stream processing vs batch processing: A Data Strategy Guide
Explore stream processing vs batch processing: compare architectures, performance, cost, and use cases to choose the right data strategy for your needs.
When you get right down to it, the main difference between stream processing and batch processing is all about timing. Batch processing is about gathering up data and handling it in big, scheduled chunks. Think high throughput for massive datasets. Stream processing, on the other hand, is about analyzing data the moment it arrives, making low latency the top priority for real-time insights.
Understanding The Core Difference
The choice between these two approaches boils down to how you need to handle time and data volume. Batch processing is like getting your bank statement at the end of the month—it gathers everything that happened into one comprehensive report. It’s the perfect fit for jobs where you don't need an immediate answer, like end-of-day financial summaries or running monthly payroll.
Stream processing is more like watching a live stock ticker. It gives you information instantly, event by event, so you can react on the spot. This is absolutely essential for things like real-time fraud detection, where a delay of just a few seconds could be a huge problem. If you want to dig deeper into the mechanics, check out our guide on data stream processing.
The market is clearly moving toward real-time. The global data streaming market was valued at USD 11.2 billion in 2021 and is expected to grow at a CAGR of 22.6% through 2030, all because businesses need instant insights to stay competitive. Still, according to Gartner, around 60% of enterprise analytics continues to rely on traditional batch methods for historical reporting. You can find more on this in another helpful data processing comparison.
The real question isn't which one is "better," but which one is right for the job. Batch is king when you're dealing with huge, finite datasets, while streaming shines when you have an endless flow of continuous data.
To make this distinction crystal clear, here’s a quick summary of how they stack up.
Quick Comparison Stream vs Batch Processing
This table provides a high-level summary of the key differences between stream and batch processing, giving you a quick reference point.
AttributeStream ProcessingBatch ProcessingData ScopeUnbounded, continuous dataBounded, finite datasetsLatencyMilliseconds to secondsMinutes to hoursData SizeSmall, individual recordsLarge, grouped blocksThroughputHigh velocity of eventsHigh volume of total dataPrimary GoalImmediate reaction and analysisDeep, historical analysisExample Use CaseLive fraud detectionEnd-of-month payroll
Ultimately, each model serves a distinct purpose, and understanding these core attributes helps you choose the right tool for your specific data challenge.
A Tale of Two Architectures: Batch vs. Stream
To really get to the heart of the stream processing vs. batch processing debate, you have to look past the obvious difference in timing. The real distinction lies in their technical blueprints. Each approach is built on a completely different philosophy, and that architecture is what dictates everything from performance and complexity to the problems they're best suited to solve.
The visual below lays out the high-level journey data takes in both worlds, giving a quick sense of their core operational flows.
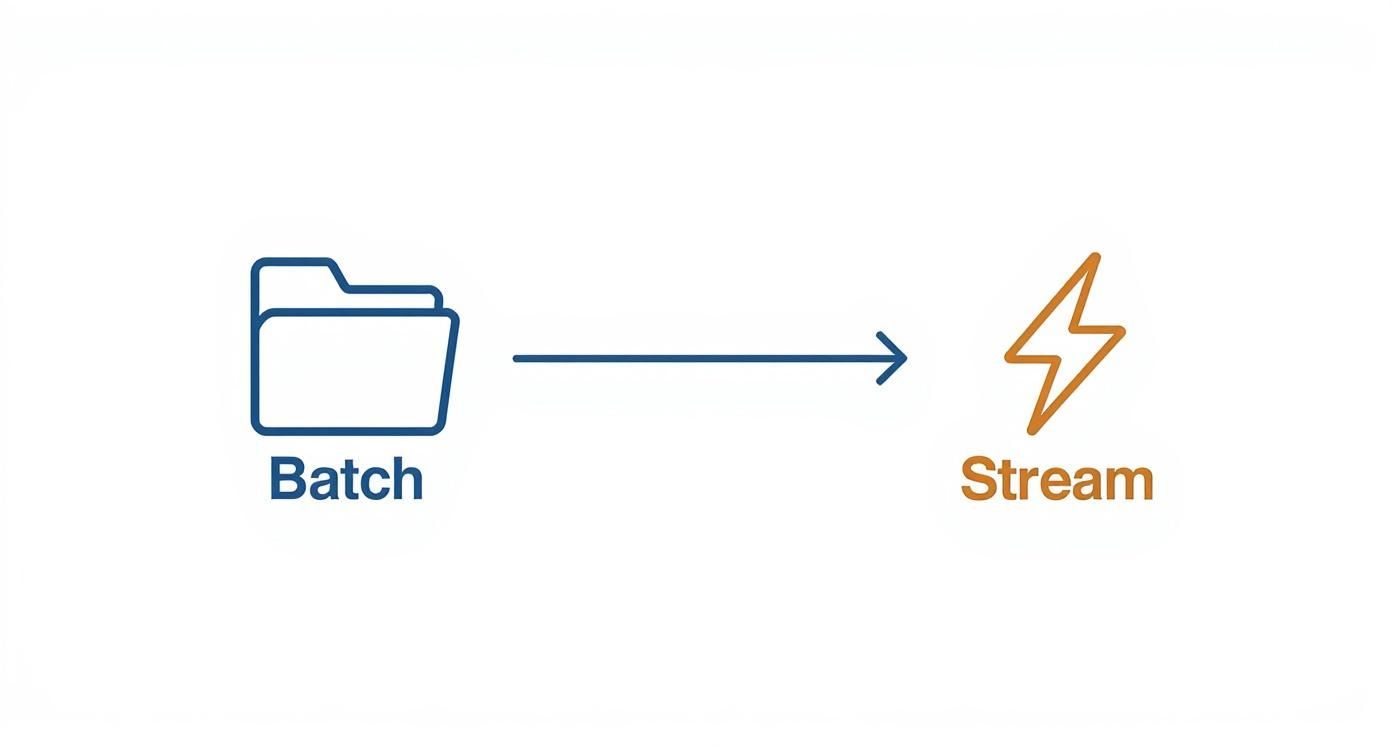
As you can see, batch processing follows a linear, stop-and-start schedule, while stream processing is all about continuous, immediate motion.
The Anatomy of a Batch Processing Pipeline
Classic batch architecture is synonymous with the tried-and-true ETL (Extract, Transform, Load) model. It's a methodical, step-by-step process designed to handle massive, but finite, chunks of data. Think of it as the system built for scheduled, heavy lifting, where throughput and completeness are the top priorities.
A typical batch workflow unfolds in three distinct stages:
- Extract: Data is pulled from various sources—transactional databases, application logs, CRMs—at a set time, like nightly or every hour.
- Transform: All that raw data gets moved to a staging area. Here, powerful engines like Apache Spark or Hadoop MapReduce get to work cleaning, validating, and enriching the entire dataset in one big job. This is the computationally intensive part, often scheduled for off-peak hours to save on costs.
- Load: Once transformed and structured, the data is loaded into its final destination, usually a data warehouse like Snowflake or Google BigQuery, where it's ready for BI tools and historical analysis.
The key takeaway is that this entire cycle runs on a fixed schedule. That means your insights are only as current as the last time a batch job successfully finished.
The Structure of a Stream Processing Pipeline
Stream processing, on the other hand, is built for a world of never-ending, unbounded data. Its entire architecture is optimized for one thing: minimizing latency. Instead of collecting data into batches, it processes events the moment they happen, paving the way for real-time analytics and immediate action. Speed and constant availability are the name of the game.
A real-time pipeline usually consists of these core components:
- Ingestion: Events are captured as they're generated from sources like IoT sensors, clickstreams, or database change events. An event broker, most commonly Apache Kafka, acts as a durable, high-throughput buffer to handle this incoming firehose of data.
- Processing: A stream processing engine, such as Apache Flink or Spark Streaming, subscribes to the event broker. It applies transformations, runs aggregations, or detects patterns on each event (or a tiny micro-batch) as it flies by, often in just milliseconds.
- Delivery: The processed data is immediately pushed to a destination system. This could be anything from a live monitoring dashboard or a fraud detection system that needs to trigger alerts, to an operational database that powers an application feature.
The most fundamental architectural split is where the transformation happens. In batch, data comes to rest before it's transformed in bulk. In streaming, data is transformed while it's still in motion, which cuts out storage latency entirely.
Understanding these foundational blueprints is the first step in picking the right model for the job. Of course, modern systems often blend these approaches. For a deeper dive into more complex designs, you can explore these modern data pipeline architectures. Every component choice, from ingestion to delivery, has a massive impact on what your pipeline can ultimately achieve.
Analyzing Performance: Latency, Throughput, and Cost
When you get down to the brass tacks of stream versus batch processing, the real differences surface in performance and how you manage resources. The choice often comes down to a classic engineering trade-off: speed (latency), volume (throughput), and budget (cost). These three aren't independent; they're tangled together, and figuring out the right balance is key to building a data architecture that actually works for your business.

At their core, each model is built for a different world. Batch processing is all about crushing massive, bounded datasets with maximum efficiency. Stream processing, on the other hand, is designed for immediate reaction to an unending flow of data. Let's dig into how these philosophical differences play out in the real world of performance and cost.
The Great Divide: Latency
Latency is where the two approaches diverge most dramatically. It's simply the delay between an event happening and you getting a usable insight from it.
In batch systems, latency isn't a bug; it's a feature. We're talking minutes, hours, or even days. The whole point is to wait, collect a big chunk of data, and then process it on a set schedule. This is perfectly fine for things like crunching monthly financial reports or running an overnight ETL job to update a data warehouse.
Stream processing is the polar opposite. It’s engineered from the ground up to shrink that delay to near zero—often down to milliseconds or seconds. The goal is to process data in-flight to trigger an immediate action. This isn't just a "nice-to-have" for use cases like real-time fraud detection, live inventory management, or monitoring critical systems. In these scenarios, a delay can mean serious financial loss or operational chaos.
The Core Latency Trade-Off: Batch processing gives up immediacy to gain the raw efficiency of chewing through huge, complete datasets. Stream processing gives up the simplicity of working with bounded data to gain the massive competitive edge that comes with real-time reactions.
The performance gap is massive. One benchmark study showed stream processing systems hitting average latencies under 100 milliseconds for event processing, while comparable batch jobs took anywhere from several minutes to hours. For example, companies that switched to streaming for fraud detection have seen response times drop from 15 minutes (in a batch world) to under 30 seconds, cutting fraudulent losses by as much as 70%.
Balancing Volume and Velocity: Throughput
Throughput measures how much data your system can handle in a given period. Here, the comparison gets a bit more interesting because both architectures can be built for high throughput—they just optimize for different kinds of it.
Batch processing is the undisputed king of high-volume throughput for static, historical data. It’s purpose-built to efficiently grind through petabyte-scale datasets. By scheduling massive jobs during off-peak hours, batch systems can max out their computational resources, making them perfect for deep historical analysis or large-scale data migrations where you need to process everything at once.
Stream processing, however, is all about high-velocity throughput. It's designed to handle a continuous, potentially infinite firehose of events arriving at a blistering pace. While any single event is tiny, the system has to be able to ingest and process millions of them per second without getting overwhelmed. The focus isn't on processing a giant stored dataset, but on keeping up with the relentless pace of new data.
For organizations building out these systems, the underlying infrastructure is a critical piece of the puzzle. The right Virtual Private Server (VPS) solutions can make or break your ability to scale and directly influence performance, latency, and your bottom line.
Unpacking the Total Cost of Ownership
Cost is usually the deciding factor, and it's far more complicated than just looking at your cloud bill. The total cost of ownership (TCO) has to account for hardware, software, maintenance, and—most importantly—the business impact of data latency.
Batch Processing Cost Profile
- Infrastructure: The baseline costs are typically lower. You can spin up resources for scheduled jobs and then shut them down, which is great for optimizing spend.
- Operations: It's a simpler world. Jobs are discrete, and state is managed between runs, which generally means less operational headache and lower overhead.
- Opportunity Cost: This is the hidden killer. The value you lose because of delayed insights—missed sales opportunities, undetected fraud, a frustrating customer experience—can be enormous.
Stream Processing Cost Profile
- Infrastructure: The starting costs are almost always higher. The "always-on" nature of streaming means you need infrastructure running 24/7 to catch data as it arrives.
- Operations: Let's be honest, it's more complex. Managing state in a continuous flow, guaranteeing data ordering, and gracefully handling failures requires specialized skills and more sophisticated tools.
- Business Value: The ROI is all about the value of acting now. The ability to respond instantly can create new revenue streams, prevent major losses, and deliver a competitive advantage that makes the higher infrastructure cost look like a bargain.
In the end, the "cheaper" solution is the one that actually meets your business goals. For some, the predictable, scheduled efficiency of batch processing is a perfect fit. For others, the upfront investment in a real-time streaming architecture unlocks value that pays for itself many times over.
Choosing The Right Model For Your Use Case
Picking the right data processing model is more than a technical choice—it's a strategic decision that shapes what your business can do. The whole stream vs. batch debate really boils down to your specific needs, especially how quickly you need an answer and how complete the data has to be.
Let's move past the theory and look at real-world situations where one model is clearly the right tool for the job. This isn't about finding a single "best" approach, but about matching the architecture to the problem you're actually trying to solve.
When Stream Processing Is The Clear Winner
Stream processing shines when the value of data is highest the very second it’s created. In these situations, acting immediately isn't just a nice-to-have; it's critical for preventing fraud, seizing an opportunity, or keeping operations running smoothly. The unifying theme here is the demand for sub-second latency.
Here are a few classic examples where streaming is the only real option:
- Real-Time Fraud Detection: Think about a credit card transaction. It has to be flagged as fraudulent before it's approved. A batch process that runs every hour is completely useless—the money would already be gone. Stream processing, on the other hand, can analyze transaction data in milliseconds to spot suspicious patterns and trigger an instant decline.
- Live IoT Sensor Monitoring: In a smart factory, IoT sensors are constantly monitoring critical machinery. A continuous stream of temperature and vibration data can be analyzed in real time to predict equipment failure before it happens. This allows for proactive maintenance, preventing the kind of costly downtime a daily batch report would never catch in time.
- Dynamic E-commerce Pricing: Online retailers constantly tweak prices based on supply, demand, competitor moves, and even a user's browsing behavior. Streaming engines analyze clickstream data and market signals as they occur, enabling automated, instant price adjustments that maximize revenue.
The key takeaway is that in each of these scenarios, the data's value is perishable. An insight delivered a few minutes too late is often worthless. Stream processing is built for this world, where speed is everything.
Where Batch Processing Still Reigns Supreme
Even with all the hype around real-time data, batch processing remains the workhorse for many core business functions. It's the go-to when accuracy, completeness, and cost-efficiency trump the need for speed. We're talking about scheduled, periodic jobs that chew through large, finite datasets.
Batch has always been the foundation of large-scale analytics where getting the numbers exactly right is non-negotiable. A 2023 survey revealed that 65% of data engineers still depend on batch methods for heavy-duty transformations and historical analysis. The scale can be staggering; Facebook's batch infrastructure, for instance, crunches over 100 petabytes of data daily. To really grasp its importance, it's worth understanding the history and continued relevance of batch vs. streaming data engineering methodologies.
Batch processing is the perfect fit for these kinds of jobs:
- End-of-Day Financial Reporting: A bank doesn’t need a running, real-time P&L statement. What it needs is a perfectly reconciled report after the close of business. A nightly batch job is designed for this—it gathers all the day's transactions, validates their integrity, and produces the comprehensive financial summaries needed for regulators and executives.
- Monthly Billing and Payroll Cycles: Your utility company doesn't calculate your bill in real time. It generates it once a month based on your total consumption. A massive batch process is the most efficient way to collect meter readings, apply the correct rates, and spit out millions of invoices in a single, scheduled run.
- Large-Scale Historical Trend Analysis: A data science team building a customer churn model needs to look back at years of data to find meaningful patterns. A batch job is the only cost-effective way to process terabytes of historical customer interactions, support tickets, and purchase history to train a robust model. This kind of deep, comprehensive analysis is something stream processing just isn't built for.
How to Transition From Batch to Streaming
For most teams, the big question isn't if they should adopt real-time data, but how to do it without blowing up existing workflows. Moving from the predictable, scheduled world of batch processing to an always-on streaming model feels like a huge leap. But with the right strategy, it's more of a gradual ramp-up than a cliff jump, and the key is Change Data Capture (CDC).
CDC is the technology that makes a smooth migration possible. Instead of hammering your database with inefficient, full-table scans on a schedule, CDC taps directly into the database's transaction log. It captures every single row-level change—inserts, updates, and deletes—as it happens and streams it out as a discrete event.
The best part? This approach is incredibly low-impact. It doesn't bog down your source systems and gives you a perfect, event-by-event feed of every change.
The Role of CDC in a Phased Migration
Using a CDC-driven platform like Streamkap takes a lot of the pain out of this shift. It handles the low-level pipeline plumbing, so your team can focus on the business logic, not the infrastructure. The goal here isn't a risky "big bang" replacement; it's a careful, deliberate evolution.
A smart migration strategy usually breaks down into three stages:
- Pinpoint the High-Value Workflows: Start small. Find the use cases that are crying out for real-time data. Think fraud detection, live inventory management, or customer-facing dashboards where every second of delay costs money.
- Run a Hybrid Model: This is the key. Use CDC to start streaming data for those high-priority workflows. Meanwhile, leave your less urgent tasks, like end-of-month reporting, on their existing batch schedules. This hybrid approach lets you get the benefits of real-time where it counts without overhauling everything at once.
- Expand Incrementally: Once your team gets comfortable with streaming and sees the results, you can start moving more workloads over. This iterative process is far less risky and ensures a controlled, successful transition across the company.
The real beauty of a CDC-based transition is that it's non-disruptive. It runs right alongside your existing batch jobs. You're essentially building a new, faster lane on the data highway without shutting down the old one.
Cutting TCO and Engineering Overhead
One of the biggest blockers for moving to stream processing has always been the perceived cost and complexity. Building and managing a real-time pipeline used to require a team of specialists who were experts in tools like Kafka and Flink, which meant a ton of engineering overhead. For a deeper dive, check out our guide on how to implement Change Data Capture without complexity.
A modern, CDC-driven approach completely flips the script on the cost equation.
- Lighter Load on Source Systems: By getting rid of those heavy, periodic batch queries, you immediately reduce the strain on your production databases.
- Simpler Pipeline Management: A managed CDC platform handles all the tedious work—schema changes, error handling, scaling—freeing up your engineers to work on things that actually drive the business forward.
- Lower Latency, Higher Value: Ultimately, this shift lets you act on data when it's most valuable. This opens up new revenue opportunities that can quickly justify the infrastructure investment.
This streamlined model drastically reduces your Total Cost of Ownership (TCO) by cutting both direct infrastructure costs and the hidden costs of engineering time and operational headaches. Moving from batch to streaming isn't just a technical upgrade—it’s a strategic play to build a more responsive, competitive data foundation.
Common Questions About Data Processing
When you're weighing stream processing vs. batch processing, a few common questions always come up. The right choice isn't always cut and dried, especially since modern data problems often blur the lines between the two. Let's clear up some of the most frequent points of confusion to help you make smarter architectural decisions.
Can I Use Stream and Batch Processing Together?
Absolutely. In fact, combining them is one of the most powerful and common strategies in modern data architecture. A hybrid approach gives you the best of both worlds: the immediate, real-time feedback of streaming with the deep, cost-effective analysis of batch processing.
Two famous patterns for this are the Lambda and Kappa architectures.
- Lambda Architecture: This model runs two parallel data paths. A "speed layer" uses stream processing for real-time views, giving you immediate but sometimes approximate insights. A separate "batch layer" processes the same data in large, scheduled jobs to guarantee complete accuracy for historical analysis. The two views are then merged to give a complete picture.
- Kappa Architecture: A simpler approach that tries to handle everything with a single streaming pipeline. It treats all data as a stream, using a powerful stream processing engine to recalculate historical views from the stream itself when needed.
In practice, most organizations end up with a hybrid model. They use streaming for time-sensitive, critical operations while relying on batch for less urgent tasks like monthly financial reporting or deep analytical modeling.
What Are The Most Common Tools For Each Model?
Both the stream and batch processing ecosystems are mature, with plenty of specialized tools for every stage of the pipeline. While some tools, like Apache Spark, can work in both modes, they are often optimized very differently for each job.
Here’s a quick look at the popular tools for each approach:
StageBatch Processing ToolsStream Processing ToolsIngestionETL Platforms (e.g., Informatica), Custom ScriptsApache Kafka, AWS Kinesis, Google Cloud Pub/SubProcessingApache Hadoop, Apache Spark (Batch Mode), AWS BatchApache Flink, Spark Streaming, Azure Stream AnalyticsStorageData Warehouses (Snowflake, BigQuery), Data LakesNoSQL Databases, Time-Series Databases, In-Memory Caches
Change Data Capture (CDC) platforms like Streamkap are becoming key players here, effectively bridging the two worlds. They turn your traditional databases into real-time streams, making it incredibly simple to feed transactional data into a stream processing system without relying on clunky, inefficient batch queries.
The real power of a modern data stack comes from how you combine these tools. Using a CDC platform to stream database changes into Kafka, which then feeds a Flink job, is a common and effective pattern for building a real-time analytics pipeline.
Is Stream Processing Always More Expensive?
Not necessarily, but you have to look at the cost from more than one angle. The upfront infrastructure bill for an "always-on" streaming system can look higher than for a scheduled batch system, but the Total Cost of Ownership (TCO) often tells a very different story.
Let's break the cost comparison down into three key areas:
- Infrastructure Costs: On paper, batch processing often looks cheaper. You can spin up compute resources for a scheduled job and then shut them down, which is great for optimizing cloud spend. Streaming requires continuously running infrastructure to process data the moment it arrives, leading to a higher baseline cost. However, modern cloud-native streaming platforms lean heavily on autoscaling to manage this much more efficiently.
- Operational Overhead: Building and maintaining a resilient, scalable streaming pipeline is complex. It often demands specialized engineering skills to manage state, handle out-of-order events, and ensure true fault tolerance. This can drive up operational costs if you're building it all yourself. This is exactly the complexity that managed platforms are designed to absorb.
- Business Value and Opportunity Cost: This is where streaming really proves its worth. What’s the cost of a missed opportunity? Or a delayed reaction? For an e-commerce site, a five-minute delay in flagging a fraudulent transaction could cost far more than a real-time processing cluster. The ROI from stream processing comes from preventing losses, delighting customers, and capitalizing on fleeting opportunities—value that batch processing simply can't provide.
Ultimately, the most cost-effective solution is the one that directly serves your business goals. The higher infrastructure spend for streaming can be an excellent investment if the value of real-time insight is high enough.
Ready to make the leap from slow batch jobs to real-time data pipelines? Streamkap uses Change Data Capture (CDC) to stream data from your databases to your warehouse in seconds, dramatically reducing latency and TCO. See how you can build a faster, more efficient data architecture.