Solving Your Top Data Integration Problems
Struggling with data integration problems? Discover the 7 most common challenges holding back your business and learn the modern solutions to fix them.
Data integration problems aren't just technical hiccups; they're silent business killers that inject friction into every corner of your organization. They show up as conflicting reports, countless hours spent manually wrangling data, and missed market opportunities that block growth and hamstring smart decisions.
The Hidden Costs of Disconnected Data
Let's be real. Most data integration issues feel like an IT problem, but their shockwaves are felt far beyond the server room. Picture your sales, marketing, and operations teams all working from different maps—everyone is busy, but nobody is moving in the same direction. This is what happens when your data lives in separate silos, and the hidden costs pile up fast.
This isn't just an inconvenience; it's a major drag on the business. When your systems can’t talk to each other, you're left with a shattered picture of your own company, which naturally leads to bad strategic calls. To really get why this matters so much, it helps to look at a field where connected data is literally a matter of life and death. The same core ideas in what is interoperability in healthcare apply directly to the health of your business.
Operational Inefficiency and Wasted Resources
One of the most immediate costs is the sheer human effort it takes to patch over the data gaps. It's not uncommon for highly skilled analysts to spend up to 80% of their time just finding, cleaning, and prepping data instead of actually analyzing it.
This wasted effort puts a serious brake on operations. Think about these all-too-common situations:
- Manual Report Generation: Someone on your team exports spreadsheets from Salesforce, Marketo, and a production database, then spends the rest of the day trying to stitch them together in Excel just to get a single, coherent report.
- Delayed Decision-Making: Key business decisions are put on ice because leaders simply don't trust the conflicting numbers coming from different departments.
- Error-Prone Processes: Manual data entry and reconciliation are magnets for human error. Those tiny mistakes lead to flawed insights that can send your strategy and budget in completely the wrong direction.
The real cost of disconnected data isn't just the hours lost; it's the compounding effect of slow, unreliable, and inaccurate information poisoning your entire decision-making ecosystem. Every delayed project and every flawed forecast can be traced back to a failure in data integration.
Damaged Customer Experience and Missed Opportunities
Beyond the internal chaos, poor data integration directly hurts your customers. When your support team can't see a customer's purchase history, or marketing blasts out irrelevant promos based on stale data, people notice. This fragmented view of the customer leads to frustrating, impersonal interactions that chip away at loyalty.
Worse yet, a slow or incomplete data picture means you’re always playing catch-up. You might miss a subtle shift in customer behavior or fail to spot a new trend until a competitor has already seized the opportunity. These missed chances are the invisible price tag of data integration failures, representing lost revenue and a weaker position in the market.
Pinpointing the 7 Core Data Integration Challenges
Before you can fix the friction in your data, you have to find its source. It's easy enough to spot the symptoms—conflicting reports, endless hours wasted reconciling numbers, and missed opportunities. But the real culprits, the underlying data integration problems, are usually buried deeper. These are the foundational cracks that can destabilize your entire data strategy.
By getting to the root of these issues, you can stop just reacting to data emergencies. Instead, you can start building a resilient, modern data architecture that actually works. Let's dig into the seven most common blockers that prevent businesses from getting the full value out of their data.
1. Data Silos and Fragmentation
Picture a company where every department keeps its records in a separate, locked file cabinet. Sales has its cabinet, marketing has another, and finance a third. None of them talk to each other. That’s exactly what data silos are in the digital world. Each system—the sales CRM, the marketing automation platform, the ERP—operates as its own isolated island of information.
This fragmentation means you never get the whole story. You’re left with an incomplete, and often contradictory, picture of the business. Forget about a true 360-degree view of your customer or end-to-end visibility into your supply chain; it's just not possible when your data is scattered everywhere.
2. Data Quality and Inconsistency
So, you've managed to pull data from different sources. Great. The battle, however, is far from over. The next massive hurdle is making sure that data is actually usable. Inconsistent data quality is one of the most stubborn challenges in this entire process.
Just think about these all-too-common scenarios:
- Mismatched Formats: One system logs a customer's state as "CA," another as "California," and a third as "Calif." Which one is right?
- Duplicate Records: You have three different entries for the same customer, each with slightly different contact information.
- Missing or Stale Data: Critical fields are left blank, or you’re looking at information that's months out of date.
When your data is a mess, trust evaporates. Decision-makers can't rely on the numbers, so they fall back on gut feelings and guesswork, completely defeating the purpose of being data-driven in the first place.
3. Scalability and Performance Bottlenecks
As your business grows, so does your data. And it grows fast. The sheer volume of information being generated every single day can quickly overwhelm older integration methods. Traditional batch processes that run maybe once a day just can't keep up and end up creating serious performance bottlenecks.
During those long processing windows, the source systems themselves can slow to a crawl, impacting the day-to-day operations for your frontline teams. As data volumes explode, those batch jobs take longer and longer, pushing back the availability of fresh data and increasing the risk of outright failure. This constant game of catch-up is simply unsustainable.
"The true test of a data integration strategy isn't whether it works today, but whether it can handle three times the data volume tomorrow without breaking. Scalability isn't a feature; it's a prerequisite for survival."
This visual map shows exactly how these disconnected data sources create real business headaches, from conflicting reports to wasted time and lost revenue.
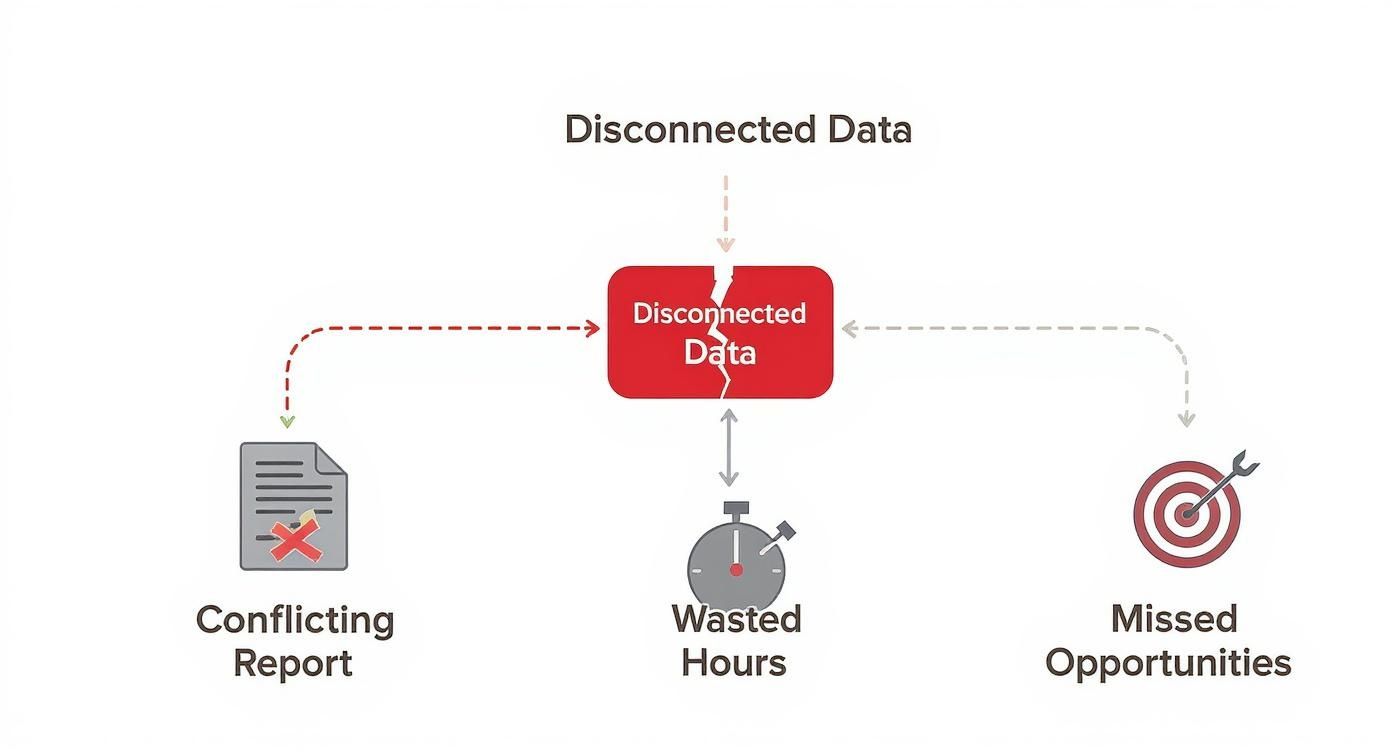
As the infographic makes plain, data fragmentation isn't just a technical annoyance. It's a core operational bottleneck with tangible, painful consequences.
4. The Demand for Real-Time Synchronization
Business doesn't operate on a 24-hour cycle anymore. Critical decisions around fraud detection, dynamic inventory management, and personalized customer experiences have to happen in seconds, not hours. This shift has created immense pressure for real-time data synchronization.
Relying on data that's 12, 8, or even 2 hours old is a recipe for failure. A customer service agent needs to see the purchase a customer made a few moments ago, not yesterday. An e-commerce site has to update stock levels instantly to avoid selling items that are already gone. The need for immediacy has made slow, batch-based integration methods completely obsolete.
5. Security and Compliance Risks
Every time you move data between systems, you open a new door for security risks. Each transfer point is a potential vulnerability. While encrypting data in transit and at rest is a given, managing access controls across dozens of disconnected systems is a monumental headache.
On top of that, regulations like GDPR and CCPA have strict rules about how personal data is handled and stored. A fragmented data landscape makes it nearly impossible to track data lineage or fulfill a customer's "right to be forgotten" request, exposing your organization to massive legal and financial penalties.
6. The Explosion of Data Sources and Formats
A couple of decades ago, most of a company's data lived neatly in structured relational databases. Today, it’s a whole different ballgame. Data flows in from an ever-expanding universe of sources in a dizzying variety of formats.
Just look at the modern data ecosystem:
- Structured Data: Classic databases from SQL or Oracle.
- Semi-Structured Data: JSON files from APIs, XML feeds.
- Unstructured Data: Social media comments, customer support chat logs, video files.
- Streaming Data: IoT sensor readings, website clickstream data.
Every new data source adds another layer of complexity to the integration puzzle. Trying to build and maintain custom connectors for every new app or API is a strategy that simply doesn't scale.
7. The Growing Skills Gap
Finally, there’s the human element. The technology for solving these integration problems is evolving at a breakneck pace, but the pool of talent isn't keeping up. Finding data engineers who are true experts at building and managing complex, real-time data pipelines is both incredibly difficult and expensive.
This skills gap puts a huge strain on existing IT teams, pulling them away from strategic projects to constantly patch and maintain brittle, high-maintenance integrations. The scale of the problem is staggering: enterprises now use an average of 897 different applications, but only 28% of them are actually connected. It’s no wonder that about 95% of IT leaders see integration as a major barrier to adopting AI—you can't train effective models on disconnected data. If you want to dive deeper, you can explore more insights about real-time data integration growth.
To put it all together, here’s a quick summary of how these technical issues translate directly into business pain.
Common Data Integration Problems and Their Business Impact
Integration ProblemTechnical SymptomBusiness ImpactData SilosInaccessible data across departments and systems.Incomplete customer view, poor cross-functional collaboration.Poor Data QualityInconsistent formats, duplicates, and missing values.Lack of trust in reports, flawed decision-making, wasted effort.Scalability BottlenecksSlow batch jobs, system slowdowns during processing.Delayed insights, poor operational performance, inability to grow.Lack of Real-Time DataData is hours or days old, leading to latency.Missed opportunities, poor customer experience, fraud risks.Security & ComplianceVulnerable data transfer points, poor data governance.Data breaches, fines from non-compliance (GDPR/CCPA).Source/Format ExplosionInability to connect to APIs, unstructured sources.Incomplete analytics, high maintenance costs for custom connectors.Skills GapOverburdened IT teams, reliance on manual processes.Slow innovation, high operational costs, project backlogs.
As you can see, what starts as a technical challenge quickly becomes a significant obstacle to achieving core business goals.
Why Traditional ETL Can No Longer Keep Up

Once you dig into the root causes of data integration headaches, a clear culprit emerges: the very methods we’ve trusted for years are now holding us back. For decades, the go-to process for moving data was ETL—Extract, Transform, and Load. It was a reliable workhorse for a business world that moved at a much slower pace.
Think of old-school ETL like a daily newspaper. It lands on your doorstep once a day, packed with yesterday’s news. You get a comprehensive summary, but the information is already out of date. You’re always reacting to what happened, not what’s happening now. This model worked just fine when big decisions were made weekly or monthly, but today, it's a massive bottleneck.
This legacy approach is simply cracking under the strain of modern data demands. When your entire economy operates in real-time, you can't afford to run your business on last night's data. It's time to unpack exactly why this once-trusted method has become a primary source of data friction.
The Inevitable Delay of Batch Processing
The core design of traditional ETL is built around batch processing. Data isn't moved as events happen. Instead, it’s collected and moved in big, scheduled chunks—usually overnight when nobody's watching. This means data latency isn't a bug; it's a feature.
By the time information lands in front of your analytics team, it’s already hours, or even a full day, behind reality. This built-in delay has some serious consequences:
- Delayed Insights: Leaders are left making critical calls based on a stale snapshot of the business.
- Poor Customer Experience: A support agent can't see a customer’s most recent purchase or complaint, leading to clumsy, frustrating conversations.
- Missed Opportunities: The moment you finally spot a trend in the data warehouse, the window to act on it has likely already slammed shut.
This fundamental lag is a huge reason companies can't get real-time analytics off the ground. For a closer look at the mechanics, you can read our guide on the key differences between batch vs. stream processing.
Intense Strain on Source Systems
Running a big ETL job is a brute-force operation. To pull all that data, these jobs hammer source databases with heavy, complex queries. This can hog an enormous amount of CPU, memory, and I/O, slowing down the very operational systems your business depends on to function.
To work around this, IT teams cram these jobs into "ETL windows," typically in the dead of night. But as data volumes explode, those windows are shrinking. A job that used to take two hours now takes six, often spilling into business hours and slowing performance for everyone.
Traditional ETL forces a painful trade-off: you can either have fresh data or a performant production system, but rarely both at the same time. This conflict creates a constant state of operational tension.
Inflexibility in a World of Exploding Data Sources
Today’s data ecosystem is a chaotic mix of databases, SaaS apps, APIs, and event streams. Traditional ETL was born in a much simpler era, when most data lived in a handful of well-behaved relational databases. It was never designed for the sheer variety and velocity of modern data.
Hooking up a new data source often means building a fragile, custom pipeline that’s expensive to create and a nightmare to maintain. The moment a schema changes or an API gets updated, these brittle connections break, forcing already-swamped data teams to drop everything and fix them. This rigidity makes it almost impossible to keep up, turning data integration into a reactive chore instead of the strategic asset it should be.
A Better Way: Streaming Data and CDC

It’s pretty clear that the old ways of moving data just can't keep up anymore. Relying on batch jobs is like getting yesterday's newspaper—by the time you read it, the world has already moved on. Businesses need to operate at the speed of right now, making decisions based on what’s happening, not what happened hours ago.
This is where a modern approach built on two core technologies comes in: streaming data and Change Data Capture (CDC). Think of them as the one-two punch that knocks out the latency, scalability, and system strain caused by legacy data pipelines.
Let’s Talk About Change Data Capture (CDC)
Imagine you’ve hired a hyper-efficient security guard to watch your main database. Instead of doing a full inventory check of the entire warehouse every night (the old batch method), this guard instantly notes every single item that enters or leaves, the second it happens.
That’s basically what Change Data Capture does.
CDC is a technique that keeps an eye on a source database and captures every single row-level change—inserts, updates, and deletes—as they happen. The real magic is how it does this. Instead of hammering the database with heavy queries, CDC quietly reads the database's own transaction logs. It’s like reading a diary the database keeps of every change it makes to itself.
This method is a game-changer for a few key reasons:
- Barely-There Impact: Reading from the logs puts almost no performance strain on your source systems. Your production databases can keep humming along at full speed, completely undisturbed.
- Truly Real-Time: It captures changes the moment they're committed, letting you build data pipelines with latency measured in seconds, not hours.
- Perfect Accuracy: CDC grabs every change. Nothing gets missed between cycles, giving you a complete and granular history of every event.
To really dig into the mechanics of how this works, check out our complete guide on what is Change Data Capture.
The Power of the Data Stream
If CDC is the alert that something just changed, streaming data is the live broadcast that delivers that news across your organization. It’s a constant river of information flowing from your sources to their destinations. This completely replaces the old bucket brigade of traditional ETL, where you’d haul massive batches of water from one point to another.
Data streaming platforms are engineered to handle this continuous, high-volume flow of events. They’re built for a world where data is never "done"—it's always in motion. This makes streaming the perfect partner for CDC. Changes captured by CDC are immediately put into the stream to be processed and delivered on the fly.
The big shift here is moving from a "pull" model, where you have to constantly ask the database for updates, to a "push" model, where the database tells you about changes the instant they happen. This is the foundation of a truly real-time data infrastructure.
From Tech Upgrade to Business Breakthrough
Switching from batch to real-time isn't just a technical detail; it opens up business opportunities that simply weren't possible before. When your data flows continuously, you can stop reacting to the past and start acting in the moment. The applications are everywhere and directly solve the common data integration headaches we've discussed.
Just think about these real-world scenarios:
- Instant Fraud Detection: An e-commerce platform streams transaction data the moment a customer clicks "buy." An AI model can analyze this event in real-time, flag a suspicious purchase, and stop the order before it ships, preventing millions in losses.
- Always-Accurate Inventory: A retailer can sync sales from its point-of-sale systems to warehouse management systems instantly. This means inventory counts are never stale, preventing stockouts and the frustration of a customer ordering an out-of-stock item.
- On-the-Fly Personalization: A marketing team captures a user's clicks on their website and can immediately trigger a personalized offer or recommendation based on what they're doing right now, massively boosting conversion rates.
These modern solutions go straight to the root of the problem, eliminating the bottlenecks in latency and scalability. They deliver the fresh, trustworthy data needed to power the advanced analytics, machine learning, and operational systems that give a business its competitive edge.
A Practical Framework for Your Modern Integration Strategy
Knowing you have a data integration problem is one thing; actually fixing it requires a solid plan. Moving to modern solutions like data streaming and Change Data Capture (CDC) is more than just a tech upgrade—it's a fundamental shift in how your business operates. You need a roadmap to guide you from sluggish, outdated batch processes to a culture built on real-time data.
This isn't about a massive, risky "rip-and-replace" project. Instead, think of this as a step-by-step guide to build momentum, prove value fast, and tie your technology directly to what the business actually cares about. It's your blueprint for finally leaving legacy data headaches behind.
Audit Your Data Ecosystem
Before you can build a better future, you need an honest map of where you are right now. An ecosystem audit is all about identifying every data source, every destination, and all the rickety bridges connecting them. The goal is to find the biggest points of friction—the places where things are truly broken.
Start by asking a few critical questions:
- Where is our most valuable data? Is it locked in a production database, a CRM, or an ERP system?
- Which business operations are choking on stale data? Think about things like fraud detection, inventory management, or customer support.
- What are our most painful data quality bottlenecks? Is it the weekly manual effort to reconcile two systems?
This first step gives you the clarity to focus your energy where it will make the biggest difference, rather than trying to boil the ocean.
Define Clear Business Objectives
With your audit in hand, it’s time to connect the technical fix to a business outcome. Don't just set a vague goal like "implement real-time data." Get specific. For example, a much better objective would be to "reduce fraudulent transactions by 15% by Q3" by streaming payment data directly into a real-time analytics engine.
A modern data strategy succeeds not when the technology is running, but when it measurably improves a core business metric. Tying every integration project to a clear KPI is non-negotiable for getting buy-in and proving your ROI.
This focus on business value immediately changes the conversation. It’s no longer an IT cost, but a strategic investment. It also gives you a clear yardstick to measure success once the new system is live.
Select the Right Tools and Launch a Pilot
The data integration market is booming, with a projected compound annual growth rate (CAGR) of 13.8% by 2025, largely driven by the hunger for real-time analytics. This growth gives you plenty of options, but also a lot of noise to cut through. For a deeper dive, you can learn more about how to build data pipelines with modern tools. The trick is to pick tools that fit your team's existing skills and the scope of your project.
Once you have a potential solution in mind, launch a small-scale pilot project. Choose one of the critical pain points from your audit and apply a real-time solution to just that one problem. A successful pilot does wonders—it builds crucial internal support, proves the value of this new approach, and gives your team hands-on experience before you commit to a wider rollout. This iterative, prove-it-as-you-go process is the safest and fastest way to solve your most urgent data integration challenges.
Real-World Stakes: The Global Impact of Integration

The data integration headaches we’ve talked about go far beyond sales figures and marketing analytics. To really understand what’s on the line, let's pull back and look at a situation where the consequences aren't just lost revenue, but the stability of the entire global economy.
Think about the monumental job facing the world’s central banks. They’re tasked with protecting entire economies by spotting and neutralizing systemic risks. This means they have to make sense of an overwhelming, constant stream of data from thousands of sources to see the next potential crisis before it unfolds.
The Blind Spots in Global Finance
This is where classic data integration problems become a massive roadblock. Every global bank, regulatory body, and market exchange uses its own data standards, its own identifiers, its own way of doing things. It's like trying to build a single, coherent puzzle when every piece is from a different box, cut to a different shape.
This lack of a common language creates enormous blind spots. Regulators can't get a clean, consolidated view of a bank’s total risk exposure when its assets are spread across multiple countries and logged in incompatible systems. In the middle of a crisis, that kind of delay can be absolutely catastrophic.
The inability to seamlessly integrate financial data isn't a minor technical issue; it's a direct threat to global stability. When regulators can't connect the dots in real-time, they are effectively flying blind, unable to see the full picture until it's too late.
The High Cost of Inconsistent Data
Central banks are constantly trying to stitch their internal data together with external market sources to get an accurate risk assessment, but the process is incredibly difficult without harmonized standards. Something as simple as inconsistent ID codes for financial products can make it impossible to link datasets. This leads to more complexity, less efficiency, and a weaker grasp on reality.
Addressing this requires a massive, coordinated effort to build common standards and improve data governance across the board. If you want to dive deeper, you can read more on how financial institutions tackle data integration challenges to see just how big the problem is.
This high-stakes example brings everything into focus. Whether you’re running a business or trying to safeguard an economy, solving data integration problems is absolutely fundamental to gaining clarity, control, and the ability to act decisively.
Frequently Asked Questions
When you start digging into data integration, a lot of questions pop up about the tech, the best approach, and how to actually get it done. Here are some straightforward answers to the questions we hear most often from people ready to solve their data integration headaches for good.
Key Definitions and Starting Points
What's the difference between data integration and ETL?
Think of data integration as the overall goal: getting all your data to work together. ETL (Extract, Transform, Load) is just one way to do that, and it's a bit old-school. It works in big, scheduled batches, which was fine when "fresh" data meant it was from yesterday.
Today, modern integration has moved on to real-time methods like streaming and Change Data Capture (CDC). These approaches are much faster and don't require the disruptive, all-or-nothing batches that traditional ETL relies on.
How do I know if my company has a data integration problem?
You'll feel it more in business pain than in technical alerts. The classic signs are teams arguing over whose report is correct, or people wasting hours every week manually copy-pasting data into spreadsheets to get a simple answer.
If decisions are constantly delayed because you're waiting for data, or you can't get a single, trustworthy view of your customers, you've got an integration problem.
Understanding Modern Solutions
Is Change Data Capture difficult to implement?
It used to be. Not long ago, setting up CDC required a ton of specialized engineering effort. But modern data platforms have completely changed the game.
Today, many tools offer low-code or even no-code connectors for common databases. This makes implementing CDC much more straightforward, freeing up your engineers from building and maintaining fragile, custom pipelines.
The real win with a modern platform is that it handles all the low-level complexity. Your team gets to focus on what to do with the real-time data, not the mechanics of capturing it.
Can I solve these issues without a complete system overhaul?
Yes, and you absolutely should. Good data integration works with your existing systems, not against them.
Technologies like CDC and streaming are designed to plug into the databases and applications you already have. You can get real-time data flowing between them without having to rip and replace everything, which saves a massive amount of time, money, and risk.
Ready to eliminate data latency and build reliable, real-time pipelines? Streamkap uses CDC and streaming to solve your most complex data integration problems, ensuring your data is always fresh, accurate, and available. Get started with Streamkap today.