How to Build Data Pipelines for Real-Time Insights
A practical guide to build data pipelines that deliver real-time insights. Learn modern architecture, CDC, and key tools for robust data integration.
If you're going to build a data pipeline that actually delivers value, you have to think beyond the slow, scheduled batch jobs of the past. The goal is real-time data movement, and the key is using technologies like Change Data Capture (CDC) to stream events from databases and other sources the second they happen. A truly modern pipeline boils down to a source, a processing engine, and a destination, all working in sync to serve up fresh, reliable data for immediate analysis.
Laying the Groundwork for Modern Data Pipelines

Let's be honest, the days of waiting hours—or even a full day—for a data report are over. We're now in a world where instant answers aren't just a competitive edge; they're a basic requirement. This is where the old-school approach of batch processing, which moves data in big, scheduled chunks, just falls flat.
That traditional method introduces huge delays, which means the data you're analyzing is already stale. For a retailer, that might mean not knowing about a stockout until it's too late. For a fintech company, it could mean a critical delay in detecting fraud. To build data pipelines that solve real problems today, you have to shift your thinking from periodic updates to continuous, real-time flows.
Understanding the Core Components
No matter how complex it gets, every modern data pipeline is built on three fundamental pillars. Getting a handle on how they work together is the first step to designing a system that won't fall over.
Here's a quick look at the essential parts of any modern pipeline.
Core Components of a Real-Time Data PipelineComponentPrimary FunctionExample TechnologiesSourcesWhere the data is born. This can be anything from transactional databases to SaaS apps or IoT sensors.PostgreSQL, MongoDB, Salesforce, Kafka, Application LogsProcessing EngineThe brains of the operation. It ingests, transforms, and validates the data as it flows through.Streamkap, Apache Flink, Apache SparkDestinationsWhere the processed, analysis-ready data lands. This is where your BI tools and applications connect.Snowflake, Google BigQuery, Databricks platform, Redshift
As you can see, the architecture is conceptually simple, but the implementation is what matters. The move toward real-time processing has sparked massive growth in this space. The global market for data pipeline tools was valued at around $12.09 billion and is expected to hit $48.33 billion by 2030. That growth is being driven by the relentless demand for faster data to power AI, machine learning, and IoT applications.
Why Real-Time Data and CDC Are Essential
The magic behind this real-time shift is Change Data Capture (CDC). Instead of hammering your database with constant queries to see "what's new?"—a slow and resource-heavy process—CDC hooks directly into the database's transaction log. It captures every single insert, update, and delete as an event, just milliseconds after it occurs.
By treating data changes as a continuous stream of events, CDC allows you to build data pipelines that are not just faster, but also far more efficient and less impactful on your production systems.
This event-driven model is what makes true real-time analytics a reality. Think about an e-commerce platform that can instantly sync inventory across every system the moment a purchase is made. Or a logistics company that can reroute trucks based on live traffic data. Those things are only possible with a pipeline built from the ground up for speed. For a deeper dive, check out our guide on what data pipelines are.
A platform like Streamkap is designed to manage this entire process, taking the headaches out of complex CDC setups and turning them into straightforward workflows. It’s about making sure your pipeline isn't just fast, but also scalable and reliable enough to grow with your business.
Designing a Resilient Pipeline Architecture
Any successful data pipeline project starts with a solid architectural plan. Think of it as your blueprint. It’s what ensures the system can handle the chaos of the real world, from sudden data spikes to unexpected changes in your source tables. Getting this right upfront saves you from massive headaches later on.
The first big decision is picking the right tools for the job. This isn't about chasing the latest trends; it's about matching technology to your actual business needs. For example, a pipeline streaming from a PostgreSQL database for real-time inventory has completely different demands than one pulling user events from MongoDB for product analytics. Your destination, whether it's Snowflake, BigQuery, or something else, needs to directly support the kind of analysis you plan to do.
Choosing Your Architectural Pattern
Once you have a shortlist of tools, you need to decide on an architectural pattern. This choice dictates how your pipeline will be built, maintained, and scaled. The two most common options present a classic trade-off: simplicity versus flexibility.
- Monolithic Architecture: This is your all-in-one, tightly-integrated approach. Ingestion, transformation, and loading are all handled within a single, unified system. It's often quicker to set up and simpler to manage at first, making it a decent choice for smaller teams or straightforward projects.
- Microservices Architecture: Here, the pipeline is broken down into small, independent services. Each service does one thing—like pulling data from a specific source or running one transformation. It's more complex to orchestrate initially, but you get far better scalability and resilience. A failure in one service won't take down the whole system.
The right choice really comes down to your team's skills and where you see the project going. A monolithic design might be perfect for now, but a microservices approach gives you the room to grow and adapt. For a deeper dive, it's worth exploring different data pipeline architectures.
Managing Schema Evolution Gracefully
If I had to name the number one reason data pipelines break, it’s schema drift. This is what happens when the structure of your source data changes—a new column gets added, a data type is altered, or a field is dropped. A rigid pipeline will simply break, halting data flow and wrecking your downstream analytics.
A truly resilient architecture has to see these changes coming and handle them automatically. This is exactly what modern tools like Streamkap are built for. They detect schema changes at the source and automatically propagate those updates to the destination warehouse. That new column in your production database just shows up in Snowflake, no manual DDL required. This keeps your pipeline robust and your data trustworthy.
Building a data pipeline without a plan for schema evolution is like building a house on a shaky foundation. It's not a matter of if it will cause problems, but when. Automated schema handling is a non-negotiable for any serious data operation.
This kind of forward-thinking design is part of the broader move toward cloud-native systems. Today, cloud-native is the default for any organization that needs to move fast and scale. In fact, over 65% of organizations are now adopting cloud-native pipeline architectures, ditching their old, inflexible on-prem setups. This shift is all about managing explosive data growth and enabling real-time insights.
The results speak for themselves. Teams that get this right report 40-60% time savings on data preparation and see a return on investment between 150-250%.
Ultimately, a well-designed architecture is your best defense against data downtime. By carefully selecting your tools, choosing the right pattern, and building in automated schema management, you create a resilient system that delivers reliable, timely data to the business.
A Hands-On Guide to Building with Streamkap
Theory is great, but the real learning starts when you roll up your sleeves and actually build something. This guide is all about that—a practical, step-by-step walkthrough for creating your first real-time data pipeline with Streamkap. We're going to connect a source, fire up Change Data Capture (CDC), and get that data streaming straight into a destination like a data warehouse.
Forget the abstract concepts. We're getting into the specific configurations and best practices I've seen work time and again. You’ll learn how to handle credentials securely and even transform data on the fly, making sure it lands clean and ready for analysis the moment it arrives.
Connecting Your First Data Source
Every pipeline starts at the source. This is where your data lives, whether it's a trusty transactional database like PostgreSQL, a NoSQL workhorse like MongoDB, or even a SaaS app. The good news is, Streamkap makes this initial connection surprisingly simple.
You'll just pick your source type from the dashboard and plug in the connection details—the usual suspects like host, port, database name, and credentials.
My advice: Always create a dedicated, read-only user for this. Give it the absolute minimum permissions needed. This is a crucial security step that also ensures you won't accidentally impact your production database.
This initial process of mapping out sources and destinations is a core part of pipeline design, as shown below.
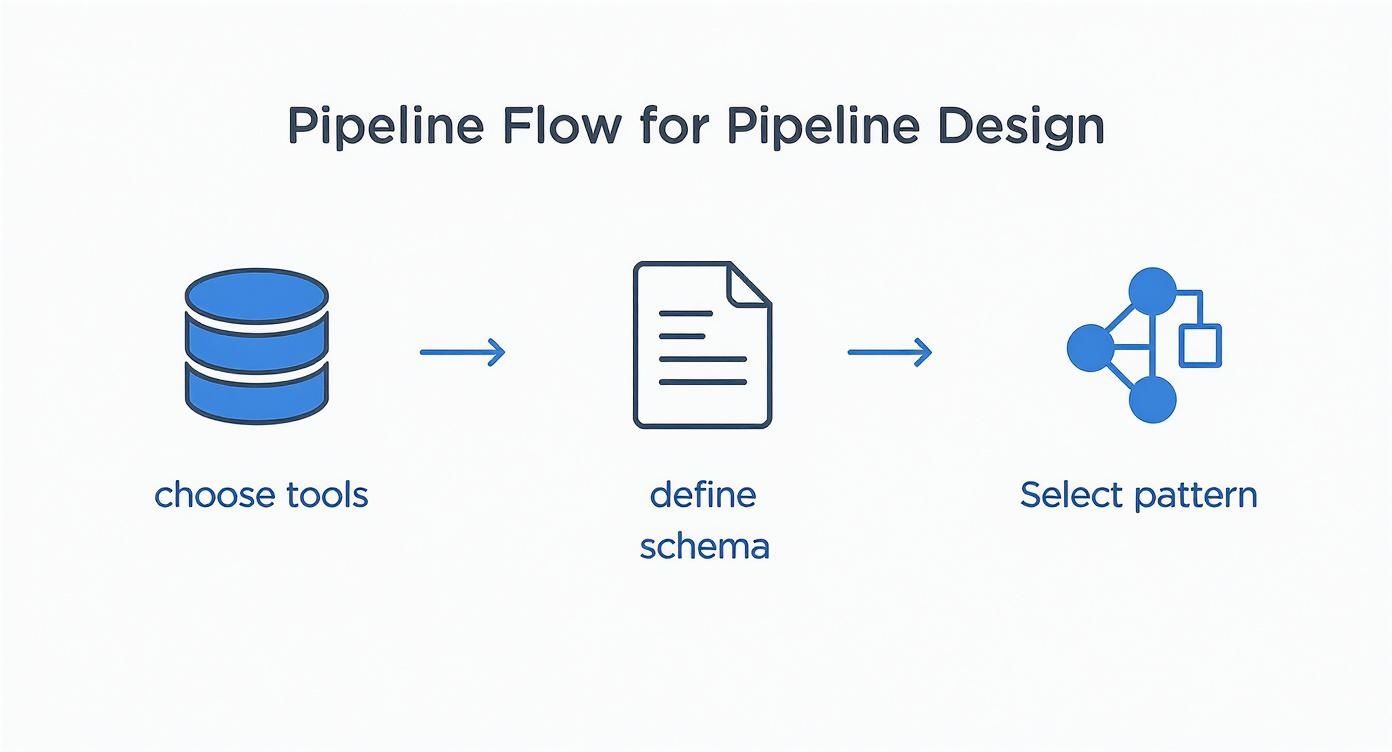
As you can see, a solid plan means choosing your tools, defining the schema, and picking the right architecture before you start building.
Enabling Change Data Capture
With your source connected, it's time for the real magic: enabling CDC. This is the technology that lets us capture every single row-level change—inserts, updates, and deletes—as it happens. No more clunky, inefficient batch queries. Streamkap taps directly into the database’s native replication tools, like PostgreSQL's logical replication.
Activating CDC usually just takes a few minor tweaks on the source database itself to let it stream its transaction logs.
- For PostgreSQL: You'll need to set
wal_level = logicalin your configuration file. This tells Postgres to add enough detail to its write-ahead log for logical decoding to work. - For MySQL: You have to enable binary logging (
binlog). Make surebinlog_format = ROWis set and that the server has a uniqueserver-id. - For MongoDB: Streamkap uses the replica set oplogs, which are almost always enabled by default in a production-grade replica set.
These changes are small but absolutely essential for creating a low-impact, real-time stream of data.
Configuring Transformations and Destination
Now that the data is flowing, you can decide how to shape it before it even reaches its destination. Streamkap lets you apply transformations in-flight, which is way more efficient than dumping raw data into your warehouse and cleaning it up later.
For instance, you can:
- Mask sensitive data: Easily anonymize columns with PII (Personally Identifiable Information) like names or emails to stay compliant.
- Filter out noisy tables: Only sync the specific tables you actually need for analysis. This cuts down on storage costs and clutter.
- Restructure JSON: Flatten those messy nested JSON objects into a clean, columnar format that's a dream to query in warehouses like Snowflake or BigQuery.
The ability to transform data mid-stream is a game-changer. It means the data landing in your warehouse isn't just fresh—it's immediately usable. That drastically shortens the time-to-insight for your analytics teams.
Finally, you'll connect your pipeline to a destination. The process is a lot like the source setup; you just provide the credentials for your data warehouse or lakehouse. Streamkap takes it from there, automatically creating tables that match the source schema and handling any future schema changes without you having to lift a finger.
For a more in-depth look, you can follow our complete guide to getting started with the Streamkap set up. This process ensures your data pipeline stays robust and low-maintenance, even when your source applications change.
How to Ensure Pipeline Reliability and Data Quality

When you first get a data pipeline up and running, it's easy to celebrate. Getting data from point A to point B feels like a huge win. But the real work, the stuff that separates a hobby project from a mission-critical system, starts right after you go live.
A pipeline that isn't reliable or pumps out bad data is worse than useless—it's actively harmful. It can lead to terrible business decisions, tank everyone's trust in your analytics, and bury your team in a mountain of maintenance tickets.
Keeping your pipeline healthy and your data trustworthy isn't about perfection. It's about building a resilient system that can handle the messiness of the real world, from unexpected null values to downstream API outages. That takes a solid strategy for testing, monitoring, and handling errors.
Automated Data Validation and Testing
The best way to keep your data clean is to catch problems before they ever make it to your analysts. Trying to do this manually is a fool's errand at scale, which is why automated data validation is a non-negotiable part of any serious pipeline. This means setting up programmatic checks that run constantly as data flows through the system.
Think of it as building guardrails for your data. These checks can look for all sorts of issues to protect data integrity.
- Null Checks: A classic, but incredibly effective test. Flag any records where critical fields—like a
user_idortransaction_amount—are mysteriously empty. - Format Validation: Make sure data looks the way it's supposed to. A
phone_numbercolumn, for example, should always contain something that actually resembles a phone number. - Range Checks: Sanity-check your numbers. If an
agefield shows a value of 200, something is clearly wrong and you need to know about it immediately. - Uniqueness Tests: You need to trust your primary keys. This test confirms that unique identifiers are, in fact, unique across the dataset.
These tests are your first line of defense, an early warning system that stops garbage data from polluting your warehouse and derailing your analytics.
Proactive Monitoring and Alerting
You can't fix problems you don't know about. This is where good monitoring comes in, giving you a real-time pulse on your pipeline's health. It’s the key to shifting from a reactive "break-fix" cycle to a proactive maintenance mindset. Instead of waiting for a frustrated user to report a broken dashboard, your team gets an alert the second a key metric goes sideways.
A data pipeline without monitoring is a black box. You're just crossing your fingers and hoping everything is working, which is a recipe for disaster. Real-time visibility into key health metrics is the only way to build and maintain trust in your data infrastructure.
For a streaming pipeline built with a tool like Streamkap, you'll want to keep a close eye on a few crucial metrics:
- Latency: How long does it take for a source change to show up in the destination? If latency suddenly spikes, you might have a bottleneck in your processing engine or an issue with the destination warehouse.
- Throughput: How many records or events are you processing per second? A sudden drop could point to a problem at the source, while a huge, sustained increase might mean it's time to scale up your resources.
- Error Rate: What percentage of your records are failing during transformation or loading? Tracking this helps you zero in on bugs, whether it’s a schema mismatch or a data type conflict.
Tools like Datadog or Prometheus are perfect for this. You can set up dashboards and configure alerts that ping your team on Slack or via email the instant a threshold is breached.
Designing a Solid Error Handling Plan
Look, things are going to break. Networks drop, APIs time out, and malformed data will inevitably find its way into your stream. A truly resilient pipeline isn't defined by its ability to avoid failure, but by how gracefully it recovers. A rock-solid error-handling and recovery plan is essential when you build data pipelines that people depend on.
This means deciding ahead of time what happens when an error occurs. For fleeting issues like a temporary network hiccup, an automated retry mechanism with an exponential backoff is usually the right call. But for more stubborn problems, like a record that keeps failing validation, the pipeline should shunt that data to a dead-letter queue (DLQ). This simple trick prevents one bad apple from spoiling the whole batch, allowing you to investigate and reprocess the faulty record later without data loss.
This modern approach to building resilient systems is backed by broader industry trends. For instance, 84% of organizations are expected to use container orchestration platforms like Kubernetes to automate scaling and improve deployment consistency. Similarly, 71% of organizations now have formal data governance programs, reflecting the growing importance of data quality. You can explore more big data statistics and insights to see how these trends are shaping the field.
Keeping Your Data Pipeline Humming at Scale
So, you've built your pipeline. It’s live, data is flowing, and stakeholders are happy. Mission accomplished, right? Not quite. Now comes the real challenge: making sure it can handle success.
What works for a thousand events per minute can quickly fall apart when that number jumps to a million. A pipeline that was once a lean, mean, data-moving machine can morph into a slow, costly bottleneck. The trick is to shift your mindset from "just get it working" to continuous, smart optimization. This isn't about throwing more money or hardware at the problem; it's about being strategic.
Fine-Tuning for Higher Throughput
When your data volume starts to spike, tiny inefficiencies you never noticed before suddenly become major performance killers. The first place I always look is the configuration of the streaming connectors and the jobs processing the data.
For example, take a look at the batch size and flush intervals on your connectors. Increasing the batch size means you’re writing to your destination in larger, more efficient chunks. This boosts throughput, but it might add a few milliseconds of latency. You have to find that sweet spot that works for your specific needs.
Another critical area is how you allocate resources. If you're using a managed platform like Streamkap, which is built to handle this, you can often scale your resources up or down on the fly. Keep a close eye on your CPU and memory usage during peak hours. Those metrics are your early warning system, telling you when it's time to add more muscle before backlogs start to pile up.
My Two Cents: Don't just think vertically (bigger machines). True scalability often comes from thinking horizontally. By partitioning your data stream on a key like customer_id, you can split the workload across multiple parallel workers. This is a much more robust and effective way to handle massive volumes than just relying on a single, super-powered instance.
Getting Smart with Costs and Resources
Scaling shouldn't mean getting a heart-stopping bill from your cloud provider at the end of the month. The key to avoiding this is to be proactive about cost management, not reactive.
Start by picking the right instance types and getting aggressive with auto-scaling. Overprovisioning "just in case" is a recipe for wasted money. Instead, use your monitoring dashboards to figure out a baseline for your pipeline's resource needs. Once you have that, you can set up auto-scaling rules that add capacity during traffic spikes and—this is the important part—spin it back down when things are quiet. You only pay for what you use.
Cost optimization doesn't stop at the pipeline, either. It extends all the way to your data warehouse, where sloppy queries can burn through your budget in a hurry. This is where a little bit of foresight in how you organize your data can pay massive dividends.
Why Smart Data Partitioning is a Game-Changer
If there's one optimization technique that delivers the most bang for your buck, it's data partitioning in your destination warehouse, whether that's Snowflake or BigQuery. Think of partitioning as creating a hyper-efficient filing system for your data. Instead of dumping everything into one massive table, you physically group related data based on a column—usually a date or timestamp.
The magic happens when someone runs a query.
Let's say an analyst queries for data from a specific day (WHERE event_date = '2023-10-26'). The query engine already knows where to look. It completely ignores all the other partitions and scans only the tiny slice of data it actually needs.
The benefits here are huge:
- Dramatically Faster Queries: Results come back in seconds, not minutes, because the engine isn't sifting through irrelevant data.
- Lower Warehouse Bills: Most cloud warehouses charge you based on the volume of data scanned. Less data scanned means lower costs. Simple as that.
Implementing partitioning is a relatively small change that delivers enormous wins for both performance and your bottom line. As your datasets grow into terabytes and petabytes, it's not just a nice-to-have; it's an absolute necessity for building a cost-effective, long-term data platform.
Frequently Asked Questions About Data Pipelines
As you get your hands dirty building data pipelines, you'll find that some questions pop up over and over again. Here are some straightforward answers to the common challenges I've seen teams face, focusing on what you actually need to know to get things done.
What Is the Difference Between ETL and ELT?
The big difference between ETL (Extract, Transform, Load) and ELT (Extract, Load, Transform) is simply when you transform the data. It sounds like a minor detail, but it completely changes your architecture.
- ETL (Extract, Transform, Load): This is the classic way of doing things. You pull data from a source, clean it up and reshape it on a separate server, and then load the finished, structured data into your warehouse.
- ELT (Extract, Load, Transform): This is the modern, cloud-first approach. You just dump the raw data directly into a powerful cloud data warehouse like Snowflake or Google BigQuery. All the heavy lifting of transformation happens right inside the warehouse, using its massive processing power.
Then there’s a third option, streaming ETL, which is what platforms like Streamkap do. It transforms data while it's in motion, meaning only clean, ready-to-use data ever lands in your warehouse. This is great for keeping things fast and your storage costs down.
The rise of powerful cloud data warehouses has made ELT incredibly popular. By loading raw data first, you give yourself the flexibility to run all sorts of different transformations later on without ever having to pull the data from the source again.
How Should I Handle Unexpected Schema Changes?
Schema drift is a classic pipeline killer. A developer adds a new column, changes a data type, or removes a field without telling anyone, and boom—your carefully built pipeline grinds to a halt.
Honestly, the best way to deal with this is to use tools that expect it to happen. Modern data platforms are built to automatically detect schema changes at the source and just roll with them. For example, if someone adds a last_login_ip column to your users table, a resilient pipeline will see that change and immediately add the corresponding column in Snowflake for you. No downtime, no frantic late-night fixes.
How Do I Choose Between Batch and Streaming Pipelines?
Deciding between batch and streaming really just boils down to one question: how fresh does your data need to be to be useful?
Think about what you're trying to accomplish:
- Batch processing is totally fine for things that aren't urgent. Think end-of-day sales reports or a weekly summary of user activity. It's designed to move big chunks of data on a regular schedule.
- Streaming processing is a must-have when you need to react to data in seconds. This is the world of real-time fraud detection, live inventory tracking, or operational dashboards where old data is useless data.
For most modern applications, a streaming-first approach using Change Data Capture (CDC) is the way to go. It gives you the freshest data possible with almost no performance hit on your source systems.
What Are the Most Common Pipeline Performance Bottlenecks?
When you’re building pipelines that need to handle serious volume, you're going to run into performance issues. It’s not a matter of if, but when. In my experience, the bottlenecks almost always show up in a few key places.
First, look at your data ingestion method. If you’re still hammering your source database with constant queries to check for new records, you're creating a massive performance drag. That alone is a compelling reason to switch to log-based CDC.
Next up, check your transformation logic. Trying to run complex joins or heavy aggregations on an undersized processing engine is a recipe for backlogs. You need to make sure your processing layer can scale up when traffic spikes.
Finally, don't forget the destination warehouse. Little things can bring everything to a crawl. Are you writing data row-by-row instead of in optimized micro-batches? Are your biggest tables properly partitioned so queries don't take forever? Getting your monitoring in place is the only way you'll spot these problems before your users do.
Ready to build data pipelines that are fast, reliable, and don't require constant babysitting? Streamkap uses real-time CDC to replace slow batch jobs with an efficient, event-driven architecture. See how you can get started.