Data in Motion Your Complete Guide to Real-Time Streaming
Unlock the power of real-time data streaming. This guide explains data in motion, its core technologies like CDC and Kafka, and how to build powerful pipelines.
You’ve probably heard the terms data in motion and data at rest, but what do they actually mean in practice? Think of it this way: data at rest is like a printed map—a static snapshot of information stored on a hard drive or in a database. It’s useful, but it’s frozen in time.
Data in motion, often called data in transit, is the live traffic feed. It’s the information actively flowing between systems—across a network, from an application to a user, or from RAM to a CPU. It gives you actionable, real-time intelligence about what’s happening right now.
Data In Motion vs Data At Rest At A Glance
To make this crystal clear, let’s break down the key differences between these two states of data. The distinction isn’t just technical; it fundamentally changes what you can do with your information.
| Attribute | Data In Motion | Data At Rest |
|---|---|---|
| State | Actively moving between locations (e.g., across a network). | Stored in a fixed location (e.g., on a disk, in a database). |
| Time Value | High and immediate. Value decays quickly. | Stable and long-term. Value persists over time. |
| Analysis | Real-time processing and streaming analytics. | Batch processing and historical queries. |
| Primary Use Cases | Fraud detection, real-time personalization, IoT sensor monitoring, live analytics. | Data warehousing, long-term archiving, business intelligence reporting, compliance. |
| Key Technologies | Apache Kafka , Apache Flink , Change Data Capture (CDC), message queues. | Databases (SQL/NoSQL), data lakes, cloud storage (S3, Azure Blob), file systems. |
Understanding this table is the first step. Data at rest is crucial for looking back and understanding history, while data in motion is all about seeing and acting on the present.
Why Data In Motion Is Your New Competitive Edge
Imagine trying to navigate a bustling city using a day-old paper map. You’d have no idea about sudden road closures, fresh traffic jams, or new detours. You’d be making decisions based on outdated information, leading to delays and frustration. For years, this is exactly how many businesses operated, relying on data at rest that was processed in slow, periodic batches.
This traditional approach, known as batch processing, creates a critical “data lag”—the gap between when an event happens and when you can actually do something about it. While this was fine in a slower world, today’s business environment demands instant responses.
The Shift from Static Maps to Live Feeds
Data in motion completely flips this model on its head. Instead of waiting for data to be collected, stored, and then processed in large chunks, you analyze it as it flows through your systems. This real-time capability is no longer a luxury; it’s a fundamental necessity for staying competitive.
Processing data in motion allows organizations to:
- Stop fraud instantly by analyzing transaction patterns the moment they occur, not hours later.
- Personalize customer experiences by reacting to user clicks and behaviors as they happen on a website or app.
- Optimize supply chains by tracking inventory and logistics data as it moves, preventing bottlenecks before they even form.
This pivot to real-time operations is driving massive market growth. The global big data market, which is powered by the need to handle data in motion, was valued at roughly $90 billion as of January 2025. This explosion is fueled by the need to manage and analyze the estimated 402.74 million terabytes of data generated daily.
Leaving Data Lag Behind
The true power of embracing data in motion lies in eliminating data lag. Your decisions are no longer based on historical snapshots but on the current reality of your business. This opens up opportunities that are simply impossible with batch processing.
By capturing and analyzing data as it’s created, businesses move from reactive problem-solving to proactive opportunity-seeking. This is the essence of becoming a truly data-driven organization.
Ultimately, harnessing data in motion means your business operates with a live, dynamic view of the world. You gain the agility to make split-second decisions, respond to market changes instantly, and create far superior customer experiences. To get there, it’s essential to explore the fundamentals of real-time data integration and see how it reshapes modern architectures. This approach is the key to building a more responsive, intelligent, and successful enterprise.
The Core Technologies Powering Data In Motion
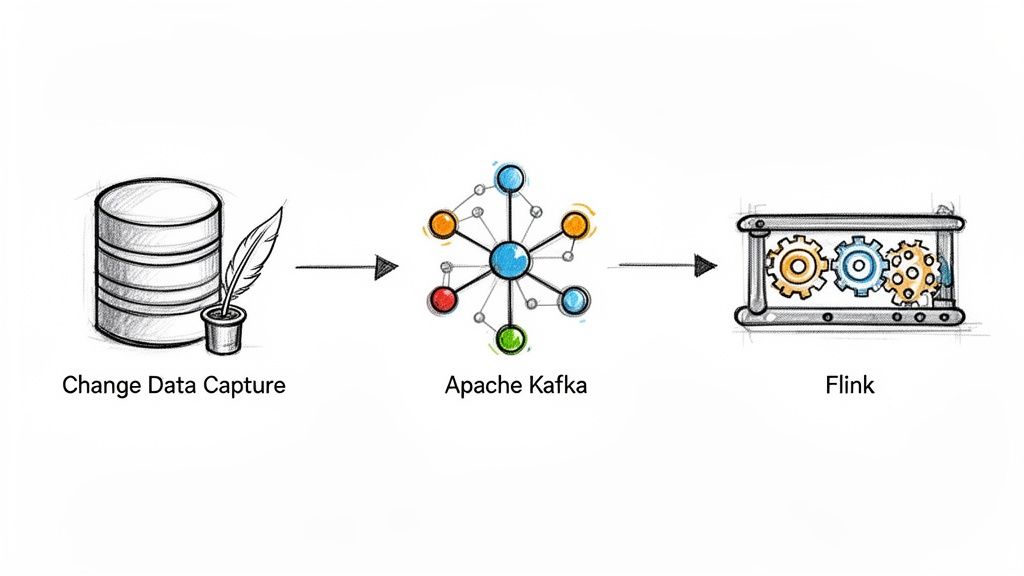
To make data in motion a reality, you need a powerful engine running under the hood. While the concept of real-time streaming might seem intimidating, it really boils down to a few key technologies working together in perfect harmony. Once you understand these components, the whole process clicks into place.
Each piece of this technology puzzle has a specific job, from spotting changes the instant they happen to processing that data mid-flight. Together, they create the foundation of any modern real-time data architecture, unlocking the immediate insights that give businesses an edge.
Let’s break down the three essential pillars that make it all possible.
Change Data Capture: The Database Journalist
The first step in any real-time pipeline is simply knowing when something has changed in your data. In the past, the only way to do this was to constantly ask the database, “Anything new yet?” This old-school method, called batch polling, is slow, clunky, and puts a ton of unnecessary strain on your source systems.
Change Data Capture (CDC) is a much smarter solution. Think of it as a dedicated journalist assigned to your database. Instead of hammering the entire system with questions, CDC quietly reads the database’s transaction log—the internal diary where every single change (insert, update, delete) is recorded.
This approach gives you two massive advantages:
- Near-zero latency: Changes are captured the moment they’re written to the log, not minutes or hours later.
- Minimal performance impact: CDC works in the background without getting in the way of your database’s main job, so your applications keep running smoothly.
With CDC, you get a continuous, detailed stream of every event without bogging down the systems you depend on.
Apache Kafka: The Central Nervous System
Okay, so CDC has captured an event. Now what? You need a rock-solid, high-speed system to get these events from the source to all the different places that need them. This is exactly what distributed event streaming platforms like Apache Kafka were built for.
Picture Kafka as the central nervous system for your data. It acts as a durable, ordered highway that can handle an insane volume of events from countless sources (your databases with CDC) and deliver them reliably to many destinations (like analytics dashboards, microservices, or data warehouses).
Kafka isn’t just a simple pipe. It’s a fault-tolerant, scalable buffer that separates your data sources from your data consumers. If a downstream application goes offline, the data just waits safely in Kafka, ready to be picked up when the system is back online.
This design ensures no event ever gets lost, giving you the reliability you need for any mission-critical data pipeline.
Apache Flink: The On-The-Fly Workshop
Just capturing and moving data is only half the battle. Raw event data often needs to be cleaned up, combined with other information, or reshaped before it’s truly useful. Doing this after the data has landed in a warehouse is the old way; modern stream processors let you do it while the data is still flying through the pipeline.
Apache Flink is a powerful stream processing framework that acts like an on-the-fly workshop for your data. As events stream in from Kafka, Flink can perform incredibly complex operations on them in real time.
For example, a Flink job could:
- Join a real-time stream of user clicks with a static customer profile dataset to add valuable context.
- Calculate a running total of sales by region over a five-minute sliding window.
- Instantly filter out potentially fraudulent transactions based on a complex set of rules.
This ability to process and shape data in motion is where the real magic happens. It’s how you turn a raw flood of events into sharp, actionable intelligence.
For a deeper look at how these systems fit together, our overview of data streaming platforms offers more detail. These three technologies—CDC, Kafka, and Flink—form a powerful trio, enabling businesses to build robust and scalable real-time data pipelines.
Architecting Your Real-Time Data Pipelines
Knowing the individual tools is one thing, but assembling them into a solid, cohesive strategy is the real challenge. When you’re architecting for data in motion, you’re not just plugging in new technologies. It’s a fundamental shift in thinking—moving away from rigid, monolithic systems toward designs that are far more flexible and responsive.
The whole approach centers on creating pipelines that are not only fast but also scalable and tough enough to handle anything thrown at them. You’re building a system that can manage the unpredictable nature of real-time data streams without collapsing under pressure or, even worse, losing critical information. It’s all about designing for flow, not just for storage.
Embracing Event-Driven Architecture
At the heart of modern data pipelines is a concept called Event-Driven Architecture (EDA). Think of a traditional system like a statue carved from a single, massive block of stone. It’s impressive, but completely inflexible. Once you’ve made a cut, it’s incredibly difficult to change.
EDA, on the other hand, is like building with LEGOs.
Each component is a small, independent service that talks to other services by producing and consuming events. This “decoupling” means you can add, remove, or upgrade individual pieces without breaking the entire system. For instance, a single “new order” event can be picked up by the inventory system, the shipping department, and a real-time analytics dashboard all at the same time, without them ever needing to know the others exist.
This modularity gives you some incredible advantages:
- Flexibility: You can easily adapt to new business needs just by adding new services that listen for events already flying around the system.
- Scalability: You can scale individual components based on their specific workload, rather than having to scale the entire application monolith.
- Resilience: If one service fails, the others can keep on trucking. The events are safely buffered in a message broker like Kafka, waiting to be processed when the service comes back online.
The Streaming ETL Pattern
This architectural shift has given birth to a powerful new pattern: Streaming ETL. The old model of Extract, Transform, and Load (ETL) relied on slow, nightly batch jobs. These jobs would pull huge amounts of data from source systems, process it all at once, and then dump it into a data warehouse. This created a huge time lag, meaning business decisions were always based on yesterday’s news.
Streaming ETL completely flips this on its head, turning the process into a continuous, low-latency flow.
Instead of waiting for a scheduled batch window, data is extracted via CDC, transformed on the fly by a stream processor like Flink, and loaded into its destination in near real-time. This means your data warehouse is always just seconds behind your operational databases, not hours or days.
This approach transforms the data warehouse from a historical archive into a dynamic, up-to-the-minute source of truth that the entire organization can rely on.
Key Design Considerations
As you start designing your pipelines, a few practical considerations are absolutely crucial for success. Building high-performance streaming data pipelines demands a deliberate focus on fault tolerance and scalability right from the start.
- Fault Tolerance: What happens if a server crashes or a network connection drops? Your architecture has to be able to withstand failure. Technologies like Kafka are built for this, automatically replicating data across multiple nodes to ensure no events are ever lost.
- Scalability: Can your system handle a sudden, massive spike in data volume? Your design should allow for horizontal scaling, meaning you can just add more machines to distribute the load without any downtime.
- Latency: How fast does the data really need to be? Minimizing latency is often the main goal. This involves optimizing every single step of the pipeline, from efficient CDC capture at the source to streamlined transformations in the middle.
Unlocking Value with Real-World Applications
It’s one thing to talk about architectural diagrams and data theory, but the real power of data in motion comes alive when you see it solving actual business problems. This is where the technical “how” meets the business “why.” Companies at the top of their game aren’t just hoarding data anymore; they’re acting on it the moment it’s created to drive real, tangible results.
By swapping out slow, batch-based processes for live data streams, these organizations are completely overhauling their operations, creating better customer experiences, and finding entirely new ways to make money. Let’s dig into a few powerful examples of data in motion in the wild.
E-commerce Personalization in Real Time
Think about the last time you browsed an online store. You click on a blue jacket, then a pair of running shoes. In an old-school, batch-oriented system, the store might send you an email with recommendations for those items… tomorrow. By then, the impulse to buy has probably vanished.
With data in motion, the whole experience is immediate.
- Every click you make is an event, instantly captured using Change Data Capture (CDC).
- That event flows through a streaming platform like Kafka.
- A stream processor analyzes your clicks, understands you’re interested in “blue activewear,” and instantly refreshes the homepage to show you a perfectly coordinated outfit.
This isn’t some futuristic concept; it’s standard practice for e-commerce leaders. They use live user behavior to fuel recommendation engines, customize search results, and even adjust pricing on the fly, turning a flicker of interest into a completed sale.
This diagram illustrates the basic flow of a streaming ETL pipeline, where data moves continuously from a source, through a processing engine, and to a destination.
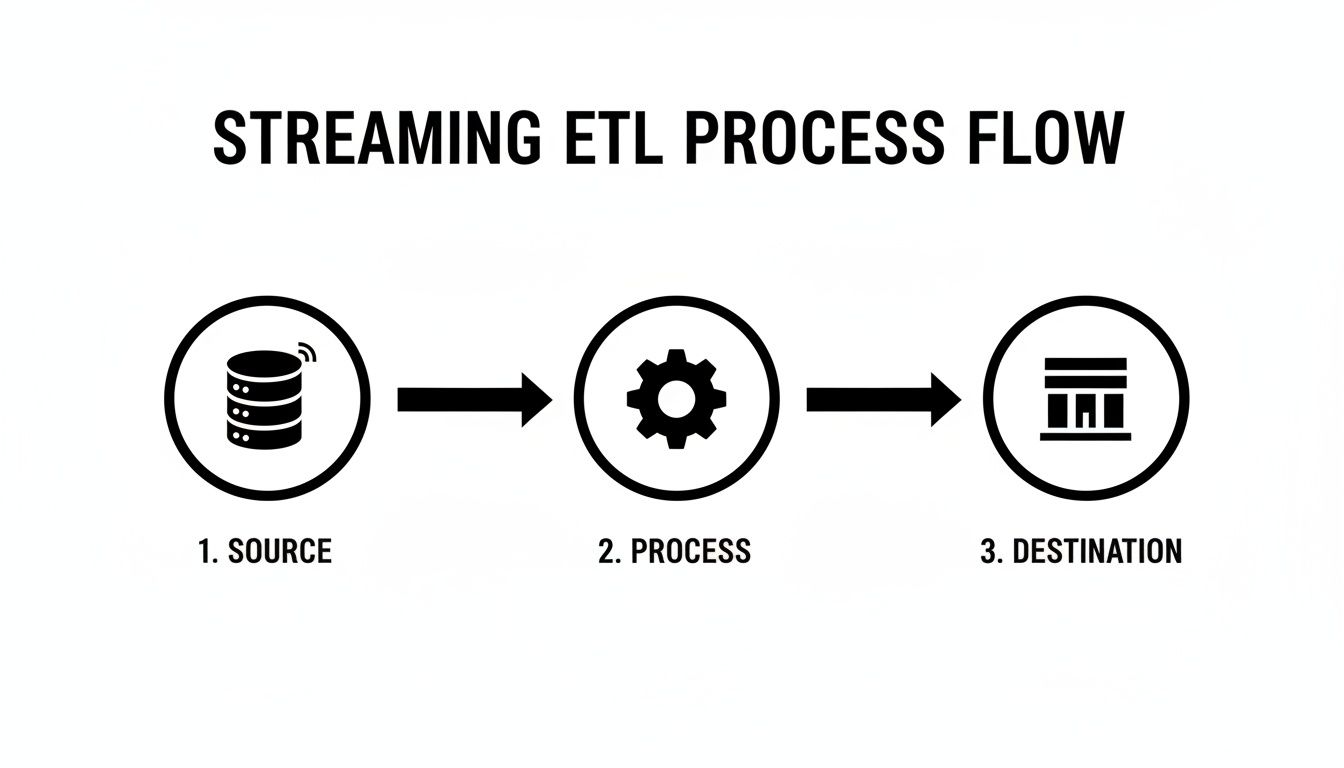
The big idea here is replacing delayed batch jobs with an always-on data highway that lets you take action right now.
Financial Fraud Detection in Milliseconds
In the financial world, speed isn’t just a feature—it’s everything. A fraudulent credit card transaction can be over and done with in less than a second. Waiting for a nightly report to flag suspicious activity is like trying to catch a thief who’s already on another continent. This is where processing data in motion becomes a non-negotiable security tool.
When a card is swiped, a transaction event is born. A real-time fraud detection system can:
- Grab the transaction data the instant it happens.
- Enrich it with historical context, like a user’s typical spending patterns and locations.
- Run it through a machine learning model to score the transaction’s fraud risk—all within milliseconds.
If the score is too high—say, a purchase in a new country just minutes after a local one—the transaction is blocked before any money changes hands. This simple shift saves companies millions in potential losses.
By analyzing financial data as it moves, institutions shift from investigating past fraud to preventing it from ever happening. It’s a proactive defense mechanism powered by streaming data.
Predictive Maintenance in Manufacturing
On a factory floor, unplanned downtime is the ultimate profit killer. A single broken part on an assembly line can bring production to a grinding halt, costing thousands of dollars for every minute of inactivity. The old way was either reactive (fixing things after they break) or calendar-based (replacing parts whether they needed it or not).
Smart factories now embed IoT sensors in their machinery, which generate a constant stream of data in motion. This data—think temperature, vibration, and pressure readings—is analyzed in real time, allowing manufacturers to:
- Spot tiny irregularities that signal an impending equipment failure.
- Send alerts to maintenance crews to inspect specific components before they actually break.
- Build maintenance schedules around the actual health of the equipment, not just the calendar.
This predictive approach is a game-changer. The motion control market, which is built on real-time sensor data, hit $16.7 billion in 2024 and is on track to reach $25.3 billion by 2033. Today, smart factories process an estimated 60% of their data in real time, a strategy that has cut unplanned outages by an average of 30%.
The applications of real-time data span countless domains; for example, the core principles of using live data for smarter decisions are also central to fields like HR analytics. These examples all point to a single truth: businesses that master data in motion gain a massive competitive edge by making faster, more intelligent decisions.
Navigating Security and Compliance Challenges
Moving data at high speed is a game-changer, but all that velocity brings a new set of security and compliance hurdles. Fast data must also be safe data. In a world of constant data streams, protecting data in motion can’t be an afterthought—it has to be a core part of the design.
This means you have to think beyond just securing the network. You need to consider the entire journey of your data, from the moment it leaves the source database to the second it lands in a dashboard. Every single handoff is a potential weak spot. Securing this fast-moving environment demands a strategy with multiple layers, tackling both immediate threats and long-term regulatory rules.
Building An Armored Car For Your Data
The most basic layer of defense is encryption. Think of it like an armored car for your data; just as the truck protects cash while it’s being moved, end-to-end encryption shields your data as it zips across networks. For any kind of sensitive information, this is simply not optional.
Here are the essential security layers you need:
- End-to-End Encryption: Using protocols like TLS/SSL makes your data completely unreadable to anyone trying to snoop on it between point A and point B. This is your first and most important line of defense.
- Robust Access Controls: Not everyone in your organization should see every piece of data. By setting up strong authentication and role-based access control (RBAC), you ensure only the right people and systems get the keys to specific data streams.
- Data Masking and Anonymization: Sometimes you need the data’s structure for development or testing, but not the sensitive bits. Masking techniques can hide personally identifiable information (PII) while keeping the data useful for non-production work.
Security for data in motion is a continuous process, not a one-time setup. It involves constant monitoring, auditing, and adaptation to new threats to ensure the integrity and confidentiality of your information stream.
Translating Regulations For Streaming Architectures
Data privacy laws like GDPR and CCPA were largely written with static databases in mind, but their principles absolutely apply to data that’s on the move. To be compliant in a streaming world, you have to be able to track, audit, and control data as it flows.
This means your architecture has to meet some specific technical demands. You need to maintain a clear chain of custody for every record. This is where data lineage comes in—the ability to trace exactly where a piece of data came from, what happened to it along the way, and where it ended up. This creates the audit trails that regulators need to see. And once the data stops moving, you also need to ensure its secure disposal by understanding the principles of proper data sanitization.
In the end, creating a streaming architecture that’s both fast and secure comes down to proactive design. When you weave these security and compliance measures in from the very start, you build a system that’s not just powerful, but also worthy of trust.
Overcoming Common Implementation Hurdles
Adopting a strategy for data in motion is a fantastic move, but the road from a whiteboard concept to a production-ready system is often paved with operational headaches. While powerful open-source tools like Apache Kafka and Apache Flink give you the raw engine for real-time streaming, managing them yourself is a whole different ball game.
It’s a bit like being handed the keys to a high-performance race car but with no pit crew, no mechanic, and no one to tune the engine. The raw power is there, sure, but keeping it running at peak performance demands constant, specialized attention. This operational burden can quickly suck the life out of a project, pulling your best engineers away from building valuable products and into the frustrating weeds of infrastructure management.
The Hidden Costs Of Self-Management
When you decide to build and maintain your own streaming infrastructure, you’re not just signing up for an initial setup. It’s an ongoing, resource-draining commitment that many teams seriously underestimate.
Here are a few of the most common pain points we see time and again:
- The Hunt for Niche Expertise: Finding and keeping engineers who truly understand the deep complexities of Kafka and Flink is tough, and it’s expensive. These systems have notoriously steep learning curves, and a small gap in knowledge can lead to poorly configured clusters that are unstable, inefficient, and prone to failure.
- Constant Cluster Firefighting: You’re on the hook for everything. Provisioning servers, managing brokers, rebalancing partitions, and ensuring high availability becomes your team’s 24/7 reality. It’s a relentless cycle of monitoring, patching, and putting out fires.
- The Nightmare of Performance Tuning: Squeezing low latency out of a system at scale isn’t a “set it and forget it” task. It requires meticulous and continuous tuning, balancing throughput against resource use and processing delays. This job gets exponentially harder as your data volumes explode.
These operational hurdles create a significant drag on productivity. They slow down innovation and drive the total cost of ownership far beyond what you initially budgeted for hardware.
Navigating Schema Evolution And Scale
Beyond the day-to-day grind, two specific challenges consistently derail self-managed streaming projects: handling schema evolution and maintaining performance at scale. When the structure of your incoming data changes—what’s known as schema evolution—it can instantly break your pipelines, causing downtime or, worse, silent data loss.
At the same time, a pipeline that hums along nicely with a million events a day can completely fall apart when hit with a billion. For CTOs and IT leaders, this isn’t a hypothetical problem. Global data volume is projected to hit an incredible 50 zettabytes by 2025, with an estimated 30% of that being data in motion. Scaling your own infrastructure to keep up with that kind of growth while managing costs is a monumental task. You can learn more about the trends shaping data management in this insightful industry report.
The core problem with self-managed streaming is that it forces your best data engineers to become infrastructure experts. Their time is spent wrestling with servers and configurations instead of extracting value from the data itself.
The Zero-Ops Alternative
This is exactly the problem that managed, “zero-ops” platforms were created to solve. A solution like Streamkap is designed to abstract away the immense complexity of running Kafka and Flink. It lets you trade the heavy operational burden for speed, efficiency, and focus.
Instead of building the engine from scratch, you get to just drive the car. The table below really crystallizes the difference in approach.
Self-Managed vs Managed Streaming Platforms
Deciding whether to build your own streaming stack or use a managed service is a critical choice. This comparison breaks down the key differences in terms of effort, cost, and the expertise you’ll need on your team.
| Consideration | Self-Managed (Kafka & Flink) | Managed Solution (Streamkap) |
|---|---|---|
| Initial Setup | Weeks or months of complex configuration and cluster provisioning. | Minutes to set up connectors through a user-friendly interface. |
| Ongoing Maintenance | Requires a dedicated team for 24/7 monitoring, patching, and scaling. | Zero maintenance; all infrastructure management is handled by the platform. |
| Schema Evolution | Requires manual intervention and custom code to prevent pipeline failures. | Handled automatically, ensuring pipelines are resilient to data structure changes. |
| Expertise Required | Deep, specialized knowledge of Kafka, Flink, and distributed systems. | Basic knowledge of source and destination systems is sufficient. |
| Time-to-Value | Slow, as significant time is invested in infrastructure before value is realized. | Fast, allowing teams to build real-time pipelines and see results almost immediately. |
Ultimately, by opting for a managed solution, you empower your data teams to do what they do best: build innovative, data-driven applications. It lets them tap into the full power of data in motion without getting bogged down by the complex machinery that makes it all possible.
Got Questions About Data in Motion?
As you start digging into real-time data, a few common questions always seem to pop up. Let’s tackle them head-on to clear up any confusion and solidify your understanding of how modern data streaming really works.
What’s the Real Difference Between Data in Motion and ETL?
The biggest difference comes down to timing. Think of traditional ETL (Extract, Transform, Load) as a batch job—it gathers up big chunks of data and processes them on a schedule, maybe once a day or every hour. This approach inherently creates a lag between when something happens and when you can actually do something with that information.
Data in motion, on the other hand, is all about the “now.” It uses streaming tech to process data event-by-event, the moment it’s created. It’s a continuous flow, which means you can analyze and react to things instantly.
Is Apache Kafka My Only Option for This?
Not at all, though it’s definitely the big one. While Apache Kafka has become the go-to for building event streaming pipelines, you’ll also find great tools like Amazon Kinesis or Google Cloud Pub/Sub.
So, why does everyone talk about Kafka? Its massive ecosystem, proven ability to scale, and rock-solid reliability have made it the industry standard for a reason. This is why platforms like Streamkap build on top of Kafka’s power, giving you all the benefits without the massive operational headache of running it yourself.
Will Streaming Data Hammer My Source Database?
This is a fantastic question, and the answer is: it depends entirely on how you do it. The old-school way involved constantly polling the database with queries to ask, “Anything new? Anything new?” That approach is a performance killer and can bog down your most important applications.
The modern solution is log-based Change Data Capture (CDC). Instead of querying the database, CDC reads directly from the transaction log—the same log the database uses for its own recovery processes. This is an incredibly low-impact, asynchronous operation that has a near-zero effect on your source system’s performance.
This lets you capture every single change in real time without getting in the way of your production traffic.
So, Where Does Streamkap Fit In?
Think of Streamkap as the engine and the plumbing for your entire data in motion strategy. It’s a fully managed platform, built on the best of Kafka and Flink, that takes all the operational pain away.
Instead of your team spending months building and babysitting complex distributed systems, you just use Streamkap to:
- Spin up real-time CDC pipelines from databases like PostgreSQL, MySQL, and SQL Server in minutes.
- Stream those changes directly into destinations like Snowflake, Databricks, or BigQuery.
- Forget about schema changes. Streamkap handles them automatically, so your pipelines don’t break every time a developer adds a column.
- Transform data in-flight, so it lands in your warehouse perfectly structured and ready for analysis.
Essentially, Streamkap handles the complex infrastructure so your engineers can stop wrestling with servers and start delivering the insights your business needs.
Ready to put your data to work in real time, without the operational drag? Streamkap offers a fully managed, zero-ops platform to build high-performance streaming pipelines in minutes. Start your free trial today and see just how easy it is to set your data in motion.
Related resources
Kafka Connect for CDC: Distributed Mode, SMTs, and Production Configuration
A hands-on guide to deploying Kafka Connect for CDC workloads: standalone vs distributed mode, offset management, single-message transforms for routing, and connector task scaling.
Real-Time Decisioning: How Streaming Data Powers Instant Decisions
Real-time decisioning replaces batch-driven choices with instant, data-driven actions. Here's how streaming infrastructure makes it possible and why it matters for AI agents.
A Guide to the Modern Data Streaming Platform
Explore how a modern data streaming platform transforms business with real-time data. This guide covers core technologies, architecture, and use cases.