10 Essential Data Integration Techniques for Real-Time Analytics in 2026
Discover 10 essential data integration techniques, from CDC to streaming. Learn the pros, cons, and use cases to build efficient, real-time data pipelines.
In an era where real-time insights drive competitive advantage, relying on outdated batch processing is no longer a viable strategy. The speed at which an organization can move, process, and analyze information directly determines its ability to react to market changes, personalize customer experiences, and optimize critical operations. Slow data leads to missed opportunities and flawed decision-making. Therefore, mastering the right data integration techniques is mission-critical for building a responsive, data-driven enterprise.
This article provides a comprehensive roundup of 10 essential methods that form the backbone of modern data stacks. We will move beyond high-level theory to offer a practical guide for data engineers, architects, and IT leaders. You will gain a clear understanding of each technique’s core architecture, implementation considerations, and key trade-offs across latency, cost, and complexity.
We will explore a full spectrum of approaches, including:
- Traditional batch methods like ETL and its modern counterpart, ELT.
- Real-time streaming with technologies like Change Data Capture (CDC), Apache Kafka, and Apache Flink.
- Connectivity-focused patterns such as API-based integration and message queues.
For each technique, we’ll dissect its specific pros and cons, outline ideal use cases, and provide actionable guidance to help you select the right strategy for your unique business needs. We will also examine how modern streaming platforms like Streamkap are democratizing real-time data pipelines, simplifying the adoption of powerful but traditionally complex technologies. This guide is designed to equip you with the knowledge to build a robust and scalable data integration framework that fuels innovation and growth.
1. Change Data Capture (CDC)
Change Data Capture (CDC) is a powerful data integration technique that identifies and captures data changes (INSERTs, UPDATEs, and DELETEs) at the source in real-time. Instead of periodically extracting entire datasets, CDC monitors the source system’s transaction logs or other mechanisms to detect modifications as they happen. This approach allows organizations to stream only the incremental changes to target systems, drastically reducing latency and computational overhead compared to traditional batch processing.
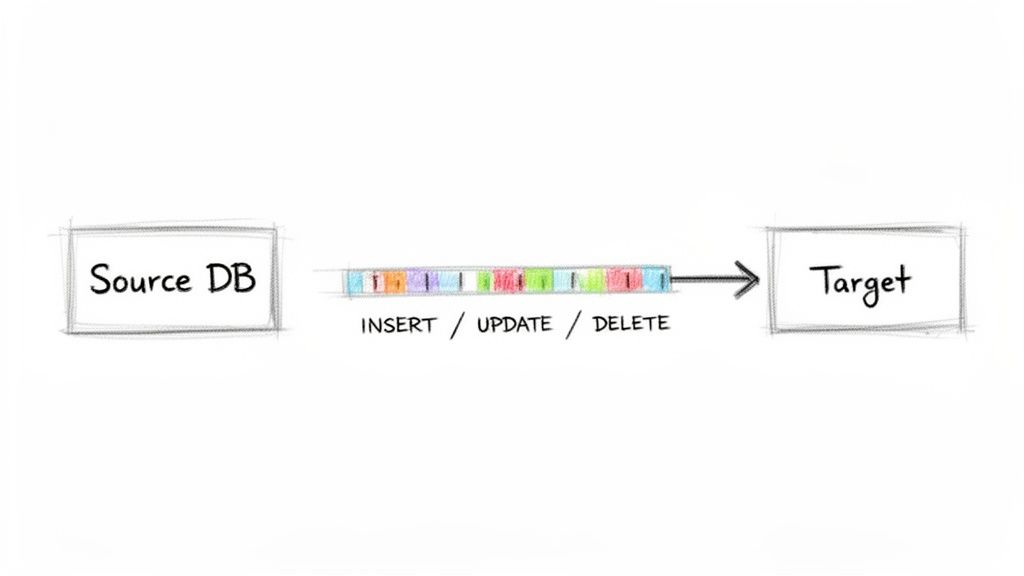
This method is the foundation for modern, real-time data pipelines, enabling use cases like immediate data warehousing, live analytics dashboards, and responsive, event-driven applications. By streaming only the delta, CDC minimizes the impact on source databases, making it a highly efficient and non-intrusive solution for continuous data synchronization.
Why It’s a Top Technique
CDC is a transformative approach to data integration because it delivers low-latency, resource-efficient, and reliable data movement. It eliminates the need for full table scans and complex batch windows, providing a continuous flow of fresh data. This capability is critical for businesses that rely on up-to-the-minute information for operational intelligence and decision-making.
Key Insight: CDC shifts the data integration paradigm from periodic, disruptive batch jobs to a continuous, low-impact stream. This is a fundamental change that unlocks real-time analytics and event-driven architectures.
Implementation Considerations
- Initial Load: Before enabling incremental CDC, perform a baseline snapshot or initial load of the source data to ensure the target system is fully synchronized.
- Monitoring: Implement comprehensive monitoring to track CDC lag (the time between a change occurring at the source and it being available at the target) and handle potential failures gracefully.
- Schema Evolution: Schema changes in the source system can break pipelines. Plan for schema management, or leverage platforms like Streamkap that offer automated schema handling to mitigate this complexity.
- Database-Specific CDC: The best implementation method often depends on the source database. Common approaches include reading transaction logs (e.g., PostgreSQL’s WAL, SQL Server’s transaction log), using database triggers, or leveraging built-in publisher/subscriber features.
CDC is exemplified by tools like Debezium, Oracle GoldenGate, AWS DMS, and Streamkap, which leverage it to power real-time data movement into destinations like Snowflake, BigQuery, and Kafka.
2. Apache Kafka Streaming
Apache Kafka is a distributed event streaming platform that acts as a central nervous system for real-time data integration. It allows numerous data producers (sources) to publish streams of records, which are then stored durably and consumed by multiple data consumers (targets). This publish-subscribe model decouples sources from destinations, enabling asynchronous, high-throughput, and fault-tolerant data pipelines that can scale massively.
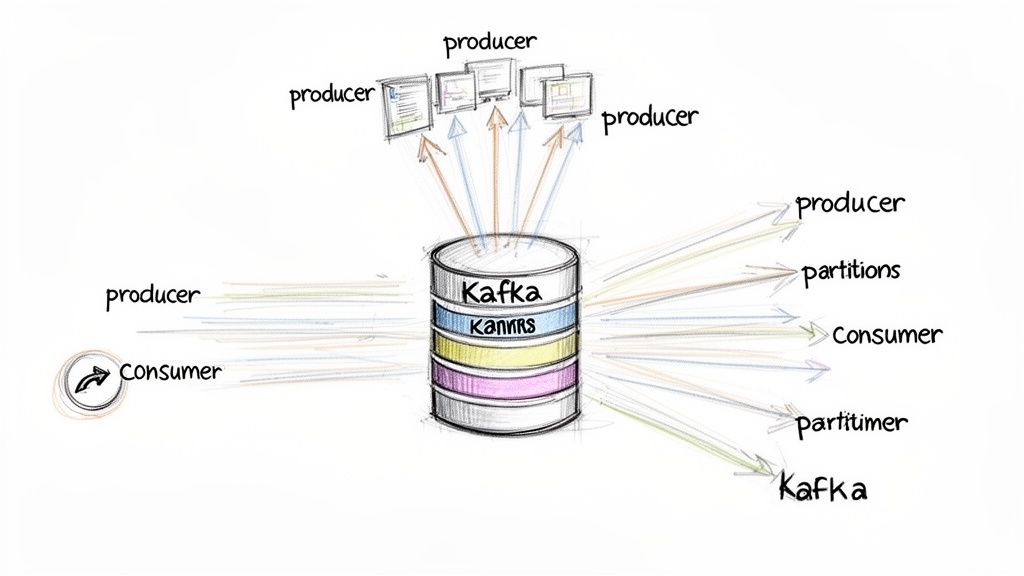
Kafka is the backbone of modern event-driven architectures, facilitating use cases from real-time analytics at Netflix to Uber’s monitoring systems. It organizes data into “topics,” which can be partitioned and replicated across multiple servers, ensuring both high availability and parallel processing. This design makes it one of the most powerful data integration techniques for building scalable, real-time systems.
Why It’s a Top Technique
Kafka excels at high-throughput, low-latency data ingestion and distribution at scale. Its ability to durably store event streams allows consumers to process data at their own pace and even re-process historical events. This durability and decoupling make it an incredibly versatile and resilient foundation for connecting disparate applications and services across an entire organization.
Key Insight: Kafka is more than just a message queue; it’s a distributed log that serves as a single source of truth for event data. This fundamentally changes how systems interact, moving from point-to-point connections to a centralized, scalable data hub.
Implementation Considerations
- Partitioning Strategy: Plan your topic partition strategy carefully. The number of partitions dictates the maximum parallelism for consumers and is crucial for meeting throughput requirements while maintaining message ordering where needed.
- Schema Management: Enforce data contracts using a schema registry with formats like Avro or Protobuf. This prevents data quality issues and ensures producers and consumers can evolve independently without breaking the pipeline.
- Operational Overhead: Self-managing a Kafka cluster is complex, requiring expertise in monitoring, tuning, and failure recovery. Consider managed solutions like Confluent Cloud or platforms like Streamkap that handle the underlying Kafka infrastructure for you.
- Retention Policies: Configure topic retention policies to balance data availability with storage costs. Decide how long data should be kept based on your use cases for real-time consumption versus historical reprocessing.
Kafka’s widespread adoption by companies like LinkedIn (its creators) and its robust open-source community make it a cornerstone of modern data architecture.
3. ETL (Extract, Transform, Load)
ETL (Extract, Transform, Load) is a foundational data integration technique where data is extracted from one or more sources, transformed into a structured and compliant format, and loaded into a target destination, typically a data warehouse. This process has historically been the backbone of business intelligence and analytics, operating in scheduled batches to consolidate disparate data for reporting and analysis. The transformation stage is the core of ETL, where data is cleansed, aggregated, and business rules are applied.
While traditionally associated with overnight batch jobs, modern ETL tools have evolved to handle more frequent micro-batches and even near-real-time data flows. This method remains critical for scenarios requiring complex data enrichment, validation, and restructuring before the data is made available to end-users, ensuring high data quality and consistency in the target system.
Why It’s a Top Technique
ETL is a mature and robust methodology that provides a structured, reliable, and high-quality approach to data consolidation. Its strength lies in the “transform” step, which centralizes data cleansing and business logic, ensuring that the data loaded into the warehouse is analysis-ready. This approach simplifies analytics by offloading complex transformations from the query layer, resulting in faster and more efficient reporting.
Key Insight: ETL prioritizes data quality and consistency by performing transformations before loading. This pre-processing makes it ideal for building curated, high-performance enterprise data warehouses where data integrity is paramount.
Implementation Considerations
- Staging Area: Utilize a staging area between the source and target to perform transformations. This isolates the resource-intensive transformation logic from both the source operational systems and the final data warehouse.
- Data Quality: Implement rigorous data quality and validation checks within the transformation layer to catch errors, standardize formats, and enrich data before it reaches the destination.
- Batch vs. Streaming: Evaluate your latency requirements. While traditional ETL is batch-oriented, consider a hybrid approach. Use batch ETL for historical reporting and supplement it with streaming platforms like Streamkap for real-time dashboards and operational analytics.
- Performance Monitoring: Continuously monitor job execution times and resource consumption. Optimize slow-running transformations by refining logic, partitioning data, or scaling processing resources.
ETL is best represented by established tools like Informatica PowerCenter, Talend, and Microsoft SQL Server Integration Services (SSIS), which are designed to handle complex, large-scale data warehousing workloads.
4. ELT (Extract, Load, Transform)
ELT (Extract, Load, Transform) is a modern data integration technique that flips the traditional ETL sequence. Instead of transforming data before loading it, ELT first extracts raw data from various sources and loads it directly into a powerful target system, like a cloud data warehouse or data lake. The transformation logic is then applied after the data has landed, leveraging the massive parallel processing (MPP) capabilities of the destination platform.
This approach dramatically accelerates the data loading process, making raw data available for exploration almost immediately. It decouples the extraction and loading steps from the complex and often resource-intensive transformation step, providing greater flexibility and scalability. By using the computational power of the target warehouse, ELT is highly efficient for handling large and diverse datasets.
Why It’s a Top Technique
ELT is a cornerstone of the modern data stack because it delivers speed, flexibility, and scalability. By offloading transformations to powerful cloud data warehouses, it minimizes the need for a separate, often costly, transformation server. This architecture also supports a “schema-on-read” approach, where raw data is preserved, allowing for different transformations to be applied over time as business requirements evolve without needing to re-extract the data.
Key Insight: ELT leverages the immense power of cloud data platforms to transform data in place. This paradigm shift democratizes data by making raw, untransformed data quickly available for various analytics and data science use cases.
Implementation Considerations
- Modular Transformations: Use tools like dbt to build modular, version-controlled, and testable transformation layers (e.g., staging, intermediate, and analytics-ready marts) directly within the warehouse.
- Cost Management: Transformations consume warehouse compute credits. Monitor query performance and costs closely, optimizing complex SQL jobs to ensure efficiency.
- Data Quality: Implement data quality and validation checks as one of the first steps in your transformation pipeline after the data is loaded to ensure the integrity of your raw data layer.
- Real-Time ELT: Combine ELT with real-time ingestion methods for a powerful, low-latency pipeline. For example, using a platform like Streamkap to stream CDC data into Snowflake and then running dbt transformations on that near real-time data.
ELT workflows are commonly seen with tools like dbt running transformations on data within cloud warehouses like Snowflake, BigQuery, and Databricks. This approach has become the de facto standard for modern analytics engineering.
5. API-Based Integration
API-Based Integration is a data integration technique that leverages Application Programming Interfaces (APIs) to enable communication and data exchange between disparate software applications. Instead of accessing a database directly, this method uses well-defined endpoints (like REST or GraphQL) to request or push data in a structured, controlled manner. This approach is the backbone of modern cloud-based and SaaS application ecosystems, allowing systems to interact seamlessly.
This technique is fundamental for connecting microservices, synchronizing data with SaaS platforms like Salesforce or Shopify, and building composite applications. Whether fetching customer data via a REST call or receiving real-time order updates through a webhook, API integration provides a standardized protocol for application interoperability, abstracting away the underlying complexity of each system.
Why It’s a Top Technique
API-based integration offers flexibility, standardization, and real-time connectivity for modern application landscapes. It decouples systems, allowing them to evolve independently while maintaining stable communication channels. This is essential for integrating with third-party services where direct database access is not feasible or secure, making it a cornerstone of modern, distributed architectures.
Key Insight: API integration shifts the focus from low-level data access to high-level application interaction. It treats applications as services that can be composed and connected, enabling greater agility and scalability in a cloud-native world.
Implementation Considerations
- Rate Limiting and Throttling: Be mindful of API rate limits imposed by service providers. Implement queuing and exponential backoff strategies to manage request volumes and avoid being blocked.
- Data Format and Transformation: APIs deliver data in specific formats like JSON or XML. Your integration logic must be prepared to parse these formats and transform the data to fit the target system’s schema.
- Polling vs. Webhooks: For real-time updates and event-driven architectures, many systems leverage Webhook integrations to push data as events occur. This is far more efficient than constantly polling an API endpoint for changes.
- Security and Authentication: Secure API integrations using standard protocols like OAuth 2.0 or API keys. Ensure that sensitive credentials are never exposed and are managed securely.
This approach is widely used by platforms like Zapier and Make to orchestrate workflows between thousands of cloud applications, and by services like Twilio and PagerDuty to send and receive event-driven notifications.
6. Message Queue-Based Integration
Message Queue-Based Integration is a data integration technique that leverages an intermediary message broker to decouple source and target systems. Instead of communicating directly, applications publish messages (data packets) to a queue, and consumer applications subscribe to that queue to retrieve the messages asynchronously. This creates a highly resilient and scalable architecture where systems can operate independently without being tightly linked.
This asynchronous model ensures that if a consumer application is temporarily offline, messages remain safely in the queue until the consumer is available again. This method is fundamental to building robust, event-driven architectures and distributed systems, allowing different components to communicate reliably without direct dependencies. Technologies like RabbitMQ, AWS SQS, and Azure Service Bus are central to this approach.
Why It’s a Top Technique
This technique excels at creating decoupled, scalable, and resilient systems. By acting as a buffer, the message queue absorbs spikes in traffic and ensures data is not lost during system outages or maintenance. This loose coupling allows teams to develop, deploy, and scale individual services independently, greatly improving agility and fault tolerance in complex microservices environments.
Key Insight: Message queues shift the integration model from direct, synchronous calls to indirect, asynchronous messaging. This decoupling is the key to building resilient, scalable, and maintainable distributed systems.
Implementation Considerations
- Idempotent Consumers: Design consumers to be idempotent, meaning they can safely process the same message multiple times without unintended side effects. This is crucial for handling “at-least-once” delivery guarantees common in message systems.
- Dead-Letter Queues (DLQs): Implement a DLQ to automatically route messages that cannot be processed successfully after several retries. This prevents poison pills from blocking the queue and allows for later analysis and manual intervention.
- Message Schema Design: Define clear and versioned message schemas (e.g., using Avro or Protobuf). A well-designed schema ensures long-term compatibility as producer and consumer applications evolve independently.
- Monitoring Queue Health: Actively monitor key metrics like queue depth (number of messages waiting), message age, and consumer processing lag. These metrics are vital for identifying bottlenecks and ensuring the health of the integration pipeline.
Popular tools that exemplify this data integration technique include RabbitMQ, Apache Kafka (which can act as a message queue), AWS SQS, and Azure Service Bus, all of which are staples in modern microservices and event-driven architectures.
7. Data Virtualization
Data virtualization is an agile data integration technique that creates a unified, logical data layer over multiple, disparate data sources without physically moving the data. Instead of consolidating data into a central repository, it connects to source systems and presents a single, virtual view. When a user or application queries this virtual layer, the virtualization engine translates the query into the native languages of the underlying sources, retrieves the necessary data in real-time, and integrates the results on the fly.
This approach is invaluable for organizations needing quick access to data scattered across a federated landscape. It provides immediate access for reporting, business intelligence, and ad-hoc analysis without the cost, complexity, and latency associated with building and maintaining a physical data warehouse. It serves as an abstraction layer that decouples data consumers from the complexities of the underlying data sources.
Why It’s a Top Technique
Data virtualization delivers unmatched agility and real-time access to distributed data. It sidesteps the lengthy and resource-intensive processes of ETL and physical data movement, allowing businesses to stand up new data services and reports in hours or days instead of months. This makes it a powerful tool for rapid prototyping, data exploration, and serving operational reports that require the most current information available.
Key Insight: Data virtualization provides access without movement. By creating a semantic abstraction layer, it offers a flexible and cost-effective way to integrate data on-demand, making it ideal for scenarios where timeliness is more critical than historical consolidation.
Implementation Considerations
- Performance Optimization: Since queries run against live sources, performance can be a bottleneck. Implement intelligent caching strategies for frequently accessed data and optimize complex queries to reduce the load on source systems.
- Source System Impact: Be mindful of the query load placed on operational source systems. Data virtualization is best suited for low-to-medium query volumes, like those from BI dashboards, not for heavy-duty analytical processing or large-scale data science workloads.
- Governance and Security: A robust data virtualization platform must enforce security and governance policies centrally. Ensure it can manage access controls, data masking, and lineage tracking across all connected sources from the virtual layer.
- Hybrid Architectures: Combine data virtualization with other data integration techniques. For example, use it for real-time operational reporting while leveraging a physically consolidated warehouse (populated via ETL or CDC) for historical analytics.
Prominent tools in this space include Denodo, Teiid, and offerings from Informatica and Cisco. They provide the query federation and optimization engines necessary to make this technique effective at an enterprise scale.
8. Batch Processing with Apache Spark
Batch processing with Apache Spark is a dominant data integration technique for handling massive datasets. Spark is a powerful, open-source distributed computing system that processes large volumes of data in parallel across a cluster of machines. Unlike traditional MapReduce, Spark performs in-memory computations, which dramatically accelerates complex transformations, aggregations, and machine learning jobs. This makes it ideal for large-scale ETL pipelines where data is processed in scheduled, discrete chunks.
The framework is designed for fault tolerance and scalability, allowing organizations to process petabytes of data reliably. While its core strength lies in batch jobs, its Spark Streaming and Structured Streaming modules also provide micro-batch capabilities for near-real-time processing, bridging the gap between traditional batch and true real-time streaming. This versatility makes it a cornerstone of modern big data architectures.
Why It’s a Top Technique
Apache Spark offers unmatched performance, scalability, and flexibility for large-scale data processing. Its in-memory processing engine is significantly faster than Hadoop MapReduce for complex, multi-stage data pipelines. Furthermore, its unified API for batch, streaming, SQL, and machine learning simplifies the development of sophisticated data integration workflows, making it a go-to choice for organizations like Netflix and Uber that process enormous volumes of data daily.
Key Insight: Spark democratized big data processing by combining high performance with a more accessible developer experience, making it the industry standard for large-scale batch data integration and transformation.
Implementation Considerations
- Partitioning Strategy: Strategically partition your data to enable maximum parallelism and minimize data shuffling across the network, which is a common performance bottleneck.
- Resource Management: Use a cluster manager like YARN or Kubernetes and carefully tune memory and CPU core allocation for Spark executors to optimize resource utilization and job performance.
- Data Ingestion: While Spark can read from batch sources, integrating it with real-time data requires a robust ingestion layer. Platforms like Streamkap can stream real-time CDC events into a message queue like Kafka, which Spark can then consume for micro-batch or continuous processing.
- Monitoring and Tuning: Actively monitor Spark jobs using its UI to identify and tune performance issues related to data skew, shuffle operations, and inefficient transformations. Caching frequently accessed DataFrames can also provide a significant speed boost.
Apache Spark’s ecosystem, popularized by Databricks and major cloud providers like AWS (EMR) and Google Cloud (Dataproc), has solidified its position as a critical tool for any organization serious about big data integration.
9. Real-Time Data Streaming with Apache Flink
Apache Flink is a powerful, open-source distributed processing framework designed for stateful computations over unbounded and bounded data streams. It processes data with extremely low latency and high throughput, making it a cornerstone among modern data integration techniques. Flink’s sophisticated engine provides fine-grained control over state, time, and windowing, enabling true real-time processing for the most demanding applications.
This framework is not just for moving data; it’s for processing it in-flight. Flink allows organizations to perform complex transformations, aggregations, and event processing as data flows through the system. This capability supports use cases like real-time fraud detection, live recommendation engines, and dynamic pricing models, where immediate computation on streaming data is critical.
Why It’s a Top Technique
Flink excels at complex, stateful stream processing with exactly-once semantics. While other tools move data, Flink processes it with sophisticated logic in true real-time. Its advanced features like event-time processing and flexible windowing (tumbling, sliding, session) allow developers to handle out-of-order events and complex temporal queries accurately, a challenge for many other systems.
Key Insight: Flink bridges the gap between data integration and real-time application logic, enabling organizations to build sophisticated, event-driven services directly on top of their data streams, rather than waiting for data to land in a warehouse.
Implementation Considerations
- Managed Services: The operational complexity of managing a Flink cluster can be significant. Platforms like Streamkap offer managed Flink, abstracting away the infrastructure management and allowing teams to focus on building business logic.
- State Management: Carefully plan your state backend (e.g., RocksDB) and checkpointing strategy. This configuration is crucial for ensuring fault tolerance, performance, and the ability to recover from failures without data loss.
- Windowing Strategy: Choose the appropriate windowing mechanism based on your use case. Tumbling windows are great for fixed-time reports, while sliding windows are ideal for moving averages, and session windows excel at grouping user activity.
- Stateless vs. Stateful: Design operations to be stateless whenever possible, as they are simpler to scale and manage. For stateful operations, ensure your state management and checkpointing are robustly configured and tested.
Flink is battle-tested at massive scale by companies like Alibaba, which processes trillions of events daily, and DoorDash, which uses it for real-time delivery optimization.
10. Hybrid and Multi-Pattern Integration
Hybrid and Multi-Pattern Integration is a sophisticated data integration technique that strategically combines multiple methods-such as CDC, API-based integration, and message queues-into a single, cohesive architecture. This approach acknowledges that no single pattern is optimal for every use case. Instead, it leverages the unique strengths of each technique to build a flexible and powerful data ecosystem tailored to diverse business needs.
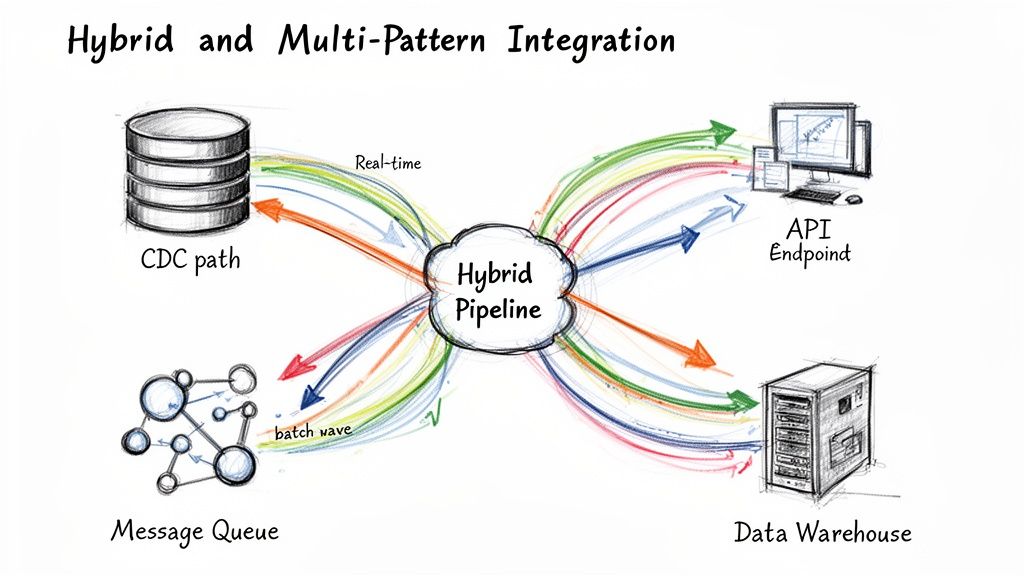
This methodology allows organizations to orchestrate complex data flows seamlessly. For example, a company might use real-time CDC for operational databases, pull data from SaaS applications via APIs, and process event streams from IoT devices through a message queue, all feeding into a central cloud data platform. This holistic strategy ensures that data is moved in the most efficient and effective way possible for each specific source and destination.
Why It’s a Top Technique
Hybrid integration is the pragmatic reality of modern enterprise data architecture. It provides the versatility and scalability needed to manage a complex landscape of on-premises systems, cloud services, and third-party applications. By not forcing a one-size-fits-all solution, it enables organizations to build robust, future-proof data pipelines that can adapt to new technologies and evolving business requirements without requiring a complete architectural overhaul.
Key Insight: Hybrid integration moves beyond a single-minded approach, embracing a “right tool for the right job” philosophy. This flexibility is essential for creating comprehensive and resilient data ecosystems in complex enterprises.
Implementation Considerations
- Unified Platform: Managing multiple integration patterns can introduce significant operational complexity. Use a unified platform like Streamkap to abstract this complexity, providing a single interface for monitoring, managing, and scaling diverse data pipelines.
- Establish Standards: Create clear internal standards and data contracts for how different patterns are used. Document data flows and establish consistent schema management practices to prevent chaos and ensure data quality across all integrations.
- Holistic Monitoring: Implement comprehensive monitoring that provides a single pane of glass across all integration patterns. This is crucial for tracking end-to-end data latency, identifying bottlenecks, and ensuring reliability.
- Start Small: Begin by implementing a hybrid approach for a few core use cases. For instance, combine CDC for a critical database with API integration for a key SaaS tool. Gradually expand the patterns as your team gains experience and as new business needs arise.
This approach is exemplified by enterprises using platforms like Streamkap to orchestrate real-time CDC alongside API-based data ingestion, creating a unified flow of data into destinations like Snowflake or Databricks.
10-Point Comparison of Data Integration Techniques
| Pattern / Technology | Implementation Complexity | Resource Requirements | Expected Outcomes | Ideal Use Cases | Key Advantages |
|---|---|---|---|---|---|
| Change Data Capture (CDC) | Moderate — DB-specific setup, schema evolution handling | Low ongoing; initial snapshot can be resource-intensive; requires log access | Near‑real‑time incremental sync with preserved transactions | DB-to-warehouse sync, real-time replication, event sourcing | Low source load, transactional consistency, low latency |
| Apache Kafka Streaming | High — cluster ops, topic/partition design, tuning | High (broker clusters, storage for retention, ops expertise) | Scalable high‑throughput event streaming with replayability | Enterprise event bus, decoupled producers/consumers, stream backbone | Durability, replay, high throughput, strong ecosystem |
| ETL (Extract, Transform, Load) | Moderate–High — complex transformations and scheduling | High compute/storage for batch jobs and ETL tools | Curated, validated datasets loaded on schedules | Traditional data warehousing, regulated reporting, complex transforms | Mature tooling, governance, rich transformation capabilities |
| ELT (Extract, Load, Transform) | Moderate — simpler extract/load; SQL-centric transforms | Warehouse compute and storage; tools like dbt | Faster raw data availability; scalable in‑warehouse transforms | Cloud data warehouses, analytics engineering, iterative models | Leverages warehouse scale, faster loads, flexible schema |
| API‑Based Integration | Low–Moderate — depends on API complexity and auth | Low infrastructure; needs rate‑limit handling and adapters | Real‑time app‑level synchronization and webhook events | SaaS integrations, microservices, webhook-driven workflows | Native app connectivity, low source impact, flexible |
| Message Queue‑Based Integration | Moderate — broker design, idempotency, ordering | Moderate (message brokers, persistence) | Reliable asynchronous delivery, decoupled processing | Transactional workflows, microservices communication, retries | Reliable delivery, decoupling, load leveling |
| Data Virtualization | High — federation, semantic mapping, query optimization | Low physical storage; higher network/query compute; caching | Unified logical view with real‑time access (no copy) | Real‑time dashboards across federated sources, prototyping | No data movement, single view, strong governance |
| Batch Processing with Apache Spark | High — cluster management, performance tuning | High compute/memory; cluster orchestration | Fast large‑scale batch and micro‑batch processing for complex transforms | Big data analytics, ML pipelines, heavy aggregations | In‑memory speed, rich APIs, scalable processing |
| Real‑Time Streaming with Apache Flink | High — state management, event‑time design, ops | High (state backend, checkpointing, infra expertise) | True low‑latency, stateful, exactly‑once stream processing | CEP, fraud detection, time‑window analytics, real‑time scoring | Event‑time semantics, large state support, exactly‑once guarantees |
| Hybrid & Multi‑Pattern Integration | Very high — orchestrating multiple patterns and policies | Variable/high — combines resource needs of chosen patterns | Flexible, optimized pipelines covering batch and real‑time needs | Enterprises with diverse sources/SLAs, phased migrations, complex ecosystems | Best‑of‑breed per use case, flexibility, unified governance when managed |
From Techniques to Transformation: Building Your Modern Data Strategy
Navigating the expansive landscape of data integration techniques can feel like choosing a path through a dense, ever-changing forest. From the steadfast reliability of traditional batch ETL to the blistering speed of real-time CDC and Flink streaming, the options are vast and the stakes are high. As we have explored, the journey from raw, siloed data to actionable, transformative insight is paved with critical architectural decisions. There is no single “best” method; instead, the optimal approach is a carefully orchestrated blend of patterns tailored to your specific business needs, latency requirements, and technical capabilities.
The core takeaway is that modern data integration is no longer a monolithic, one-size-fits-all discipline. The rigid dichotomy between batch and real-time is dissolving, giving way to a more fluid, hybrid reality. A successful strategy might involve using ELT for large-scale data warehousing transformations, API-based integration for connecting SaaS applications, and a real-time CDC pipeline powered by Kafka for feeding operational analytics dashboards. The key is to understand the distinct trade-offs of each technique in terms of cost, complexity, and performance, enabling you to build a cohesive and resilient data ecosystem.
The Strategic Shift: From Infrastructure to Value
A critical theme throughout our discussion has been the evolution from managing complex infrastructure to delivering business value. While understanding the mechanics of Apache Kafka, Flink, and Spark is invaluable, the operational overhead associated with deploying, scaling, and maintaining these powerful open-source systems can be immense. It often requires dedicated teams of specialized engineers, diverting precious resources from the ultimate goal: building data products that drive revenue, improve customer experiences, and unlock competitive advantages.
This is where the modern data stack offers a paradigm shift. Managed platforms are designed to abstract away this underlying complexity. They provide the power and scalability of enterprise-grade streaming systems without the corresponding management burden. This democratization of advanced data integration techniques allows organizations of all sizes to leverage patterns that were once the exclusive domain of tech giants.
Actionable Next Steps for Your Integration Journey
Mastering these concepts is the first step. The next is to translate this knowledge into a tangible strategy. Here’s a practical roadmap to guide your organization forward:
- Audit Your Current State: Begin by mapping your existing data sources, targets, and integration workflows. Identify pain points, latency bottlenecks, and areas where data quality is compromised. Understanding where you are is essential to planning where you need to go.
- Define Your Use Cases: Categorize your integration needs. Are you building an analytical data warehouse (favoring ELT)? A real-time fraud detection system (requiring CDC and streaming)? Or a customer 360 platform (a hybrid approach)? Aligning techniques to specific business outcomes is crucial.
- Evaluate a Proof of Concept (POC): Don’t commit to a full-scale migration without validation. Select a high-impact, low-risk use case and implement a POC using a modern, managed streaming platform. This allows you to test the technology, measure performance, and demonstrate value to stakeholders quickly.
- Embrace a Hybrid Future: Recognize that your architecture will likely be a composite of several patterns. Plan for a flexible, multi-pattern strategy that allows you to apply the right tool for the right job, ensuring your data infrastructure can evolve alongside your business.
The power of modern data integration techniques lies not just in their ability to move data, but in their capacity to transform an organization. By building a resilient, scalable, and real-time data foundation, you are not just connecting systems; you are enabling a culture of data-driven decision-making, accelerating innovation, and future-proofing your business in an increasingly dynamic digital world.
Ready to unlock the power of real-time data integration without the operational headache? Streamkap provides a fully managed, serverless platform built on Kafka and Flink, enabling you to build elite streaming pipelines in minutes. Explore how you can leverage cutting-edge data integration techniques like CDC with zero infrastructure management by visiting Streamkap today.
Related resources
ETL Workflow Automation: From Manual Scripts to Real-Time Pipelines
How to automate ETL workflows — orchestration tools, CDC-based streaming, error handling patterns, and the shift from batch scripts to continuous pipelines.
Data Integration Challenges: Master Solutions for Unified Data
Explore data integration challenges and how to overcome silos, latency, and quality issues with proven, actionable strategies for seamless data flow.
Discover: snowflake marketplace and streamkap is now available on it
Discover how snowflake marketplace and streamkap is now available on it unlocks real-time data streaming for analytics with easy setup tips.