A Guide to Postgres Change Data Capture
A complete guide to Postgres Change Data Capture. Learn how CDC works, explore different methods, and discover best practices for real-time data pipelines.
Imagine trying to keep a perfect, real-time record of every transaction in a bustling bank. Postgres Change Data Capture (CDC) acts like a silent observer, instantly recording every deposit, withdrawal, and transfer as it happens. Instead of manually checking balances periodically, you get a continuous stream of changes.
What Is Postgres Change Data Capture

Think of a traditional database as a library where you must periodically walk through the aisles, checking every book to see if anything is new or has been moved. This approach, known as batch processing, is slow, resource-intensive, and always provides slightly outdated information.
Postgres Change Data Capture is like having a librarian who instantly notifies you the moment a new book arrives or an old one is checked out. Instead of polling the entire database for changes, CDC monitors the database's internal transaction log. It captures each event as a discrete piece of information and streams it to other systems that need to know about it.
The Shift from Batch to Real-Time Data
Historically, businesses relied on daily or hourly batch jobs to move data between systems. An analytics platform, for example, might sync with the production database every night. However, this creates a significant delay, meaning business decisions are always based on yesterday's information.
CDC fundamentally changes this model. It enables a continuous flow of data, ensuring that downstream systems are always synchronized with the source. This is crucial for modern data needs, where immediacy is key.
The importance of this shift is reflected in market trends. Change Data Capture tools have become a vital part of modern data architectures, propelled by the growth of cloud computing and big data. Industry analysis indicates that the CDC market will see major expansion through 2033, driven by the demand for real-time insights that power faster business decisions. You can learn more about the CDC market's expected growth on datainsightsmarket.com.
Why Capturing Every Change Matters
The core value of Postgres CDC lies in its ability to unlock new capabilities and improve existing processes. By treating data changes as a stream of events, organizations can:
- Power Real-Time Analytics: Feed live data directly into dashboards and business intelligence tools, giving stakeholders an up-to-the-minute view of operations.
- Synchronize Disparate Systems: Keep various databases, microservices, and caches perfectly in sync. For instance, updating a user's profile in one service can instantly trigger updates in all related services.
- Build Responsive Applications: Create event-driven architectures where applications react to data changes immediately, such as sending a notification when an order status changes.
At its heart, CDC turns your database from a passive data store into an active, event-producing system. It allows data to flow where it's needed, precisely when it's needed, without putting a heavy load on the source database.
Understanding How Postgres Natively Supports CDC

To really get why Postgres change data capture works so well, we have to pop the hood and look at how the database is built. It turns out, Postgres has a core feature originally designed for crash recovery that makes it perfect for CDC.
This brilliant piece of engineering is the Write-Ahead Log (WAL).
Think of the WAL as the database’s own flight recorder. Before a single byte of data is changed in the main database files, Postgres first scribbles a note in the WAL detailing exactly what it's about to do. This "log first" rule is what makes Postgres so durable. If the server ever crashes, it just replays the WAL to bring itself back to life, ensuring no committed data is ever lost.
From Physical Replication to Logical Decoding
For a long time, the WAL was mostly used for physical replication. This meant a backup server would read the WAL and mimic the primary server's actions, byte for byte. It’s great for creating an identical clone, but the data is raw and technical—not very useful for anything other than a backup.
That's where logical decoding changed the game.
Introduced back in PostgreSQL 9.4, logical decoding is the magic translator that unlocks native CDC. It takes those dense, technical WAL entries and converts them into a clean, human-readable stream of events. Instead of seeing low-level file changes, you get a clear message: "A new row was inserted," "this record was updated," or "that one was deleted," along with the actual data.
Logical decoding essentially turns the WAL from a simple recovery log into a live, real-time feed of everything happening in your database. External tools can just subscribe to this feed without needing to know a thing about Postgres's internal plumbing.
This gives us a high-performance, low-impact way to stream changes. Since we're just tapping into a process that's already running, we completely sidestep the performance drain that comes with old-school methods like triggers.
The Key Components of Logical Decoding
To get this whole system running smoothly, a few pieces need to be in place. They all work together to create a reliable stream of changes that other applications can count on.
- Replication Slots: A replication slot is basically a bookmark in the WAL stream for a specific consumer. It’s a crucial safety net. The slot tells Postgres, "Hey, don't delete these log files yet; my application hasn't read them." This guarantees that even if your consumer app goes offline for a while, it won't miss a single change when it comes back.
- Output Plugins: An output plugin is the formatter. It takes the decoded data from the WAL and shapes it into a specific format. Postgres has a built-in plugin called
pgoutput, but many teams use popular alternatives likewal2jsonto get the change events neatly packaged in a JSON format that's super easy for other services to work with. - Logical Replication Protocol: This is the language that clients use to talk to Postgres to stream the changes. It's the set of commands for creating a replication slot, telling the database to start sending data, and acknowledging that the data has been received.
These three components are the bedrock of native Postgres change data capture. The WAL provides the immutable source of truth, logical decoding makes it understandable, replication slots make it reliable, and output plugins make it usable. It’s an elegant system that makes Postgres a fantastic foundation for any modern, data-driven architecture.
Choosing Your Postgres CDC Implementation Method
When you're ready to set up Postgres change data capture, you'll find yourself at a fork in the road. The path you choose will have a major impact on your data architecture's performance, complexity, and overall reliability. There’s no single "best" answer here; the right approach really depends on your project's specific needs, your team's technical skills, and what you're trying to achieve.
You have three main options. We’ll look at the classic trigger-based method, the modern standard of native logical decoding, and the streamlined approach of using a fully managed CDC platform. Picking the right one from the start is the key to building a real-time data pipeline that will stand the test of time.
The Traditional Trigger-Based Approach
The oldest trick in the book for capturing changes is using database triggers. A trigger is essentially a small piece of code that you tell the database to run automatically whenever a certain event happens—like an INSERT, UPDATE, or DELETE on a specific table.
In this setup, you create a trigger for every table you want to watch. When a row is modified, the trigger immediately fires and writes a copy of that change into a separate "audit" or "shadow" table. From there, your other applications can periodically check this audit table to see what's new.
While this method is pretty easy to grasp and set up, it has some serious downsides. Those triggers add a little bit of overhead to every single transaction, which can really bog down your main database, especially when things get busy. They also create a tight coupling between your CDC logic and your database schema, making future schema migrations a lot more painful to manage.
Native Logical Decoding: The Modern Standard
For most modern systems, native logical decoding is the way to go for Postgres change data capture. As we touched on earlier, this technique plugs directly into PostgreSQL's Write-Ahead Log (WAL)—the same journal the database relies on for its own replication and recovery processes.
This approach is incredibly efficient because it hooks into a core process that Postgres is already running. The performance hit on your source database is minimal, since it isn't adding extra work to your transactions. Because the WAL is an ordered, unchangeable log of everything that happens, you get a perfect, complete, and correctly sequenced record of all changes.
By using logical decoding, you effectively separate your CDC process from the database's day-to-day workload. This decoupling is a game-changer for building high-performance, resilient systems that can scale without dragging down your primary applications.
The catch? Building a custom solution with logical decoding isn't a walk in the park. It demands a lot of engineering effort. You'll be responsible for managing replication slots, figuring out failover scenarios, guaranteeing exactly-once processing, and wrestling with the complexities of creating initial data snapshots.
Managed CDC Platforms: The Hands-Off Solution
The third option is to let someone else do the heavy lifting by using a managed CDC platform like Streamkap. These services are built on the power of logical decoding but hide all the messy details behind a simple interface. They give you a complete, production-ready solution for streaming data from Postgres to destinations like data warehouses or event streaming platforms.
This infographic gives you a glimpse of the performance you can expect from a well-designed Postgres CDC pipeline, showing key metrics like ingestion rates and latency.
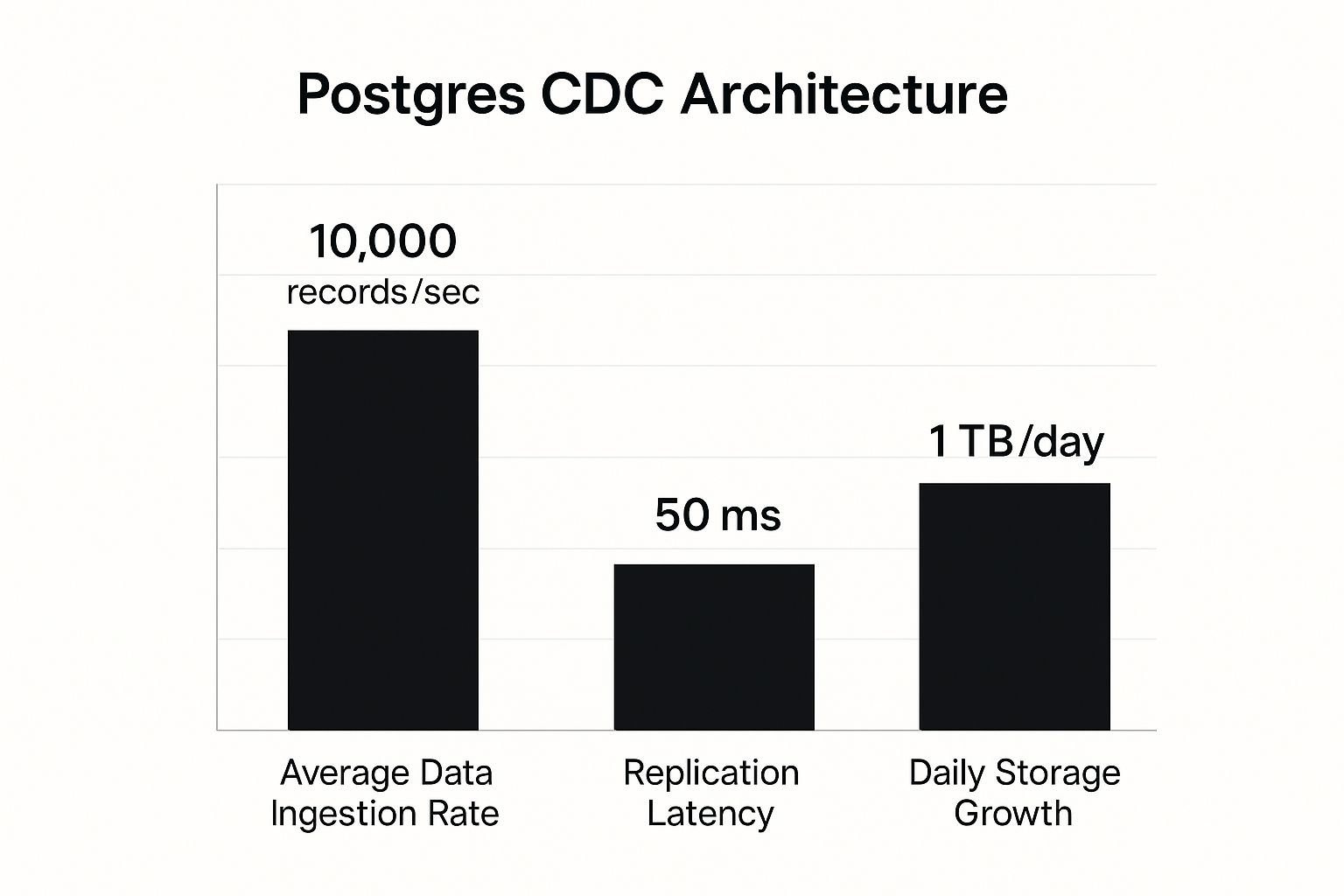
As the chart shows, modern CDC pipelines are built for speed and scale. They can handle thousands of records per second while keeping your data fresh and nearly real-time.
With a managed platform, you get all the performance perks of logical decoding without any of the operational headaches. These platforms typically come packed with features that make life easier:
- Automated Setup: Just connect to your database, point to a destination, and the platform takes care of everything in between.
- Schema Evolution: The service automatically detects schema changes in your source tables and propagates them downstream, so your pipelines don't break.
- Resilience and Fault Tolerance: These platforms are designed for high availability, with built-in failover and recovery mechanisms to keep the data flowing.
- Exactly-Once Guarantees: They ensure every change event is processed once and only once, preventing lost data or messy duplicates.
This approach is perfect for teams that want to focus on using their data, not on building and maintaining the plumbing to move it. It’s the fastest way to get into production and often has a much lower total cost of ownership in the long run.
Comparison of PostgreSQL CDC Implementation Methods
To help you decide, let's put these three methods side-by-side. This table compares the key characteristics of each approach, helping you see the trade-offs at a glance.
MethodPerformance ImpactLatencyReliabilityEase of SetupTriggersHigh (adds overhead to transactions)Low to MediumModerate (can be complex)EasyNative Logical DecodingLow (taps into existing WAL)LowHigh (guaranteed delivery)HardManaged PlatformLow (uses logical decoding)Very LowVery High (built-in resilience)Very Easy
Ultimately, choosing your implementation method is a strategic decision. While triggers offer a quick way to get started, the performance penalty makes them a poor choice for most serious production systems. Native logical decoding is a powerful and efficient foundation, but it requires specialized expertise to build and maintain.
For most businesses looking for a robust, scalable, and low-maintenance solution, a managed platform strikes the perfect balance between top-tier performance and operational simplicity.
Exploring Popular Tools for Postgres CDC

Knowing the theory behind logical decoding is one thing, but putting it into practice means picking the right tool for the job. You could certainly build a custom solution from scratch, but why reinvent the wheel? A whole ecosystem of powerful open-source and managed tools has emerged to handle the heavy lifting.
These tools are specifically designed to tackle the tricky parts of Postgres change data capture, like guaranteeing data consistency, managing replication slots, and gracefully handling schema changes.
The best choice really boils down to your team’s technical skills, your current tech stack, and just how much operational work you’re willing to take on. Let’s break down some of the most common options out there.
Debezium for an Open-Source Approach
If your team lives and breathes Kafka, Debezium is probably already on your radar. It’s a robust, open-source platform that has become a go-to for change data capture. It works as a source connector for Kafka Connect, hooking directly into PostgreSQL’s logical decoding feature to convert database changes into a clean, well-structured stream of events.
From there, it sends those events straight to Kafka topics, making Debezium a natural fit for event-driven systems. You can effectively turn your trusty Postgres database into a real-time event firehose, perfect for everything from keeping microservices in sync to feeding live data into analytics dashboards.
The catch? Its power comes with a price: operational overhead. Running Debezium means you're also on the hook for managing Kafka and Kafka Connect clusters. That’s a significant responsibility that demands real expertise in monitoring, scaling, and maintaining those complex distributed systems.
Debezium gives engineers incredible flexibility and fine-grained control over their data pipelines. Think of it as a "batteries-included but assembly-required" solution that truly shines in sophisticated, Kafka-centric environments.
Managed Low-Code Platforms
At the other end of the spectrum, you’ll find managed, low-code data integration platforms like Fivetran and Airbyte. These tools are all about simplifying the entire data pipeline process, hiding the gnarly details of CDC behind a clean, user-friendly interface.
With these platforms, launching a Postgres change data capture pipeline can be as simple as a few clicks in a web UI:
- Connect your source: Just plug in your PostgreSQL database credentials.
- Pick your destination: Point it to a data warehouse like Snowflake or a data lake.
- Go live: The platform takes over, handling the initial data snapshot and then seamlessly streaming all subsequent changes.
This kind of service is a lifesaver for teams that need to get data flowing quickly without tying up engineering resources on infrastructure management. They take care of schema drift, ensure data lands where it should, and offer a reliable, set-it-and-forget-it experience. For a managed, real-time solution, check out this powerful PostgreSQL connector from Streamkap.
The trade-off, of course, is that you give up some of the granular control you'd get with Debezium, and you’ll typically be looking at a consumption-based pricing model.
The Build vs. Buy Decision
Real-time data is no longer a luxury; it’s a core piece of modern infrastructure, and that has made CDC a hot commodity. The market for Change Data Capture technology has seen a flurry of major acquisitions and investments. Since 2015, there have been over 15 significant acquisitions of CDC-focused companies, with some deals running into the billions.
Look at Qlik’s purchase of Talend for $2.4 billion in May 2023. This kind of market consolidation sends a clear signal: building and maintaining robust CDC is incredibly difficult and resource-intensive. It's a problem that even the biggest engineering organizations often decide to buy a solution for rather than build their own.
Ultimately, picking a tool is a balancing act between control, cost, and convenience. Debezium gives you maximum control if you have the in-house expertise, while managed platforms deliver speed and simplicity for teams who just want to focus on the results.
Where Postgres CDC Really Shines: Use Cases & Business Impact
Okay, so we've covered the "how" of Postgres change data capture. But the real magic happens when you see what it can actually do for a business. Moving past the technical jargon, CDC is what transforms your database from a simple, static storage box into a living, breathing source of events that can power some seriously impressive applications.
This isn't just about chasing the latest tech trend. The shift to real-time data is a direct answer to the market's demand for faster, smarter, and more accurate information. And with PostgreSQL's popularity exploding, this need is more pressing than ever. In fact, by 2025, PostgreSQL is expected to grab a 16.85% share of the relational database market. Even more telling, nearly 12% of massive companies—those with over $200 million in revenue—are already running it in production. This level of enterprise trust is exactly why robust CDC solutions are no longer a "nice to have." You can dig deeper into PostgreSQL's market growth at experience.percona.com.
Powering Real-Time Analytics and Live Dashboards
One of the quickest wins with Postgres CDC is bringing analytics dashboards to life. Remember the old way? A slow, clunky ETL job would run overnight, dumping data into a warehouse. This meant every decision was based on information that was hours, if not a full day, out of date.
CDC flips that script entirely. By streaming every single insert, update, and delete into your data warehouse or analytics engine the moment it happens, you unlock a new reality for your business.
- See Your Operations Live: Imagine tracking sales, inventory levels, or user engagement in real-time. No more waiting. You can spot trends and react to problems instantly.
- Make Sharper Decisions: When leadership has the most current data at their fingertips, guesswork goes out the window.
- Understand Customers Now: Analyze user behavior as it's happening to personalize their experience or smooth out friction points on the fly.
Building Bulletproof, Highly Available Systems
Postgres CDC is also a linchpin for modern disaster recovery. How? By constantly replicating every data change to one or more standby databases, often in completely different parts of the world.
If your primary database ever goes down—whether due to hardware failure or a regional outage—a replica can be promoted to take over in seconds. The result is minimal disruption and, crucially, minimal to no data loss. This goes way beyond simple nightly backups; it's about engineering systems that are genuinely resilient to chaos.
Keeping Your Microservices in Sync
In a microservices world, you often have a bunch of different services, each with its own private database. This creates a huge headache: how do you keep data consistent across all of them? For instance, if a customer updates their address in the "Accounts" service, the "Shipping" service needs to know about that change right now.
CDC offers a brilliantly simple solution: turn database changes into events. The "Accounts" service simply publishes an "AddressUpdated" event. Any other service that cares about addresses can subscribe to this event and update its own records. Data stays perfectly synchronized without the services being tightly coupled.
This event-driven pattern is the foundation of modern, scalable systems. By using Postgres change data capture for streaming ETL, development teams can build decoupled architectures that communicate through a reliable stream of events. It’s a win-win that boosts data consistency, system resilience, and overall scalability.
Best Practices for Building a Resilient CDC Pipeline
Getting a Postgres change data capture pipeline up and running is one thing. Building one that can take a punch in a real production environment is another challenge entirely. A truly resilient CDC setup isn't just about shuffling data from point A to B; it's about building a system you can actually trust when things go wrong—and they always do.
Your first line of defense is simply paying attention. Seriously. One of the quickest ways to take down your production database with CDC is to let a replication slot go unmonitored. If your consumer application stalls or dies, that slot will hold onto old Write-Ahead Log (WAL) files indefinitely. Before you know it, your primary database's disk is full, and the whole system grinds to a halt.
A resilient CDC pipeline is one where failures are predictable and recoverable. Proactive monitoring, automated alerting, and robust error-handling are not optional features—they are fundamental requirements for any production system.
Handle Schema Evolution Gracefully
Let's face it: schemas change. It's a fact of life. A new column gets added, a data type gets tweaked, a table gets a new name. Without a solid plan, these routine DDL (Data Definition Language) operations can shatter your data pipeline, leading to lost data or, even worse, corrupted data.
You absolutely need a strategy for schema evolution. Some of the more sophisticated CDC tools like Debezium can capture and pass along DDL changes, but don't assume it's a magic fix. You have to test how your tool reacts to different kinds of schema changes. For anything more than a trivial update, the safest bet is a coordinated rollout:
- Pause Downstream Consumers: Hit pause on whatever applications are listening for those change events.
- Apply DDL to Source: Make the schema change on your main PostgreSQL database.
- Update Downstream Schema: Apply the same change to your target systems, like your data warehouse or microservice databases.
- Resume the Pipeline: Turn the consumers back on to start processing the stream again.
This methodical approach ensures you don't send data to a system that has no idea what to do with it, preventing a cascade of errors and keeping your data clean.
Ensure Data Consistency and Integrity
At the end of the day, it's all about consistent, trustworthy data. This whole process kicks off with a reliable initial data snapshot, sometimes called a backfill. When you first light up a pipeline, you need a perfect copy of all existing data before you start streaming the live changes. Getting this right is tricky because the source data is still changing while you're taking that snapshot. A common and effective technique is to use watermarking to seamlessly "join" the snapshot data with the live WAL stream, which helps avoid both missed records and duplicates.
These challenges get even bigger in more complex setups, like multi-tenant databases where many customers share the same infrastructure. Making sure each tenant's data stays isolated and is processed correctly requires a much more advanced architecture. You can dive deeper into this specific problem in our guide to implementing PostgreSQL CDC in multi-tenant systems.
By focusing on diligent monitoring, smart schema management, and rock-solid data consistency, you can build a CDC pipeline that becomes a reliable cornerstone of your real-time data strategy.
Your Top Postgres CDC Questions, Answered
Okay, we've covered the what and the why. Now, let's get into the nitty-gritty. When you're in the trenches implementing Postgres change data capture, a few practical questions always come up. Here are the answers to the ones we hear most often.
How Much Will This Slow Down My Database?
This is usually the first question on everyone's mind, and the answer is surprisingly reassuring: very little. Logical decoding barely touches the performance of your source PostgreSQL database, especially when you compare it to the old-school, trigger-heavy methods.
The main thing to watch isn't your transaction speed—it's your disk space. Postgres is already writing to the Write-Ahead Log (WAL) for its own recovery purposes; CDC just reads from that existing stream. The catch is that if your data consumer falls behind or disconnects, the replication slot will tell Postgres to hold onto old WAL files.
The bottom line? Your queries and transactions should run just as fast as they do today. The real job is to keep an eye on replication lag. If it gets too big, those WAL files can pile up and fill your disk, which can bring your database to a halt.
What’s the Best Way to Handle Schema Changes?
Handling schema changes—those DDL operations like ALTER TABLE—is one of the trickiest parts of CDC. How you manage it really boils down to the tools you're using.
Some of the more sophisticated platforms like Debezium are smart enough to spot DDL changes and automatically push them downstream, keeping your target schema in sync. It feels like magic when it works.
If your setup is simpler, you’ll likely need a more hands-on, manual process to prevent the whole pipeline from breaking. It usually looks something like this:
- Pause your CDC stream and any applications writing to the target.
- Run the schema change on your source Postgres database.
- Apply the same schema update to your target systems (like your data warehouse).
- Restart the stream.
Whatever you do, make sure you test how your specific tool handles schema evolution before you need it in production.
Can I Do Postgres CDC Without a Special Tool?
Absolutely. You can roll up your sleeves and build a custom solution using PostgreSQL's native logical decoding features. The process involves creating a replication slot and picking an output plugin, like wal2json, to get the change data into a usable format. From there, your own application would connect to the stream and process the events.
This gives you total control, but it also puts a lot of engineering weight on your team's shoulders. You'll be responsible for building and maintaining the logic for connection management, handling failovers, and guaranteeing exactly-once processing. These are genuinely hard problems that dedicated CDC tools are built to solve right out of the box.
Ready to build a rock-solid, real-time Postgres CDC pipeline without the operational headache? Streamkap offers a fully managed platform that takes care of everything from the initial data snapshot to handling schema changes, so you can focus on what to do with your data. Check it out at https://streamkap.com.