How to Reduce Latency: Proven Tips for Faster Systems
Learn how to reduce latency effectively. Discover actionable strategies to minimize delays and boost your system's performance today!

When you’re trying to reduce latency, you’re essentially fighting to shrink the delay before a data transfer even starts. The goal is to make your systems feel instantaneous. To get there, you need to chip away at the four main sources of that delay: propagation, transmission, processing, and queuing. By tackling each of these, you’ll see a real difference in your application’s speed.
What Latency Really Is and Why It Matters

Before we can get into fixing latency, we have to be clear on what it actually is. It’s easy to mix it up with bandwidth, but they’re two different beasts.
Imagine a highway. Bandwidth is the number of lanes—how much traffic can move at the same time. Latency, on the other hand, is the time it takes for a single car to get from point A to point B. Even if you have a massive, 10-lane superhighway, it still takes time to drive across the country. That time is latency.
This delay isn’t just a number on a monitoring dashboard. It has a direct, and often painful, impact on user experience and your bottom line. In a world where people expect instant results, even a tiny delay can be enough to drive them away.
The Real-World Impact of High Latency
When latency creeps up, you feel it immediately. Think about a video call where the audio keeps cutting out or the video freezes just as someone is making a key point. That’s a classic latency problem. Or picture an e-commerce site where you scroll down and have to wait as product images slowly pop into view. That friction leads straight to abandoned carts and lost sales.
In some fields, the stakes are much, much higher. For a high-frequency trading firm, a few milliseconds of delay can literally mean the difference between making or losing millions. For an online gamer, high latency—what they call “lag”—can make a competitive game completely unplayable.
These examples make it clear: getting latency under control is a critical business priority. A key strategy companies use to minimize these delays is real-time data streaming.
Understanding the Four Core Sources of Delay
To really get a handle on latency, you have to know where it’s coming from. Every single delay in your data pipeline can be traced back to one of four culprits. Knowing which one is causing you the most grief is the first step toward building a faster, more responsive system.
Key Takeaway: Latency isn’t one single problem. It’s a combination of delays from different sources. The trick is to find your biggest bottleneck and attack that first.
Let’s break down the four sources:
- Propagation Delay: This is simply the time it takes for a signal to travel the physical distance between two points. It’s governed by the speed of light, so geographic distance is the biggest factor here. Data can’t travel from New York to Tokyo instantly.
- Transmission Delay: This is the time it takes to push all the bits of a data packet onto the network link. Think of it as loading passengers onto a bus. This depends on the size of the packet and the bandwidth of the connection.
- Processing Delay: This is the time a router or a server needs to handle a data packet—reading its header, checking for errors, and figuring out where to send it next. Every hop adds a little bit of processing time.
- Queuing Delay: This is the time a packet spends sitting in a line (a queue) at a router or switch, waiting its turn to be processed. This is what happens when you hit network congestion, just like a traffic jam on the highway.
Finding and Measuring Your Latency Bottlenecks

Before you can start slashing latency, you have to figure out where it’s hiding. It’s easy to fall into the trap of guessing, which often leads to optimizing components that aren’t the real culprits. To make any meaningful progress, you need to stop guessing and start measuring.
A simple ping test might tell you if a server is online, but it barely scratches the surface. To truly understand what’s slowing down your data pipeline, you have to dig deeper. Think of yourself as a detective hunting for clues. Your mission is to find the exact stage where data gets stuck, whether it’s during a cross-country network hop, a complex database query, or a slow-moving application process.
Moving Beyond Basic Diagnostics
To get a real feel for your system’s latency, you need to look at specific metrics that tell a story about different parts of the data’s journey. Two of the most important metrics I always start with are Round-Trip Time (RTT) and Time to First Byte (TTFB).
RTT gives you a baseline for network delay by measuring the total time it takes for a packet to travel from a source to a destination and back again. It’s your go-to for understanding raw network performance.
TTFB, on the other hand, tells you how long it takes for a browser to receive the very first byte of data after making a request. A high TTFB is a classic sign of a server-side problem—think slow database queries or clunky application logic—rather than just a slow network connection.
By looking at both RTT and TTFB together, you can start to distinguish between network-level slowdowns and application-level bottlenecks. This distinction is absolutely critical; it tells you exactly where to focus your energy.
Powerful Tools for Comprehensive Monitoring
To capture and analyze these metrics, you’ll need to bring in some specialized tools. These platforms are built to give you a deep, granular view of your entire infrastructure.
Here are the types of tools I find most effective:
- Application Performance Management (APM): Tools like Datadog or New Relic are fantastic because they trace requests as they move through your actual code. They can pinpoint the exact database query that’s taking forever or identify the one microservice that’s causing a logjam.
- Network Monitoring Platforms: These focus on the pipes themselves. They track things like packet loss, jitter, and RTT across your network, helping you spot congestion or failing hardware before they become a full-blown crisis.
- Real User Monitoring (RUM): This is where you get the user’s perspective. RUM tools collect performance data directly from your end-users’ browsers, giving you invaluable insight into how latency actually feels for people in different parts of the world, on different devices, and with varying network quality.
The final step is to bring all this information together. I always recommend setting up a central monitoring dashboard that pulls data from these tools. A well-designed dashboard gives you an at-a-glance view of the entire pipeline, from the user’s first click to the final database write. This is what turns the abstract problem of “latency” into a concrete, data-driven action plan.
Optimizing Your Infrastructure to Cut Down on Latency
When you’re hunting for ways to speed up your data pipeline, your physical and cloud infrastructure is often the place to find the biggest wins. Fine-tuning your code is important, but nothing impacts speed more directly than the foundational decisions you make about where your data lives and how it travels. Get this right, and you can transform a sluggish system into a remarkably responsive one.
The single biggest enemy of low latency? Physical distance. Data moves incredibly fast, but it’s not instant. Every mile between your user and your server adds a tiny but real delay. When you’re talking about data crossing continents, those milliseconds stack up fast, creating the kind of lag that frustrates users and kills performance.
Beat the Distance with Edge Computing and CDNs
The most effective way to solve the distance problem is simple in concept: move your data closer to the people who need it. This is the whole idea behind edge computing and Content Delivery Networks (CDNs).
A CDN is a classic solution. It works by caching static assets—like images, videos, and CSS files—on servers located all over the world. When a user in London requests an image, they don’t have to wait for it to travel from your main server in California. The CDN serves it from a local server right there in London, slashing the round-trip time and making everything feel snappier.
Edge computing takes this a step further. It lets you run actual application logic on these distributed servers, not just serve static files. This is a game-changer for tasks like real-time data processing or interactive applications where even a tiny delay can ruin the experience.
This chart really drives home why shrinking that network travel time is so critical.
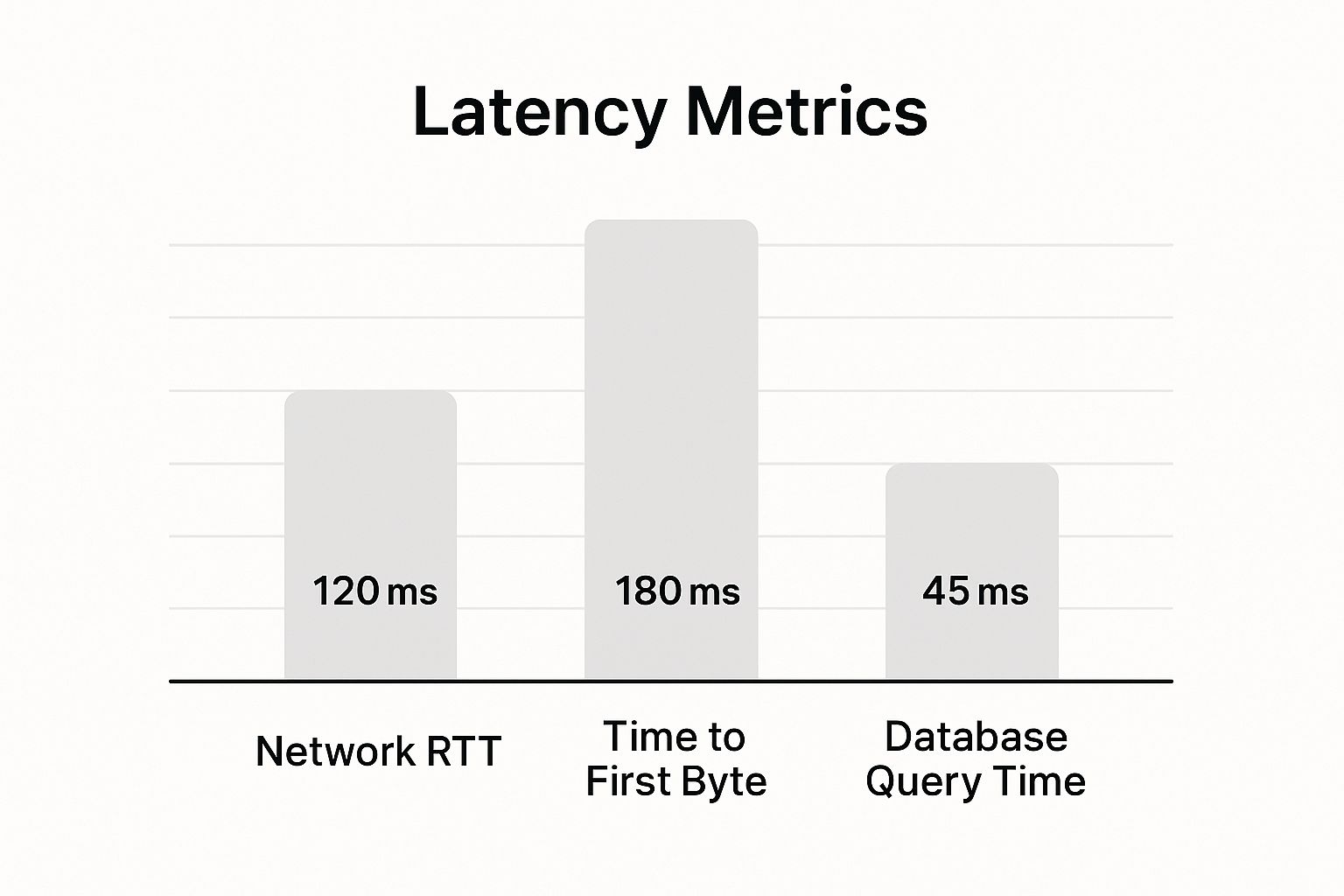
As you can see, the Network RTT (Round Trip Time) and Time to First Byte are often the biggest culprits behind latency, and both are directly tied to your infrastructure choices.
Making Smart Cloud Architecture Decisions
For the dynamic parts of your application, your cloud architecture is everything. The way you set up your regions, availability zones, and virtual networks can either create bottlenecks or build a high-speed highway for your data. When you’re looking to improve performance, it’s worth exploring different approaches for optimizing cloud computing that focus on this principle.
One of the most common mistakes I see is a poorly planned multi-region deployment. Imagine your application server is in a us-east-1 region, but its primary database is running in us-west-2. Every single database query now has to make a round trip across the entire country. That’s a huge, self-inflicted latency penalty.
Key Takeaway: Co-locating your application components is one of the most powerful and straightforward ways to reduce internal latency. The closer your compute and storage resources are, the faster they can communicate.
The impact here isn’t trivial. Studies have shown that deploying application components in the same region and availability zone can slash latency by up to 80% compared to a cross-region setup. For hybrid environments connecting on-premise data centers to the cloud, using a direct connection like VPC Peering can cut delays by 50% over sending traffic across the public internet.
Choosing the right cloud setup is a critical step in building a low-latency system. The table below compares a few common strategies to help you decide.
Cloud Architecture Impact on Latency
Deployment StrategyTypical Latency ImpactBest ForSingle-Region DeploymentLowest internal latencyApplications with a geographically concentrated user base.Multi-Region DeploymentHigher internal latency, lower user-facing latencyGlobal applications needing high availability and disaster recovery.**Hybrid Cloud (VPN)**Moderate to high latencyExtending on-premise systems to the cloud with standard security.**Hybrid Cloud (Direct Connect)**Low, consistent latencyHigh-performance hybrid applications requiring stable, private connections.
Ultimately, by carefully picking cloud regions based on where your users are and making sure your interdependent services are neighbors, you can eliminate a massive source of unnecessary delay from your system.
Fine-Tuning Your Software and Protocols

You can have the most powerful infrastructure money can buy, but inefficient software will bring it to its knees every time. Once your hardware and network paths are solid, the next battleground for latency reduction is inside your code and the protocols it speaks.
This is where surgical changes can deliver massive performance boosts.
Let’s start with the protocols that govern data transfer. The classic trade-off is between TCP (Transmission Control Protocol) and UDP (User Datagram Protocol). TCP is the reliable workhorse, guaranteeing every packet arrives in order, which is critical for file transfers but comes with a cost in overhead.
On the other hand, UDP is the sprinter—fast and lean. It sends data without waiting for confirmation, which is ideal for latency-sensitive applications like video streaming or gaming, where speed trumps the occasional lost packet. Even switching to modern protocols like HTTP/3, which runs over UDP, can slash latency by cutting out the connection handshake delays that bogged down older versions.
Digging into Your Application and Database
Beyond the network, your application’s logic is often a minefield of hidden delays. From my experience, inefficient database queries are one of the most common culprits, creating bottlenecks that cascade through the entire system.
It only takes one poorly written query to lock up tables and leave other processes waiting. To get ahead of this, your team should be laser-focused on:
- Smart Indexing: Make sure your database tables are properly indexed on columns used in
WHEREclauses. This is low-hanging fruit for speeding up data retrieval. - Query Analysis: Get familiar with tools like
EXPLAIN. They show you the execution plan for your queries, instantly highlighting slow or inefficient operations that need fixing. - Change Data Capture (CDC): Instead of hammering a database with constant queries to check for new data—which adds load and latency—CDC-based systems stream changes the moment they occur. If you’re using PostgreSQL, understanding the details of https://streamkap.com/resources-and-guides/postgres-change-data-capture can help you build incredibly responsive data pipelines.
The global race to crush latency is no joke. For instance, 28% of global companies report losing up to $5 million due to poor network performance. It’s a stark reminder that software-level optimizations are just as crucial as big-budget infrastructure upgrades. You can dig into the costs of network latency from M247 for more on this.
Smart Caching and Connection Management
Caching is another powerful weapon in your arsenal. By storing frequently accessed data somewhere faster and closer (think in-memory caches), you can eliminate slow roundtrips to the primary database or disk. A multi-layered caching strategy that combines browser, CDN, application, and database caching creates a system that’s both resilient and incredibly fast. For a broader look at performance, you can find great tips in this guide on how to optimize laptop performance for speed and reliability, which touches on both software and hardware.
Finally, don’t overlook how you manage connections. Opening and closing connections to a database over and over again is incredibly wasteful. This is where connection pooling comes in; it maintains a pool of active connections ready for use, which cuts out the setup and teardown overhead for every request.
Similarly, using HTTP keep-alives lets you reuse a single TCP connection for multiple requests—another simple but effective trick for shaving precious milliseconds off your response times.
Advanced Strategies for Ultra-Low Latency
Once you’ve exhausted the standard optimizations, squeezing out those last few milliseconds requires a much more aggressive approach. In worlds like high-frequency trading or competitive online gaming, where a fraction of a second can make or break you, software tweaks just won’t cut it. You have to start looking at the hardware itself.
Think of it this way: a general-purpose CPU is a jack-of-all-trades, but it’s a master of none. To really slash processing delay, teams often bring in specialized hardware like network offload engines. These are dedicated processors that take on all the network-related grunt work, letting your main CPU focus entirely on running the core application logic.
Pushing Hardware to the Edge
For the most extreme use cases, Field-Programmable Gate Arrays (FPGAs) are the name of the game. FPGAs are essentially customizable circuits you can program to perform one specific task at mind-boggling speeds.
Imagine offloading a critical function—like processing market data or running a complex real-time algorithm—directly onto an FPGA. You’re basically hardwiring the logic, which can shrink processing times from milliseconds down to mere nanoseconds.
This is the kind of optimization you need when every single clock cycle counts. By moving key processes from software to dedicated silicon, you’re stripping away layers of abstraction and overhead, getting as close to the bare metal as possible.
Key Insight: In the hunt for ultra-low latency, the final frontier is often the physical distance data has to travel. Hardware acceleration can crush processing delays, but propagation delay—the time it takes for a signal to get from A to B—is a fundamental challenge dictated by physics.
Radical Infrastructure for a Faster World
The laws of physics set a hard limit on latency, but that doesn’t stop people from trying to build smarter infrastructure to get around it.
A fantastic example is the evolution of satellite internet. According to a performance report from Ookla, one provider using traditional geostationary (GEO) satellites clocked a median latency of 683 ms. In contrast, newer low-Earth orbit (LEO) systems achieved a median of just 45 ms—that’s over 15 times faster. The only difference was bringing the satellites physically closer to Earth.
This huge leap shows how radical, infrastructure-level thinking is a core strategy for fighting latency. These advanced methods aren’t for everyone, of course. But for businesses that live and die by speed, they offer a serious competitive edge. It’s the same principle behind modernizing data architecture, as seen in how Streamkap helped reduce data latency from 24 hours to near real-time for Niche.com.
Common Questions About Reducing Latency
As you start digging into latency optimization, you’ll find a few questions tend to come up over and over again. Let’s get right to them with some practical answers based on real-world experience.
What Is a Good Latency to Aim For?
This is the classic “it depends” answer, but for good reason. There’s no single magic number for “good” latency; it’s completely tied to what your users expect and what your application needs to function well.
For instance, in the world of competitive online gaming, a latency under 20ms is the gold standard—it’s what gives players that split-second, real-time edge. But for general web browsing, anything under 100ms feels snappy and instantaneous. Video streaming can get away with even higher latency because it uses buffering to smooth out the playback.
The first step is always to define the acceptable threshold for your specific use case. Once you have that target in mind, you can start making targeted optimizations to hit it.
Can I Reduce Latency Without Spending a Lot of Money?
Absolutely. It’s a common myth that cutting down latency always requires a big budget. While major infrastructure overhauls like moving cloud regions or bringing in a global CDN have costs, many of the most effective techniques are just smart software engineering.
Pro Tip: Always go for the low-hanging fruit first. You’d be surprised how much you can improve things just by optimizing your existing setup before you even think about writing a check for new hardware or services.
Before you consider spending, pour your energy into these areas:
- Fine-tuning database queries to get rid of slow, clunky operations.
- Switching on HTTP/3 on your web server for faster, more reliable connections.
- Implementing smarter caching to serve data from memory instead of hitting the database every time.
- Compressing your assets—images, scripts, CSS—to make your data payloads smaller.
Start by identifying your biggest bottlenecks, and you’ll likely find that many can be fixed with code, not cash.
How Does a CDN Actually Reduce Latency?
A Content Delivery Network, or CDN, is basically a cheat code against the laws of physics. Its whole purpose is to dramatically shorten the physical distance your data needs to travel to reach a user.
It does this by creating copies of your static content—like images, videos, and stylesheets—and storing them on a massive, worldwide network of servers. When a user in, say, Japan requests a file from your server in Virginia, the request doesn’t travel across the Pacific. Instead, it’s served from a local CDN “edge” server, maybe just a few hundred miles away in Tokyo.
This directly slashes the propagation delay, which is often the single biggest contributor to network latency for a global audience.
Will More Bandwidth Lower My Latency?
This is a really common point of confusion, but the answer is usually no. It’s critical to understand the difference between bandwidth and latency.
Imagine a highway. Bandwidth is how many lanes the highway has. Latency is the time it takes for a single car to get from one end to the other.
Adding more lanes (increasing bandwidth) is fantastic because it allows more cars on the road at once, preventing traffic jams (congestion). But it doesn’t actually make any individual car go faster. The speed limit and the physical distance of the journey (the latency) don’t change. So, more bandwidth helps if your pipeline is clogged, but it won’t do a thing for delays caused by physical distance or slow server response times.
Ready to eliminate data latency in your pipelines? Streamkap uses real-time CDC to replace slow batch jobs, ensuring your data is always up-to-date. See how you can achieve near-instant data synchronization by visiting https://streamkap.com.
Related resources
Kafka Consumer Lag: Causes, Debugging, and Fixes
Consumer lag is the most common Kafka operational issue. Learn what causes it, how to measure it, and practical strategies to bring it under control.
Kafka on Kubernetes: Real-World Lessons
Running Kafka on Kubernetes sounds like a good idea until you hit storage, networking, and operational challenges. Here's what teams learn the hard way and how to avoid the common pitfalls.
Backpressure in Stream Processing: What It Is and How to Handle It
Learn what backpressure means in streaming pipelines, how to detect it, and practical strategies for handling it in Kafka, Flink, and CDC pipelines without losing data.