Discover batch processing vs stream processing: Which Is Best for Your Data
Compare batch processing vs stream processing to decide the right approach for your data. Learn architectures, use cases, and decision criteria.
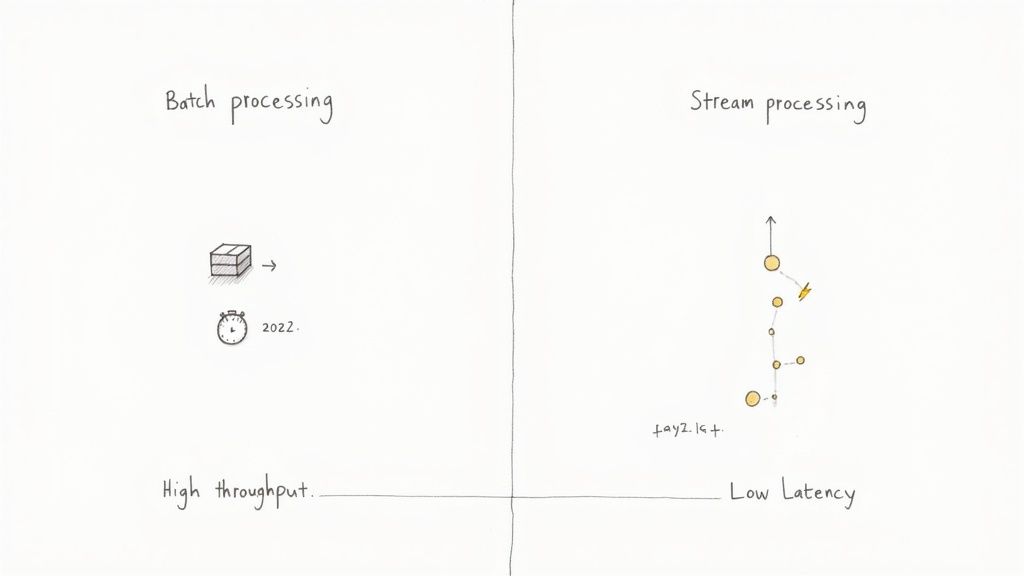
When you get right down to it, the difference between batch and stream processing is all about timing and how much data you're looking at in one go.
Batch processing is the classic approach: you collect data, let it pile up, and then run a massive job over the whole chunk at a set time. Think high throughput for huge workloads. Stream processing, on the other hand, is about the here and now. It tackles an endless flow of data in tiny pieces, almost as it’s created, prioritizing low latency so you can get immediate answers.
Understanding The Fundamental Difference In Data Processing
The choice between batch and streaming boils down to a single, critical question: do you need to analyze a massive, historical dataset, or do you need to react to new events the moment they happen?
Batch processing is like taking a census. You gather all the information you can over a long period, and only then do you sit down to analyze it for those big-picture, comprehensive insights. Stream processing is more like a live news ticker. It delivers information one event at a time, giving you the power to react and analyze on the fly.
This distinction is more than just a technical detail; it's central to modern data architectures. For decades, batch processing was the undisputed king, reliably handling everything from end-of-day financial reports to monthly billing cycles. But today, the business world moves faster. The demand for instant feedback and real-time analysis has put streaming in the spotlight. You can dive deeper into the mechanics of this continuous data flow in our guide on what is streaming data.
A Quick Comparison
To get a clearer picture, let's start with a high-level look at what sets these two methods apart. Think of this as the foundation for the deeper architectural and operational differences we'll explore later.
The decision is no longer just a technical preference but a strategic one. It's driven by how quickly you need to act on data, the complexity of your pipelines, and what your infrastructure can support. Modern data needs often require a blend of both.
Here’s a simple table to summarize the core differences. Getting these distinctions straight is the first step toward choosing the right data strategy for your specific needs, whether that’s historical reporting or a real-time fraud detection engine.
Quick Comparison Batch vs Stream Processing
As you can see, each model is built for a completely different purpose. One is about depth and scale over time, while the other is about speed and immediacy.
A Deep Dive Into Processing Architectures
To really get the difference between batch and stream processing, you have to look past the surface-level details like speed. The real story is in their underlying architectures. Each is built from the ground up for a totally different purpose, and that design choice dictates everything—how data moves, where it lives, and how you work with it.
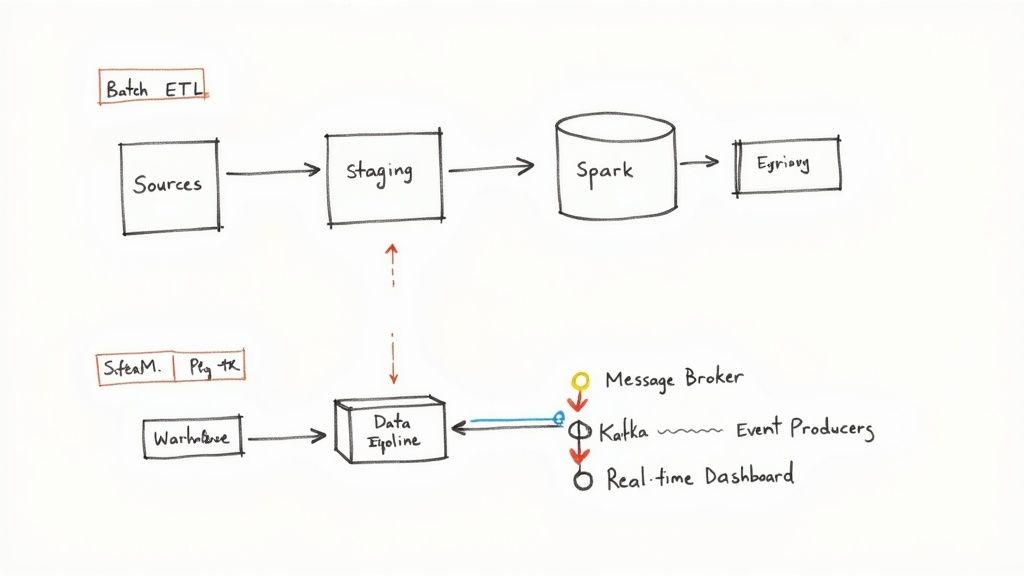
The Structured World of Batch ETL
Batch processing architecture is all about the classic Extract, Transform, Load (ETL) workflow. It’s a predictable, sequential model designed for handling huge, but finite, chunks of data. Think of it like a factory assembly line: one stage has to finish its job completely before the next one can even start.
The process is broken down into three well-defined steps:
- Extract: First, the system pulls data from all the different sources—databases, CRMs, flat files, you name it—at a scheduled time. This raw data then gets dumped into a temporary staging area.
- Transform: Here in the staging area, the data gets a heavy-duty makeover. It's cleaned, validated, aggregated, and reshaped to match the schema of whatever system it's heading to next.
- Load: Finally, the clean, transformed data is loaded into its final destination, usually a data warehouse or data lake. At this point, it's ready for BI teams and analysts to start running reports.
This whole operation is typically managed by processing engines like Apache Spark or Hadoop MapReduce. For a good look at how this plays out in a cloud environment, you can find great examples of Batch ETL with AWS Glue, EMR, and Athena. One of the big advantages of this architecture is its robustness; if a job fails, you can often just restart the batch without losing any data.
The Continuous Flow of Stream Processing
Stream processing is a different beast entirely. Its architecture is built for data that’s always in motion. Instead of rigid, separate stages, it’s a continuous pipeline that processes events the moment they’re created. This is what makes real-time analytics and immediate action possible.
You'll find a few core components in any streaming setup:
- Event Producers: These are the sources spitting out the constant flow of data. Think application logs, IoT sensor readings, clicks on a website, or database changes picked up by Change Data Capture (CDC).
- Message Brokers: This is the pipeline's central nervous system. Tools like Apache Kafka or RabbitMQ catch and hold onto these event streams. They act as a buffer, separating the producers from the consumers, which is critical for making sure no data gets lost if a downstream processor hiccups.
- Stream Processing Engines: This is where the real-time work gets done. Engines like Apache Flink or Kafka Streams grab events from the broker and apply transformations, run calculations, or trigger alerts on the fly, often in milliseconds.
With batch, data is at rest when you process it. With streaming, it's always in flight. This model is non-negotiable for things like fraud detection, live monitoring dashboards, and real-time personalization, where data’s value evaporates in seconds.
The move from batch to streaming isn't just an upgrade—it's a fundamental shift in how you think about data. Batch treats data like a static library you check out periodically. Streaming treats it like a dynamic, live conversation.
Of course, many organizations need both historical analysis and real-time insights, leading to hybrid models. To see how these systems cleverly blend batch and streaming, it’s worth checking out https://streamkap.com/blog/the-evolution-from-lambda-to-kappa-architecture-a-comprehensive-guide. Each architectural pattern offers a different take on balancing latency, cost, and complexity.
Making the Right Trade-Offs in Your System Design
Choosing between batch and stream processing is far more than a technical coin flip. It’s a strategic decision that ripples through your system’s performance, its cost, and ultimately, its ability to create business value. You need to get to grips with the fundamental trade-offs: latency, throughput, and data consistency.
This isn’t about one being "fast" and the other "slow." It’s about understanding the business implications of your choice. Are you aiming for deep, historical analysis or immediate, event-driven action? The answer dictates your architecture.
Latency vs. Throughput: The Core Dilemma
The classic tug-of-war in data processing is between latency (how fast you get an answer) and throughput (how much data you can push through in a set time).
Batch processing is all about maximum throughput. It’s designed to chew through massive datasets efficiently by gathering data into large, scheduled chunks. Think of it like a cargo ship—it can move an incredible amount of freight, but it’s not winning any speed races. This high-latency, high-throughput model is perfect when comprehensiveness is more important than speed, like for end-of-month financial reporting or training a machine learning model on years of historical logs.
Stream processing, on the other hand, is built for minimal latency. It handles events one by one, or in tiny micro-batches, as they happen. This is your fleet of delivery motorcycles—each carries a small package but gets it to its destination almost instantly. This approach is non-negotiable for real-time applications like fraud detection, where you need to flag a suspicious transaction in seconds, not hours.
The difference in scale and speed is stark. For instance, a Databricks survey found that 65% of enterprises process over 100 TB of data monthly using batch ETL. On the streaming side, a platform like Apache Kafka can power systems at LinkedIn to process 2 million messages per second, enabling fraud detection with 99.99% accuracy by raising alerts within 100ms. The catch with streaming? It often has to wrestle with tricky issues like out-of-order data. You can find more details in this breakdown of batch and stream processing.
Consistency and Order: A Tale of Two Models
Data consistency is another crucial battleground. The way a system manages data state and event order defines its reliability and its complexity.
With a batch system, consistency is refreshingly simple. You're processing a finite, bounded dataset all at once, giving you a complete, stable snapshot of the data for that period. If a job fails? No problem. You just rerun the entire batch on the same input data. This atomic nature makes batch processing inherently dependable for any task that demands strong consistency.
Stream processing forces you to confront the messiness of the real world—events arrive late, out of order, or not at all. Handling this requires a more complex architecture, but the payoff is a system that reflects reality in near real-time.
Streaming operates in a much more chaotic world. It has to contend with unbounded, continuous data where events can show up late or out of sequence. This introduces a whole new level of complexity. To keep data accurate, streaming systems rely on sophisticated tools:
- Windowing: This involves grouping events by time (like a 5-minute rolling average) to carve out finite chunks for analysis from an otherwise infinite stream.
- Watermarking: A clever mechanism that uses event timestamps to estimate when a time window is "complete," allowing the system to handle late data without waiting forever.
- State Management: Continuously maintaining and updating application state as new events arrive. This requires bulletproof fault tolerance to avoid losing data if a server goes down.
Achieving exactly-once processing semantics—guaranteeing every event is processed once and only once, even if failures occur—is a serious engineering challenge in streaming. Frameworks like Apache Flink have made it possible, but it adds operational overhead you just don't have when you can simply rerun a failed batch job. The right choice comes down to your use case: can you live with eventual consistency, or do you absolutely need the immediate, (and more complex) accuracy of a real-time system?
Practical Use Cases To Guide Your Decision
It's one thing to understand the theory behind batch and stream processing, but it's another to see how they play out in the real world. Honestly, the right choice always comes down to the business problem you're trying to solve. The fundamental question is: does your operation hinge on periodic, deep analysis, or do you need immediate, actionable insights from live data?
This simple decision tree can help frame your initial thinking by focusing on whether your core need is historical analysis or real-time action.
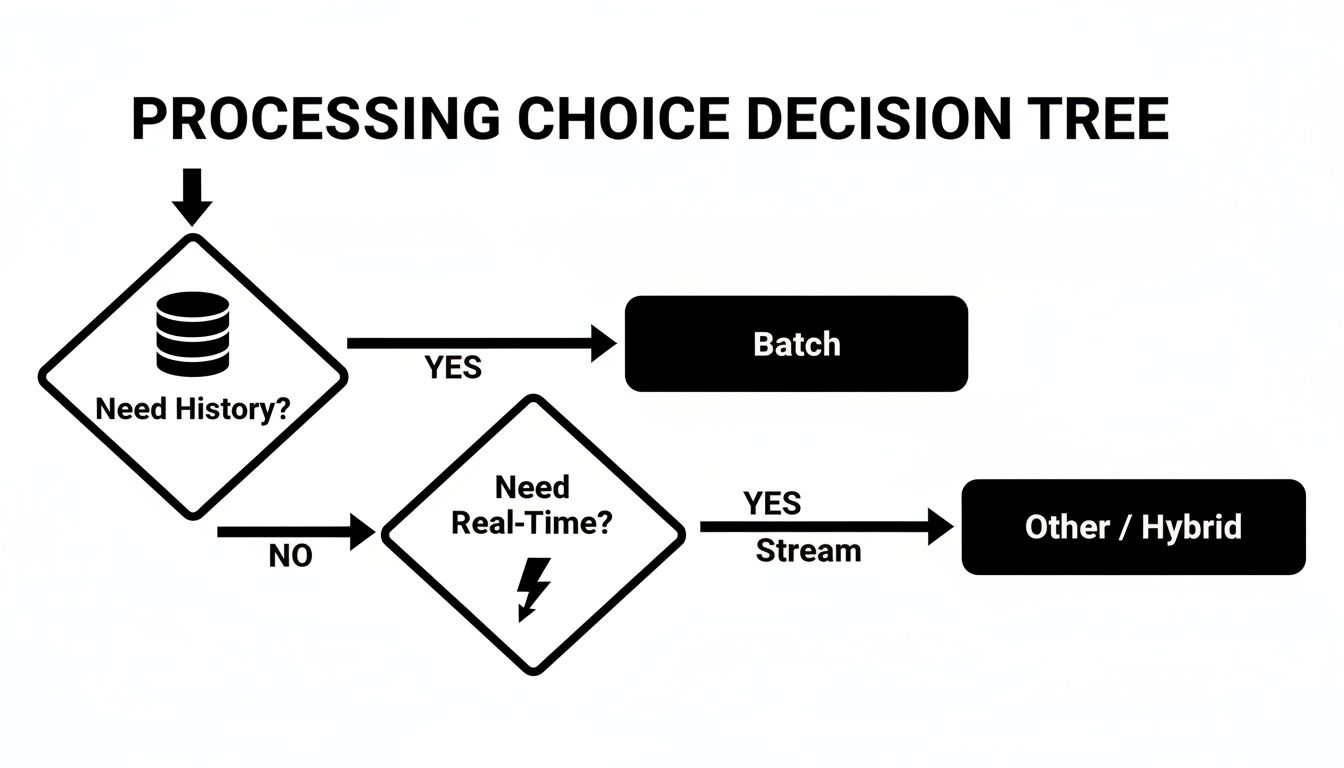
As the visual shows, if your main goal is to analyze historical data, batch processing is the straightforward path. If the priority is reacting to events as they happen, stream processing is what you need.
When Batch Processing Excels
For any workflow where high throughput and comprehensive analysis of large, finite datasets are the top priorities, batch processing is still king. In these scenarios, latency is an acceptable trade-off because the value is in the depth of the insight, not the speed of its delivery.
Think about these classic examples:
- End-of-Day Financial Reporting: Banks and financial firms absolutely depend on batch jobs to reconcile the day's transactions. The process demands total accuracy and completeness, making a scheduled, high-volume job a perfect fit.
- Monthly Billing Systems: Utility companies and subscription services gather usage data over an entire month. Then, they run a single, massive batch process to generate all the invoices. The goal isn't speed; it's about correctly and efficiently processing every single customer's data.
- Large-Scale Machine Learning Model Training: When you're training a complex AI model, you often need to feed it years of historical data. This is a quintessential batch workload—processing terabytes of data to find patterns, a job that can take hours or even days to complete.
In batch processing, the dataset is the star of the show. The goal is to perform a complex operation on a complete, static set of information, ensuring every record is accounted for before delivering the final result.
Where Stream Processing Is Essential
Stream processing shines wherever the value of data decays rapidly. The business imperative is to analyze and react to events in milliseconds or seconds. Any delay can mean missed opportunities or even direct financial losses.
Here are a few prime examples where streaming is non-negotiable:
- Real-Time Fraud Detection: The moment a credit card is swiped, that transaction data has to be analyzed against fraud patterns to approve or deny the charge. Waiting for a batch job would make the entire system useless.
- Live Monitoring of IoT Sensor Data: A factory floor with thousands of sensors needs to detect equipment anomalies the second they happen to prevent costly shutdowns. Stream processing engines analyze this constant flow of data to trigger immediate alerts.
- Dynamic E-commerce Pricing: Online retailers constantly adjust prices based on real-time demand, competitor pricing, and user behavior. This requires a streaming architecture that can ingest market signals and update prices on the fly.
Batch processing has been a data management cornerstone for decades, with systems like Hadoop MapReduce capable of crunching up to 10 TB of data per hour on a large cluster. By contrast, stream processing, popularized by platforms like Apache Kafka, processes data continuously, slashing latency to just milliseconds.
Netflix's move from batch processing to Apache Flink is a perfect case study. They cut their personalization latency from hours down to under a minute. This change boosted user engagement by 20% and slashed storage costs by 50% by removing the need to persist batch data. You can learn more about this powerful shift in this comprehensive comparison.
Hybrid Architectures: The Best of Both Worlds
Many organizations quickly realize they need both deep historical analysis and real-time responsiveness. This has naturally led to the rise of hybrid architectures that combine batch and stream processing to get the job done.
The Lambda Architecture is a well-known hybrid model. It essentially runs two parallel data pipelines: a "batch layer" that computes comprehensive views from all historical data, and a "speed layer" that provides real-time views of the most recent events. Queries then combine results from both layers to give users a complete, up-to-date picture. While powerful, it can be a beast to maintain.
The newer Kappa Architecture aims to simplify this. It uses a single streaming pipeline to handle both real-time processing and historical reprocessing, effectively treating batch as just a special case of streaming.
The Day-to-Day Reality: What It's Really Like to Run Each System
Performance metrics like latency and throughput only tell half the story. The real decider between batch and stream processing often comes down to the practical, day-to-day realities of keeping the lights on. We're talking about total cost of ownership—not just servers, but fault tolerance, debugging headaches, and the specialized talent you'll need. Getting this right is the key to a sustainable architecture.
Batch systems are, frankly, simpler and more forgiving. If a nightly job falls over, the fix is usually pretty clear: find the bug, and rerun the whole thing. This operational simplicity is a huge plus, especially for teams that aren't staffed with distributed systems wizards.
Stream processing, on the other hand, is a world of perpetual motion. You can't just hit "restart" on an infinite, stateful data flow. When something breaks, recovery is a much trickier, higher-stakes game.
Fault Tolerance and Data Consistency
The way each model handles data integrity couldn't be more different. Batch processing has a natural advantage here, making consistency a much easier problem to solve.
Since batch jobs work on finite, self-contained datasets, they can achieve near-perfect consistency with relative ease. A failed Hadoop job, for instance, can often recover 99.8% of its data without gaps just by re-running. It’s a robust model. A Forrester report found that 82% of batch users in both Europe and the US see error rates under 1%. Compare that to the 15% error rate some stream processing setups report, and the difference is stark. You can dig into more of these data processing benchmarks on docs.databricks.com.
Stream processing, in contrast, is all about resilience by design. To handle a never-ending flow of data, you have to build for failure. The holy grail is exactly-once semantics—ensuring every single event is processed once and only once—and it's a massive engineering lift. Frameworks like Apache Flink can process over a trillion events daily with less than a 0.01% duplication rate for companies like Netflix, but that kind of reliability demands stateful backends that can easily add 20-30% to your operational overhead.
The operational mantra for batch is "rerun on failure." For streaming, it's "recover state without data loss." The latter requires a far more sophisticated and expensive engineering effort to get right.
When planning for disaster recovery, understanding the specifics of differential vs. incremental backup strategies is also critical for maintaining state and ensuring you don't lose precious data.
Cost Implications: Infrastructure and Talent
The price tags—both in dollars and human resources—are also worlds apart. These costs go far beyond the initial server setup and bleed into long-term maintenance and team-building.
Batch processing often plays nicely with a more frugal infrastructure model. You can spin up a cluster to crunch numbers for a few hours and then spin it right back down. This elastic, on-demand approach is a perfect fit for the cloud and keeps you from paying for idle resources.
Streaming systems don't have that luxury. They have to be "always-on," which means a cluster of servers must be running 24/7, ready to process data the instant it arrives. While autoscaling helps, the baseline cost for constant availability is inherently higher.
The talent pool also has a major impact on your budget.
- Batch Development: The skills for building classic ETL pipelines are fairly widespread. Plenty of data professionals are comfortable with SQL, Python, and tools like Apache Spark.
- Stream Development: Finding engineers who can build and maintain robust, real-time streaming applications is a different story. They need deep expertise in distributed systems, state management, and complex frameworks like Flink or Kafka Streams. This talent is harder to find and more expensive to hire.
At the end of the day, while batch systems might feel old-school, their operational simplicity and lower overhead make them a pragmatic, cost-effective choice for many situations. Streaming unlocks incredible real-time power, but that power comes with a hefty operational tax in complexity, cost, and the need for a highly specialized team.
Modernizing Your Data Stack: From Batch To Streaming
Making the leap from the familiar, scheduled world of batch processing to a real-time streaming architecture is a fundamental shift in strategy. It's more than just plugging in new tools; it’s a complete change in how you think about data, moving from periodic reports to continuous, operational intelligence. The first, most critical step is to nail down the business case. What's the goal? Are you trying to stop fraud as it happens, personalize a customer's experience on the fly, or keep a close eye on critical infrastructure?
Getting a clear answer to that question proves the value of sub-second data and builds the justification for the investment. Once you know why you're doing it, you can figure out how. This means evaluating the right technologies—stream processing engines like Apache Flink, message brokers like Apache Kafka, and, crucially, a way to get data from your sources without bringing them to a crawl.
Implementing The Migration
A smooth migration comes down to a solid plan that tackles the big technical hurdles from day one. The bedrock of any modern streaming pipeline from a database is Change Data Capture (CDC). CDC lets you capture and stream every single insert, update, and delete from your source systems in real-time, all without putting any extra load on them.
This completely sidesteps the inefficient, performance-killing batch queries that old-school ETL jobs relied on. But just setting up CDC isn’t the whole story. You'll run into several operational challenges that need solving:
- Handling Schema Evolution: Let's be honest, database schemas are never static. Your pipeline needs to be smart enough to detect schema changes automatically and push them downstream without breaking everything or losing data.
- Ensuring Data Integrity: You can't afford to miss events. The system must have bulletproof, exactly-once delivery guarantees to make sure every change is processed correctly, even when things inevitably go wrong.
- Developing Robust Monitoring: A batch job is simple: it works or it fails. A streaming pipeline is a living, breathing thing that runs 24/7. You absolutely need continuous monitoring for latency, throughput, and errors to keep it healthy.
The real trick to modernizing your data stack isn't just about making data move faster. It's about building a system that is resilient, adaptable, and easy to observe—one that can roll with the punches of a continuous, unpredictable data flow. The key is abstracting away the gnarly bits.
This is where platforms like Streamkap come in. They are built specifically to take the pain out of this transition by managing all the complex, moving parts of a real-time CDC pipeline. By providing a managed Kafka and Flink setup, Streamkap handles tricky things like schema evolution, fault tolerance, and monitoring out of the box.
This significantly lowers the barrier to entry, letting your team focus on creating value from real-time data instead of getting bogged down in infrastructure management. For a more detailed guide, check out our technical deep dive on migrating from batch ingestion to a streaming model. It's a practical way to adopt a streaming-first approach without the massive operational overhead.
Tying Up Loose Ends: Common Questions on Data Processing
To wrap things up, let's tackle a few questions that always seem to pop up when people are weighing batch against stream processing. Getting these straight can clear up common confusion and help you make a much better decision.
Can You Mix Batch and Stream Processing?
Yes, and it's actually quite common. Most sophisticated data platforms are hybrids, pulling from both worlds to cover all their bases. A classic example is a large e-commerce business. They'll use stream processing to power real-time fraud detection at checkout and keep inventory levels updated by the second.
But overnight? That's when the batch jobs kick in. They'll run massive analytical queries on the day's sales data, generate complex financial reports, and trigger warehouse restocking. This hybrid model, often built on a Lambda or Kappa architecture, gives you the best of both: instant operational smarts and deep, historical analysis.
Is Stream Processing Always the More Expensive Option?
It can be, but it’s not a given. The real difference is in the cost structure. Streaming systems have to be "always-on," which means you're paying for compute and infrastructure around the clock. Batch systems, on the other hand, can often be spun up during off-peak hours and then shut down, which can save on costs.
There's also the human element. Building and managing resilient, real-time pipelines takes a specific skillset that often comes at a premium. The key is to weigh these costs against the value of real-time data. If you can stop a $10,000 fraudulent transaction a minute sooner, the higher operational cost of streaming starts to look like a smart investment.
The cost debate isn't just about dollars and cents. It's about the value of speed to your business. If real-time insights generate revenue or prevent major losses, the higher operational expense of streaming becomes a strategic advantage, not just a line item.
Which One Is Better for Machine Learning?
That's like asking if a hammer or a screwdriver is better for construction—it completely depends on the job.
Batch processing is your go-to for training massive, complex ML models. Think about training a large language model on the entire internet or an image recognition model on millions of photos. You need to process enormous, static historical datasets, and batch is built for exactly that.
Stream processing is essential when the model needs to make decisions in the real world, right now. This is for things like real-time ad bidding, recommendation engines that update as you browse, or predictive maintenance systems on a factory floor that need to react to live sensor data.
Ready to move past slow, clunky batch ETL? Streamkap offers a managed Apache Kafka and Apache Flink platform designed for real-time, CDC-based pipelines. We handle the operational complexity so you can focus on unlocking the value of your data in real time. Start building your first streaming pipeline today.