<--- Back to all resources
Batch vs Real Time Processing A Guide to Data Strategy
Struggling with batch vs real time processing? This guide breaks down the core differences in architecture, cost, and use cases to help you choose wisely.
Picking the right data processing model is one of the most critical decisions you’ll make for your data strategy. You’re essentially choosing between batch processing, which gathers and handles data in scheduled chunks, and real-time processing, which tackles data the second it’s created. The former is a workhorse for high-volume, non-urgent jobs like running payroll or generating daily reports. The latter is indispensable for time-sensitive tasks like fraud detection or live analytics.
Understanding Core Data Processing Models
At the end of the day, the batch vs. real-time debate comes down to timing. How quickly do you need insights? The answer dictates your architecture and directly impacts everything from operational efficiency to the customer experience. These two approaches aren’t just slightly different; they represent fundamentally opposing philosophies on how to handle information.
Batch processing is the classic, tried-and-true method. It works on a set schedule—maybe hourly, maybe nightly—collecting massive amounts of data before running a single, large processing job. It’s a lot like the postal service: all the mail for a town is collected first, then sorted and delivered in one big, efficient run. This makes it incredibly effective for massive datasets where you don’t need an immediate answer.
Real-time processing, also known as stream processing, is the polar opposite. It’s built for speed, processing data as it flows in, often in just milliseconds. Think of a live news ticker updating as events unfold. This is essential when the value of data is fleeting and decisions have to be made on the spot.
A Quick Side-By-Side Look
Getting a handle on the core differences is the first step to making an informed decision. The right choice is never universal; it’s completely dependent on your specific application and what your business needs to accomplish. Both models are cornerstones of modern engineering, and you can see how they are implemented in various data pipeline architectures to build a more complete picture.
To get us started, here’s a quick breakdown of how they compare at a high level.
Batch vs Real Time Processing At a Glance
| Characteristic | Batch Processing | Real-Time Processing |
|---|---|---|
| Data Scope | Processes large, finite blocks of data (batches). | Processes continuous, unbounded streams of data. |
| Latency | High (minutes, hours, or days). | Very low (milliseconds to seconds). |
| Throughput | High; optimized for processing large data volumes. | Varies; optimized for low-latency response. |
| Data State | Data is at rest in storage before processing. | Data is in motion as it flows through the system. |
| Resource Usage | Intermittent and scheduled, often during off-peak hours. | Continuous and always-on, requiring constant resources. |
| Common Use Cases | Payroll processing, end-of-day reporting, ETL jobs. | Fraud detection, live analytics, stock trading platforms. |
This table shows the fundamental trade-offs in a nutshell.
The core decision often boils down to a trade-off between latency and throughput. Batch processing is designed to maximize throughput for large datasets, while real-time processing is all about minimizing latency, which can come with higher operational costs.
Ultimately, the goal isn’t to decide which model is “better,” but which is the right tool for the job. As we go deeper, we’ll unpack the specific scenarios, architectural patterns, and cost factors that will help you make the right call for your data stack.
When Batch Processing Is the Smart Choice
Don’t let the buzz around real-time data fool you—batch processing is still the backbone of countless data operations for good reason. It’s a methodical and incredibly efficient approach that prioritizes high throughput and cost-effectiveness over instant results. This makes it the perfect fit for any task where getting the complete picture is more important than getting it right now.
At its core, the architecture is simple. Data is collected over a set period, known as a batch window, which could be anything from an hour to a day or even a month. Once the window closes, a scheduled job kicks off and processes the entire chunk of data at once, often using battle-tested frameworks like Apache Hadoop or Apache Spark to chew through massive volumes.
This scheduled, deliberate process is exactly where batch shines. By running resource-intensive jobs during off-peak hours, you can process terabytes of data without bogging down operational systems. That efficiency is precisely why batch processing remains a non-negotiable part of so many data stacks.
High Throughput for Large-Scale Analytics
Batch processing truly comes into its own when you’re dealing with enormous datasets that need complex, heavy-duty transformations. Imagine prepping all your data for a business intelligence warehouse. The goal isn’t to react to every single raw event, but to give analysts a complete, consistent, and accurate dataset for deep historical analysis.
Here are a few classic scenarios where this high-throughput model is the optimal choice:
- End-of-Day Financial Reporting: Banks need to reconcile every transaction from the day, calculate closing balances, and generate reports for regulators. Accuracy and completeness are non-negotiable, and processing everything at once is the only way to guarantee data integrity.
- Monthly Billing and Payroll Cycles: Think about a utility company generating millions of customer bills or a payroll system calculating wages and deductions for thousands of employees. These are perfect examples of tasks that happen on a fixed schedule and are executed in a single, massive run.
- Large-Scale ETL/ELT for Data Warehouses: Pulling data from a dozen different operational systems, cleaning it up, and loading it into a data warehouse like Snowflake or BigQuery is a textbook batch job. These jobs typically run overnight to refresh dashboards with the previous day’s complete dataset.
The decision to use batch processing often boils down to a simple trade-off: you sacrifice immediate insights for superior efficiency, lower cost, and a much simpler architecture. When the business cost of a few hours of data latency is low, batch is almost always the more pragmatic option.
Cost-Efficiency and Simpler Operations
Another huge win for batch is cost control. Real-time streaming systems require an “always-on” infrastructure, which means you’re paying for compute resources around the clock. Batch systems, on the other hand, consume resources in predictable, scheduled bursts, making it far easier to manage budgets and scale infrastructure for specific processing windows.
Operational simplicity is another big draw. Let’s be honest: debugging a failed batch job is usually much more straightforward than trying to untangle a complex, distributed streaming pipeline where you’re chasing down out-of-order events or state management bugs.
This isn’t just anecdotal, either. The global big data market, which is built on a foundation of batch processing, shows consistent growth. You can dig into these data processing production trends from OnPoint Insights to see just how firmly these established methods are holding their ground.
Ultimately, choosing between batch vs real time processing is a strategic decision. While the pull of instant data is strong, the sheer reliability, efficiency, and cost-effectiveness of batch processing make it the smart, strategic choice for a huge range of critical business functions.
Why Real-Time Stream Processing Is a Game Changer
While batch processing has its place for handling huge, static datasets, today’s business world runs on immediate answers. We need insights in milliseconds, not hours or days. This is where real-time stream processing completely flips the script. It’s a fundamental shift from analyzing data at rest to processing data in motion—a constant, unending flow of events.
Instead of waiting for a batch window to close, streaming systems grab, process, and act on data the very moment it’s created. The whole approach is built for speed and immediacy, letting companies react to opportunities and threats as they unfold. Think about it: the value of an insight is often highest in its first few seconds. Stream processing is the only way to actually capture that value.
This kind of speed is only possible because the underlying architecture is totally different. At its core are some powerful, open-source technologies that have become the de facto standard for handling massive event streams.
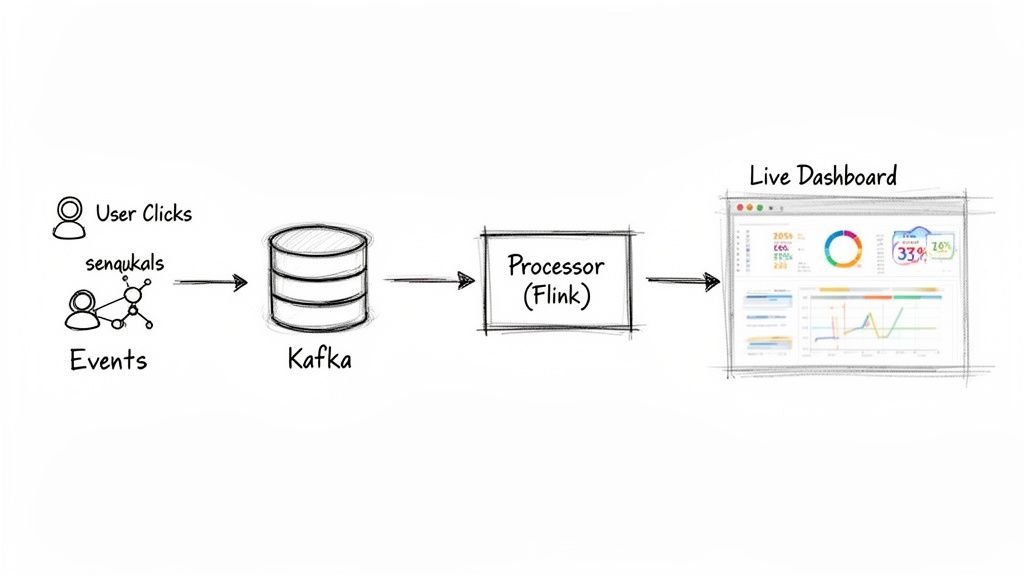
Core Components of a Streaming Architecture
Most modern streaming pipelines rely on a couple of specialized tools that are absolute workhorses in the field. Two of the most important are:
- Apache Kafka for event transport. Kafka is the central nervous system of any modern data stack. It’s a durable, high-throughput message broker that can handle literally trillions of events per day, ingesting raw data from countless sources and making it available for processing.
- Apache Flink for the heavy lifting. Flink is a stateful stream processing engine that can run sophisticated calculations, transformations, and aggregations on unbounded data streams with incredibly low latency.
Together, they form a powerful combination for building tough, scalable real-time applications. But there’s a critical piece missing: how do you get data from your core operational databases into Kafka in the first place without crippling them?
The Rise of Change Data Capture (CDC)
The old way of sourcing data from databases like PostgreSQL or MySQL was to run frequent, resource-heavy queries. This puts a massive load on production systems and is just a terrible fit for real-time needs. That’s why Change Data Capture (CDC) has become such a key technology for modern streaming.
CDC is a technique that taps directly into the database’s transaction log to capture row-level changes—inserts, updates, and deletes—and streams them as events in real time. Instead of hammering the database with queries, CDC reads the log, which is a highly efficient process that has almost zero impact on the source system’s performance.
By turning your database into a streamable source, CDC unlocks its data for immediate use in analytics, machine learning, and operational systems. It effectively bridges the gap between your transactional systems and your real-time data stack.
Real-World Value Driven by Real-Time Data
The applications for real-time stream processing are everywhere, and they deliver tangible business value. When you can analyze events in the moment, you can create far more dynamic and responsive customer experiences.
Just think about these practical examples:
- Dynamic E-commerce Pricing: An online retailer can adjust product prices on the fly based on real-time demand, competitor price changes, and current inventory levels to maximize revenue.
- Live Fraud Detection: A financial institution can analyze transaction streams as they happen, identifying and blocking fraudulent activity in milliseconds—often before the transaction is even finalized.
- Interactive Operational Dashboards: A logistics company can monitor its entire fleet on a live map, tracking ETAs, flagging delays, and re-routing vehicles to stay on schedule.
Of course, building and managing these complex systems takes serious operational expertise. This is precisely why managed solutions have become so popular. Platforms like Streamkap handle the complexities of deploying and managing Kafka and Flink, which lets teams focus on building powerful CDC pipelines and generating business value instead of wrestling with infrastructure. This makes the choice between batch vs real time processing much simpler by making the more powerful option far more accessible.
Comparing Key Architectural and Cost Differences
When you get past the basic definitions, the real conversation around batch vs. real-time processing boils down to some serious architectural and financial trade-offs. The path you choose here doesn’t just shape your data capabilities; it directly impacts your operational costs and the complexity your engineering team has to manage. These two models aren’t just about speed—they are fundamentally different in how they handle data, recover from failure, and consume resources.
For anyone in a data leadership role, getting these nuances right is everything. This decision trickles down to your infrastructure bills and the specific skills you need on your team. One approach is built for massive throughput and predictable costs, while the other is all about immediacy and constant availability.
Latency and Data Scope
The most obvious difference is latency, but the architectural ripple effects go much deeper. Batch processing is designed to work on a finite set of data—a bounded chunk collected over a few hours or even a full day. This makes for simple, predictable jobs that process a known amount of information and deliver results with high latency, often measured in hours.
Real-time processing, on the other hand, is built to handle an infinite, or unbounded, stream of data. The system has no idea what’s coming next or when (or if) the stream will ever end. This demands a completely different architectural mindset focused on continuous computation, managing state over time, and spitting out results in sub-second timeframes.
- Batch Latency: Think of end-of-day financial reports. A delay of several hours is totally fine and even expected.
- Real-Time Latency: This is critical for something like fraud detection, where a decision has to be made in under 100 milliseconds to stop a bogus transaction in its tracks.
Fault Tolerance and Consistency Models
How a system bounces back from an error is another major fork in the road. Batch systems are often much simpler to deal with here. If a nightly job fails, you can usually fix the underlying problem and just rerun the whole batch. The process is idempotent, making it easy to reason about and manage.
Streaming systems, however, have to be designed for continuous operation and absolute data integrity. You can’t just “rerun” a failure without carefully thinking about the data’s state. This leads to more sophisticated models for handling faults:
- At-Least-Once Delivery: This guarantees every event gets processed, but it might mean you get some duplicates. This is often acceptable in systems where you can de-duplicate the data later on.
- Exactly-Once Delivery: This is the holy grail. It ensures every single event is processed precisely one time, even if the system has hiccups. Pulling this off is a serious architectural challenge and a hallmark of truly robust streaming platforms.
The core architectural trade-off lies here: batch processing offers simpler recovery at the cost of high latency, while real-time processing provides low latency but demands a more sophisticated approach to ensure data consistency and fault tolerance.
The True Cost of Data Processing
Cost is often the tie-breaker, but a quick, surface-level comparison can be very misleading. Batch processing might look cheaper on paper because you’re only spinning up compute resources on a schedule, but the total cost of ownership (TCO) often tells a different story.
Batch Processing Costs
The financial model for batch is wonderfully predictable. You pay for compute resources during specific processing windows, often during off-peak hours when cloud providers charge less. This makes budgeting a breeze.
But there are hidden costs. Constantly running large-scale queries against your production databases can tank their performance, forcing you to upgrade to more powerful—and much more expensive—source systems. On top of that, the business cost of acting on stale data and missing out on immediate opportunities can easily dwarf any savings you made on compute.
Real-Time Processing Costs
Real-time systems need an “always-on” infrastructure, which means a continuous operational expense. This includes the cost of keeping a message broker like Apache Kafka and a processing engine like Apache Flink running 24/7. At first glance, this definitely looks more expensive.
However, modern streaming, especially when paired with Change Data Capture (CDC), can slash your TCO. CDC reads directly from database logs with almost no performance impact, so you can forget about those costly source system upgrades. Plus, managed solutions like Streamkap handle the operational heavy lifting, so you don’t need a team of specialized engineers just to keep the lights on.
When you factor in the massive business value of instant insights—like preventing a single, five-figure fraudulent transaction—the ROI on real-time infrastructure becomes incredibly clear.
Detailed Architectural and Operational Comparison
To make the right choice, you have to weigh these trade-offs carefully. The table below breaks down the technical and business implications across several critical dimensions, helping you see where each model shines.
| Dimension | Batch Processing | Real-Time Processing | Key Consideration |
|---|---|---|---|
| Latency | High (Hours to Days) | Low (Milliseconds to Seconds) | What is the business cost of stale data? |
| Data Scope | Finite, Bounded Datasets | Infinite, Unbounded Streams | Is your data a one-time report or a continuous flow? |
| Compute Model | Scheduled, Intermittent Bursts | Continuous, Always-On | Can your budget accommodate variable or steady operational costs? |
| Fault Tolerance | Simple Reruns of Failed Jobs | Complex State Management | How critical is exactly-once processing for your use case? |
| Consistency | Strong Consistency (Post-Processing) | Eventual or Strong (System Dependent) | Does your application require immediate, consistent state? |
| Cost Structure | Predictable, Scheduled OpEx | Continuous OpEx, Potentially Higher Upfront | Which model offers a lower Total Cost of Ownership (TCO) for your specific needs? |
Ultimately, choosing between batch and real-time processing isn’t just about the compute bill. It’s about evaluating the entire architectural lifecycle—from data ingestion and failure recovery all the way to the direct business impact of having fresh, actionable data.
How to Choose the Right Data Processing Strategy
Deciding between batch vs real-time processing isn’t just a technical exercise; it’s a strategic business decision. The right choice has to line up perfectly with your daily operations, your budget, and how much fresh data is truly worth to your bottom line.
The first and most important question you should ask is this: What is the business cost of stale data?
Be honest with that answer. It will dictate your entire data architecture. If a few hours of delay won’t really move the needle on revenue or frustrate customers, the sheer efficiency of batch processing is probably your best bet. But if every second of lag means a lost sale or a bigger security risk, then real-time processing stops being a luxury and starts being a necessity.
This decision tree can help you visualize the key forks in the road, like whether you need sub-second latency or if your data is constantly flowing without a defined end.
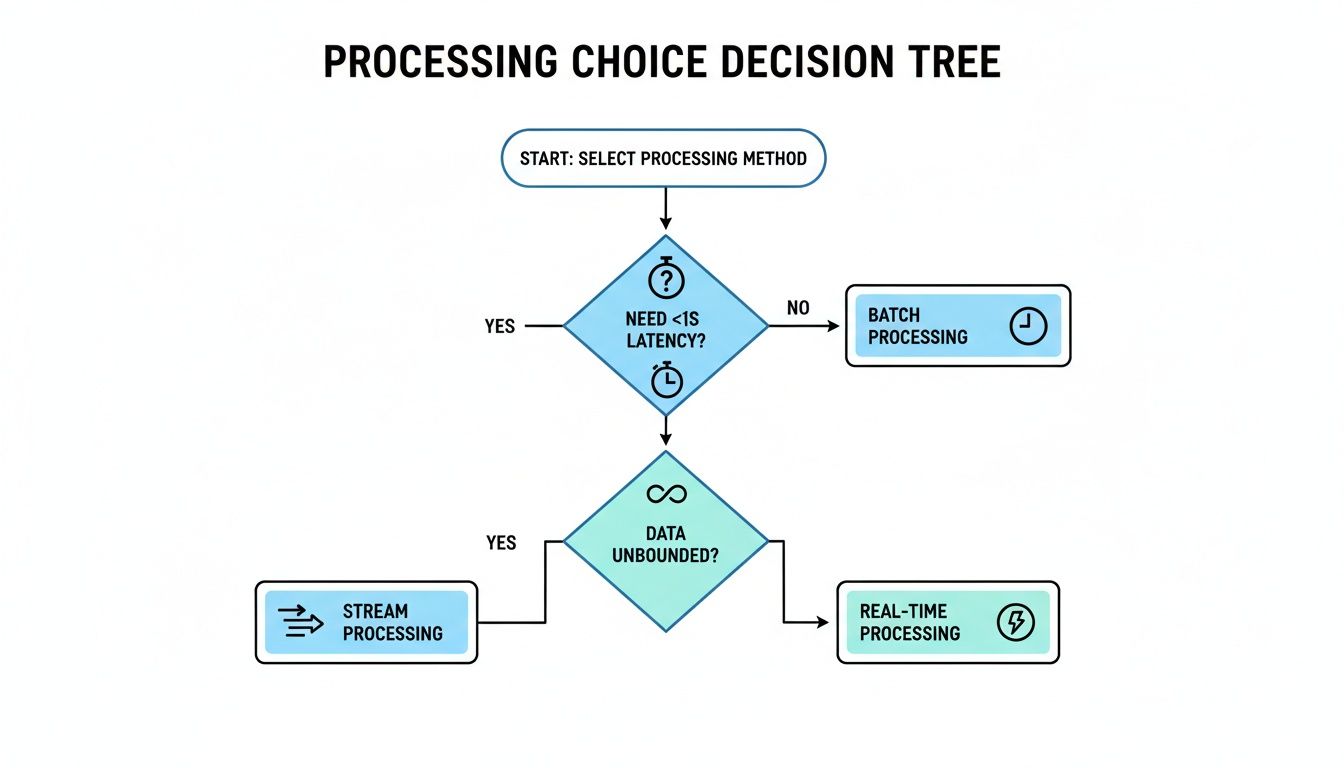
As the diagram shows, the choice really boils down to your latency tolerance and the nature of your data source. It’s about mapping the technical path to your specific business reality.
Key Questions for Your Decision Framework
To get out of the clouds and onto solid ground, your team needs to work through a few practical questions. The answers will point you toward the most logical path, making sure you invest in a solution that fixes real problems instead of just chasing the newest tech trend.
- How fast do you need answers? Are you just trying to build a daily summary report for the leadership team? That’s a classic batch job. Or do you need to fire off an instant alert when a customer’s account shows signs of fraud? That’s a clear-cut real-time need.
- What’s the “shelf life” of your data? For an e-commerce platform, inventory data goes bad fast—a five-minute delay could mean selling an item you no longer have. On the other hand, data for a monthly sales trend report has a much longer useful life.
- What are your budget and scalability limits? Batch systems typically have predictable costs tied to those scheduled jobs. Real-time systems, however, need an always-on infrastructure. This can mean a higher baseline cost, but it might save you money in the long run by avoiding expensive database upgrades just to keep up.
- How complex can your team get? Let’s be real: building and maintaining a streaming pipeline with tools like Kafka or Flink has traditionally required some specialized expertise. While managed platforms can definitely lower that barrier, it’s still a major factor to consider.
The smartest data strategies are rarely an all-or-nothing choice. The real goal is to build an architecture that’s both powerful and practical, connecting what’s technically possible to specific, measurable business outcomes. At its core, great data engineering is about picking the right tool for the right job.
Exploring Hybrid Architectures: The Best of Both Worlds
For a lot of companies, the best answer isn’t choosing one model over the other. It’s combining them. A hybrid approach, often called a Lambda or Kappa architecture, gives you the immediate feedback of a real-time “speed layer” while using a batch “serving layer” for deep, historically accurate analysis.
Think about a big retail business. They might use a hybrid model like this:
- Real-Time Speed Layer: A streaming pipeline processes sales transactions the moment they happen. This powers live inventory dashboards for the warehouse, triggers low-stock alerts for merchandisers, and fuels the real-time recommendation engine on the website.
- Batch Serving Layer: Every night, a batch job crunches the entire day’s sales data. It joins this information with data from the supply chain and marketing systems to produce detailed financial reports, calculate sales commissions, and update the data warehouse for BI analysts.
This dual-layer system means operational teams get the live data they need to run the business minute-by-minute. At the same time, strategic teams get the complete, reliable historical data they need for deep dives and long-term planning. It’s a pragmatic acknowledgment that different business questions demand different data speeds. By thoughtfully combining batch and real-time processing, you can build a flexible data stack that serves everyone without compromise.
Modernizing Your Data Stack with Real-Time CDC
If you’re looking to stay competitive, moving away from legacy batch ETL and toward a modern, real-time data stack is no longer optional. The linchpin of this entire transition is a technology called Change Data Capture (CDC). It’s the bridge that connects the old world with the new, giving you a smooth, low-impact way to get valuable data out of your operational databases and into the hands of those who need it.
Think about how traditional batch processing works: it constantly hammers your source databases with queries, creating a huge performance drag that can even slow down your primary applications. CDC flips that model on its head. Instead of running those expensive, repetitive queries, it hooks directly into the database’s internal transaction log—the unchangeable, real-time record of every single INSERT, UPDATE, and DELETE.
This method is incredibly efficient. It captures every data modification as a separate event, all with virtually zero impact on the source system’s performance. You effectively turn your database into a continuous, real-time data stream, which means you can power your analytics, apps, and dashboards with the freshest data imaginable.
Accelerating Your Transition with a Managed Platform
Let’s be realistic: building a robust CDC pipeline from the ground up is a serious undertaking. You need deep expertise in complex distributed systems like Apache Kafka for moving the events and Apache Flink for processing them. Just managing, scaling, and guaranteeing the reliability of this kind of infrastructure is a full-time engineering challenge, pulling your team away from creating actual business value.
This is exactly where a managed CDC platform comes in. A solution like Streamkap handles all the messy, operational complexity of Kafka and Flink for you. Instead of your team wrestling with low-level infrastructure, they can focus on what really matters: defining data sources and destinations through a straightforward UI. If you’re new to the concept, you can learn more about what is Change Data Capture and see how it’s the engine behind today’s data pipelines.
The real advantage of a managed platform is speed—and not just the speed of your data. It’s the speed of implementation. Teams can deploy production-ready, real-time pipelines in a matter of minutes, not months. This drastically shortens your time-to-insight and significantly lowers the total cost of ownership (TCO).
Unlocking Low-Latency Replication and Guaranteed Delivery
A properly built CDC pipeline offers much more than just speed; it brings a level of reliability that fragile, error-prone batch jobs simply can’t match. The benefits are tangible and solve common batch processing pain points.
- Low-Latency Data Replication: Data moves from your production database to destinations like Snowflake, Databricks, or BigQuery in seconds. Your analytics are always reflecting the current state of your business.
- Guaranteed Data Delivery: Batch jobs often fail, requiring manual intervention and reruns. CDC pipelines built on a foundation like Kafka offer at-least-once or exactly-once processing guarantees, ensuring that no data is ever lost along the way.
- Reduced Source System Load: By getting rid of the constant polling and heavy queries, CDC lets your operational databases breathe. They can focus on their main job: serving your customers.
At the end of the day, adopting real-time CDC isn’t just a technical upgrade; it’s a strategic one. It fosters a more agile, data-driven culture where decisions are based on what’s happening right now, not on yesterday’s reports. This evolution makes the debate over batch vs. real-time processing feel less like a choice and more like a clear path forward.
Frequently Asked Questions
When you’re trying to pick between batch and real-time processing, a few common questions always seem to pop up. Here are some straightforward answers to help you navigate your data architecture decisions.
Can I Use Both Batch and Real-Time Processing in the Same System?
Absolutely, and it’s quite common. This hybrid approach is often called a Lambda architecture. It essentially gives you a “speed layer” for handling live data and generating immediate insights, alongside a “batch layer” that crunches all the historical data for deep, comprehensive analysis.
You get the best of both worlds this way, but be aware that it adds a layer of complexity to your system. It’s a great fit when you absolutely need both up-to-the-minute views and the ability to run massive analytical queries over your entire dataset.
Is Real-Time Processing Always More Expensive?
Not necessarily. It’s easy to look at the always-on infrastructure required for real-time systems and assume the costs will be higher. But that’s only part of the story.
You have to weigh that against the business cost of acting on stale data. What’s the price of a missed opportunity or a poor decision made because the information was hours or days old? Sometimes, the cost of not having real-time data is far greater than the infrastructure expense.
The primary challenge is the cultural and technical shift from processing finite datasets to managing continuous, unbounded data streams. This requires new skills, different tools, and adopting an event-driven mindset. Teams must learn to handle concepts like state management and out-of-order data, which are less prevalent in traditional batch systems.
Ready to modernize your data stack? Streamkap provides a managed CDC and streaming platform that eliminates the operational complexity of Kafka and Flink, enabling you to build real-time pipelines in minutes, not months. Start your journey at https://streamkap.com.