9 Data pipelines examples You Should Know
Discover the top 9 data pipelines examples strategies and tips. Complete guide with actionable insights.

Data pipelines are the backbone of modern data-driven organizations, serving as automated systems that move data from source to destination. While the concept seems straightforward, the real value lies in the architectural decisions, technology choices, and strategic goals that shape their design. Understanding how leading companies build these systems provides a powerful blueprint for your own projects. This article moves beyond theory to provide a deep dive into specific, real-world data pipelines examples.
Instead of offering surface-level descriptions, we will dissect the “how” and “why” behind each implementation. You will get a behind-the-scenes look at the business challenges, architectural patterns, and technology stacks used by companies like Netflix, Spotify, and Uber. Each example is structured to deliver actionable insights, highlighting the specific strategies and tactics that led to their success.
By analyzing these proven models, you will gain a practical understanding of:
- Batch vs. Streaming: When to use each processing method for maximum impact.
- Technology Stacks: Why certain tools (like Kafka, Flink, or Lambda) were chosen for specific use cases.
- Scalability & Reliability: Architectural principles that ensure data integrity and performance at scale.
This curated list is designed for data engineers, architects, and technical leaders looking for replicable strategies to solve complex data challenges. Let’s explore these powerful data pipelines examples.
1. Netflix Real-time Data Pipeline
Netflix’s massive scale necessitates one of the most sophisticated data pipelines examples in the world. Their system processes immense data volumes daily to enhance user experience, monitor service health, and inform critical business decisions. It’s a prime example of a Lambda architecture, effectively merging real-time stream processing with large-scale batch analytics.
At its core, Apache Kafka ingests raw events, from user interactions like “play” or “pause” to operational metrics. This data is then routed into two parallel paths. The “hot path” uses Apache Flink for real-time processing to power features like personalized content carousels and adaptive bitrate streaming. The “cold path” sends data to a data warehouse for batch processing with Apache Spark, enabling complex analytics for content acquisition strategies and long-term user behavior studies.
Key Metrics and Takeaways
This dual-path architecture allows Netflix to handle an extraordinary volume and velocity of data. The following infographic highlights the sheer scale of their daily data processing operations.
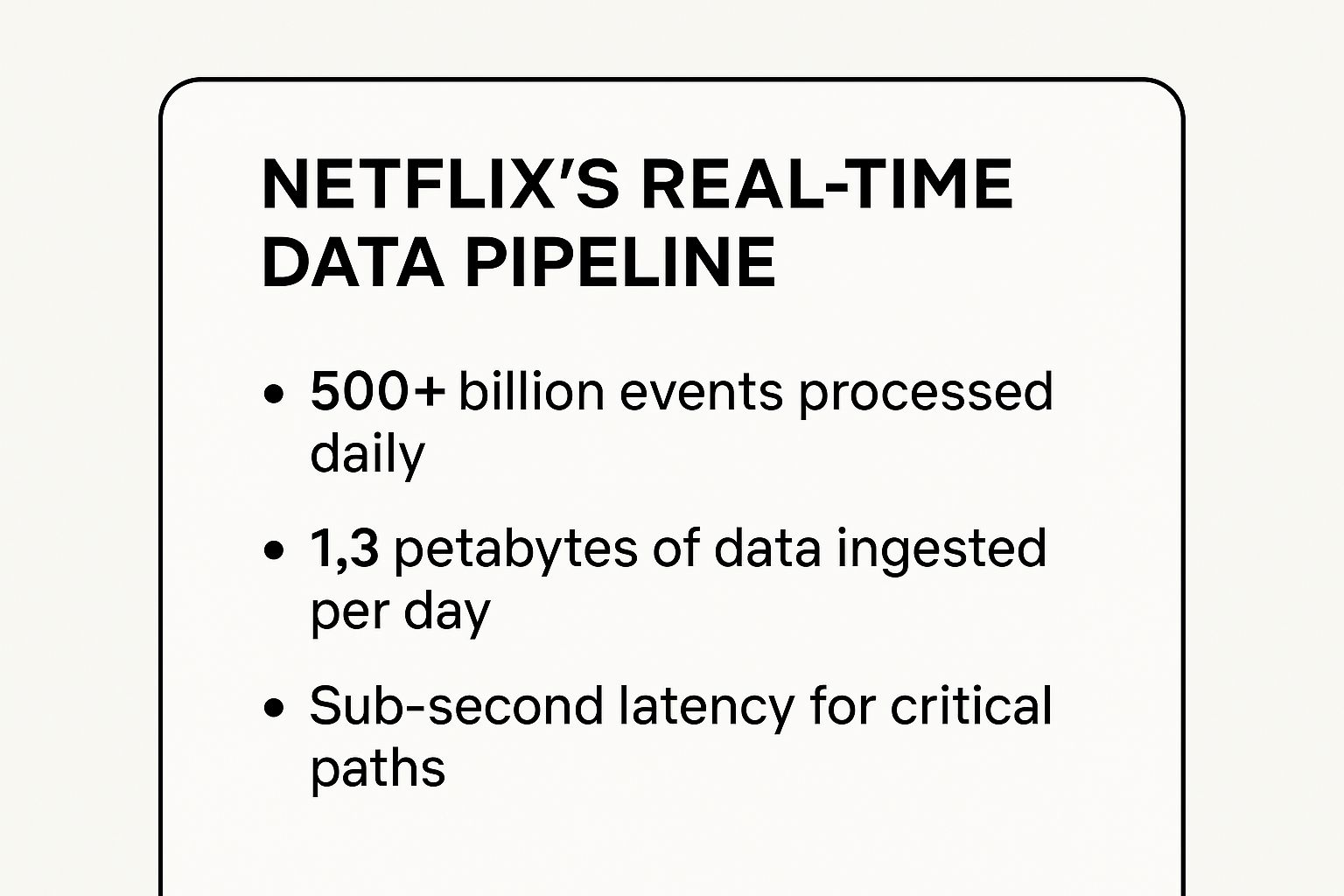
These figures underscore the pipeline’s capacity to deliver immediate insights while simultaneously building a comprehensive historical data store.
Actionable Insights for Your Pipeline
For organizations aiming to replicate this model, several strategies are key:
- Design for Failure: Implement circuit breakers and graceful degradation to ensure the pipeline remains resilient even when individual components fail.
- Schema Management: Use a schema registry (like Confluent Schema Registry) to manage data format evolution, preventing downstream breakages as data structures change.
- Start with Monitoring: Build comprehensive monitoring and alerting from day one to track pipeline health, data latency, and processing throughput.
2. Spotify’s Event Delivery System (EDS)
Spotify’s Event Delivery System (EDS) is another of the most powerful data pipelines examples, engineered to handle the massive torrent of user interactions on its platform. This centralized pipeline ingests, validates, and routes over ten million events per second, from song plays and playlist additions to ad clicks. It serves as the single source of truth for downstream systems, making it a cornerstone of Spotify’s data-driven culture.
Built on Google Cloud Platform, the architecture leverages Pub/Sub for scalable event ingestion and Dataflow for real-time stream processing and transformation. This system powers everything from artist royalty calculations and ad campaign analytics to the machine learning models behind personalized playlists like Discover Weekly. Its efficiency in processing vast event streams is a key enabler for the company’s hyper-personalized user experience, a concept central to event-driven programming.
Key Metrics and Takeaways
The pipeline’s primary achievement is its ability to reliably deliver high-quality, real-time data to dozens of internal teams. It ensures that data consumers, whether they are analytics dashboards or recommendation engines, receive fresh and accurate information. The focus is less on a dual-path architecture and more on a unified, real-time delivery system that guarantees data consistency across the organization.
This unified approach prevents data silos and ensures that when a product team analyzes user engagement, they are using the same foundational data that the finance team uses for royalty payouts.
Actionable Insights for Your Pipeline
To build a robust, centralized event pipeline like Spotify’s, consider these core strategies:
- Implement Strict Schema Validation: Use a centralized schema registry to enforce data contracts at the point of ingestion. This prevents bad data from propagating and breaking downstream applications.
- Utilize Dead-Letter Queues (DLQs): Isolate and handle malformed or failed events in a DLQ. This keeps the main pipeline flowing smoothly while allowing for later analysis and reprocessing of problematic data.
- Establish Clear Data Ownership: Assign clear owners to each dataset and maintain comprehensive documentation. This practice simplifies governance, improves data discovery, and speeds up incident resolution.
3. Uber’s Real-time Data Infrastructure
Uber’s platform is one of the most demanding data pipelines examples globally, processing millions of ride events, location updates, and transactions in real time. The architecture is engineered for massive scale and low latency, relying on Apache Kafka for event streaming and custom tools like AthenaX for stream processing. This system supports critical operations such as driver matching, dynamic pricing, and fraud detection, requiring a delicate balance between speed and data consistency.
This complex infrastructure is a masterclass in separating real-time and analytical workloads, as detailed in comparisons of batch processing vs. real-time stream processing. It uses Apache Hudi to build an incremental data lake, which allows for efficient updates and deletions on massive datasets without costly full rewrites. This enables Uber to power both its immediate operational needs, like ETA predictions, and its long-term strategic analytics from a unified data foundation.
Key Metrics and Takeaways
Uber’s pipeline is defined by its ability to handle mission-critical, real-time events at a global scale. The system ensures data integrity for financial transactions while simultaneously feeding machine learning models that optimize the entire marketplace.

These capabilities highlight the pipeline’s dual focus on transactional consistency and analytical agility, which is essential for a business operating in real time.
Actionable Insights for Your Pipeline
To build a robust pipeline inspired by Uber’s model, consider these engineering strategies:
- Implement Geo-Partitioning: Partition your data streams by geographic region to minimize cross-datacenter latency and improve performance for localized services.
- Design Idempotent Operations: Ensure your processing logic can handle duplicate events without causing incorrect outcomes, a common issue in distributed streaming systems.
- Separate Critical Paths: Isolate mission-critical data flows (like payments or ride matching) from less critical analytics paths to prevent a failure in one from impacting the other.
4. Airbnb’s Data Portal and Unified Pipeline
Airbnb’s platform, built on over a thousand microservices, requires a sophisticated and unified approach to data management. Their architecture is one of the most powerful data pipelines examples for democratizing data access, serving over a thousand data scientists and analysts. This system centralizes data ingestion, processing, and discovery to support critical business functions at scale.
The core of their pipeline relies on Apache Airflow, which Airbnb originally created, for orchestrating complex workflows. Data from various sources flows through Apache Kafka for real-time streaming and is processed using Apache Spark for large-scale batch transformations. This unified pipeline fuels essential systems like their dynamic pricing engine, search ranking algorithms, and fraud detection models, ensuring consistency and reliability across the organization.
Key Metrics and Takeaways
Airbnb’s unified approach enables rapid iteration and empowers teams with self-service analytics, a crucial factor in their growth. Their pipeline manages thousands of distinct data tables and orchestrates tens of thousands of daily task runs to keep the platform’s data fresh and reliable. The emphasis is on accessibility and governance, making complex data usable for a wide audience. This strategy highlights the importance of not just processing data, but also making it discoverable and trustworthy for all stakeholders.
Actionable Insights for Your Pipeline
For organizations looking to build a similar unified data culture, several strategies are essential:
- Establish Clear Ownership: Implement a data governance model with clear data ownership and Service Level Agreements (SLAs) from the very beginning.
- Automate Data Quality: Integrate data quality checks at both ingestion and transformation stages to catch issues early and prevent downstream pollution. For deeper insights, you can learn more about how to build data pipelines with these principles in mind.
- Create Reusable Templates: Develop and share reusable pipeline templates for common ingestion and processing patterns to accelerate development and ensure consistency.
5. LinkedIn’s Unified Streaming Platform (Brooklin)
LinkedIn’s architecture is a testament to the power of a unified streaming platform, making it one of the most compelling data pipelines examples for handling extreme data volumes. Their in-house system, Brooklin, processes over four trillion messages daily, serving as the central nervous system for data replication across multiple data centers, Kafka clusters, and cloud environments. It powers nearly every real-time feature on the platform, from the news feed to job recommendations.
The core of this system is Apache Kafka for data ingestion and Brooklin for reliable data transport. Brooklin acts as a versatile streaming bridge, abstracting away the complexities of the underlying data sources and sinks. This allows data to flow seamlessly into Apache Samza for complex stream processing tasks like fraud detection and into Espresso, LinkedIn’s distributed NoSQL database, for online data serving. This creates a cohesive, real-time ecosystem capable of supporting mission-critical applications at a global scale.
Key Metrics and Takeaways
The scale of LinkedIn’s operations demonstrates Brooklin’s ability to provide a single, reliable source of truth for streaming data across the entire organization. It effectively decouples data producers from consumers, enabling hundreds of engineering teams to build and scale applications independently without worrying about the underlying data transport mechanics. This unified approach minimizes data silos and ensures consistency for features like real-time notifications and member activity analytics.
The pipeline’s design emphasizes scalability and multi-tenancy, allowing different teams to share the infrastructure while maintaining performance and isolation.
Actionable Insights for Your Pipeline
For businesses aiming to build a centralized and scalable streaming infrastructure, LinkedIn’s model offers valuable lessons:
- Implement Schema Management Early: Use a schema registry from the beginning to manage data format evolution. This prevents downstream consumers from breaking as data structures inevitably change.
- Standardize Naming Conventions: Adopt clear topic naming conventions to organize data streams by business domain. This improves discoverability and governance across the organization.
- Build for Replayability: Design comprehensive data replay capabilities into your pipeline. This is crucial for debugging issues, recovering from failures, and backfilling data for new applications.
6. Twitter’s Manhattan and Eventbus Pipeline
Twitter’s architecture is a monumental example of data pipelines examples built for extreme real-time scale, processing peaks of over 400,000 tweets per second. Their system is designed to deliver a consistent, low-latency experience to hundreds of millions of users by efficiently handling a massive, constant stream of data from ingestion to consumption.
The core of this pipeline consists of Eventbus, Twitter’s internal messaging system similar to Kafka, and Manhattan, a distributed, real-time database. When a user tweets, the event is published to Eventbus. From there, it’s fanned out to multiple services for processing. One critical path sends the tweet to Manhattan, which stores it and powers the real-time generation of user home timelines. Other paths feed into systems for trend detection, content moderation, and ad targeting, demonstrating a sophisticated, multi-purpose streaming architecture.
Key Metrics and Takeaways
This pipeline’s primary success is its ability to handle immense write loads while serving personalized reads at an even greater scale. The system is engineered to prioritize availability and low latency for core features like timeline viewing, even during global events that cause unprecedented traffic spikes. This showcases an architecture that separates critical paths to ensure the user experience remains stable under extreme stress. The design’s focus on fanout and specialized storage systems is a key lesson in managing high-volume, real-time data ecosystems.
Actionable Insights for Your Pipeline
For businesses building high-throughput, low-latency pipelines, Twitter’s approach offers several replicable strategies:
- Implement Intelligent Fanout: For high-volume data producers (like popular accounts), create optimized fanout strategies to avoid overwhelming downstream services.
- Separate Read and Write Paths: Decouple the data ingestion and storage path from the data consumption path to allow independent scaling and prevent read-heavy workloads from impacting write performance.
- Design for Graceful Degradation: Build mechanisms to disable non-essential features during extreme traffic spikes, ensuring core functionalities like timeline delivery remain operational.
7. AWS Lambda-based Serverless Data Pipeline
Serverless architectures represent a modern evolution in data pipelines examples, and AWS Lambda is at the forefront of this shift. This approach eliminates the need to provision or manage servers, allowing developers to run code for virtually any type of application or backend service with zero administration. Data pipelines built with Lambda are event-driven, meaning functions are triggered automatically by events such as a file upload to Amazon S3, a change in a DynamoDB table, or an API Gateway request.
At its core, a Lambda-based pipeline is a set of small, single-purpose functions chained together. For instance, an image upload to an S3 bucket can trigger a Lambda function to create a thumbnail. This event-driven, pay-per-use model is ideal for workloads that are unpredictable or intermittent. Services like AWS Kinesis for real-time data streaming, AWS Glue for serverless ETL, and AWS Step Functions for orchestrating complex multi-step workflows are often combined with Lambda to build robust, scalable, and cost-effective data processing solutions.
Key Metrics and Takeaways
The primary advantage of a serverless pipeline is its elasticity and cost-efficiency. You only pay for the compute time you consume, down to the millisecond, which can lead to significant savings compared to running servers 24/7. This model is perfectly suited for tasks like real-time log analysis, IoT data ingestion from millions of devices, or scheduled data aggregation jobs where processing needs fluctuate dramatically.
This approach fundamentally changes the operational model from managing infrastructure to focusing purely on business logic. The pipeline scales automatically and instantly from a few requests per day to thousands per second.
Actionable Insights for Your Pipeline
For organizations adopting a serverless data pipeline model, a few key practices are essential for success:
- Embrace Single-Purpose Functions: Design Lambda functions to perform one specific task. This “microservices” approach enhances reusability, simplifies testing, and makes the pipeline easier to maintain and debug.
- Orchestrate with Step Functions: For complex workflows involving multiple stages, conditional logic, or parallel processing, use AWS Step Functions. It provides a visual workflow, manages state, and handles error retries, preventing the need for complex custom orchestration code within your functions.
- Manage Dependencies with Layers: Use Lambda Layers to share common code, libraries, and dependencies across multiple functions. This practice reduces the size of your deployment packages, simplifies dependency management, and streamlines updates.
9. Spotify’s CI/CD for Data Pipelines
Spotify’s approach to data engineering treats data pipelines as a core software product, managed with the same rigor as user-facing applications. This CI/CD (Continuous Integration/Continuous Deployment) model is one of the most innovative data pipelines examples for ensuring data quality, reliability, and developer velocity at scale. It transforms pipeline development from a manual, error-prone task into an automated, test-driven, and version-controlled process.
The pipeline for pipelines begins when a data engineer commits code to a repository. Automated systems then trigger a series of validation checks, including unit tests for transformation logic and integration tests in a staging environment. Once all tests pass, the changes are automatically deployed to production, often using tools like Jenkins or internal platforms integrated with Google Cloud. This system allows hundreds of teams to independently and safely manage their data assets.

Key Metrics and Takeaways
Spotify’s framework significantly reduces the risk of deploying faulty pipelines. By automating testing and deployment, they empower teams to iterate quickly without compromising the integrity of downstream analytics, artist payouts, or personalized recommendations. This approach codifies data governance and quality checks directly into the development lifecycle.
The ability to roll back changes instantly is a critical feature. If a new deployment introduces a bug, the CI/CD system can revert to the last stable version with minimal manual intervention, drastically reducing Mean Time to Recovery (MTTR) and protecting critical business operations from data-related incidents.
Actionable Insights for Your Pipeline
For organizations looking to implement a similar CI/CD approach for their data infrastructure, consider these strategies:
- Adopt Data-as-Code: Treat your pipeline definitions (e.g., DAGs, SQL transformations) as code. Store them in a version control system like Git to track changes, facilitate collaboration, and enable rollbacks.
- Implement Automated Testing: Create a robust testing suite that includes unit tests for individual components, data quality checks (e.g., using
dbt testor Great Expectations), and integration tests that run the pipeline on a small, representative dataset. - Separate Environments: Maintain distinct development, staging, and production environments. Automate the promotion of code through these stages to ensure changes are thoroughly validated before impacting production data.
9 Data Pipeline Examples Comparison
PipelineImplementation ComplexityResource RequirementsExpected OutcomesIdeal Use CasesKey AdvantagesNetflix Real-time Data PipelineHigh complexity due to Lambda architecture and multi-layer processingVery high; petabyte-scale data, substantial computeSub-second latency, fault-tolerant, scalable real-time analyticsLarge-scale streaming and batch analyticsExtremely scalable, low latency, flexible architectureSpotify’s Event Delivery System (EDS)Moderate complexity with cloud-managed stream and batch processingCloud-managed; cost-effective but requires capacity planningReliable event delivery with 99.9% uptime, strong governanceReal-time recommendations, analytics, royalty calculationsHighly reliable, flexible schema evolution, cost-effectiveUber’s Real-time Data InfrastructureHigh complexity with geo-distributed system and custom processing toolsHigh infrastructure cost for global low-latencyLow latency with strong data consistency, supports geo-spatial queriesReal-time operations like dynamic pricing, fraud detectionExtremely low latency, strong consistency, scalable globallyAirbnb’s Data Portal and Unified PipelineModerate to high complexity managing thousands of workflows and metadataModerate to high; resource contention possibleUnified data access, strong governance, scalable orchestrationData science, analytics, compliance-driven pipelinesStrong governance, self-service, comprehensive lineage trackingLinkedIn’s Unified Streaming Platform (Brooklin)Very high complexity with multi-cluster replication and specialized toolsVery high, resource-intensive with complex infrastructureMassive throughput (4+ trillion messages/day), reliable streamingLarge scale real-time feed, notifications, recommendation systemsIndustry-leading scale, strong reliability, advanced toolingTwitter’s Manhattan and Eventbus PipelineHigh complexity with custom event streaming and storage systemsHigh resource usage during traffic spikes; specialized systemsLow-latency timeline generation with strict ordering, scalableReal-time social feed, trend detection, content moderationExceptional performance during spikes, ordering guaranteesAWS Lambda-based Serverless Data PipelineLow to moderate complexity; no infrastructure management but orchestration neededLow to moderate; serverless pay-per-use, limited execution timeRapid development, automatic scaling, event-driven processingVariable workloads, rapid prototyping, event-driven microservicesNo infrastructure overhead, cost-effective for variable use
Final Thoughts
Throughout this exploration of diverse data pipelines examples, a clear, unifying theme emerges: modern data pipelines are not just about moving data from point A to point B. They are the central nervous system of a data-driven organization, enabling real-time decision-making, personalized user experiences, and scalable operational intelligence. The architectural choices made by giants like Netflix, Spotify, and Uber reveal a strategic shift away from monolithic, periodic batch processing towards more flexible, event-driven, and real-time streaming paradigms.
These case studies demonstrate that the “right” architecture is deeply contextual. A serverless pipeline powered by AWS Lambda offers unparalleled cost-efficiency and scalability for event-triggered tasks, while a unified streaming platform like LinkedIn’s Brooklin addresses the complexity of managing hundreds of data sources at scale. The common thread is a relentless focus on solving a specific, high-value business problem, whether that’s reducing recommendation latency, preventing fraud, or democratizing data access.
Key Strategic Takeaways
As you embark on designing or refining your own data infrastructure, consider these core principles distilled from the industry’s best:
- Embrace Modularity: The most resilient and adaptable data pipelines are built from decoupled, specialized components. This microservices-style approach, seen in Spotify’s Event Delivery System, allows individual parts of the pipeline to be updated, scaled, or replaced without causing system-wide disruptions.
- Prioritize Real-Time When It Matters: Not all data needs to be processed in milliseconds. The key is to identify the business cases, like Uber’s dynamic pricing or Netflix’s operational monitoring, where low latency provides a significant competitive advantage. For these scenarios, investing in a robust streaming infrastructure is critical.
- Unify and Abstract Complexity: As an organization grows, so does its data landscape. Platforms like Airbnb’s Data Portal and LinkedIn’s Brooklin showcase the immense value of creating a unified layer that abstracts away the underlying complexity. This empowers more users to leverage data without needing to be experts in the underlying technologies.
Your Next Steps in Building Better Data Pipelines
The journey from understanding these examples to implementing them requires a strategic, phased approach. Start by identifying a single, high-impact business process that is currently hindered by data latency or inaccessibility. Use this as a pilot project to experiment with new tools and architectures, whether it’s adopting Change Data Capture (CDC) for real-time database replication or building your first serverless processing function.
Ultimately, mastering the art and science of data pipelines is about more than just technical implementation. It’s about building the foundational infrastructure that enables innovation, drives efficiency, and unlocks the true potential of your organization’s data assets. The data pipelines examples we’ve covered are not just blueprints to be copied, but sources of inspiration for building robust, scalable, and business-aligned data solutions.
Ready to build your own high-performance, real-time data pipeline without the complexity? Streamkap provides a fully managed platform that leverages CDC to stream data from databases like Postgres, MySQL, and MongoDB directly into your data warehouse or streaming platform in real-time. Start building scalable, low-latency pipelines in minutes, not months, by visiting Streamkap.
Related resources
Kafka Consumer Lag: Causes, Debugging, and Fixes
Consumer lag is the most common Kafka operational issue. Learn what causes it, how to measure it, and practical strategies to bring it under control.
Kafka on Kubernetes: Real-World Lessons
Running Kafka on Kubernetes sounds like a good idea until you hit storage, networking, and operational challenges. Here's what teams learn the hard way and how to avoid the common pitfalls.
Backpressure in Stream Processing: What It Is and How to Handle It
Learn what backpressure means in streaming pipelines, how to detect it, and practical strategies for handling it in Kafka, Flink, and CDC pipelines without losing data.