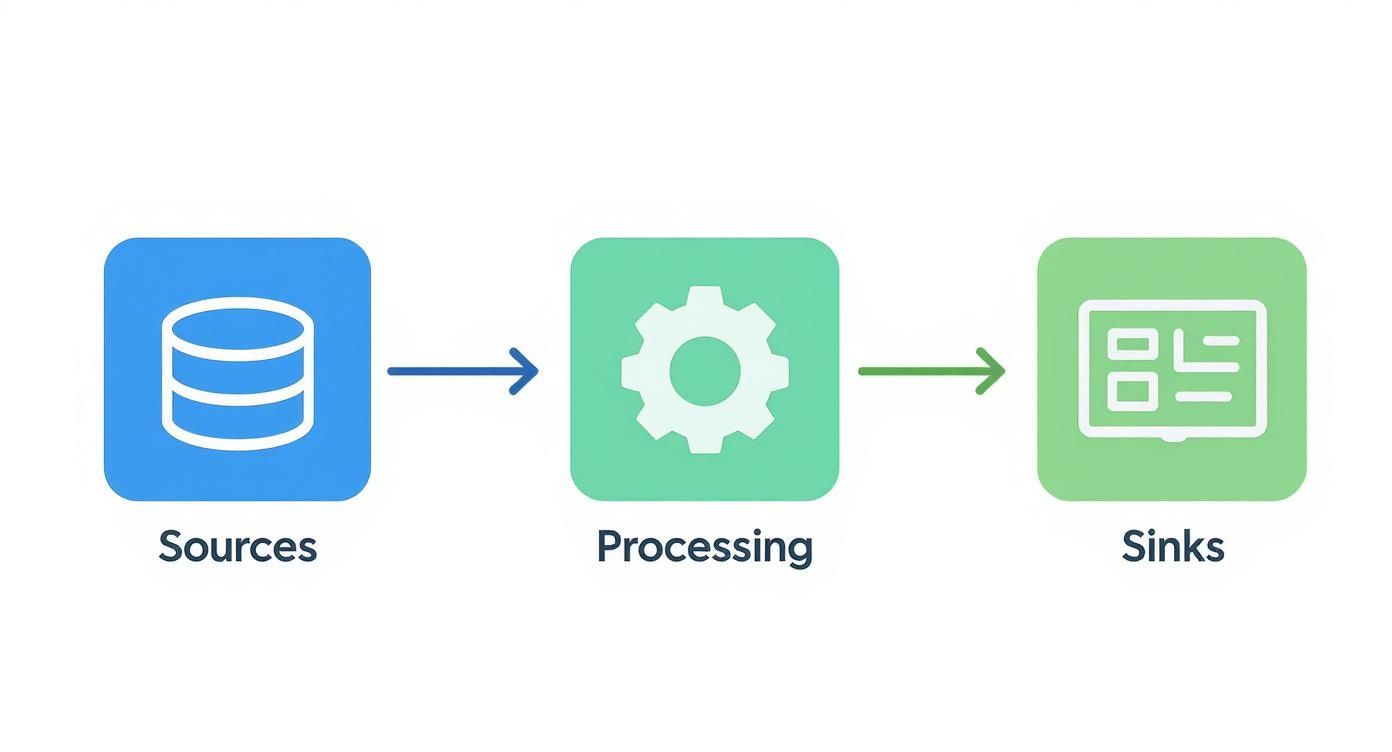
This highlights the three core stages—Sources, Processing, and Sinks—that every pipeline is built on, showing that constant, linear flow of information.
The Lambda Architecture: A Two-Lane Highway for Data
The Lambda Architecture was one of the first really solid solutions to a tough problem: how do you process huge datasets and get low-latency, real-time query results? The solution was to split the data flow into two parallel paths, creating a hybrid system.
Imagine you’re running a news organization. You need to get breaking stories out instantly, but you also publish in-depth, thoroughly fact-checked weekly summaries. Lambda Architecture works a lot like that:
- The Batch Layer: This is your “in-depth summary” path. It takes in all the data and stores it in its raw, unchangeable form. Then, on a regular schedule, it runs massive batch jobs to create a master dataset, guaranteeing 100% historical accuracy.
- The Speed Layer: This is your “breaking news” desk. It processes data the second it arrives, giving you an immediate view of what’s happening. The view might be slightly less perfect than the batch layer’s, but it’s incredibly fast.
When someone asks for information, the system pulls results from both layers to deliver a complete picture. While this makes it incredibly resilient, the downside is significant: you’re essentially building and maintaining two separate codebases. That gets complex and expensive, fast.
The Kappa Architecture: A More Streamlined Approach
As stream processing technology got better and more powerful, a simpler alternative showed up: the Kappa Architecture. This model ditches the batch layer completely. The argument is that a well-built streaming system can handle both real-time processing and reprocessing historical data just fine on its own.
The central idea is to treat everything as a stream. All your data, whether it’s from a second ago or a year ago, gets pushed through a single pipeline.
By using one unified stream processing engine, the Kappa Architecture eliminates the need for managing two separate systems. This dramatically simplifies development, reduces operational overhead, and lowers costs.
Need to re-calculate something from the past? You just replay the stored events from your message log (like Apache Kafka) through the same streaming engine. This approach is way more efficient and just feels right for modern, event-driven systems where speed and simplicity are the name of the game. If you want to dive deeper, you can check out our detailed comparison of these data pipeline architectures.
How Modern Platforms Cut Through the Complexity
Frankly, while it’s good to understand these architectures, today’s managed platforms like Streamkap give you a much more direct route to building powerful streaming data pipelines. You don’t have to get bogged down in a Lambda vs. Kappa debate and build everything from scratch. These tools abstract away that foundational complexity.
Instead, they focus on the outcome: getting data from Point A to Point B reliably and in real time. They handle the messy parts—like fault tolerance, schema changes, and scaling—so your team can focus on the business logic that actually matters. It’s the best of both worlds: you get all the reliability of these proven architectural patterns without the headache of building and maintaining them yourself.
The Business Impact of Real-Time Data

It’s one thing to understand the technical nuts and bolts of a streaming data pipeline, but what really matters is how it translates into business value. Moving from analyzing yesterday’s reports to acting on data from this very second is more than a simple upgrade—it opens up entirely new ways to run your business, outmaneuver competitors, and delight your customers.
This isn’t just a niche trend; it’s a seismic shift. The streaming analytics market was already valued at $23.4 billion in 2023 and is on track to hit an incredible $128.4 billion by 2030. That’s a compound annual growth rate of 28.3%, completely blowing traditional data markets out of the water. You can find more insights on this explosive growth in real-time data integration on integrate.io.
Driving Smarter, Faster Decisions
The most immediate payoff from real-time data is the power to make intelligent decisions at machine speed. In fast-paced industries where every second counts, this isn’t a luxury—it’s a necessity.
Think about these real-world scenarios:
- Financial Fraud Detection: Instead of finding out about a fraudulent charge hours later, a streaming pipeline can spot it, check it against user behavior patterns, and block the transaction in milliseconds. It stops the loss before it even happens.
- E-commerce Dynamic Pricing: An online store can adjust prices on the fly based on a competitor’s stock, a surge in demand, or a user’s browsing pattern. A rival sells out of a hot item? A pipeline can trigger an instant, automated price change to capture that demand.
A streaming data pipeline transforms data from a backward-looking report into a forward-looking guidance system. It gives businesses the power to react to opportunities and threats the moment they emerge, not after the fact.
Enhancing the Customer Experience
Modern customers demand personalized and seamless experiences. Streaming data is the engine that makes this possible, letting companies anticipate what customers need and respond before they even have to ask.
It works by building a complete, up-to-the-second profile of every customer. For instance, a support agent can see a customer’s recent website clicks and purchase history as they’re talking, allowing them to offer truly helpful, relevant advice. Likewise, a recommendation engine can suggest products based on what a user is looking at right now, not just what they bought last week.
Boosting Operational Efficiency
The benefits aren’t just customer-facing. Real-time data gives you an unparalleled view into your own operations, helping you run a leaner, smarter organization. In manufacturing, sensors on equipment can stream performance data, allowing teams to predict when a machine needs maintenance before a costly breakdown brings the production line to a halt.
It’s a game-changer for supply chain logistics, too. Streaming pipelines provide a live map of inventory, shipment locations, and delivery times. This lets companies:
- Optimize Routes: Instantly reroute trucks to avoid traffic jams or weather delays.
- Manage Inventory: Automatically trigger a reorder the moment stock levels hit a certain threshold.
- Improve Forecasting: Make far more accurate demand predictions using live sales data.
Ultimately, by tying technology directly to tangible business goals, streaming data pipelines create a clear path to growing revenue, cutting costs, and building a serious competitive edge.
It’s one thing to get a streaming data pipeline up and running. It’s another challenge entirely to build one that’s robust, scalable, and reliable for the long haul. A truly resilient pipeline is so much more than just connecting a source to a sink. It demands careful planning, a design-for-failure mindset, and a commitment to doing things right from the very beginning.
Think of it like building a bridge. You could throw a wooden plank across a small stream and call it a day. But to cross a major river with constant, heavy traffic? You’ll need deep foundations, redundant supports, and a way to monitor the bridge’s structural health. The same exact principles apply to your data infrastructure. Failures here lead to lost insights, bad business decisions, and a total loss of trust in your data.
The market for these tools is exploding for a reason. Valued at around $12.09 billion in 2024, the data pipeline tools market is expected to skyrocket to $48.33 billion by 2030. A huge driver for this growth is the wave of small and medium-sized businesses adopting cloud-based, no-code solutions that finally make powerful data pipelines accessible. You can see more on this trend and get other market statistics on integrate.io.
Start With a Clear Use Case
Before you write a single line of code or click a single button in a tool, you have to define your goal. Be crystal clear about what you’re trying to achieve. It’s so easy to fall into the trap of building a pipeline just because the tech is cool, but that’s how you end up with an over-engineered, costly system that doesn’t solve a real problem.
Force yourself to answer these critical questions first:
- What specific business decision will this real-time data actually inform?
- What’s our tolerance for latency? Are we talking milliseconds, or is a few seconds acceptable?
- Who is actually going to use this data, and what format do they need it in?
A well-defined use case is your North Star. It guides every architectural choice and saves you from a world of unnecessary complexity down the road.
Choose the Right Tools for the Job
The ecosystem for streaming data is massive. You’ve got open-source workhorses like Apache Kafka and Flink on one end, and fully managed platforms like Streamkap on the other. The “right” choice is completely dependent on your team’s skills, your budget, and the specific demands of your use case.
A classic mistake is trying to stitch together a bunch of single-purpose tools. You often end up with a brittle, Frankenstein-like system that’s a nightmare to maintain. A unified platform that handles ingestion, transformation, and monitoring in one place is almost always a more cohesive and reliable solution.
For a detailed walkthrough, our guide on how to build data pipelines is a great resource. It breaks down the technical decisions you’ll face when setting up your infrastructure.
Comparing Streaming Pipeline Solutions
Choosing your approach is a critical decision point. To help you see the landscape clearly, here’s a high-level look at the common ways to build and manage streaming pipelines.
ApproachKey TechnologiesProsConsBest ForDIY Open-SourceApache Kafka, Flink, Spark Streaming, NATSMaximum flexibility and control; no vendor lock-in; strong community.High operational overhead; requires deep in-house expertise; complex setup.Large engineering teams with specific, custom requirements.Cloud-Native ServicesAWS Kinesis, Google Cloud Dataflow, Azure Stream AnalyticsManaged infrastructure; pay-as-you-go pricing; integrates with cloud ecosystem.Potential for vendor lock-in; can become expensive at scale; configuration complexity.Teams already heavily invested in a specific cloud provider’s ecosystem.Managed PlatformsStreamkap, Confluent, DatabricksFast time-to-value; low operational burden; built-in reliability features.Less granular control than DIY; subscription-based cost model.Teams wanting to focus on data outcomes, not infrastructure management.No-Code/Low-Code ToolsHevo Data, Fivetran (for near real-time)Extremely easy to use; accessible to non-engineers; quick to set up.Limited transformation capabilities; less suitable for ultra-low latency.Business analysts or data teams needing simple source-to-sink replication.
Ultimately, there’s no single “best” answer. The right path depends on your team’s expertise, your budget, and how much control you truly need over the underlying infrastructure.
Design for Failure and Ensure Fault Tolerance
Let’s be realistic: your streaming data pipeline is going to fail at some point. A network will hiccup, a source system will go down, a processing node will crash. A robust pipeline is one that expects these problems and is built to handle them gracefully—without losing or duplicating data.
A fault-tolerant design must include:
- Exactly-Once Processing: This is non-negotiable. You need mechanisms to guarantee that every single event is processed once and only once, even when things go wrong. It’s the only way to prevent data corruption.
- Automated Recovery: The system should be smart enough to recover on its own. If a process fails, it should restart automatically without someone needing to wake up at 3 AM to intervene.
- Backpressure Handling: What happens when your destination can’t keep up with the source? A good pipeline will automatically slow down ingestion to avoid getting overwhelmed, preventing crashes and data loss.
When you assume failure will happen, you build a system that’s prepared for the real world, not just a perfect-world scenario. This proactive approach is the signature of a truly professional data architecture.
Common Questions About Streaming Pipelines
When teams first dip their toes into real-time data, a few common questions always pop up. It usually boils down to connecting the new concepts of streaming with the battle-tested processes they already know. Getting these fundamentals straight is key to building a solid understanding.
Let’s tackle some of the most frequent ones.
Streaming ETL vs. Traditional ETL: What’s the Real Difference?
One of the first hurdles is understanding how a streaming data pipeline is different from the traditional ETL (Extract, Transform, Load) we’ve used for decades. In simple terms, streaming flips the entire model on its head.
Instead of bundling data into big chunks and shipping it off on a schedule—say, once an hour or once a day—streaming ETL processes each event, one by one, as it happens. The data is transformed in flight, making it ready for use the moment it arrives.
How Does Change Data Capture Fit In?
Right on the heels of the ETL question comes Change Data Capture (CDC). What is it, and why does it matter so much for streaming?
Think of CDC as a silent, incredibly efficient observer sitting inside your database. Rather than constantly polling the database with queries like “What’s new? Anything new yet?”, which hammers your production systems, CDC quietly reads the database’s own internal changelog.
This means your pipeline captures every single insert, update, and delete the second it’s committed, all without adding any performance load to the source. It’s the perfect way to create a low-latency, high-fidelity stream that truly reflects what’s happening in your business.
By using CDC, streaming pipelines ensure that your destination—whether it’s a data warehouse for analytics or a real-time app—is always a perfect, up-to-the-second mirror of your source data. This is the bedrock of trustworthy, real-time decision-making.
Can You Build These Pipelines with Python?
Naturally, developers want to know if they can use a familiar, powerful language like Python. The answer is a resounding yes. The Python ecosystem is packed with great libraries and frameworks for stream processing.
A couple of popular tools include:
- Faust: A stream processing library built on the shoulders of Kafka Streams, perfect for high-performance, distributed applications.
- PySpark Streaming: Part of the massive Apache Spark ecosystem, it lets you apply Spark’s powerful analytics engine to live data streams.
While these tools give you immense control for building custom solutions, they also demand serious expertise to set up, scale, and maintain the underlying infrastructure. This is often where a managed platform offers a much quicker and more reliable path to getting your real-time data flowing.
Ready to build robust, real-time streaming data pipelines without the operational headache? Streamkap offers a fully managed platform that simplifies CDC and real-time data movement, letting you focus on insights, not infrastructure. Learn more and get started with Streamkap.
Related resources
Kafka Consumer Lag: Causes, Debugging, and Fixes
Consumer lag is the most common Kafka operational issue. Learn what causes it, how to measure it, and practical strategies to bring it under control.
Kafka on Kubernetes: Real-World Lessons
Running Kafka on Kubernetes sounds like a good idea until you hit storage, networking, and operational challenges. Here's what teams learn the hard way and how to avoid the common pitfalls.
Backpressure in Stream Processing: What It Is and How to Handle It
Learn what backpressure means in streaming pipelines, how to detect it, and practical strategies for handling it in Kafka, Flink, and CDC pipelines without losing data.