Real Time Processing vs Batch Processing A Guide to Data Strategy
Explore the differences in real time processing vs batch processing. This guide covers use cases, architecture, and cost to help you choose the right approach.
The simplest way to think about the difference is this: batch processing is like running a massive payroll job overnight, while real-time processing is like getting an instant fraud alert on your credit card. One is about handling huge volumes on a schedule; the other is about acting on data the second it’s created. The right choice hinges on whether your business can wait for historical analysis or needs to react in the moment.
Understanding the Core Differences in Data Processing
Choosing between real-time and batch processing is a fundamental decision in data architecture. Each approach is built for different business goals and has its own operational quirks. Getting this choice right is the first step toward a data strategy that actually works.
Batch processing is the old guard of the data world. Think of it like a librarian who collects all the returned books throughout the day and then sorts and shelves them in one big, efficient push after closing. It works by collecting data over a set period—the "batch window"—and then running a single, scheduled job to process it all.
This method has been a data management staple for decades, dating back to the 1960s with mainframe systems like IBM's OS/360 running enormous inventory and accounting jobs. It's far from obsolete; a 2023 report found that 70% of enterprise data analytics still leans on batch methods. In banking, for instance, over 80% of daily transactions are still processed in nightly batches. You can read more about the evolution of production data processing for deeper context.
On the flip side, real-time processing (often called stream processing) deals with data as it flows in. It’s more like a security guard watching a live camera feed, ready to respond to an event the instant it occurs. This is the approach for use cases where every second counts.

The image above nails the core concept: batch systems collect and queue data to be processed together, prioritizing sheer throughput over speed.
Quick Comparison Real Time vs Batch Processing
To really grasp the trade-offs at play when deciding between real-time processing and batch processing, it helps to see their core characteristics side-by-side.
This table cuts right to the chase. Batch is your workhorse for massive jobs where you can afford to wait. Real-time is essential for systems that need to know and act now. Your specific business needs will ultimately determine which approach—or, more often, which combination of the two—is the right fit for your architecture.
A Look at Architectural Patterns and Key Technologies
To get to the heart of the real-time processing vs. batch processing discussion, you have to look under the hood at their architectural designs and the tools that make them tick. Each approach is built on a completely different philosophy, which in turn defines how data moves from point A to point B and which technologies are right for the job. These foundational differences are precisely why one is a workhorse for massive, scheduled jobs and the other is built for instant, event-driven responses.
The image above nails this contrast. Batch processing is a straightforward, step-by-step march, while real-time processing is a constant, unending flow.
The Foundation of Batch Processing: ETL and Data Warehouses
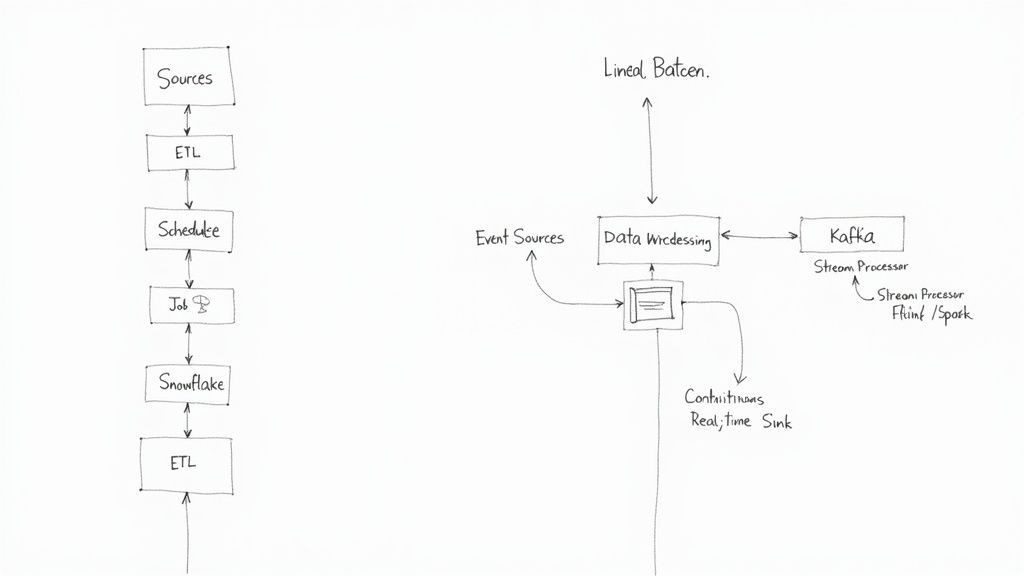
The classic architecture for batch processing is ETL (Extract, Transform, Load). It’s a tried-and-true pattern that lays out a clear, three-step workflow, usually running on a fixed schedule like nightly or hourly.
- Extract: Data is pulled in large chunks from various source systems—think databases, CRMs, or application log files.
- Transform: All that raw, messy data gets cleaned up, validated, aggregated, and reorganized into a structured format perfect for analysis.
- Load: The newly polished data is loaded into a final destination, which is almost always a data warehouse.
The entire process is engineered for efficiency with massive volumes of data, prioritizing throughput over low latency. It’s the data world’s equivalent of a factory assembly line, where raw materials are processed in large, predictable batches.
The key technologies in the batch world were built for this very purpose. Apache Hadoop and its MapReduce framework became legendary for chewing through petabytes of data across huge clusters. Today, modern cloud data warehouses like Snowflake and Google BigQuery have taken this model to the next level, providing incredible storage and compute power for running complex analytical queries on enormous datasets.
Real-Time Architectures: Event-Driven Systems and Streaming
Real-time processing works on a completely different principle: an event-driven architecture. Instead of waiting around for a scheduled job to kick off, the system reacts to events as they happen—a user clicking a button, a sensor transmitting a reading, or a record changing in a database. This demands a pipeline that is "always on" and ready to process data continuously.
A cornerstone of modern real-time systems is Change Data Capture (CDC). CDC is a technique that sniffs out changes made to data in a database and immediately streams those changes to other systems. This approach completely sidesteps the need for inefficient, resource-heavy bulk queries and gives you a low-latency feed of every single update.
Key Insight: CDC essentially turns your databases from static archives you query on a schedule into live, streaming sources of truth. This is the fundamental shift that makes true real-time analytics possible without hammering your production systems.
The tech stack for streaming is all about speed and low latency. Apache Kafka has become the industry-standard backbone for real-time data pipelines, acting as a central nervous system that can reliably handle trillions of events a day. From there, processing frameworks like Apache Flink and Spark Streaming consume these event streams to run calculations, aggregations, and transformations in flight.
This potent combination of CDC, Kafka, and a stream processor creates a powerful, uninterrupted flow of information. It's what allows a business to analyze and react to what's happening in milliseconds, not hours. Newer patterns like the Kappa architecture have even emerged to simplify these pipelines. For a deeper dive, you can explore the evolution from Lambda to Kappa architecture in our comprehensive guide.
Ultimately, the choice between these architectures comes down to a simple question: can your business afford to wait for insights, or do you need to act on them right now?
Latency, Throughput, and Cost: Analyzing the Trade-Offs
Choosing between batch and real-time processing isn't just a technical decision; it's a fundamental business trade-off between speed, scale, and budget. Each approach forces you to prioritize one aspect over the others, directly shaping your operational capabilities and financial outlay. Getting this right is about building a data strategy that delivers real value without breaking the bank.
The most dramatic difference between the two is latency—the time it takes for data to go from creation to insight.
Batch processing, by design, has high but predictable latency. Data piles up over a set period—minutes, hours, or even a full day—before being processed in one large, scheduled job. This built-in delay is a feature, not a bug, making it a perfect fit for tasks like end-of-day financial reporting or monthly inventory analysis where immediate results aren't necessary.
Real-time processing, on the other hand, is all about ultra-low latency. It's engineered to act on data within milliseconds or seconds of its arrival, enabling immediate responses. This is non-negotiable for use cases like fraud detection, where a few seconds of delay could translate into significant financial loss. The right choice here really hinges on your business's tolerance for data staleness. For a deeper look into the mechanics of speed, explore our detailed guide on how to reduce latency in data systems.
Juggling Throughput and Data Volume
While latency is about speed, throughput is all about scale—the total amount of data a system can process in a given period. And here, the advantages flip.
Batch systems are the undisputed champions of high-volume throughput. They are built to efficiently chew through massive datasets, often on the scale of terabytes or petabytes. By scheduling these intensive jobs during off-peak hours, you can process enormous amounts of historical data without disrupting daily operations. This makes batch the go-to for large-scale analytics and training machine learning models.
Real-time systems are optimized for high-velocity data streams, not sheer volume. They are built to handle a continuous, unending flow of individual events, but processing huge historical datasets all at once isn't what they're for. Think of it as the difference between a massive cargo ship (batch) and a fleet of speedboats (real-time). One moves more total goods over time, while the other excels at rapid, continuous delivery.
The Core Trade-Off: Batch processing sacrifices low latency to achieve massive throughput. Real-time processing accepts a lower per-job data volume to deliver sub-second latency. The right choice depends on whether your business value comes from deep analysis of historical data or immediate reaction to current events.
The Nuanced Economics of Cost
Cost is often the most complex—and decisive—factor in the batch vs. real-time debate. The financial models for each are fundamentally different, reflecting their distinct operational demands.
Batch processing is generally more cost-effective from an infrastructure perspective. Its resource consumption is cyclical; it spikes during scheduled jobs and then drops to near zero. This allows organizations to optimize compute costs by only paying for resources when they are actively processing data.
Real-time processing requires an "always-on" infrastructure. Since the system must be ready to process data at any moment, servers and processing engines run continuously. This leads to a consistent, and often higher, operational expenditure. That constant readiness is essential for low latency, but it comes at a premium.
This section provides a high-level overview of the trade-offs. The table below breaks down these factors in more detail to help guide your decision-making process.
Trade-Off Analysis: Batch vs. Real-Time Processing
A 2023 Forrester analysis highlights this economic divide, noting that batch processing can reduce expenses by 60-80% for large-scale operations by allowing resources to remain idle 90% of the time. Conversely, Netflix's real-time streaming analytics on Apache Flink reportedly costs $50 million annually—a necessary expense to power a recommendation engine that boosts user retention by 75%.
Ultimately, the decision isn't about which is cheaper overall, but which model provides the best return on investment for a specific business need. While batch offers predictable, lower-cost efficiency for historical analysis, real-time delivers immediate value that can generate revenue or prevent losses, justifying its higher continuous cost.
Real-World Use Cases for Each Processing Model
Knowing the technical specs of real time processing vs batch processing is one thing. Seeing where they actually make a difference in the real world is another. The right choice isn't just a technical preference; it's about matching the processing model to a business problem where timing and data volume are everything.
Some operations are all about efficiency over long periods, while others live or die by their ability to react in seconds. Let's look at some practical examples that show why a certain latency or throughput isn't just a nice-to-have—it's fundamental to getting the job done.
When Batch Processing Is the Right Choice
Batch processing is the workhorse for scenarios where you need to chew through massive amounts of data and can afford to wait for the results. It's the engine running behind the scenes for many core business functions that don't require instant feedback.
Here are a few classic examples:
- End-of-Day Financial Reporting: Think about a major bank. It handles millions of transactions every single day. When the market closes, massive batch jobs kick off to reconcile accounts, calculate final balances, and generate daily reports. Speed isn't the priority here; absolute accuracy and completeness are.
- Corporate Payroll Systems: A company with thousands of employees doesn't calculate paychecks every second. Instead, the payroll system gathers timesheets, benefits info, and tax data over a set period—say, two weeks or a month. Then, it runs one enormous batch job to process everything at once.
- Large-Scale Data Analysis: When you need to analyze historical information, batch is often the way to go. This includes tasks like backtesting strategies against years of market data. In scientific fields like genomics, researchers process huge datasets to find patterns, a job perfectly suited for scheduled, high-throughput batch runs.
The common thread here is that the business value comes from a comprehensive, deep analysis of a large, complete dataset. A delay of a few hours—or even a full day—is perfectly fine because the goal is historical accuracy, not a knee-jerk reaction.
Where Real-Time Processing Delivers Crucial Value
Real-time processing becomes essential when the value of data plummets with every passing moment. For these applications, the ability to act on new information within milliseconds isn't just a competitive edge; it's the entire point.
This is the approach that powers some of today's most dynamic digital experiences and critical security systems.
Key Real-Time Scenarios:
- Instant Fraud Detection: The moment you swipe your credit card, a real-time system is already analyzing the transaction. It checks your spending habits, location, and other risk factors in milliseconds. If something looks off, the transaction is declined before it's completed, stopping fraud in its tracks. A batch system would only catch it hours later, long after the money is gone.
- Live E-commerce Personalization: E-commerce giants are watching every click, search, and mouse hover. This data streams directly into processing engines that instantly tweak product recommendations or adjust prices on the fly. This is how you get a shopping experience that feels uniquely tailored to you.
- Real-Time Patient Monitoring: In a hospital, wearable devices and sensors stream patient vital signs to a central monitoring system. Real-time processing allows medical staff to get immediate alerts for critical events, like a sudden drop in heart rate, enabling them to intervene and save lives.
The rise of real-time processing is directly linked to the explosion of IoT devices. Look at autonomous vehicles: Tesla's fleet logs 1.3 petabytes of data daily through real-time streams. This data allows for over-the-air updates that have helped slash accidents by 40% since 2019.
Likewise, Amazon's real-time personalization, which analyzes customer clicks within 100 milliseconds, is credited with driving 35% of its sales. That’s a result you simply can't achieve with a dashboard that only refreshes once a day.
How to Choose the Right Data Processing Strategy
Deciding between real-time and batch processing isn't a simple technical choice—it's a business decision. Forget a generic pro/con list. The right answer comes from digging into your operational needs, your budget, and how much a delay in data really costs you.
Honestly answering a few key questions will point you to the right architecture. This ensures you're building a system that delivers genuine value, not just running up a cloud bill.
Key Questions for Your Decision Framework
Before you commit to a specific data stack, run through these questions with your team. They’re designed to shift the focus from abstract technical features to real-world business impact.
- What's the business cost of stale data? If a few hours or even a full day’s delay doesn’t hurt the bottom line, batch processing is a perfectly smart and cost-effective choice. But if that delay means losing a sale, failing to stop fraud, or making a bad trade, then you absolutely need real-time processing.
- What does your data flow look like? Batch systems are workhorses, built to chew through massive, predefined datasets on a schedule. Real-time systems, on the other hand, are designed for the opposite: a never-ending, high-speed flow of individual events.
- What’s your budget for infrastructure? Real-time systems are "always on," which means a constant, predictable operational cost. Batch processing is often cheaper because it spikes resource usage only during scheduled runs, then goes quiet.
- How critical is perfect consistency? Batch processing shines when you need a single, rock-solid, consistent view of a huge dataset. Real-time systems often make a slight trade-off, prioritizing speed and availability, which sometimes means dealing with eventual consistency.
This flowchart boils the entire debate down to its most fundamental question: How fast do you need to know?
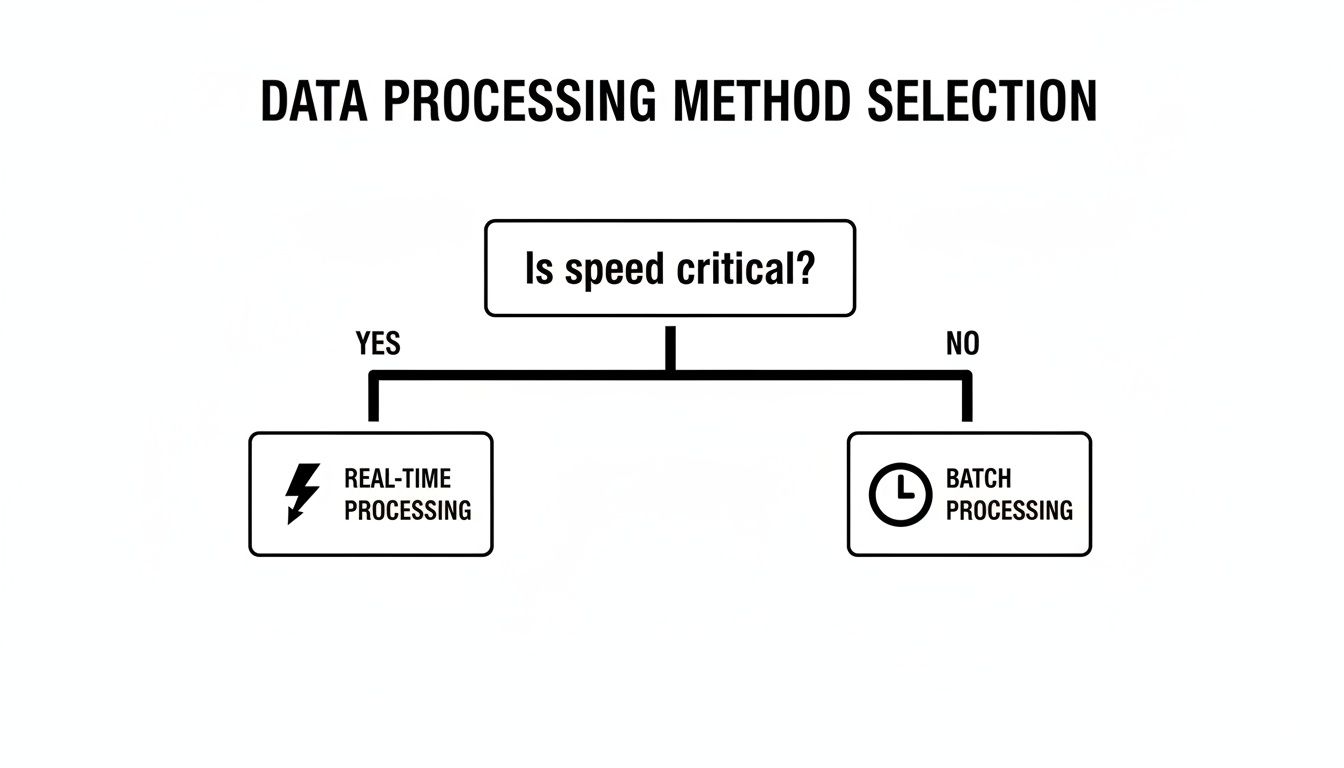
If your data loses its value by the second, real-time is the only way to go. Otherwise, the sheer efficiency of batch processing often wins out.
Considering Hybrid Architectures
It's rarely a black-and-white decision. The truth is, many of the most effective data platforms are actually a hybrid of both. For companies exploring how to get the most out of their data, looking into strategies like automating business processes with AI vs. RPA can reveal where different processing speeds are needed.
Two common hybrid patterns you'll see in the wild are the Lambda and Kappa architectures.
The Lambda architecture runs two parallel pipelines: a batch layer that provides a comprehensive, super-accurate view of all historical data, and a speed layer for immediate insights on incoming data. The Kappa architecture streamlines this by treating everything as a single stream, handling both real-time and historical replays with one processing engine.
These models exist because most businesses have different data needs across different departments. An e-commerce platform is a classic example: they'll use real-time processing for things like live fraud detection and dynamic product recommendations, but stick with batch processing for their end-of-day sales reports and weekly inventory forecasting.
By mapping your business needs to these core trade-offs, you can build a data strategy that's a true asset—one that directly supports your goals instead of just being another line item on the IT budget.
How Streamkap Makes Real-Time Adoption Practical
The jump to real-time processing is incredibly appealing, but let's be honest—the implementation can be a beast. Building and maintaining streaming pipelines from scratch demands deep, specialized knowledge in tricky technologies like Change Data Capture (CDC) and Apache Kafka. For most engineering teams, this creates a massive barrier to entry.
That's precisely the problem Streamkap was designed to solve.
We offer a managed platform that completely removes the operational headache of building real-time data pipelines. Instead of your team burning months just getting the infrastructure right—wrangling Kafka clusters and CDC connectors—they can focus on what actually matters: delivering business value. This completely changes the equation, slashing engineering overhead and getting your real-time applications to market faster.
From Months of Manual Work to a Pipeline in Minutes
Let’s take a common scenario: you want to build a real-time analytics dashboard in Snowflake that’s fed directly from your production PostgreSQL database. If you try to build this yourself without a managed service, you're in for a long and difficult project.
A typical DIY setup looks something like this:
- Wrestling with CDC: You’d have to configure a tool like Debezium to capture database changes, a delicate process where one wrong move could hammer your source system.
- Taming Kafka: Next, you need to deploy, secure, and scale a Kafka cluster to manage the event stream. This isn't a "set it and forget it" task; it requires significant operational expertise.
- Coding Custom Consumers: You'll need to write and maintain custom code that pulls data from Kafka, gracefully handles any schema changes, and reliably loads everything into Snowflake.
- Praying for Scalability: The entire pipeline needs constant monitoring to manage performance, ensure it’s fault-tolerant, and scale as your data volume inevitably grows.
Honestly, running this kind of pipeline is a full-time job for a dedicated data engineering team.
The Streamkap Advantage: We abstract away the brutal complexity of Kafka and Flink. What was once a multi-month engineering nightmare becomes an automated workflow you can configure in just a few minutes.
With Streamkap, that same pipeline is almost trivially simple to set up. You connect your PostgreSQL source and your Snowflake destination in our UI, and that's pretty much it. The platform automatically handles the CDC, schema evolution, and data transformations, ensuring a reliable data flow with sub-second latency.
This means you can get real-time capabilities without hiring a specialized infrastructure team. You can see how Streamkap’s product features make this happen.
This approach doesn't just make the move from batch to real-time more accessible; it also guarantees your pipelines are scalable and resilient right out of the box. By eliminating the technical roadblocks, you can start using your data for immediate insights and finally shift from analyzing the past to making decisions in the now.
Common Questions About Data Processing
As you weigh the pros and cons of real-time vs. batch processing, a few key questions usually pop up. Let's tackle them head-on to clear up any lingering confusion and help you map out your data strategy.
When Does a Hybrid Approach Make Sense?
A hybrid model is the way to go when a one-size-fits-all approach just won't cut it. Think about an e-commerce company: they absolutely need real-time processing for things like fraud detection and live inventory tracking. You can't have a customer buy an out-of-stock item.
At the same time, that same company runs end-of-month financial reports and analyzes years of sales data to spot trends. Those tasks are perfect for batch processing. Mixing both lets you use the right tool for the right job, keeping costs down by not forcing everything into a pricey real-time pipeline when it's not needed.
How Do AI and Machine Learning Fit In?
The explosion of AI and machine learning has actually made both processing models more critical than ever. It's a two-sided coin:
- Training Models: Building a sophisticated ML model is a classic batch processing job. You're feeding it enormous historical datasets, a computationally massive task that doesn't need to happen in the blink of an eye.
- Making Predictions: Once that model is live, it needs to generate predictions on new data—fast. This is where real-time processing shines. An AI recommendation engine on a shopping site, for example, has to serve up relevant products in milliseconds based on what a user is clicking on right now.
As AI becomes standard, your data infrastructure has to be a dual threat: capable of handling huge batch training jobs and delivering the low-latency performance needed for real-time predictions.
Is Batch Processing on Its Way Out?
Not a chance. Batch processing isn't dying; it's just getting more specialized. While real-time gets all the glory for powering flashy, instant applications, batch remains the undisputed champion for large-scale data workloads where speed isn't the primary concern.
Think about core business functions like payroll, customer billing, or populating a massive data warehouse. None of these require sub-second latency. For these foundational operations, batch processing delivers unmatched throughput and cost-effectiveness. It's not about one replacing the other—it's about knowing when to use each. Batch will remain the workhorse for historical data analysis for a long time to come.
Ready to stop wrestling with complex infrastructure and unlock the power of real-time data? Streamkap provides a fully managed, automated platform that simplifies Change Data Capture (CDC) and streaming pipelines, allowing you to move from batch to real-time in minutes, not months. See how you can accelerate your data strategy by visiting the Streamkap website.