A Guide to Data Streaming Platforms and Real-Time Data
Discover how data streaming platforms transform business. This guide explains core concepts, architectures, and how to choose the right real-time solution.
Data streaming platforms are the backbone of a real-time business. They’re designed to continuously pull in, process, and send out endless streams of data from where it’s created to where it’s needed—all in the blink of an eye. Think of it less like a database that just stores information and more like the active, central nervous system of your entire operation.
Why Data Streaming Is the New Default
For decades, we treated data like a calm, still lake. Every so often, we'd send a team out in a boat to collect samples (this is batch processing), bring them back to shore, and analyze what they found. The whole process was slow, and by the time you got any answers, the lake's conditions had already changed. That reactive model was fine for a while, but it just can't keep up anymore.
Data streaming completely flips that model on its head. Instead of a lake, picture a constantly flowing river. These platforms don't just dip a bucket in every few hours; they are built right into the river's current, analyzing every drop of data as it rushes by. This is what allows a business to sense and respond to events the very instant they happen.
The core idea is moving from periodic, reactive analysis of data-at-rest to continuous, proactive action on data-in-motion. This shift is fundamental to staying competitive.
The Shift from Batch to Real Time
Moving away from traditional batch processing isn't just some minor technical upgrade; it's a critical business decision. The demand for immediate, actionable information has caused the real-time data streaming market to explode. Forecasts predict the live streaming market alone will hit around $345 billion by 2030. That kind of growth signals a massive, industry-wide shift toward wanting insights now, not tomorrow.
To really grasp the difference, here's a quick breakdown:
Batch Processing vs Stream Processing At a Glance
Making this transition from batch to real-time unlocks some serious advantages.
- Instantaneous Insights: Forget waiting hours or days for reports. Decision-makers get information in milliseconds, which is crucial for things like real-time fraud detection, dynamic pricing adjustments, and immediate customer support.
- Proactive Operations: You can spot and fix problems before they ever affect a customer. For instance, an e-commerce site can detect a sudden spike in cart abandonments and instantly trigger an automated "Can we help?" message or a discount offer.
- Enhanced Customer Experiences: Streaming data is what powers the personalization engines that adapt to user behavior on the fly. This creates far more relevant and engaging interactions. To go deeper on this topic, check out our guide on what streaming data is and how it works.
- Event-Driven Architectures: So many modern applications are built to react to events—a user click, a sensor reading, a financial transaction. Data streaming platforms are the essential plumbing that makes these responsive, event-driven systems actually work.
In short, data streaming platforms provide the infrastructure to turn your data from a historical archive into a live, actionable intelligence feed. This isn't just a luxury for massive tech companies anymore; it's becoming an essential tool for any organization that wants to be agile and precise.
Understanding the Building Blocks of Data Streaming
To really get a feel for what data streaming platforms do, it helps to peek under the hood. At its core, you can think of a data streaming platform as a super-efficient, automated nervous system for your business's data. It takes in signals (data events) from all over, processes them instantly, and routes them to the right places so you can act on them right now.
The magic that makes this happen is called stream processing. This is what lets the platform analyze and transform data the very second it's created, instead of waiting for it to land in a database for batch analysis later. Forget looking at yesterday's sales report; you're analyzing each sale as it rings up.
This is all about connecting business events directly to insights and actions in a continuous, real-time loop.
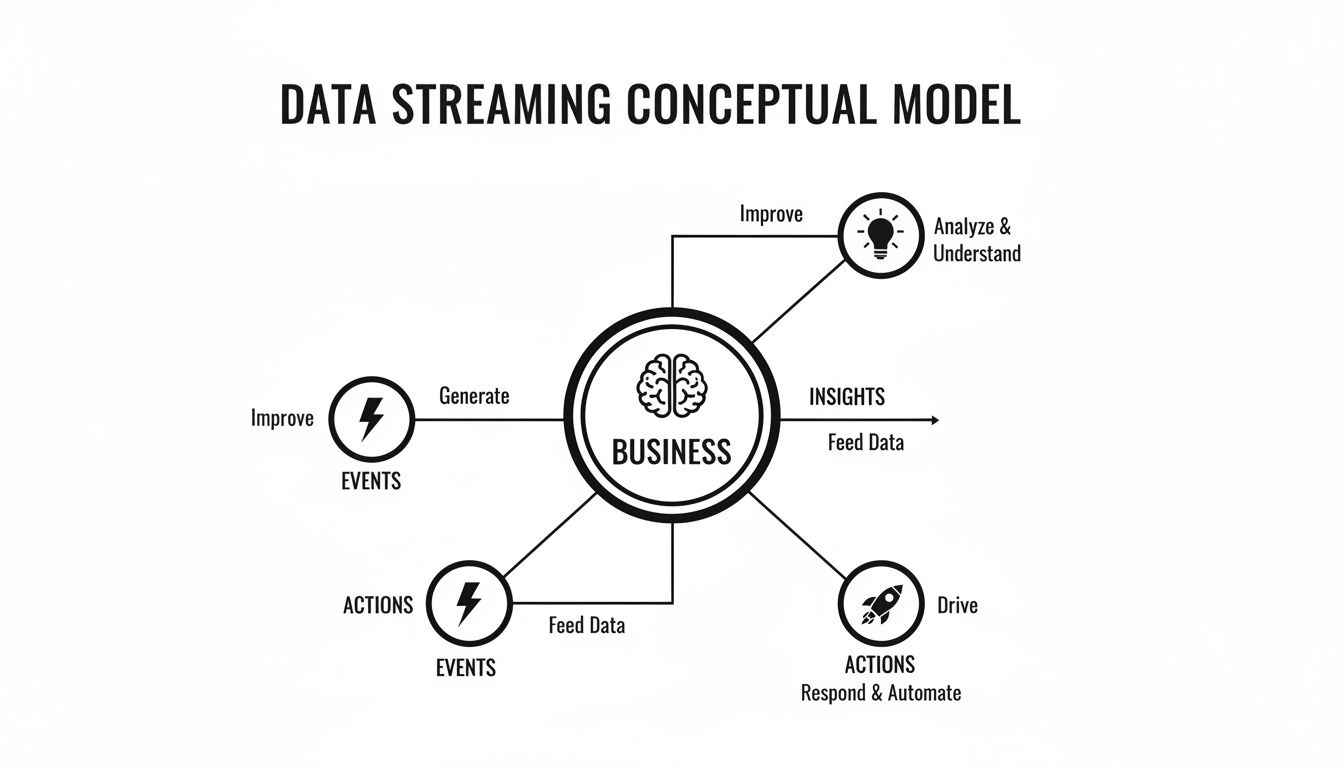
As you can see, raw events are constantly being refined into valuable insights, which in turn trigger intelligent business actions.
The Immutable Event Log
The heart of almost every data streaming platform is the event log, sometimes called a message queue. Picture it as the system's permanent, unchangeable diary. Every single event—a button click, a sensor reading, a financial transaction—gets written down in the order it happened. And once it's written, it can't be altered.
This simple concept is incredibly powerful. It makes your data durable. If a downstream application crashes, it can just restart and pick up reading the diary from where it left off. No data is ever lost. Apache Kafka is the undisputed king here, acting as the central transport layer for countless real-time systems by reliably handling massive volumes of events.
The event log provides a fault-tolerant, replayable history of all data. This is the bedrock of reliable streaming architectures, ensuring data integrity even when individual components fail.
Stream Processing Engines
If the event log is the diary, the stream processing engine is the brain that reads it in real time and figures out what it all means. These engines grab events from the log, run all sorts of computations on them, and then push the results out to other systems. This is where the actual "thinking" happens.
Here are a few things these engines do constantly:
- Filtering: Sifting through the noise to find what matters. Think of it as ignoring routine server pings to focus only on critical error messages.
- Enrichment: Adding context to make an event more useful. For instance, taking a user ID from a click event and joining it with detailed customer profile info from another database.
- Aggregation: Crunching numbers over time. This could be counting website clicks per minute or calculating the moving average of a stock's price.
Tools like Apache Flink and Kafka Streams are popular choices, giving developers the power to turn raw event streams into genuinely actionable intelligence.
Sources and Sinks: The On-Ramps and Off-Ramps
A streaming platform can't just exist in a vacuum. It has to connect to everything else in your tech stack. That’s where connectors come in—they are the on-ramps and off-ramps for your data highway.
Source connectors are the on-ramps. They pull data into the streaming platform from your various systems. A classic example is a source that captures every single change made in a production database. This technique, known as Change Data Capture (CDC), is a game-changer for streaming database updates without hurting the database's performance. For a deeper look, check out our guide on what Change Data Capture is and how it powers modern data pipelines.
Sink connectors are the off-ramps. They deliver the processed, valuable data out of the platform to where it needs to go. That final destination could be a real-time analytics dashboard, a data warehouse like Snowflake, or another application that needs to react to the new information. Together, sources and sinks create a seamless, end-to-end flow that turns raw data into real business outcomes with virtually no delay.
A Look at Common Data Streaming Architectures
Working with real-time data means you have some big strategic choices to make. Once you've got a handle on the core components, the next step is figuring out the blueprint for your system. The architecture you land on will define everything—from scalability and cost to the daily operational lift for your team.
It's a lot like building a house. Do you buy a prefabricated kit with step-by-step instructions, or do you source the raw lumber and build a custom home from the ground up? That’s the core question you need to answer when you start thinking about your data streaming setup.

Managed vs. Self-Hosted Platforms
The first major fork in the road is the choice between a managed platform and a self-hosted solution. Each path comes with its own unique trade-offs in control, convenience, and cost.
A self-hosted architecture is the classic do-it-yourself (DIY) route. You take powerful open-source tools like Apache Kafka and Apache Flink and deploy them on your own infrastructure, whether that’s in the cloud or on-premise. This approach gives you absolute control and lets you customize every last detail.
But that freedom comes with a hefty price tag. Your team is suddenly on the hook for everything. This creates a massive operational burden that includes:
- Provisioning and configuration: Setting up every server, network, and piece of software just right.
- Scaling: Manually adding or removing resources as data loads spike and dip.
- Maintenance and patching: Constantly applying software updates to fix bugs and patch security holes.
- Monitoring and troubleshooting: Keeping a 24/7 watch on the system and jumping on any issues the moment they pop up.
If you go the on-premise route, you also have to get smart about your physical infrastructure. Understanding the different types of data center services becomes a critical piece of the puzzle.
On the other hand, a managed platform is like bringing in an expert general contractor. A provider like Streamkap takes care of all the mind-numbing infrastructure complexity of Kafka and Flink for you. This frees your team to focus on what they do best: building data pipelines that deliver real business value, not managing the plumbing.
While self-hosting seems to offer ultimate control, the total cost of ownership (TCO) is often shockingly high. All that engineering time spent on operations is time not spent on innovation. Managed platforms abstract this complexity away, which can dramatically speed up your time-to-market.
The Rise of Event-Driven Architectures
Beyond just the hosting model, another crucial idea to grasp is event-driven architecture (EDA). This isn't a specific technology but a design philosophy that modern data streaming platforms make possible.
Imagine a busy restaurant kitchen. In a traditional, clunky system, a manager would have to take an order, walk it to the grill, wait for the food, and then carry the plate to the finishing station. It’s slow and full of bottlenecks.
An event-driven kitchen is different. An order (an event) gets pinned to a central board. The grill cook sees it and gets to work independently. Once the steak is done, they place it on the pass (another event). The plating chef sees that new event and preps the final dish. Each station just reacts to events as they happen, all working in parallel without a central manager holding things up.
That's precisely how an EDA works in software. Different parts of your business system (we call them services) communicate by producing and consuming events.
- An
OrderPlacedevent is published. - The Inventory service sees this event and immediately decrements stock.
- The Shipping service sees it and starts preparing a label.
- The Notifications service sees it and sends the customer an email confirmation.
Each service is decoupled, which means you can update one or have one fail without crashing the whole system. This design makes your architecture incredibly resilient, scalable, and agile. Data streaming platforms are the nervous system that reliably carries these event messages between all your services.
These patterns have matured significantly over the years, leading to simpler, more powerful designs. You can see this progression clearly by reading about the evolution from Lambda to Kappa architecture, which shows how the industry has moved toward unified, real-time data processing.
Seeing Data Streaming in Action with Real-World Examples
It’s one thing to talk about data streaming in theory, but where it really clicks is seeing how it solves actual problems in the real world. These platforms aren't just abstract tools for engineers; they're the engines driving real business outcomes across all kinds of industries. From personalizing your shopping cart to protecting your bank account, streaming data is quietly working behind the scenes.
Let's dive into a few stories of how this technology is reshaping entire sectors by turning raw data into immediate, intelligent action. These examples show how companies are tackling tough challenges and uncovering new opportunities, all by adopting a real-time mindset.
Revolutionizing Retail with Real-Time Personalization
Picture a massive e-commerce company in the middle of a huge holiday sale. In the past, they ran nightly batch jobs to update inventory. The problem? They'd often oversell popular items, leaving customers frustrated with out-of-stock notices long after they thought they'd secured a purchase.
The Challenge: Slow inventory updates created terrible customer experiences and cost them sales. Their recommendation engine was always a day late, suggesting products based on what a user did yesterday, not ten seconds ago.
The Streaming Solution: They brought in a data streaming platform to treat every click, cart addition, and purchase as a distinct event. This live stream feeds directly into their inventory system and their personalization engine.
Now, the moment a product's stock drops to a critical level, the "buy" button can vanish instantly, or the system can suggest a similar item that's actually available. The personalization engine uses in-session behavior to offer relevant upsells right at checkout, giving their average order value a serious boost.
Securing Finance with Millisecond Fraud Detection
Financial institutions are locked in a constant arms race against fraud. Old-school systems reviewed transactions in batches, which meant they might catch a fraudulent charge hours—or even days—after the money was gone. This reactive approach was not only expensive but also chipped away at customer trust.
By the time a batch-based fraud alert was triggered, the damage was done. Real-time stream processing shifts the paradigm from damage control to active prevention, identifying and blocking threats before they can execute.
A major bank integrated a streaming platform to analyze a constant flow of transaction data as it happens. The system looks at the amount, location, merchant, and time of each transaction, then cross-references it with the customer’s typical behavior patterns, all in milliseconds.
If a card is used in a new country just minutes after being used at a local grocery store, the system flags it as suspicious on the spot. An automated process can then block the transaction and fire off an immediate alert to the customer's phone, all before the fraudulent purchase is even approved. This approach dramatically cuts fraud losses and gives customers a sense of security they can actually feel.
Optimizing Manufacturing with IoT Data Streams
Modern factories are buzzing with thousands of sensors on assembly lines, robotic arms, and environmental controls. Every sensor produces a non-stop stream of data—temperature, vibration, pressure, you name it. Letting that data sit in a database until the end of the day is a huge missed opportunity.
An automotive manufacturer, for instance, uses a data streaming platform to pull in and analyze this IoT data in real time. By monitoring the vibration patterns of a specific machine, their system can detect tiny anomalies that signal a component is about to fail. This is the heart of predictive maintenance.
Instead of waiting for an unexpected breakdown that brings the entire production line to a halt for hours, they can schedule maintenance during planned downtime. This simple shift saves them millions in lost productivity every year. Many innovative solutions, such as those found in AI in business automation, critically depend on data streaming platforms to process and react to real-time data for intelligent decision-making.
Picking the Right Data Streaming Platform
Choosing a data streaming platform isn't just another IT decision. It’s a foundational choice that will dictate how your company uses real-time data for years to come. It's tempting to just grab the cheapest option or the one with the longest feature list, but that path often ends in regret. A smart decision balances raw performance, the true long-term cost, and what it actually means for your engineering team day-to-day.
To make the right call, you have to look past the marketing gloss and focus on the things that will genuinely make or break your project. Let's walk through a framework that helps you evaluate platforms systematically, ensuring you pick one that works for you now and can scale with you later.
Latency and Throughput
The first two hurdles any platform has to clear are latency and throughput. Think of latency as the time it takes for a single event to get from point A to point B. For something like real-time fraud detection, you need that delay to be in the low milliseconds. Any slower, and the opportunity is lost.
Throughput, on the other hand, is all about volume—how much data the system can process over time. You'll see it measured in megabytes per second or millions of events per day. Your platform absolutely must be able to handle your peak traffic, whether that's a Black Friday sales rush or a viral marketing campaign, without breaking a sweat. When you’re evaluating options, don't just take the advertised numbers at face value. Ask for proof of performance under conditions that look a lot like your own.
Total Cost of Ownership
The price tag you see on the website is just the tip of the iceberg. To understand the real financial impact, you need to calculate the Total Cost of Ownership (TCO). This gives you a much clearer picture by factoring in all the hidden and ongoing expenses.
- Infrastructure Costs: This is the obvious one—the servers, storage, and networking hardware, whether it's in the cloud or on-premise.
- Operational Staffing: Self-hosting a platform like Apache Kafka means you need dedicated engineers to maintain, scale, and troubleshoot it. These are highly skilled (and expensive) specialists whose time could be spent building things that actually make the company money.
- Development and Integration: Don't forget to account for the hours your team will spend building and maintaining custom connectors, wrestling with schemas, and writing glue code.
- Downtime Costs: What's the business impact if your streaming pipeline is down for an hour? A more reliable managed platform might have a higher subscription fee, but its TCO can be dramatically lower once you factor in the staggering cost of outages.
A managed platform often comes out way ahead on TCO. By taking the operational nightmare of running Kafka and Flink off your plate, services like Streamkap can cut engineering overhead by up to 80%. This frees up your team to focus on building valuable data products, not just keeping the lights on.
Operational Burden
The day-to-day operational burden is easily the most underestimated cost of running a streaming platform. When you go the self-hosted route, the responsibility for uptime, security, patches, and performance tuning lands squarely on your team. This isn't just about workload; it's about having a very specific, hard-to-find skill set.
Managing a complex distributed system like Kafka is notoriously difficult. You need deep expertise to tune it for performance, handle failures gracefully, and scale it without causing a system-wide meltdown. A managed service absorbs all that complexity for you. It provides a stable, reliable platform without you needing to hire a team of dedicated Kafka experts, which massively lowers the barrier to getting started with real-time data.
Integrations and Ecosystem
A data streaming platform is completely useless on its own. Its real value is in how well it connects to the other tools in your data stack. Before you sign any contracts, make sure the platform has pre-built, production-grade connectors for all your critical sources and destinations.
At a minimum, look for solid support for:
- Databases: Connectors for databases like PostgreSQL, MySQL, and MongoDB are fundamental for capturing database changes with CDC.
- Data Warehouses: You need seamless, reliable integration with analytical destinations like Snowflake, BigQuery, and Databricks. This is non-negotiable.
- Other SaaS Tools: The ability to stream data to and from other applications is what extends the platform's value across the entire business.
A platform with a rich, well-maintained ecosystem of connectors will save you hundreds of hours of painful custom development work, letting you get value from your data much, much faster.
Schema Management
Your data is always changing. A new column gets added to a database table, a field is removed from an API response—it’s inevitable. Without a solid plan for schema management, these small changes will constantly break your data pipelines, causing data loss and frustrating downtime.
A modern, mature platform handles these changes automatically. It should be able to detect "schema drift" at the source and propagate those changes through the entire pipeline without anyone having to lift a finger. This capability, often called schema evolution, is a hallmark of an enterprise-ready platform and is absolutely critical for maintaining the health and reliability of your pipelines over the long run.
Choosing the right platform involves a careful look at your specific needs. The checklist below can help you structure your evaluation and compare different options on the factors that truly matter.
Evaluation Checklist for Data Streaming Platforms
By thoughtfully working through these criteria, you can move beyond a simple feature comparison and make a strategic decision that aligns with both your technical requirements and your business goals.
Frequently Asked Questions About Data Streaming
If you're digging into the world of data streaming platforms, you've probably got questions. That's completely normal. This stuff represents a major shift from the old ways of handling data, and it's smart to get the fundamentals down first. Let's walk through some of the most common questions to clear things up.
Think of this as a quick-start guide to the core concepts, helping you understand the tech and the practical decisions you'll need to make.
What Is the Difference Between Streaming and ETL?
This is easily the most common point of confusion, so let's clear it up right away. Traditional ETL (Extract, Transform, Load) is all about batch processing. It works by grabbing a huge chunk of data from a source, transforming it all in one go on a staging server, and then loading that finished batch into its final destination, like a data warehouse. This whole process usually runs on a fixed schedule—maybe once a night or every few hours.
Data streaming, especially when you pair it with Change Data Capture (CDC), flips that model on its head. Instead of waiting for a scheduled run, streaming captures and processes every single event or data change the very moment it happens.
It's like this: ETL is getting the newspaper delivered to your doorstep once in the morning, filled with all of yesterday's news. Data streaming is a live, scrolling news feed on your phone, updating you the second a story breaks.
This simple difference is massive. Streaming delivers information with latency measured in milliseconds, while ETL's latency is stuck in hours or even days.
What Role Does Apache Kafka Play in All This?
You're going to hear the name Apache Kafka a lot, and for good reason. It has become the gold standard for the "message bus" or event log that sits at the heart of nearly every modern data streaming platform. At its core, Kafka is a highly durable and incredibly scalable central nervous system for all your event data.
The best way to think of Kafka is as the postal service for your data. Your applications and databases (the "producers") send letters (data events) to the Kafka post office. Kafka then sorts these letters into different mailbags (called "topics") and holds onto them securely. Your analytics tools and other applications (the "consumers") can then subscribe to specific mailbags and get a continuous stream of letters as soon as they arrive.
In a streaming architecture, its main jobs are:
- Decoupling Systems: It lets the systems creating data and the systems using it work completely independently, without needing fragile direct connections.
- Durability: Kafka reliably stores events, so even if a consumer application goes offline for a while, no data is ever lost. It’ll be there when the app comes back online.
- High Throughput: It was built from the ground up to handle a colossal volume of events, making it the right tool for even the most demanding, high-traffic businesses.
But here's the catch: while Kafka is incredibly powerful, it's also notoriously difficult to manage yourself. That complexity is the single biggest reason why managed services have become the go-to choice for most companies.
Should I Build My Own Platform or Use a Managed Service?
Ah, the classic "build vs. buy" debate. This is a huge strategic decision. Building your own platform from open-source parts like Apache Kafka and Apache Flink gives you total control and endless customization options. But—and it's a big but—this path demands a dedicated team of highly specialized (and very expensive) engineers just to handle the setup, maintenance, scaling, security, and 24/7 monitoring. The operational burden is immense.
A managed service takes all that infrastructure complexity off your plate. The provider does the hard, tedious work of keeping the platform running, which frees up your team to focus on what actually matters: building data pipelines that deliver value to the business.
Here’s what to weigh when making your choice:
- Team Expertise: Do you already have engineers on staff with deep, battle-tested knowledge of distributed systems like Kafka and Flink?
- Time to Market: How fast do you need to get your real-time pipelines up and running? A managed service can shrink your development timeline from months down to days.
- Total Cost of Ownership (TCO): When you add up engineering salaries, cloud infrastructure costs, and the opportunity cost of having your best people managing plumbing instead of building products, a self-hosted solution is almost always far more expensive than a managed subscription.
For the vast majority of companies, a managed platform is simply the faster, more reliable, and more cost-effective way to get real-time data flowing.
What Are the First Steps to Migrate from Batch to Streaming?
Moving from batch jobs to a real-time world can feel like a massive project, but you don't have to boil the ocean. The smartest way to start is by picking one, high-impact use case. Find a business process that's currently being hurt by data delays—think inventory management, fraud detection, or personalizing the customer experience.
Once you have your target, the first practical step is usually setting up CDC on a key operational database. This lets you start streaming changes out of that database and into your new platform without touching or disrupting the existing application. This first pipeline becomes the perfect proof-of-concept. It lets you show the value of real-time data quickly, build momentum, and get buy-in for expanding streaming across the rest of the organization.
Ready to replace your slow batch ETL jobs with efficient, real-time data streaming? Streamkap provides a fully managed platform that leverages Kafka and Flink without the operational headache. Start building powerful data pipelines in minutes and see how you can cut costs and complexity. Explore our solution.