ETL Tools Comparison Choosing Your Modern Data Integration Solution
Explore our in-depth ETL tools comparison to choose the right solution. We analyze batch, ELT, and real-time CDC for modern data stacks and complex use cases.
Picking the right way to move your data around isn’t just a technical detail; it’s a strategic choice. A proper ETL tools comparison boils down to weighing old-school batch processing against the newer, faster world of ELT and real-time streaming. The core difference? Latency. Legacy ETL tools work on a schedule—think hours or even days—while modern ELT and Change Data Capture (CDC) give you data almost as it happens. The right choice really depends on a simple question: can your business afford to wait for answers, or do you need them now?
Why Your Data Integration Strategy Needs a Modern Approach
The era of waiting for nightly data dumps is long gone. Today, having immediate access to fresh, reliable data is a massive competitive edge. This hunger for low-latency analytics is pushing companies to ditch traditional, scheduled ETL and embrace more responsive ways of integrating data.
You can see this shift playing out in the market’s explosive growth. The global ETL tools market is expected to jump from USD 8.85 billion in 2025 to USD 18.60 billion by 2030. That’s a compound annual growth rate of 16.01%, which tells you just how much companies are leaning on better data integration to handle their increasingly complex data environments. For a deeper dive into these trends, check out this data integration market report.
The Limits of Legacy Batch ETL
Traditional batch ETL was built for a simpler time, a world with fewer data sources and a lot less urgency. In that model, you extract data, transform it on a staging server, and then finally load it into the data warehouse. It works just fine for historical reporting, but it also creates serious delays and operational headaches. If you want a refresher on the basics, our guide on what is an ETL pipeline is a great place to start.
The Rise of ELT and Real-Time CDC
Modern data stacks solve these problems by flipping the process on its head (ELT) or creating a direct, real-time connection (CDC).
- ELT (Extract, Load, Transform): This approach takes full advantage of powerful cloud data warehouses like Snowflake or BigQuery. You load raw data directly into the warehouse and do all the transformations there. It’s a much simpler pipeline that gives analysts faster access to the raw data they need.
- Streaming CDC (Change Data Capture): When you absolutely, positively need data in real time, CDC is the way to go. It captures individual changes from source databases the moment they happen and streams them to their destination in milliseconds.
Shifting from batch processing to real-time streaming unlocks a whole new world of possibilities. Think fraud detection, dynamic pricing, and live inventory management—scenarios where stale data isn’t just unhelpful, it’s a liability. This guide will walk you through a detailed ETL tools comparison to help you choose the right architecture for what you’re trying to build.
How to Actually Compare ETL Tools: The Core Criteria
Picking the right ETL tool without a clear game plan is a recipe for a bad decision. To get past the marketing fluff and find what truly works for your team, you need a solid framework for comparison. This isn’t about finding the “best” tool, but the best tool for your specific problems.
Let’s break down the essential criteria you should be using to evaluate your options.
Architecture and Data Latency
The most fundamental difference between tools comes down to their architecture, which directly dictates how fast you get your data. This is the first fork in the road for any tool comparison.
- Batch ETL/ELT: These are the traditional workhorses. They move data in large chunks on a fixed schedule—maybe once an hour or once a day. This approach works perfectly fine for things like end-of-day sales reporting but falls flat when you need data now.
- Streaming CDC: In stark contrast, streaming Change Data Capture (CDC) tools watch for changes at the source and send them over, one event at a time, almost instantly. We’re talking sub-second latency here, which is non-negotiable for real-time use cases.
Your business’s tolerance for data delay will immediately filter your list. If you’re building a fraud detection system or a live inventory dashboard, batch tools are out of the running from the start.
Scalability and Schema Handling
Your data isn’t going to shrink. The tool you choose today has to handle tomorrow’s volume without falling over or forcing a painful migration. True scalability isn’t just about processing more data; it’s about doing it without your costs spiraling out of control. Modern, cloud-native platforms are often built for this, letting you scale horizontally as needed.
Just as critical is how a tool reacts when your data’s structure changes. What happens when a developer adds a new column to a production database? Brittle, old-school ETL pipelines will simply break, sending a pager alert and ruining a data engineer’s weekend.
The ability to handle schema evolution automatically is a massive differentiator. Modern tools can detect these changes and propagate them downstream without any manual work. This makes your pipelines far more resilient and frees up your engineers from constant, low-value maintenance tasks.
This single feature can dramatically cut down on operational headaches and fragile pipelines.
Connectors and Day-to-Day Complexity
A tool is only as good as its connections. You need to know it can talk to everything in your stack, from your ancient Postgres databases and a dozen SaaS apps to your shiny new data warehouse. The breadth and reliability of these connectors are paramount.
But connectivity is only half the story. Think about the operational overhead. A powerful tool that requires a team of specialists just to keep the lights on isn’t a win. The Total Cost of Ownership (TCO) will kill you. Look for platforms that prioritize ease of use with good UIs, smart monitoring, and logging that makes sense.
Speaking of TCO, it’s way more than just the monthly bill. A real cost analysis includes:
- Subscription Fees: The obvious price tag.
- Infrastructure Costs: The compute and storage you’re paying for to run the thing.
- People Costs: The salary hours spent building, monitoring, and fixing pipelines.
- Opportunity Cost: What’s the business impact of data being late or pipelines being down?
Setting these criteria before you even look at a demo will give you a clear, practical lens to conduct your ETL tools comparison. It grounds your decision in what your business and your tech stack actually need.
When you’re comparing data integration tools, you’re really comparing philosophies. It’s not just about a list of features; it’s about the fundamental architecture and how each approach gets data from point A to point B. Let’s break down the three big models: traditional batch ETL, modern cloud ELT, and real-time streaming CDC, focusing on the criteria that actually matter to data teams on the ground.
This screenshot from our homepage really gets to the heart of it. It’s a simple visual that shows the core promise of streaming CDC—speed and a continuous, real-time flow of data. You can immediately see how this architecture smashes the latency bottlenecks that are just part of the deal with older, batch-based systems.
Data Latency: The Make-or-Break Difference
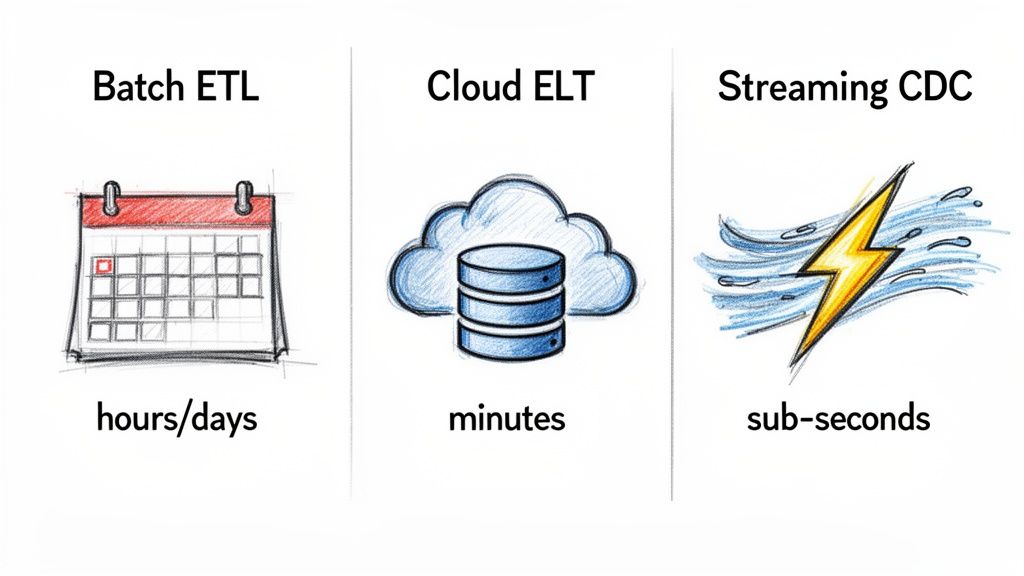
If there’s one factor that separates these approaches, it’s data latency. This is the time it takes for a piece of data to travel from its source to its final destination, and it often single-handedly decides which tool is even an option for your use case.
-
Traditional Batch ETL (think Informatica, SSIS): These are the old workhorses. They run on a fixed schedule, gathering data in massive chunks, processing it, and delivering it once a day or maybe once an hour. This is fine for historical reporting, like end-of-month financials, where nobody needs the numbers right now. Latency here is measured in hours or days.
-
Modern Cloud ELT (think Fivetran, Stitch): Cloud-native ELT tools made a huge leap forward by cutting down this wait time. They extract and load data much more frequently, often on schedules as short as every five or fifteen minutes. This makes them great for feeding business intelligence dashboards and analytics where timeliness matters. Latency is measured in minutes.
-
Streaming CDC (think Streamkap, Debezium): This is a completely different ballgame. Instead of scheduled pulls, streaming platforms capture database changes the instant they happen and stream them to their destination. This gets you sub-second latency, making it the only viable choice for truly real-time applications like fraud detection, live inventory systems, or dynamic pricing.
The choice between batch and streaming is a business decision disguised as a technical one. If your operations depend on reacting to events as they happen, batch processing introduces unacceptable risk. Streaming isn’t just faster; it enables entirely new business capabilities.
To get deeper into the nuts and bolts, check out our guide on batch processing vs stream processing. It breaks down how these architectural choices impact everything downstream.
Scalability and Architectural Flexibility
As your data grows—and it always does—how your tools scale becomes critical. The architecture of each approach directly dictates how it handles a heavier load.
Legacy batch ETL systems were born in the on-prem data center era and tend to rely on vertical scaling. That means you have to keep adding more CPU, RAM, or storage to a single, massive server. Not only is this expensive, but you eventually hit a wall. You can’t just make a server infinitely bigger.
In sharp contrast, modern cloud ELT and streaming CDC platforms are built for horizontal scaling. They distribute the work across many smaller, interchangeable machines. This cloud-native model is elastic, meaning you can handle huge data spikes by just adding more nodes to the cluster. It offers practically limitless scalability and is far more cost-effective.
This fundamental shift is why cloud-based data integration solutions now dominate 65% of the total market share and are growing at a rapid 15.22% CAGR. Enterprises are voting with their budgets for scalability and flexibility.
Schema Handling: Resilience vs. Fragility
Schema changes are a fact of life. A developer adds a new column or changes a data type in a source database, and your data pipeline needs to react. How it reacts determines if your system is resilient or just plain brittle.
-
Batch ETL: Traditional tools demand rigid, predefined schemas. An unexpected change at the source will almost always cause the ETL job to fail flat out. A data engineer then has to get paged, go in manually, update the pipeline mappings, and rerun the whole job. This leads to long data delays and a lot of frustration.
-
Cloud ELT: A huge selling point for many modern ELT tools is automated schema handling. They detect source changes and can automatically replicate them in the destination warehouse. This concept, often called schema evolution, makes pipelines far more robust and lifts a huge maintenance burden off the data team.
-
Streaming CDC: The best streaming platforms go one step further. They don’t just propagate schema changes automatically in real time; they also manage the tricky business of ensuring data consistency and perfect event ordering during the transition. This is an absolute must-have for event-driven architectures where the order of operations is critical.
Operational Complexity and Total Cost of Ownership
The sticker price is just the beginning. The total cost of ownership (TCO) has to include the infrastructure you need to run the tool and—most importantly—the engineering hours spent building, maintaining, and troubleshooting your pipelines.
To make this clearer, here’s a high-level look at how the three architectures stack up.
Comparing Data Integration Architectures
| Feature | Traditional Batch ETL | Cloud ELT | Streaming CDC |
|---|---|---|---|
| Primary Use Case | Nightly reporting, data archiving | Business intelligence, analytics | Real-time applications, operational analytics |
| Latency | Hours to Days | Minutes | Sub-seconds |
| Scalability Model | Vertical (Expensive, limited) | Horizontal (Elastic, cost-effective) | Horizontal (Highly elastic, built for scale) |
| Schema Handling | Manual, brittle pipelines | Automated, resilient | Automated, real-time, and consistent |
| Operational Overhead | High (Requires dedicated teams) | Low (Managed service, minimal maintenance) | Very Low (Fully managed platforms like Streamkap) |
| Typical Cost Driver | Licensing, server hardware, engineering hours | Data volume, connector usage | Data volume, processing units |
As you can see, traditional on-prem ETL requires a massive upfront investment in hardware and the ongoing cost of specialized teams to run it. And while open-source streaming tools like Kafka and Flink are incredibly powerful, managing them yourself is a full-time job that introduces immense operational complexity.
Cloud ELT tools abstract a lot of that away, offering a great low-maintenance solution for analytics. But for real-time needs, fully managed streaming CDC platforms like Streamkap offer the lowest TCO. By handling the entire underlying infrastructure—the Kafka, Flink, and connectors—we let your team focus on building valuable data products, not managing complex distributed systems.
Matching the Right Tool to Your Real-World Use Case
Understanding the technical specs of data tools is one thing, but connecting those features to actual business problems is where the real work begins. The core challenge is simple: pick the right tool for the job. Your choice of data integration architecture really boils down to what you’re trying to accomplish, whether it’s running a simple daily report or powering a complex, real-time application.
Not every problem needs sub-second data. The trick is to align the tool’s power with the urgency and complexity of your use case. Let’s walk through some practical scenarios to see where each approach really shines.
When Traditional Batch ETL Is a Perfect Fit
Despite all the hype around real-time data, traditional batch ETL tools still have a solid place in the data stack. Think of them as the reliable workhorses for jobs where data freshness takes a backseat to consistency and cost-effectiveness.
Take a large retailer’s finance department, for example. They need to pull together comprehensive end-of-month sales reports for stakeholders. This means consolidating data from all over the business—point-of-sale terminals, ERPs, and supply chain logs.
- The Business Challenge: The goal isn’t instant insight. It’s about getting a complete, perfectly accurate picture of the last month’s performance. The data only needs to be processed once, right after the month closes.
- The Integration Approach: A classic batch ETL process is perfect here. You schedule it to run on the first of the month, and it extracts all the necessary data, applies complex transformations to standardize everything, and loads a clean, aggregated dataset into the warehouse.
- The Outcome: The finance team gets exactly what it needs: a high-integrity dataset for historical analysis without the cost or operational headache of a real-time system. Anything faster would simply be overkill.
Empowering Analysts with Cloud ELT Solutions
Things change when you bring business analysts and data scientists into the mix. Their work is often exploratory. They need access to raw, granular data to build dashboards, test out hypotheses, and dig for insights. This is where modern cloud ELT platforms like Fivetran and Airbyte truly excel.
Imagine a marketing analytics team trying to understand customer behavior. They need to blend data from Salesforce, Google Analytics, and a handful of ad platforms to map out the entire customer journey.
The real need here isn’t millisecond latency; it’s giving analysts the freedom to work directly with raw data. By loading data first and handling transformations inside the data warehouse, ELT lets teams ask new questions on the fly without waiting for engineers to tweak the pipeline.
This approach dramatically speeds up the whole analytics cycle. Analysts can build their own data models with tools like dbt right on top of the raw data, creating a much more agile, self-service environment. The pipeline might run every 15 minutes, which is more than fresh enough for the BI dashboards in Tableau or Looker that guide tactical decisions.
Where Streaming CDC Becomes Non-Negotiable
For a growing number of critical business functions, waiting minutes for data just doesn’t cut it anymore. These are the situations that demand an immediate response to events as they happen, making streaming Change Data Capture (CDC) the only game in town. This is why a solid understanding of the available change data capture tools has become so critical for modern data teams.
Here are a few use cases where streaming is simply indispensable:
- Real-Time Inventory Management: An e-commerce site has to stop overselling hot items during a flash sale. A streaming CDC pipeline can capture every
INSERTorUPDATEin the sales database and instantly reflect that change in the inventory system, preventing stockouts and unhappy customers. - Live Fraud Detection: A fintech company needs to spot and block fraudulent transactions before they clear. By streaming transaction data into a machine learning model, the system can score each transaction for risk in milliseconds and shut down suspicious activity on the spot.
- Event-Driven Microservices: A logistics company relies on a microservices architecture to track shipments. When a row in the
packagesdatabase table is updated to “in transit,” CDC captures that change and publishes it as an event to a Kafka topic. Downstream services, like the customer notification app, can then react to that event instantly.
This move toward real-time isn’t just for huge corporations. Small and medium enterprises (SMEs) are actually the fastest-growing segment in the ETL tools market, with an impressive 18.7% CAGR. This boom is driven by a new wave of accessible, no-code platforms that have made advanced data integration possible for everyone. By picking the right tool for their specific needs, even smaller companies can now build incredibly powerful, responsive data systems.
Choosing the Right Tool for Your Data Stack
Picking the right tool from a sea of ETL, ELT, and CDC options is less about a feature-for-feature bake-off and more about matching the technology to where your business is headed. Ask the right questions upfront, and you can cut through the noise and find a solution that works for you today and scales for tomorrow.
The first and most important question to ask revolves around time. How fresh does your data really need to be? The answer to that question alone will set you on the right architectural path.
Key Questions to Guide Your Choice
Before you even think about booking demos, get your team in a room and hash out the answers to these questions. Honesty here will save you a world of pain later.
-
What’s our tolerance for data latency? If your business runs on nightly reports, a classic batch tool will do the job just fine. But if you’re building a customer-facing dashboard, a fraud detection model, or a real-time inventory system, you need data that’s seconds old, not hours. That immediately points you toward streaming CDC.
-
What’s our team’s real-world engineering capacity? Be brutally honest about this. An open-source framework offers incredible flexibility, but it comes with a heavy operational tax. A fully managed service has a sticker price, but it can slash your Total Cost of Ownership (TCO) by offloading all the infrastructure headaches to a vendor.
-
Where is our data strategy headed in 3-5 years? The tool you pick today needs to handle the projects you haven’t even scoped yet. If real-time analytics or event-driven microservices are on the roadmap, adopting a streaming platform now saves you from a costly and disruptive migration in a couple of years.
I see a lot of teams make the same mistake: they choose a tool that perfectly solves today’s simple problem, only to find it hits a wall when faced with next year’s complex demands. Think of this as a long-term investment in your data infrastructure, not just a quick fix for a single project.
This decision tree gives you a visual for how different business needs map to the right data integration approach.
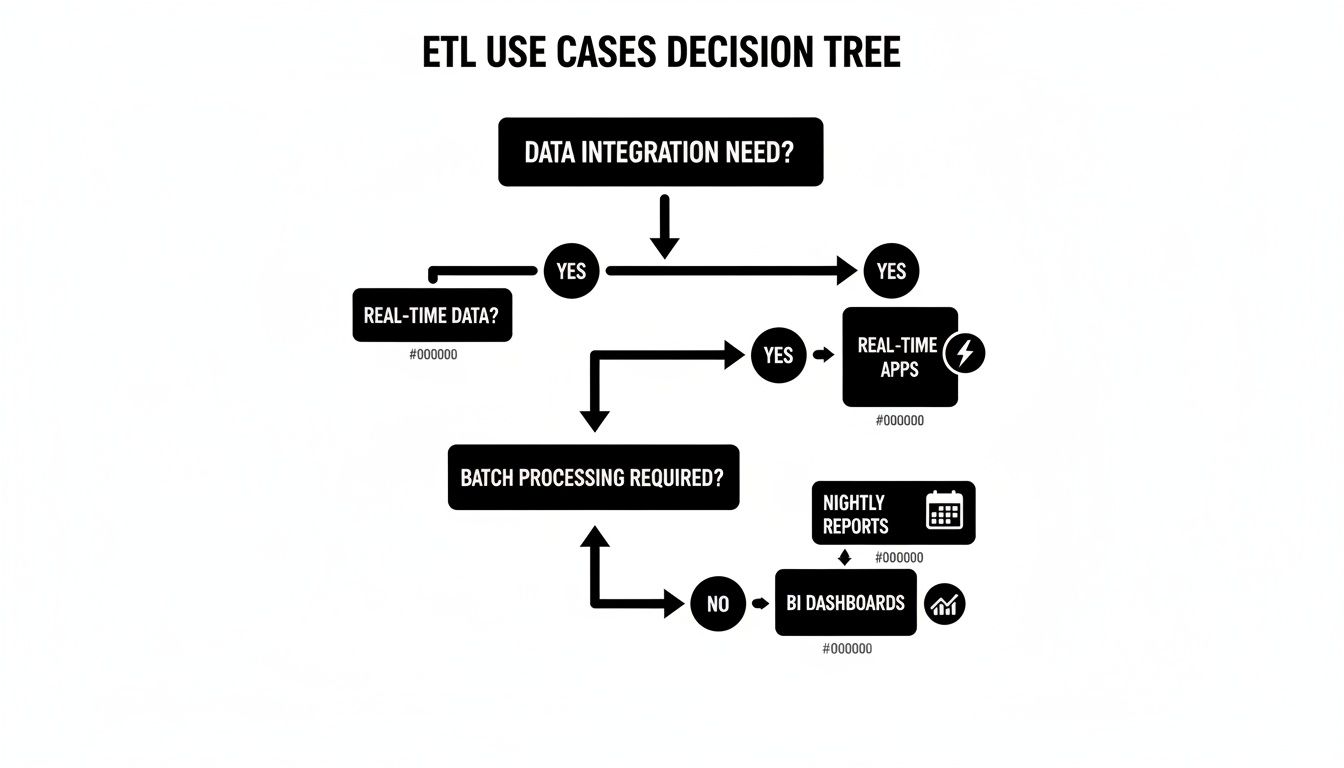
As you can see, the path is pretty clear. The lower your tolerance for latency—moving from historical reporting to in-the-moment applications—the stronger the case becomes for shifting from batch processing to real-time streaming.
The Strategic Payoff of Moving to Streaming
For many companies, the real question isn’t about choosing a tool from scratch; it’s about when and how to migrate off legacy batch systems. The reasons to make the switch go far beyond just getting faster data.
Slash Operational Overhead
Modern streaming platforms like Streamkap can replace a messy patchwork of custom Python scripts, cron jobs, and brittle batch pipelines. This consolidation drastically simplifies your data stack, meaning fewer things can break. It also frees up your best engineers from tedious maintenance so they can focus on work that actually drives revenue.
Boost Performance and Scale Gracefully
Batch jobs are notorious for hammering your source databases with huge, spiky queries that can degrade application performance. Streaming CDC, on the other hand, works by reading the database transaction log. This is a far gentler approach that has minimal impact on your production systems and scales much more smoothly as your data volume grows.
Unlock New Business Capabilities
This is the real game-changer. Moving to a streaming architecture lets you build things that were simply impossible with batch processing. You can power dynamic customer experiences, build proactive operational alerts, and make critical decisions based on what’s happening right now. Your data infrastructure evolves from a backward-looking reporting tool into a forward-looking operational engine.
Frequently Asked Questions About ETL and Data Integration
Diving into data integration often brings up more questions than answers. When you’re comparing ETL tools, you’ll likely run into the same points of confusion many others have. Let’s tackle some of the most common questions to give you a clearer path forward.
What’s the Real Difference Between ETL and ELT?
The main distinction between ETL (Extract, Transform, Load) and ELT (Extract, Load, Transform) is all about when and where you transform the data.
With traditional ETL, you pull data from a source, clean and reshape it on a separate server, and then load the finished product into your data warehouse. This was the go-to method for years, mostly because warehouse compute was expensive and couldn’t handle heavy transformations.
ELT completely flips that around. You extract the data and immediately load it—raw and untouched—into a modern cloud data warehouse like Snowflake or BigQuery. All the transformation work happens inside the warehouse itself, taking advantage of its massive, scalable compute power. This gets raw data into the hands of analysts much faster and generally simplifies the pipeline architecture.
When Should I Use Streaming CDC Instead of a Batch Tool?
The simple answer? You should reach for a streaming Change Data Capture (CDC) tool when your business can’t afford to wait for data. The choice really hinges on how fresh your data needs to be.
- Batch tools are perfectly fine for things like historical reporting—think end-of-month financial summaries or weekly performance dashboards. In these cases, data that’s a few hours or even a day old is usually acceptable.
- Streaming CDC is a must-have for real-time operations. If you’re building a fraud detection engine, a live inventory system, or any kind of event-driven application, you need data that is milliseconds fresh. Batch processing is a non-starter here.
Think about the business impact. If stale data means lost revenue, a frustrated customer, or a missed opportunity, then the real-time, low-impact nature of streaming CDC isn’t just a technical choice—it’s a strategic necessity.
How Does Automated Schema Evolution Actually Work?
Automated schema evolution is a lifesaver. It’s a feature in modern data platforms that handles changes to your source data’s structure without needing a developer to step in. Imagine someone adds a new column to a production database table.
Instead of your pipeline breaking, the tool automatically detects this change. It then mirrors that change in the destination, for instance, by adding the new column to the target table. This keeps data flowing and prevents the pipeline failures that plague so many traditional ETL setups. It’s a huge win for pipeline resilience and saves engineers from constantly putting out fires.
What Are the Hidden Costs I Should Look Out For?
The license fee for a data tool is just the tip of the iceberg. To understand the true Total Cost of Ownership (TCO), you have to dig deeper and account for the costs that aren’t on the price tag.
- Engineering and Maintenance: This is almost always the biggest expense. How many hours will your team sink into building pipelines, monitoring them, and fixing them when they inevitably break? A fully managed service can drastically cut down on this operational overhead.
- Infrastructure Costs: If you’re looking at open-source or self-hosted tools, you’re on the hook for the servers, storage, and networking. These costs can balloon quickly as your data volume grows.
- Opportunity Costs: What’s the real business cost when your data is late or a pipeline is down? If your fraud detection system is offline for an hour, the financial hit could be massive.
- Scaling Costs: Pay close attention to the pricing model. Some tools seem cheap to start, but their costs can skyrocket as your data grows, leading to some nasty budget surprises down the road.
Ready to eliminate hidden costs and operational headaches with real-time data integration? Streamkap provides a fully managed streaming CDC platform, handling the complexities of Kafka and Flink so your team can focus on building value. See how you can achieve sub-second latency and resilient pipelines by getting started with Streamkap today.
Related resources
Sub-50ms Data Streaming for AI Agents: Benchmarks, Architecture, and Platform Comparison
Compare real-time data streaming platforms by latency performance for AI agent workloads. See how sub-50ms delivery changes agent decision quality and accuracy.
Streaming to Vector Databases: Comparing Managed Platforms for AI Teams
Compare managed streaming platforms for building real-time pipelines to vector databases. Covers Pinecone, Weaviate, Qdrant, and pgvector integration patterns.
Best CDC Platform for AI Workloads: What to Look For
Evaluating CDC platforms for AI and GenAI use cases? Compare Streamkap, Confluent, Estuary, Fivetran, Airbyte, AWS DMS, and Striim across latency, transforms, agent support, and cost.