<--- Back to all resources
Data Integration Challenges: Master Solutions for Unified Data
Explore data integration challenges and how to overcome silos, latency, and quality issues with proven, actionable strategies for smooth data flow.
Data integration challenges are the technical hurdles and organizational friction that stop businesses from connecting the dots between their different systems. When you’re dealing with issues like data silos, messy data quality, and frustratingly high latency, you’re not just facing IT problems—you’re dealing with operational chaos that stalls critical projects, from real-time analytics to AI.
Why Is Modern Data Integration So Hard?
Think about a global logistics company for a minute. The sales team uses a CRM to log new orders. Miles away, the warehouse team tracks stock levels in their own inventory management system. Meanwhile, the shipping department is in a totally different platform to manage dispatch and tracking.
Without a unified view, trying to coordinate a single shipment becomes a messy, manual process of phone calls, emails, and shared spreadsheets. This is the reality for countless businesses. Disconnected data creates a constant state of operational friction, leading to expensive delays, wildly inaccurate reports, and unhappy customers. The root of the problem? Valuable information is trapped, making it impossible to see what’s actually happening across the business in real time.
The Problem Starts with Data Silos
This fragmentation, what we call data silos, is one of the biggest roadblocks to progress. When information is locked away in separate apps—like your marketing automation platform and your sales CRM—you can never get a complete picture of the customer journey. Understanding what CRM integration actually entails is a good starting point, as it’s often ground zero for these data battles.
But these silos aren’t just an inconvenience; they actively sabotage a company’s biggest goals. In one survey of over 1,000 IT leaders, a staggering 81% said that data silos were getting in the way of their digital transformation efforts. It’s even worse for AI initiatives, where 80% of organizations point to silos as the primary reason their AI and automation projects are stuck in neutral.
The table below summarizes the most common data integration challenges and the real-world impact they have on both day-to-day operations and long-term strategy.
Top Data Integration Challenges and Their Business Impact
| Challenge | Operational Impact | Strategic Impact |
|---|---|---|
| Data Silos | Manual data reconciliation, duplicated effort, inefficient workflows. | Incomplete customer view, inability to personalize experiences, poor cross-functional collaboration. |
| High Latency | Delayed reporting, missed opportunities for real-time intervention (e.g., fraud detection). | Decisions based on outdated information, loss of competitive edge, slow reaction to market shifts. |
| Poor Data Quality | Inaccurate reports, failed transactions, poor customer service experiences. | Flawed business intelligence, erosion of trust in data, misguided strategic planning. |
| Scalability | System crashes during peak loads, slow performance, expensive emergency fixes. | Stifled growth, inability to expand into new markets or handle more customers. |
| Security Risks | Inconsistent access controls, increased vulnerability to breaches, compliance failures. | Reputational damage, hefty regulatory fines, loss of customer trust. |
These challenges show that weak data integration isn’t just about messy data; it’s about a fundamental breakdown in how a business operates and competes.
Beyond Silos to System-Wide Failures
Failing to address these issues leads to serious consequences. Beyond silos, businesses are wrestling with a whole host of related problems that can halt growth in its tracks:
- Poor Data Quality: When data is inconsistent, wrong, or incomplete, your analysis is flawed and your decisions are weak. Getting this right is non-negotiable for reliable business intelligence. We dive deeper into this in our guide to fixing common data integrity problems.
- High Latency: If moving data from A to B takes hours or days, your insights are already stale by the time you get them. Real-time reactions become impossible.
- Scalability Issues: A system that works for 1,000 customers will break when you hit 100,000. Pipelines that can’t handle growing data volumes are a ticking time bomb.
Let’s be clear: poor data integration isn’t just a technical headache. It’s a direct business risk that erodes efficiency, blocks innovation, and leaves you vulnerable to competitors.
Fixing these problems is no longer optional. To thrive, modern organizations must build a fluid, unified data ecosystem. This guide will walk you through the most critical data integration challenges one by one and give you practical strategies to solve them for good.
The 7 Critical Data Integration Roadblocks
Getting data integration right can feel like trying to drive a high-performance race car on a road riddled with potholes and unexpected detours. Just when you think you’re hitting your stride, a new obstacle appears, threatening to bring everything to a grinding halt. These aren’t minor speed bumps; they’re major data integration challenges that can derail projects, corrupt insights, and burn through your budget.
To build a data infrastructure that actually accelerates your business, you first have to understand what can slow it down. Let’s break down the seven biggest roadblocks you’re likely to face.
1. Data Latency: The Real-Time Gap
In simple terms, data latency is the delay between an event happening and the data about that event being ready to use. Think of it like watching a live sports game on a stream that’s 30 seconds behind. By the time you see the big play, the real-world outcome is already decided, and your reaction is completely out of sync.
In business, this gap means your decisions are always based on a look in the rearview mirror. An e-commerce team looking at yesterday’s sales data can’t possibly react to a product going viral right now. That lag translates directly into missed revenue, poor customer experiences, and a constant feeling of playing catch-up. For critical operations like fraud detection, a few seconds of delay can literally cost millions.
2. Schema Drift: The Shifting Blueprint
Schema drift happens when the structure of your source data changes, often without any warning. Imagine you’ve built a machine at a warehouse to automatically sort packages based on a specific label format. One day, a supplier changes their label design—adding a new barcode and moving the postal code—without telling you. Your perfectly designed machine instantly breaks down, causing chaos on the loading dock.
This is exactly what happens to data pipelines. A developer pushes an application update that adds a new field to a database table or changes a data type. If your integration pipeline isn’t built to expect the unexpected, it fails. The result? Broken dashboards, failed analytics jobs, and engineers dropping everything to put out fires instead of building value.
Schema drift is a silent killer of data pipelines. Without automated handling, it creates constant maintenance headaches and erodes trust in your data, as teams never know if their reports are complete or based on a broken feed.
3. Data Quality: The “Garbage In” Problem
Poor data quality is the classic “garbage in, garbage out” dilemma. If the data feeding your pipelines is wrong, incomplete, or inconsistent, any insight you pull from it will be just as flawed. It’s like a chef trying to make a gourmet meal with spoiled ingredients—no matter how skilled they are, the final dish is going to be a disaster.
This problem shows up in a few common ways:
- Missing Values: Customer records without email addresses mean your marketing campaigns can’t reach them.
- Inaccurate Entries: Incorrect pricing data causes billing errors that infuriate customers.
- Inconsistent Formats: Dates written as “MM/DD/YYYY” in one system and “DD-Mon-YY” in another make it impossible to perform accurate time-based analysis.
The operational damage is immense. Flawed financial reports, wasted marketing spend, and a total loss of trust in the data are just the beginning. Your teams end up spending more time cleaning data than actually using it.
4. Complex Transformations: The Translation Burden
Data rarely shows up in the perfect shape for its destination. It almost always needs to be transformed—cleaned, restructured, enriched, or aggregated—before it’s truly useful. Think of this process like translating a technical manual into another language; you’re not just swapping words, you’re adapting complex concepts to make them understandable for a new audience. It’s a delicate and resource-intensive job.
Every transformation you add to a pipeline is another potential point of failure and another layer of complexity. As business logic changes, those transformations have to be updated, creating a huge maintenance burden. For many companies, the engineering effort needed to build and manage these transformation jobs becomes a massive bottleneck, slowing down every new data initiative.
5. Scalability: The Growth Bottleneck
A data pipeline that works beautifully with a thousand records a day can completely fall apart when hit with a million. Scalability is all about making sure your system can handle growth in data volume and velocity without performance grinding to a halt. A pipeline that can’t scale is like a quiet country lane that suddenly becomes the main highway at rush hour—instant gridlock.
When your business grows, your data grows with it. A successful marketing campaign can trigger a huge spike in website traffic and sign-ups. If your data pipelines can’t handle that surge, systems crash, data gets lost, and the business is effectively flying blind during its most critical moments.
6. Security Vulnerabilities: The Weakest Link
Data is one of your company’s most valuable assets, and moving it between systems opens it up to risk. Every stage of the integration process—extraction, transit, and loading—is a potential security vulnerability. It’s like moving cash in an armored truck; a single weak point along the route can lead to a heist.
Inconsistent security rules across different systems can leave sensitive data exposed. Forgetting to encrypt data in transit or failing to manage access controls properly can lead straight to a data breach. The impact goes far beyond the immediate fallout; it includes massive compliance fines (from regulations like GDPR and CCPA), lasting reputational damage, and a permanent loss of customer trust.
7. Data Governance: The Rules of the Road
Finally, data governance is what establishes the rules of the road for your data—who can access it, how it should be used, and how its quality is measured and maintained. Without a strong governance framework, data integration becomes a free-for-all, quickly turning your pristine data lake into a “data swamp” where nobody knows what to trust.
Poor governance creates a host of operational nightmares:
- Lack of Ownership: When no one is clearly responsible for a dataset, its quality and reliability inevitably decay.
- Compliance Risks: Without clear data lineage and audit trails, proving compliance with industry regulations becomes impossible.
- Inconsistent Metrics: Different teams start defining the same metric (like “active user”) in different ways, leading to conflicting reports and company-wide confusion.
These seven challenges can feel like an insurmountable barrier to becoming a truly data-driven organization. The good news is that modern solutions, particularly real-time platforms like Streamkap, were designed specifically to tackle these problems head-on.
The Hidden Costs of Poor Data Integration
When we talk about data integration problems like latency, schema drift, or bad data, it’s easy to see them as just technical hurdles for the engineering team. But they’re not. These issues quietly bleed money from the business, creating financial drains that grow larger the longer they’re ignored. Failed projects have obvious price tags, but the real damage is what’s happening just below the surface—much like an iceberg.
These hidden costs show up as wasted hours, bad decisions, and opportunities that simply vanish. When your data pipelines are brittle and unreliable, the pain spreads. It hits everything from marketing campaign ROI to the customer support experience.
The Staggering Price of Manual Labor
One of the most immediate and painful costs of messy integration is the sheer amount of time your sharpest people waste on “data wrangling.” Instead of digging for insights or building new models, your most skilled—and expensive—engineers are stuck doing grunt work. They’re manually cleaning files, trying to match up data from different systems, and constantly patching broken pipelines.
This isn’t just inefficient; it’s a colossal waste of talent and money. Study after study shows that data professionals can spend up to 80% of their time just getting data ready for analysis. That leaves a tiny sliver of their week for the strategic work that actually moves the needle. This kind of shadow work tanks productivity, burns out your best people, and creates huge delays in getting answers to critical business questions.
When Bad Data Corrupts Business Decisions
The financial hit from poor data integration and quality issues is staggering. Research shows that bad data costs companies an average of $12.9 million every year, and some estimates are even higher. Across the entire U.S. economy, the cost runs into the trillions. You can dig deeper into these integration challenges and the financial fallout in recent industry analyses on legacy technologies.
This isn’t just some abstract number; it leads to very real, very expensive mistakes. When you make decisions based on incomplete or just plain wrong information, the outcomes are predictably bad.
- Failed Marketing Campaigns: You end up targeting the wrong people because your customer data is a mess.
- Inefficient Supply Chains: You order too much or too little inventory because you’re looking at stale sales numbers.
- Poor Strategic Planning: You bet the company’s future on a strategy built on analytics from a corrupted dataset.
Every one of these missteps chips away at your profits and your edge in the market. The longer you let flawed data integration slide, the more the financial damage piles up.
The true cost of inaction is not just the money you spend fixing problems; it’s the lost revenue from opportunities you never saw coming because your data was too slow, too messy, or too fragmented.
Opportunity Costs and Stifled Innovation
Beyond the direct financial hits, there’s an enormous opportunity cost. Every hour your team spends wrestling with fragile, hand-coded integration scripts is an hour they aren’t spending on innovation. High-impact projects—like building an AI-powered recommendation engine or a predictive analytics model—get stuck on the wish list. The foundational data plumbing is just too shaky to support them.
Putting money into a modern, real-time data integration platform isn’t just another line item on the budget. It’s a strategic investment to stop the financial leaks, free up your team’s time, and build the solid data foundation you need to compete. When you automate the messy parts of moving data, you free your people to focus on what they were hired to do: use data to find and drive growth.
Moving From Batch Processing to Real-Time Streaming
If you’re still wrestling with traditional data integration, it’s time for a fundamental shift in thinking. The old way is built on batch processing, which is a bit like waiting for the morning newspaper to arrive. By the time you’re reading it over coffee, the news is already hours old, and the world has moved on. You’re getting a snapshot of yesterday, not a live feed of what’s happening right now.
This classic method works by collecting data over a set period—maybe an hour, maybe a full day—and then moving it all in one big, scheduled chunk. It gets the job done for historical reporting, but that built-in delay is the direct cause of data latency. In a world where business happens in milliseconds, batch processing just can’t keep up.
The Rise of Real-Time Data
Now, imagine getting instant push notifications on your phone instead. The moment an event happens—a customer clicks “buy,” a sensor reading spikes, a product goes out of stock—that data is captured and sent on its way. That’s real-time streaming. It closes the gap between an event happening and you gaining insight from it, allowing your business to react instantly.
This isn’t just about going faster; it’s about completely changing how data flows through your organization. Instead of systems “pulling” data on a schedule, they can now react to events as they unfold. This is the heart of an event-driven architecture, a much more powerful and modern way to build responsive, scalable applications.
For a deeper look at how these two approaches stack up, check out our guide on batch vs. real-time processing.
Introducing Change Data Capture
The engine driving this real-time revolution is Change Data Capture (CDC). The concept is brilliantly simple. Instead of constantly hammering your database with queries to ask, “What’s new? What’s new?”—a noisy and resource-heavy process called “polling”—CDC takes a much smarter, quieter approach.
Think of CDC as a silent observer listening directly to your database’s transaction log. This log is the database’s private journal, where it records every single change—every insert, update, and delete—as it happens. CDC reads this journal in real time, capturing each event without putting any extra load on the source database itself.
This technique has some massive advantages over old-school batch ETL:
- Minimal Performance Impact: Since CDC reads from the logs, it never competes with your application for precious database resources. Your production systems stay fast.
- Guaranteed Data Delivery: It captures every change, in the right order, so you never have to worry about missing data or breaking transactional integrity.
- Ultra-Low Latency: Changes are typically captured and streamed in milliseconds, making true real-time analytics and replication possible.
How CDC Solves Key Integration Challenges
When you switch to a CDC-based streaming model, you’re not just fixing one problem—you’re knocking down several of the biggest data integration roadblocks at once.
Tackling the Big Three Roadblocks
| Challenge Solved | How CDC and Streaming Provide the Solution |
|---|---|
| Data Latency | Changes are streamed in milliseconds, completely wiping out the delays of batch processing. Your analytics and downstream systems always have the freshest data. |
| Scalability Bottlenecks | Streaming architectures are built for high-velocity data. Systems like Apache Kafka, especially when managed by platforms like Streamkap, can handle millions of events per second without breaking a sweat. |
| Source System Impact | Log-based CDC avoids running heavy, performance-killing queries on your production databases. This keeps your core applications stable and fast, no matter how much data you’re moving. |
This modern approach transforms data integration from a fragile, high-maintenance bottleneck into a reliable, automated, and scalable utility. It frees up your engineers from constantly firefighting broken batch jobs and frees them to build the real-time data products that actually drive business value. With CDC, you’re not just moving data faster—you’re building a fundamentally more agile and responsive organization.
Choosing the Right Data Integration Strategy
Picking the right data integration strategy is about more than just finding a tool—it’s about matching your business needs to the right methodology. With so many options out there, it’s easy to get overwhelmed. But the secret is to ground your decision in your specific needs for speed, scale, and resources.
It all boils down to one simple question: How fresh does your data really need to be? Answering that question honestly will immediately point you in the right direction.
For some, nightly reports are fine. For others, a five-minute delay could mean a lost customer or a missed fraud alert. This is the first, most critical fork in the road.
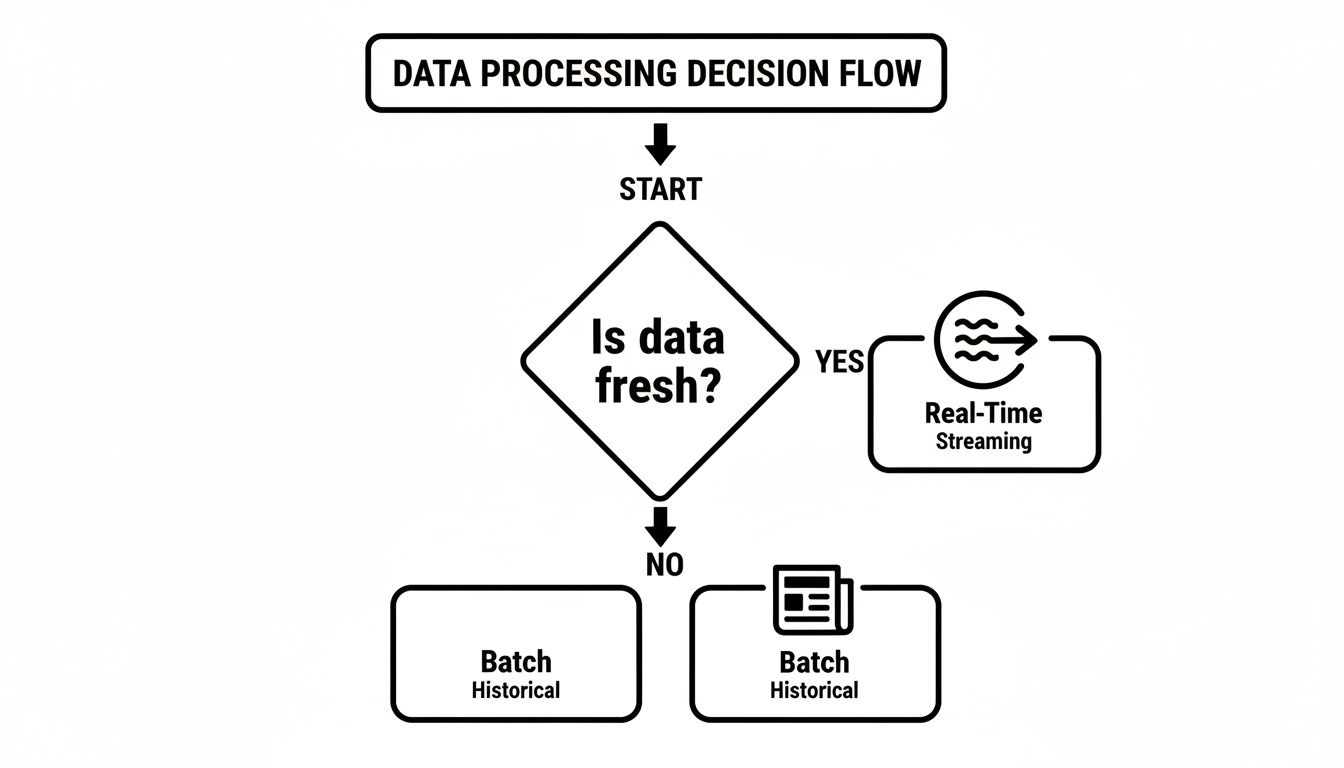
As you can see, if your use case absolutely depends on data that’s current to the millisecond, then real-time streaming is your only path forward. If not, traditional batch processing might still get the job done.
Comparison of Data Integration Approaches
Once you’ve settled the latency question, it’s time to weigh the pros and cons of the most common approaches. Each one comes with its own set of trade-offs, and understanding them is key to avoiding costly mistakes. This table breaks down the main contenders to help you see which strategy fits your technical and business needs.
| Approach | Best For | Latency | Scalability | Maintenance Overhead |
|---|---|---|---|---|
| Traditional Batch ETL | Non-urgent analytics and historical reporting where data freshness is not a priority. | High (Hours to Days) | Predictable, but struggles with sudden spikes in data volume. | Moderate to High |
| Custom-Coded Scripts | Unique, one-off integration tasks where no off-the-shelf tool fits the exact requirements. | Variable | Highly dependent on the quality of the code and infrastructure. | Very High |
| iPaaS Solutions | Connecting standardized SaaS applications with pre-built connectors for business workflows. | Low to Moderate | Varies by vendor; can become expensive at high volumes. | Low |
| Real-Time CDC Platforms | Real-time analytics, data replication, and event-driven architectures requiring millisecond latency. | Ultra-Low (Milliseconds) | Designed for high-volume, high-velocity data streams. | Very Low |
The differences here are stark. Custom scripts, for example, give you total control, but they also saddle you with technical debt and pull your best engineers away from more strategic projects. On the other hand, a modern CDC platform handles the heavy lifting for you. To see this in action, it’s worth looking at some established financial data integration tactics that really drive home the value of a well-aligned strategy.
Key Decision Criteria for Your Business
Now, let’s get practical. The right choice for a Fortune 500 company with a huge data team is almost certainly the wrong one for a nimble startup. You need to be brutally honest about your own resources and priorities.
Run through this checklist to get some clarity:
- Latency Requirements: Is this for fraud detection that needs data in milliseconds? Or is it for a BI dashboard that can be updated daily? Your answer is the biggest signpost pointing you toward real-time streaming or classic batch processing.
- Development Resources: Do you have a team of data engineers ready to build and babysit complex pipelines? Or do you need a managed, low-touch solution that a smaller team can own without getting bogged down?
- Scalability Needs: Is your data volume steady and predictable? Or do you get massive, unpredictable spikes that could crash a fragile system? Real-time platforms are purpose-built for that kind of volatility.
- Total Cost of Ownership (TCO): Don’t just look at the subscription fee. Think about the “hidden” costs: the engineering hours spent on maintenance, the infrastructure you have to manage, and the price of pipeline downtime. A managed platform often wins on TCO. Our ETL tools comparison breaks this down further.
Making an informed decision means looking at the full picture. It’s not just about solving today’s data integration challenges but also about building a foundation that can support your business as it grows and evolves.
Answering these questions gives you a solid framework for choosing your strategy and, just as importantly, explaining it to stakeholders. In the end, the best approach is the one that fixes your current headaches while empowering your team to turn data from an operational burden into a true strategic asset.
Frequently Asked Questions About Data Integration
Diving into a data integration project can feel like opening a can of worms—it often seems like every answer just leads to another question. If you’re feeling that way, you’re not alone. Teams run into the same roadblocks and questions all the time when trying to get their data infrastructure up to speed. Here are some straightforward answers to the most common ones.
What Is the Most Common Data Integration Challenge?
While every company’s tech stack has its own quirks, data silos are, without a doubt, the most common and destructive challenge we see. A silo is what happens when valuable information gets locked away in one system, completely isolated from everything else. Think of a CRM that doesn’t share data with your marketing automation tool, or an ERP system that’s an island, cut off from your data warehouse.
This kind of fragmentation makes it impossible to get a single, trustworthy view of the business. It forces people into tedious, manual work trying to stitch data together, and it completely stalls critical projects like training AI models or building out insightful BI dashboards that need the full picture. Tearing down those silos is almost always job number one.
How Does Change Data Capture Improve Data Integration?
Change Data Capture (CDC) completely changes the game by moving away from clunky, periodic batch jobs to a smooth, real-time flow of data. Instead of constantly hammering a database with queries to ask “what’s new?”, CDC taps directly into the database’s transaction log. It watches for every single row-level change—inserts, updates, and deletes—and captures it the instant it occurs.
This simple shift has a massive impact. You get:
- Near-zero latency: Your downstream systems are kept in sync with the source in milliseconds, not hours.
- Minimal source impact: You stop running those heavy, resource-draining queries that slow down your production databases.
- Complete data integrity: Every change is captured in the right order, so you never have to worry about missing data or inconsistencies.
It’s what makes CDC perfect for any situation where stale data is a non-starter, like real-time analytics dashboards, immediate fraud detection, or just keeping databases perfectly replicated.
Should We Build or Buy a Data Integration Solution?
The classic “build vs. buy” question really boils down to what your team is best at and where you want to focus your energy.
Building your own system with open-source tools like Apache Kafka and Apache Flink gives you ultimate control, but that control comes at a very high cost. It requires a serious, long-term investment in hiring and retaining engineers who specialize in the notorious complexities of distributed systems.
More often than not, this path turns your best engineers into pipeline plumbers, constantly fixing breaks and managing infrastructure instead of building products that drive your business forward.
Buying a managed platform gets you to your goal much faster, with a lower total cost of ownership and the kind of reliability you can bet your business on. It frees your team to focus on using the data, not just moving it around.
For the vast majority of companies, buying is the smarter move. It gives you all the power of real-time data technology without forcing you to become experts in running it, letting you deliver value from your data in a fraction of the time.
Ready to stop wrestling with your data pipelines and start getting real-time insights? Streamkap offers a serverless data platform powered by Change Data Capture that replaces brittle batch jobs and lowers your total cost of ownership. Start a free trial or learn more about data replication.