A Guide to Real-Time Data Processing
Discover real-time data processing with our complete guide. Learn how it works, explore key architectures, and see real-world examples in action.
Real-time data processing is all about analyzing information the very second it’s created. This lets businesses react right now, not hours or days from now. It effectively turns data from a historical record into a live tool for making decisions on the fly.
The Need for Instant Insights in Modern Business
Think about the difference between driving with a printed map and a live GPS. The map is like traditional data analysis—it shows you a planned route based on information that's already old. But the GPS? That's real-time data processing. It sees the traffic jam that just formed up ahead and instantly finds you a better way.
This simple analogy gets to the heart of why acting on live information is so powerful.
We're drowning in data from social media feeds, IoT sensors, and online shopping carts. The value of that data starts to decay the moment it's created. Businesses can't afford to wait for yesterday's reports to figure out what customers are doing or what's going wrong in their operations. Being able to process data streams as they happen isn't just a nice-to-have anymore; it's a fundamental part of staying competitive.
Why Speed Is Now a Strategy
The push for instant insights isn't just about doing things faster. It's about making smarter, more relevant decisions in the moment. This shift is driving huge growth in the market. To put a number on it, the global real-time analytics market was valued at USD 51.36 billion in 2024 and is expected to jump to USD 151.17 billion by 2035. That's a clear signal that entire industries are betting big on instant, data-driven strategies. You can find more details on these trends over at marketresearchfuture.com.
This new focus on speed brings some major advantages:
- Proactive Problem-Solving: You can spot and stop things like fraudulent transactions or supply chain hiccups before they turn into full-blown crises.
- Enhanced Customer Experiences: It's about delivering personalized offers and support based on what a user is doing right now, not what they did last week.
- Operational Agility: Businesses can adjust things like pricing or delivery routes in direct response to live market changes.
The core idea is simple but incredibly powerful: Data is at its most valuable the instant it’s born. Waiting to act on it is like letting an opportunity just fade away.
Getting to this level of responsiveness means you need to get the underlying technology right. At its core, effective real-time data processing depends on systems that can handle a constant, high-volume flow of information without breaking a sweat. To see how these systems are built, check out our guide on real-time data integration.
In this guide, we'll walk you through everything you need to know. We’ll break down the key concepts, compare different ways of processing data, and look at the architectures that make instant insights a reality. Consider it your roadmap from theory to real-world application.
Comparing Different Data Processing Paradigms
To really grasp what makes real-time data processing so powerful, it helps to put it side-by-side with more traditional methods. Let's be honest, not every piece of data needs to be acted on the second it’s created. The right approach always depends on what you’re trying to achieve. The three main ways to handle data are batch, micro-batch, and real-time streaming.
A great way to think about this is through the lens of a restaurant handling credit card payments at the end of a busy day. How and when they process those transactions perfectly illustrates the core idea behind each method.
This infographic captures the shift from the static, after-the-fact analysis of older methods to the dynamic, in-the-moment flow of real-time data.
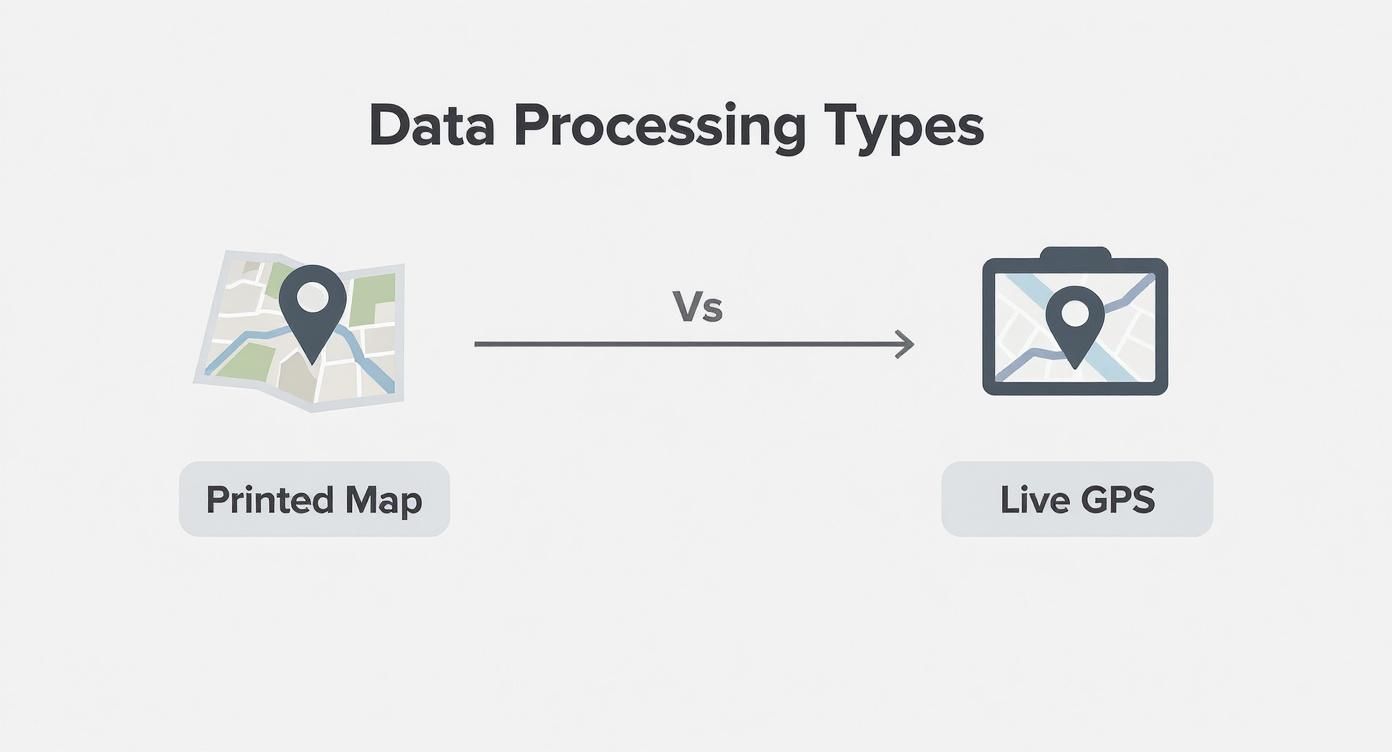
Think of it as the difference between using a printed map to plan a trip (batch) versus following a live GPS with real-time traffic updates (streaming). One gives you a historical snapshot, while the other guides your next move.
The Traditional Batch Processing Method
Batch processing is like our restaurant owner collecting every credit card slip from the entire day and running them all in one big go after closing up for the night. This method is incredibly efficient for churning through massive amounts of data when you don’t need the results right away.
This "wait and process" approach is ideal for tasks where time isn't a critical factor. Think about running monthly payroll, compiling end-of-quarter financial reports, or kicking off complex data warehousing jobs that can run overnight.
Here’s what defines batch processing:
- High Latency: The insights come hours, or even days, after the data was first collected.
- Large Data Volumes: It's built to chew through terabytes or petabytes of data without breaking a sweat.
- Scheduled Execution: These jobs are set to run at specific times, like daily at midnight or on the first of the month.
While it's a workhorse for historical analysis, batch processing just can't keep up with use cases that demand instant action.
The Middle Ground: Micro-Batch Processing
Now, what if the restaurant owner feels that waiting until midnight is leaving them in the dark for too long? Instead, they start processing the day’s receipts in small stacks every 15 minutes. That’s micro-batch processing in a nutshell.
It's a clever compromise, bridging the gap between the slow, steady pace of batch and the instant feedback of streaming. By processing data in small, time-based windows, it dramatically cuts down the latency of traditional batch methods while still organizing data into manageable chunks. If you want to dig deeper into how these methods stack up, check out our guide on batch vs stream processing.
Micro-batching delivers a "near real-time" experience. It’s a great fit for systems that need frequent updates but don’t require a sub-second response, like refreshing a sales dashboard every five minutes.
The Power Of Real-Time Stream Processing
Finally, let's look at real-time stream processing. In our restaurant, this is like having each credit card transaction approved, logged, and reflected in the daily sales report the very instant the card is swiped. There's no waiting, no grouping, and absolutely no delay.
This paradigm processes data one event at a time, as it happens. It’s the engine behind real-time data processing, turning raw data into immediate analysis and action. This is non-negotiable for applications where a delay of just a few seconds could mean a missed opportunity or a critical failure.
This approach is all about:
- Ultra-Low Latency: Data is handled in milliseconds, sometimes even microseconds.
- Continuous Data Flow: It’s designed for an endless, unbounded stream of events, not a finite dataset with a start and end.
- Event-Driven Actions: The system can trigger an immediate response—like flagging a fraudulent transaction—the moment a specific event occurs.
To make these distinctions crystal clear, let's break down how these three data processing paradigms compare.
Batch vs Micro-Batch vs Real-Time Data Processing
The table below offers a quick snapshot of the core differences, helping you see where each method shines.
AttributeBatch ProcessingMicro-Batch ProcessingReal-Time (Stream) ProcessingData ScopeLarge, bounded datasetsSmall, time-based windowsUnbounded, individual eventsLatencyHigh (Hours to Days)Low (Seconds to Minutes)Ultra-Low (Milliseconds)Data VolumeVery LargeModerateVaries (from small to very large)Use CasesPayroll, billing, reportingDashboard updates, log analysisFraud detection, live recommendations
Ultimately, choosing the right paradigm isn’t about which one is "best" overall, but which one is best for the job at hand. Each offers a different trade-off between latency, throughput, and complexity.
Understanding Core Real-Time Architectures
To make real-time data processing work, you need a solid blueprint. Just like you wouldn't build a skyscraper without an architectural plan, you can't process live data streams without a foundational pattern to manage speed, accuracy, and complexity. These architectures are the invisible frameworks that keep data flowing from its source to the point of decision in the blink of an eye.
Thankfully, you don't have to invent this from scratch. Engineers have already developed several proven models, each with its own philosophy and set of trade-offs. Let's walk through the three most influential approaches that power today's real-time systems.
The Lambda Architecture: A Dual-Path Approach
The Lambda Architecture is one of the original and most famous patterns for handling massive datasets. Its genius lies in its ability to balance near-perfect accuracy with very low latency by processing data through two separate, parallel paths.
Think of it like a news organization with two different types of journalists on the same story.
- The Batch Layer: This is your meticulous historian. It processes the entire, unchangeable master dataset in large chunks. It's not fast, but its calculations are comprehensive and incredibly accurate, creating what many call the "source of truth."
- The Speed Layer: This is the on-the-ground field reporter. It processes data as it arrives, giving you an immediate but sometimes slightly less precise view of what's happening right now. Its job is to fill the gap while the slower batch layer is busy crunching the historical numbers.
When a user asks a question, the system combines the results from both layers. This gives them a complete picture that blends historical accuracy with up-to-the-minute information.
This diagram shows how the Lambda Architecture splits the data flow, feeding new information into both the batch and speed layers at the same time.

The key thing to notice here is the separation of duties. This design provides fantastic fault tolerance, but it also introduces complexity—you’re essentially maintaining two different codebases for the two layers.
The Kappa Architecture: Simplifying the Stream
While the Lambda Architecture is powerful, managing two distinct data paths can become a real headache. That complexity is what inspired the Kappa Architecture, a more streamlined alternative designed to simplify the whole operation.
The big idea behind Kappa is to get rid of the batch layer completely. Instead, it handles everything—both real-time processing and historical analysis—through a single, unified stream processing pipeline.
How is that possible? It all hinges on a durable, replayable message log, with Apache Kafka being a prime example. If you need to recompute something from the past, you just tell the system to replay the data from the log through the very same stream processing engine.
The philosophy behind Kappa is simple: if your stream processor is fast enough and scalable enough, why bother with a separate system for batch jobs? This can slash your operational overhead.
The Kappa approach has some clear wins:
- Simplified Operations: You only have one set of processing logic to build, maintain, and debug.
- Faster Development: Your team can focus on mastering a single technology stack instead of juggling two.
- Greater Agility: It's much easier to update your processing logic since it all lives in one place.
The catch, however, is that this puts a ton of pressure on your stream processing engine. You also have to manage your data log carefully to ensure you can replay it when needed.
The Rise of Event-Driven Architectures
Finally, we have Event-Driven Architectures (EDAs). This isn't a specific data processing pattern as much as it is a broader architectural style that’s a natural fit for real-time work. In an EDA, different parts of a system communicate by producing and reacting to events.
An event is just a record of something that happened. Think "a customer added an item to their cart" or "a sensor reading crossed a critical threshold."
This model is real-time by its very nature. Services are built to react instantly and independently the moment a relevant event occurs. There's no waiting around for a batch job to run or a scheduled query to execute. The system is always on, just listening for events and ready to trigger the next action.
The growth in this space has been explosive. The streaming analytics market, which is a core part of these architectures, was valued at USD 23.4 billion in 2023 and is projected to soar to USD 128.4 billion by 2030. You can find more insights on this incredible growth in these data integration trends.
Ultimately, choosing the right architecture comes down to your specific needs. You have to weigh factors like complexity, cost, how quickly you need answers, and the skills your team brings to the table. Each of these patterns offers a different path to the same goal: turning raw data into immediate, actionable insight.
A Look Inside the Real-Time Technology Stack
Putting together a system for real-time data processing feels a lot like building a high-performance engine. You need specific, powerful components, each with a distinct job, all working in perfect harmony to handle data at incredible speeds. A typical real-time stack is made up of three core layers that manage the entire journey of your data.
Let's walk through these layers and the essential tools that bring them to life. Seeing how they connect takes the mystery out of the process and gives you a clear roadmap for building a solid, responsive system.
Message Brokers: The Central Nervous System
The first piece of the puzzle, and arguably the most critical, is the message broker. Think of it as the central nervous system for your data architecture. Its main job is to take in massive streams of events from all kinds of sources—website clicks, IoT sensor readings, application logs—and reliably hand them off to the systems that need to act on them.
These brokers serve as a durable buffer, making sure no data gets lost even if a downstream system temporarily hiccups or goes offline. They are the gatekeepers of your data stream.
Two major players dominate this space:
- Apache Kafka: Widely seen as the industry standard for high-throughput streaming, Kafka is built like a distributed, append-only log. It’s a beast at handling huge volumes of data with very low latency, which is why it's a go-to for large-scale real-time data processing where you simply can't afford to lose data. If you want to use this powerful tool without the headaches of managing it yourself, looking into managed Kafka can seriously speed up your project.
- RabbitMQ: This is more of a traditional message broker that focuses on smart routing. If Kafka is a log, RabbitMQ is a post office, offering complex and flexible routing patterns to get messages exactly where they need to go. It’s often picked for jobs that require intricate message choreography over raw data throughput.
Stream Processing Frameworks: The Analysis Engine
Once your data is flowing steadily through a message broker, the next step is to make sense of it on the fly. This is where stream processing frameworks come in. These are the engines that perform calculations, transformations, and enrichments on data as it moves, all without needing to stop and store it in a database first.
They are the brains of the operation, turning a raw flood of events into genuine, actionable insights.
These frameworks are designed to operate on unbounded data streams—meaning they work with data that has no defined beginning or end. This is the fundamental concept that makes continuous, in-the-moment analysis possible.
Here are the leading frameworks:
- Apache Flink: Known for its true event-at-a-time processing and sophisticated state management, Flink is a top choice for applications that need extremely low latency and pinpoint accuracy. It excels in use cases like real-time fraud detection and live analytics dashboards where every millisecond is critical.
- Spark Streaming: This framework uses a clever approach called micro-batching. It processes data in very small, rapid-fire batches, which creates a near real-time experience. This makes it an easy transition for developers who are already comfortable with the broader Apache Spark ecosystem for batch processing.
Specialized Databases: The Fast-Access Memory
Finally, after your data has been processed, you usually need a place to put the results so they can be queried instantly. Your standard-issue database just isn't built for the constant, high-speed writes and rapid-fire analytical queries that real-time applications demand. This is where specialized databases, designed specifically for time-series and analytical workloads, really shine.
These databases are optimized for two things: ingesting data at a blistering pace and running complex queries in milliseconds.
Here are a couple of popular choices:
- Apache Druid: A high-performance, real-time analytics database built for lightning-fast, ad-hoc queries on massive datasets. Druid is a favorite for powering user-facing analytical applications where snappy query responses are part of the core user experience.
- TimescaleDB: Built as an extension on top of PostgreSQL, TimescaleDB gives you the best of both worlds—the familiarity of a relational database with the performance you need for time-series data. It's a great option for teams that want to get into real-time data without having to abandon the comfort of SQL.
How Industries Use Real-Time Data Processing

The real magic of real-time data processing isn’t in the theory; it’s in seeing how it solves actual problems and opens up new possibilities for businesses. Across nearly every industry, the power to act on data in the blink of an eye is changing the entire game. It’s no longer just an upgrade—it's a fundamental shift in how companies operate, compete, and win.
The sheer amount of data available is almost hard to comprehend. By the end of 2025, the world is expected to be swimming in 181 zettabytes of data. A huge chunk of that—over 73 zettabytes—will come from IoT devices alone. This data explosion makes one thing crystal clear: we need systems that can keep up. You can get a better sense of this growth from this comprehensive overview of big data statistics.
Let's dive into a few examples of how different sectors are putting this to work.
Financial Services and Fraud Detection
In the world of finance, a few seconds can mean the difference between a secure transaction and a major financial loss. That's why banks and fintech firms rely on real-time stream processing to scan millions of transactions every second, hunting for red flags before any damage is done.
Think about what happens when you swipe your credit card. Instantly, a real-time system is checking that purchase against your usual spending habits, your location, and known fraud patterns. If it spots something odd—say, a purchase in another country just minutes after you bought coffee down the street—it can block the transaction and send you an alert. This same need for speed is critical in high-frequency trading, where powerful algorithmic trading strategies execute trades based on market data in fractions of a second.
E-commerce and Dynamic Personalization
For online retailers, success is all about creating a shopping experience that feels like it was made just for you. Real-time data processing is the secret sauce behind the dynamic pricing, personalized recommendations, and targeted offers that react to what you do on a site, moment by moment.
Let’s say you’re shopping for a camera. A real-time system can:
- Adjust Prices: Instantly tweak the price based on demand, what competitors are charging, or even the time of day.
- Recommend Products: Analyze your clicks and searches on the fly to suggest the perfect lens or a camera bag to go with your choice.
- Prevent Cart Abandonment: Sense that you’re about to leave the site and trigger a pop-up with a small discount to nudge you toward completing the purchase.
This kind of immediate, tailored interaction makes the whole experience feel smoother and more intuitive, which is a proven way to boost sales and keep customers coming back.
The goal is to move beyond historical analysis—what a customer did last week—and engage with what they are doing right now. This immediacy is the core of modern digital marketing.
Logistics and Supply Chain Optimization
For any company that moves goods, efficiency is the name of the game. By pulling in real-time data from GPS trackers, traffic sensors, and weather reports, logistics companies can optimize delivery routes on the fly. This means packages get where they need to go faster and with less fuel. If a sudden accident snarls up a highway, a driver’s route can be instantly recalculated to avoid the delay.
Back in the warehouse, real-time inventory tracking means the system always knows exactly what’s on the shelves. This simple but powerful capability helps prevent running out of popular items while avoiding the cost of overstocking others, creating a much more agile and efficient supply chain.
Manufacturing and Predictive Maintenance
On a factory floor, unexpected downtime is a budget killer. To get ahead of it, manufacturers now embed IoT sensors in their machinery to constantly monitor things like temperature, vibration, and power usage.
This firehose of data streams into an analytics platform where machine learning models are always watching for the tiniest signs of trouble. The system can predict that a specific part is likely to fail before it breaks down, automatically scheduling maintenance at the perfect time. This proactive approach, known as predictive maintenance, saves companies millions by preventing catastrophic failures and keeping the production line running smoothly.
Overcoming Hurdles: Implementation Challenges and Best Practices
Building a solid real-time data processing system is a serious undertaking, and it comes with its own unique set of challenges. The payoff is huge, but getting there requires careful planning and a heads-up on the common roadblocks you're likely to face. From data showing up out of order to the sticker shock of an always-on infrastructure, being prepared is half the battle.
Successfully launching a real-time platform means tackling these issues head-on with battle-tested strategies. This is your field guide, packed with practical advice to help you build a system that's not just powerful, but also dependable and affordable when the pressure is on.
Taming Out-of-Order Data
One of the first reality checks for any team is realizing that data rarely arrives in the clean, sequential order you’d expect. Network delays and multiple data sources mean events can show up late or completely mixed up. If your system can't handle this chaos, it will churn out flawed results—like miscalculating a user's journey or sending a premature alert.
To get around this, modern frameworks rely on a clever concept called watermarking. Think of a watermark as a timestamp that tells the system, "I'm not expecting any data older than this moment." This gives the system a grace period to wait for late-arriving data before it finalizes a calculation, striking a crucial balance between accuracy and speed.
A well-designed real-time system must embrace the inherent messiness of distributed data. Assuming perfect order is a recipe for failure; building in tolerance for delays is a requirement for success.
Building for Scale and Resilience
Real-time systems need to be ready for anything. A sudden traffic surge from a viral marketing campaign can overwhelm your pipeline in seconds. A single server crashing can't be allowed to take the whole operation down with it. That's why designing for scalability and resilience from day one isn't just a good idea—it's essential.
Here are a few best practices to keep your system humming along:
- Scale Out, Not Up: Go with technologies like Apache Kafka and Apache Flink that were built for horizontal scaling. This lets you simply add more machines to your cluster to handle a bigger load, instead of being stuck with the limitations of one giant server.
- Don't Lose Your State: Any process that needs to remember things (like counting clicks over a 5-minute window) requires a fault-tolerant state backend. If a node goes down, its in-progress work can be picked up instantly from a durable store like RocksDB, so you don't miss a beat.
- Monitor Everything: You can't fix what you can't see. Set up thorough monitoring and alerting to keep an eye on system health, data latency, and resource consumption. This visibility is your early warning system, helping you spot trouble before it becomes a full-blown crisis.
Managing Costs and Complexity
Let's be honest: an always-on, high-performance infrastructure can get expensive, fast. The complexity of managing all the moving parts also adds a ton of operational overhead. As you dive into building complex real-time systems, especially for AI or machine learning, looking at different outsourcing models for AI teams can be a smart move.
To keep a lid on costs and complexity, your best friends are automation and efficiency. Use infrastructure-as-code tools to make your deployments repeatable and predictable. Lean on serverless options or managed cloud services where they make sense. This frees up your team from doing routine maintenance, letting them focus on creating value instead of just keeping the lights on.
Frequently Asked Questions
What Is the Main Difference Between Etl and Real-Time Data Processing?
Think of it as the difference between developing a roll of film and watching a live video stream.
Traditional ETL (Extract, Transform, Load) is like that roll of film. It's a batch process, meaning it gathers up large amounts of data over time—say, an entire day's worth of sales—and then processes it all in one scheduled chunk. You get the full picture, but only after the fact, which is perfect for things like nightly reports.
Real-time data processing, on the other hand, is the live video feed. It processes data the very instant it's created, handling a continuous stream of events with incredibly low latency. This gives you immediate insights as things are happening, which is non-negotiable for making split-second decisions.
Is Real-Time Processing Always the Best Choice?
Absolutely not. It's a classic case of using the right tool for the job, and the best choice really boils down to your specific business needs.
Real-time processing is essential when you need to act now. Think of flagging a potentially fraudulent credit card swipe or instantly personalizing an offer for a visitor on your website. In these scenarios, the value is in the immediacy.
However, for tasks where a delay is perfectly acceptable, batch processing is often much more efficient and cost-effective. Generating monthly financial summaries or training complex machine learning models on massive datasets are perfect examples. You don't need instant results, so you can save on the complexity and cost that real-time systems often introduce. It’s always a trade-off between the need for speed and the operational overhead.
Ready to replace slow batch jobs with an efficient, streaming solution? Streamkap uses real-time CDC to sync your databases with minimal latency and no impact on source systems. Find out how to build a modern, event-driven architecture.