Real-Time vs Batch Processing The Definitive Guide to Data Strategy
Choosing between real-time vs batch processing? This guide breaks down the architecture, costs, and use cases to help you build the right data strategy.
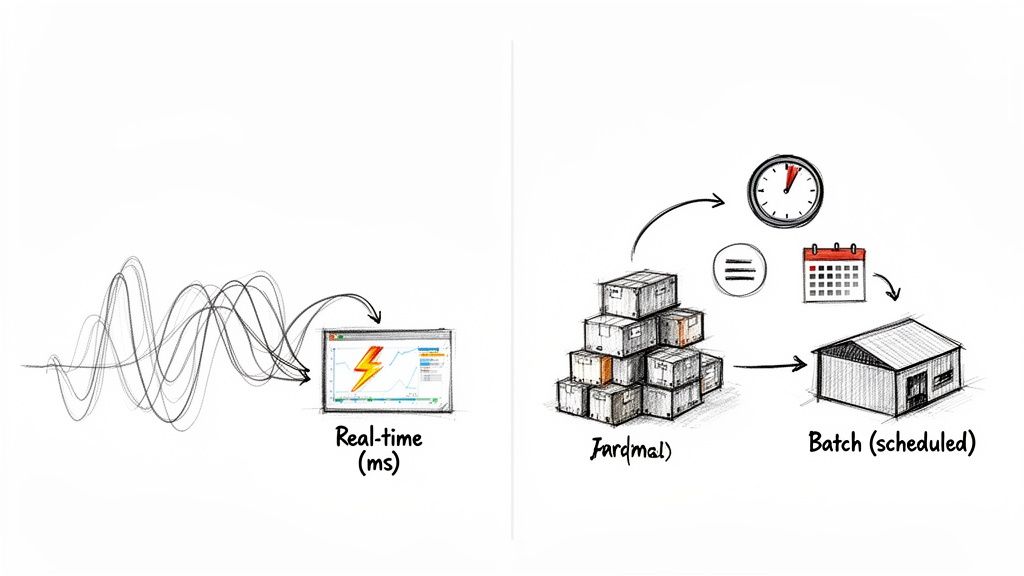
The whole debate boils down to a simple question: Do you need to act on your data right now, or can it wait? Real-time processing is all about handling data the instant it arrives, while batch processing is designed to collect data first and process it later in large, scheduled chunks.
It’s a fundamental choice. Are you building a system for immediate insights or one for periodic, large-scale analysis?
Understanding the Core Difference in Data Processing
Choosing between real-time and batch processing is one of the first major decisions you'll make when designing a data architecture. These aren't just technical terms; they represent two completely different philosophies on how to handle data timeliness and make your operations responsive.
Think of real-time processing as a continuous, event-driven stream. The moment a new piece of data appears—a customer purchase, a website click, a sensor reading—the system reacts. The entire goal is to slash latency to the bone, often down to milliseconds, so you can make decisions on the spot.
On the other hand, batch processing works like a scheduled appointment. It lets data pile up over a set period—say, an hour or a full day—and then processes the entire collection in one massive, efficient job. This approach isn't concerned with speed; it's all about throughput and handling huge volumes of data where immediate action isn't necessary.
Key Distinctions at a Glance
For anyone looking into Data Engineer roles, getting a solid grasp of these concepts is non-negotiable. Your choice here sets the tone for everything that follows, from infrastructure costs to the kinds of business problems you can actually solve. A fraud detection system, for example, is useless if it runs on an end-of-day batch job. It needs real-time analysis to catch fraudulent transactions as they happen.
Conversely, think about generating a company's monthly payroll or creating detailed financial reports. These tasks are perfect for batch processing because it can chew through enormous datasets efficiently without the overhead of constant, low-latency computation. The core trade-off always comes back to immediacy versus efficiency.
The decision isn't about which method is "better." It's about which one fits the job. Real-time is for reacting, while batch is for reporting and looking back at the big picture.
To make this even clearer, here's a table that breaks down the core characteristics separating these two powerful data processing models.
Key Differences Between Real-Time and Batch Processing
This table offers a high-level summary of what truly distinguishes real-time and batch data processing methods.
As you can see, each model is built for a different purpose. One gives you the speed to act now, while the other provides the power to analyze everything later.
Comparing Data Architecture: Streaming CDC vs. Batch ETL
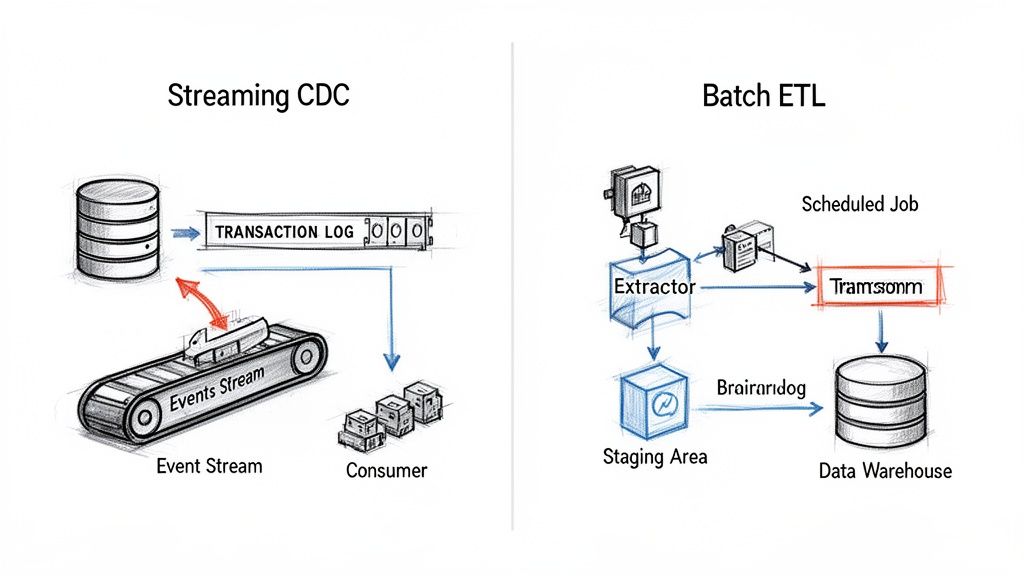
The choice between real-time and batch processing is one of the most fundamental decisions you'll make, directly dictating your entire data architecture. This decision generally leads down two very different paths: the classic Batch ETL (Extract, Transform, Load) or the more modern Streaming Change Data Capture (CDC). Getting to the heart of how they work mechanically is the key to building a pipeline that actually delivers what the business needs.
Batch ETL is the old guard of data integration. It's a reliable, time-tested method that works on a fixed schedule—maybe hourly, maybe overnight. It runs massive queries against your source databases to extract huge chunks of data all at once. From there, the data gets dumped into a staging area to be transformed (cleaned, joined, restructured) before finally getting loaded into a data warehouse.
By its very nature, this process is a heavyweight. It puts a significant, recurring strain on source systems because the queries have to scan entire tables just to figure out what's changed since the last run. It’s solid for end-of-day reporting, but its built-in delays and performance hits make it a poor fit for anything that requires up-to-the-minute data.
The Shift to Streaming Change Data Capture
Streaming CDC is a complete paradigm shift, forming the architectural backbone of real-time processing. Instead of pummeling your database with bulk queries on a schedule, CDC taps directly into the database’s transaction log—the official, immutable record of every single change.
It captures individual row-level events (INSERT, UPDATE, DELETE) the instant they happen. These events are then streamed to downstream systems with millisecond latency. The beauty of this approach is its efficiency; it has a tiny footprint on the source database because it completely avoids running expensive, resource-hogging queries.
Key Takeaway: Batch ETL has to ask the database what's new by running huge queries, which creates a heavy, periodic load. Streaming CDC simply listens to the database's own log of changes, capturing new events with almost no impact. This is the core difference that makes true real-time data possible.
The impact on data freshness is massive. With Batch ETL, your analytics are always based on a snapshot of the past, whether it's an hour or a full day old. With Streaming CDC, your data warehouse or analytics tools can stay in near-perfect sync with your production databases, giving you a view of reality as it unfolds. For a deeper dive, check out our guide on modern data pipeline architectures.
Comparing Architectural Impact
Let’s get practical and break down how these two approaches directly affect your systems and overall data strategy.
At the end of the day, Batch ETL is built for periodic, large-scale analytics where looking back at historical trends is more important than immediacy. It’s perfect for answering questions like, "What were our total sales last quarter?"
Streaming CDC, on the other hand, is designed for operational intelligence and taking immediate action. It answers questions like, "Which products are trending in the last five minutes?" or "Should we flag this transaction as fraudulent right now?" The choice you make doesn't just define how you move data—it defines what you can actually do with it.
Analyzing the Trade-Offs: Latency, Consistency, and Cost
Picking between real-time and batch processing isn't just a technical fork in the road. It’s a strategic decision that forces you to weigh three competing priorities: speed (latency), accuracy (data consistency), and budget (operational cost). Getting this balance right is crucial because improving one almost always means sacrificing another.
The most obvious trade-off is latency. Real-time processing is all about sub-second responsiveness, getting data from source to destination the moment it’s born. This kind of immediacy is table stakes for use cases like fraud detection, where a few seconds of delay can mean thousands in lost revenue.
Batch processing, on the other hand, fully embraces latency. Its strength is chewing through massive volumes of data efficiently, but that efficiency comes at the price of freshness. Data from a nightly batch job is, by definition, hours old. That’s perfectly fine for historical analysis but a non-starter for in-the-moment operational decisions.
The Consistency Conundrum
Data consistency is another major point of difference. Batch processing gives you predictable, strong consistency. Once a batch job is done, you have a clean, static, and internally consistent snapshot of the data from a specific point in time.
This is a must-have for things like financial reporting or compliance audits, where every calculation has to be based on the exact same dataset to be accurate and defensible. You can't have new transactions trickling in while you're trying to close the books on a quarter.
Real-time streaming systems usually work on a model of eventual consistency. Data flows in as a constant stream of events. While individual components in the system update quickly, there's no single moment where the entire distributed setup is guaranteed to be perfectly in sync. For operational dashboards or live inventory tracking, this is more than acceptable—having the latest data point is far more valuable than a perfectly synchronized global view.
The core difference is simple: Batch provides a perfect picture of the past, making it ideal for reporting. Real-time provides a continuous, slightly blurry view of the present, making it essential for immediate action.
Balancing the Budget: Cost vs. Value
Ultimately, cost is often the deciding factor that puts practical limits on any data strategy. From a pure compute standpoint, batch processing is almost always cheaper. There’s a reason enterprise data warehouses have relied on scheduled batch ETL for decades: it’s brilliant at optimizing resource utilization. In fact, some industry analyses suggest that running heavy analytical workloads as batch jobs during off-peak hours can slash compute costs by 30–70% compared to provisioning an equivalent always-on streaming cluster. For more details, you can explore the insights on csgi.com.
Real-time systems require a different kind of financial thinking. They need "always-on" infrastructure ready to handle data streams 24/7. This constant state of readiness means you have to provision for peak capacity, which naturally drives up baseline infrastructure costs. The operational headache of managing complex tools like Kafka and Flink can also be significant if you're not using a managed platform.
But you can't just look at the infrastructure bill. The real "cost" has to be weighed against the business value you create or the losses you prevent. A real-time fraud detection system might cost more to run, but if it stops millions in fraudulent charges, the ROI is immediate and obvious. For teams wanting to get the most out of their real-time setup, it's worth exploring how to reduce latency in their data pipelines.
The real-time vs batch processing debate always comes down to what your business truly needs from its data. The table below breaks down these trade-offs in the context of common business scenarios.
There’s no universal right answer here; it's always about context. A major e-commerce platform will likely use real-time streams for managing inventory and fraud alerts while running batch jobs for its quarterly sales reports. The key is to leverage the strengths of each approach where they matter most.
When to Choose Real-Time Processing for Business Impact
Batch processing is perfect for looking back at what happened yesterday or last quarter, but some business operations need answers right now. In these situations, real-time processing isn't just a technical choice—it's a competitive necessity where every millisecond of delay costs you something. The question stops being "What happened?" and becomes "What's happening, and what should we do about it?"
To get those immediate insights, most businesses end up leveraging robust cloud solutions that can handle the scale and speed required. This is especially true in industries where a few seconds of lag can mean lost revenue or a customer heading to a competitor.
Driving Immediate Business Value
It's no surprise that companies are rapidly adopting real-time data pipelines. By 2024, 62% of large enterprises were running at least one, a huge leap from just 38% in 2019. This trend is fueled by needs like fraud detection and dynamic personalization, where systems have to react in under 100 milliseconds.
This simple flowchart breaks down the core decision. If you need answers in less than a second, you're in real-time territory.
If your operations can wait, batch is often the more practical choice. But when immediacy matters, real-time is the only way forward.
Critical Real-World Applications
Let's get practical. Here are a few clear examples where a batch approach just wouldn't cut it, and an event-driven, real-time architecture delivers real business value.
1. Financial Fraud Detection
Credit card transactions are approved or denied in a blink. A batch system that checks for fraud at the end of the day is completely useless—the money would already be gone.
- Real-Time Impact: An event-driven system analyzes transaction data against risk models the very instant a card is swiped. It can flag and block a suspicious purchase before it's approved, saving millions in potential losses and protecting customer accounts.
2. E-commerce Dynamic Pricing
In online retail, prices from competitors, inventory counts, and customer demand fluctuate by the minute. A pricing engine that updates once a night is always going to be a step behind the market.
- Real-Time Impact: A streaming architecture constantly pulls in market signals, letting an e-commerce site adjust prices on the fly. This means you can maximize profit on hot items and strategically discount slow-movers to clear stock, directly boosting the bottom line.
The true power of real-time processing is its ability to close the gap between an event happening and the business taking intelligent action on it. This proactive capability is something batch processing, by its very design, can never offer.
3. Real-Time Inventory and Supply Chain Management
A retailer using a daily inventory report won't realize a popular product is sold out until hours later. That's a recipe for lost sales and unhappy customers who can't find what they want.
- Real-Time Impact: By streaming sales and inventory data from point-of-sale systems and warehouses, a business gets an up-to-the-second view of what's on the shelf. This unlocks automated reordering, prevents stockouts, and gives the supply chain team the visibility they need to make smart logistical moves.
How to Transition from Batch to Real-Time with Managed CDC

Making the jump from scheduled batch jobs to a continuous, real-time data model is a huge step forward for any data stack. The business upsides are obvious, but the path is often littered with technical hurdles that can kill a project before it even gets off the ground. Let's be honest: building and maintaining a resilient real-time pipeline is a whole different beast compared to managing periodic batch ETL.
This isn't just about processing data faster; it's a fundamental shift to an event-driven way of thinking. Batch systems are built for predictable, offline work. Real-time systems, on the other hand, have to run 24/7, absorb unpredictable spikes in data, and ensure every bit of data is accurate—all with millisecond latency. This demands a completely different set of tools and a much deeper level of expertise.
Common Hurdles in the Migration Journey
The biggest roadblock is almost always the immense operational overhead of trying to manage a distributed streaming ecosystem on your own. To build a solid real-time pipeline from scratch, your engineering team suddenly needs to become experts in a handful of notoriously complex open-source technologies.
- Apache Kafka: Just standing up a Kafka cluster is a challenge. You have to nail the configuration for partitioning, replication, and security. Keeping it highly available with zero data loss isn't a side project; it's a full-time job.
- Apache Flink: For processing and transforming data on the fly, Flink is incredibly powerful, but it’s also demanding. You have to manage its state, handle checkpoints for fault tolerance, and constantly optimize how it uses resources. This requires deep, specialized knowledge.
- Connectors and Integration: Building and maintaining all the connectors to pull data from sources (like your production databases) and push it to destinations (like a data warehouse) is a thankless, never-ending task.
These pieces form a fragile system where one small misconfiguration can cause data loss, stalled pipelines, or a complete system meltdown. The engineers with the skills to manage this kind of infrastructure are hard to find and expensive to hire, pulling them away from building the products that actually make money.
The Managed CDC Advantage
This is exactly where a managed Change Data Capture (CDC) platform like Streamkap changes the game. Instead of you building all that complex plumbing, a managed service abstracts away the entire infrastructure nightmare. It gives you a reliable, scalable, and zero-ops solution that takes care of the hardest parts of the real-time vs batch processing migration. If the concept is new to you, it’s worth reading up on https://streamkap.com/resources-and-guides/what-is-change-data-capture to see how it works.
A managed CDC platform handles the most difficult and error-prone parts of building a real-time pipeline for you.
By offloading the management of Kafka, Flink, and connectors, a managed CDC solution transforms a high-risk, multi-year infrastructure project into a predictable, streamlined process. This allows teams to focus entirely on the business logic and value of their data, not the underlying mechanics of moving it.
This approach gives you all the power of real-time data without the operational headaches, making the switch from batch processing both faster and much more cost-effective.
A Practical Roadmap for Modernization
Moving from an old-school batch system to a modern, real-time streaming model is a strategic play that opens up entirely new possibilities. With a managed CDC platform, the path forward becomes clear and, more importantly, achievable.
Key Benefits of a Managed Approach:
- Reduced Operational Cost: You don't have to hire a specialized team of Kafka and Flink experts. The total cost of ownership is often 5x lower than trying to build and manage it all yourself.
- Low-Impact Data Capture: It uses log-based CDC to stream changes from your source databases without adding any performance load—a huge difference from the resource-intensive queries that batch jobs run.
- Guaranteed Data Integrity: You get built-in fault tolerance and exactly-once processing, which means every single event is delivered reliably and in the right order.
- Automated Schema Evolution: It automatically detects and handles changes in your source data schemas without needing someone to step in manually. This alone prevents countless broken pipelines and saves a ton of developer time.
In the end, a managed CDC platform is an accelerator. It lets your organization skip the steepest parts of the learning curve and start seeing the benefits of real-time data right away, turning a complex architectural shift into a straightforward project.
Common Questions About Data Processing
When you're deep in the weeds of data architecture, a lot of practical questions pop up. Let's tackle some of the most common ones that teams face when figuring out where real-time and batch processing fit into their world.
Can Real-Time and Batch Processing Really Work Together?
Absolutely. In fact, a hybrid approach isn't just possible—it's usually the smartest way to build a modern data platform. You get the best of both worlds, creating an architecture that’s both powerful and practical.
Here’s how to think about it: A company might use real-time streaming for its operational systems where speed is everything. Think fraud detection alerts, live inventory dashboards, or website personalization that reacts to a user's clicks in the moment. These things can't wait.
At the same time, that same company will lean on batch processing for heavy-duty analytics and reporting. This is perfect for less time-sensitive tasks, like running end-of-day financial reports, crunching massive datasets in the data warehouse, or training machine learning models on years of historical data. Using both lets you pick the right tool for the job, balancing performance with cost.
What’s the Toughest Part of Switching from Batch to Real-Time?
The single biggest jump is the massive increase in operational complexity. Batch jobs are pretty forgiving; they run on a schedule, do their thing, and shut down. A real-time streaming pipeline is a completely different animal—it has to be up and running 24/7, with rock-solid availability.
You're suddenly managing a whole ecosystem of distributed systems, like Apache Kafka for message queues and Apache Flink for stream processing. Your engineers now have to wrestle with problems that just don't exist in the batch world:
- Backpressure: What happens when data is coming in faster than your downstream systems can handle it?
- Data Ordering: How do you make sure events are processed in the right sequence to avoid logical errors?
- Exactly-Once Semantics: How can you guarantee that no data is ever lost or duplicated, even when a server fails?
This is exactly the kind of headache that managed platforms were built to solve. They handle all that gnarly infrastructure complexity, giving you a reliable, scalable, and zero-ops way to move data in real time. This frees up your team to focus on building things that matter to the business, not babysitting systems.
Where Does Change Data Capture Fit into This?
Change Data Capture (CDC) is the key that unlocks a lot of modern real-time pipelines. Instead of the old batch method of hammering the source database with heavy queries every few hours, CDC is far more elegant and efficient.
It works by directly reading the database's internal transaction log—the immutable record of every single change made. By tapping into this log, CDC captures every row-level modification (INSERT, UPDATE, and DELETE) the instant it happens.
That change is immediately turned into a lightweight event and sent down a stream for real-time processing. The beauty of this is that it has a tiny performance impact on the source database and ensures you never miss a single change. CDC is the engine that powers low-latency data replication and is essential for building resilient, event-driven architectures.
Is Real-Time Processing Always More Expensive?
If you're just looking at the raw infrastructure bill, then yes, real-time processing often has a higher starting cost. It requires "always-on" compute resources that are ready to handle a continuous flow of data, including unexpected spikes. Batch jobs, on the other hand, can often be run during off-peak hours using cheaper, temporary resources.
But just comparing server costs is a classic mistake. You have to look at the Total Cost of Ownership (TCO) and, more importantly, the business value it creates. For the right use cases, the math changes completely.
A real-time fraud detection system might cost more to run, but if it prevents even a handful of major fraudulent transactions, it can deliver an ROI that dwarfs the infrastructure expense. You also have to factor in the high cost of hiring and retaining specialized engineers to manage complex streaming platforms. A managed service can slash the TCO of a real-time system, making it a much more accessible and financially sound choice.
Ready to modernize your data stack without the operational overhead? Streamkap provides a managed, zero-ops platform for real-time CDC, allowing you to transition from batch to streaming pipelines in minutes, not months. Start building your real-time data pipelines today.