Build a Modern Data Pipeline Architecture
Explore modern data pipeline architecture. Learn to design scalable, resilient systems with key patterns like ETL vs. ELT and the right cloud tools.

A data pipeline architecture is essentially the blueprint for how your data gets from point A to point B. Think of it as the entire system—the digital plumbing—that gathers, cleans up, and moves information from all your different sources to a final destination where it can be used for analysis, reporting, or running your day-to-day operations. A good architecture makes sure this flow is efficient, reliable, and secure.
Understanding Your Data’s Central Nervous System

It helps to think of a data pipeline architecture less like a stiff technical diagram and more like your company’s central nervous system for information. This is the framework that decides how raw data from all over the place—website clicks, sales receipts, social media interactions—is methodically turned into something truly valuable.
If you get this wrong, you end up with data silos, insights that come too late, and expensive mistakes. But a well-planned architecture? That’s the bedrock for every single data-driven thing you want to do.
Why Architecture Is More Than Just Moving Data
Just getting data from one place to another isn’t the real goal. A solid data pipeline architecture gives you a strategic edge by creating a dependable and scalable foundation for everything you do with data. It’s about more than just transport; it’s about creating real business value.
Some of the biggest wins from a thoughtfully designed architecture include:
- Consistency and Reliability: It guarantees that data is handled in a predictable and repeatable way. That builds trust in the insights you get from it.
- Scalability for Growth: A good architecture is built to handle more data from more sources without needing a total redesign. As your business scales, your data infrastructure can keep up.
- Improved Decision-Making: When your teams get clean, timely, and accessible data, they can make smarter decisions, faster.
- Foundation for Innovation: Things like machine learning models and AI-driven personalization rely on a constant flow of high-quality data. Only a great architecture can deliver that.
Without this strategic blueprint, teams are often stuck in a reactive mode, constantly putting out fires and fixing broken processes instead of uncovering new insights.
A data pipeline architecture is the bridge between raw, chaotic data and clear, actionable business intelligence. Its design determines whether your data becomes a strategic asset or an operational burden.
The Role of Governance in Architecture
Before a single byte of data enters your pipeline, you need rules for how it’s handled. At its core, a data pipeline architecture relies on strong policies that define data quality, security, and compliance from start to finish. You have to set clear guidelines to protect the integrity of your data throughout its entire journey.
For any organization serious about building a trustworthy system, putting strong data governance best practices in place isn’t just a good idea—it’s non-negotiable. These practices are what prevent the classic “garbage in, garbage out” scenario that trips up so many data projects. They make sure the data flowing through your architecture is accurate, secure, and right for the job.
Ultimately, this foresight is what separates a brittle, patched-together process from a resilient, enterprise-grade data pipeline architecture. It’s the difference between just collecting data and actually creating value from it. As we dive into the specific parts and patterns of modern pipelines, just remember that this foundational blueprint is what holds it all together.
The Building Blocks of Every Data Pipeline
If you want to get your head around data pipeline architecture, you first need to understand the fundamental pieces. It’s a lot like building with LEGOs—once you know what each brick does, you can build anything from a simple wall to an intricate castle. A data pipeline is no different; it’s a system built from distinct parts that all have to work together perfectly.
A great analogy is a city’s water supply. You have sources like rivers and reservoirs, a treatment plant to purify the water, massive storage tanks, and finally, a network of pipes to deliver it to homes. Each stage is critical. A breakdown anywhere along the line, and the whole system fails. Data pipelines follow a surprisingly similar path, making sure information flows cleanly from where it’s created to where it’s needed.
Breaking the pipeline down into these core stages helps you see how different tools fit into the bigger picture. It’s the key to designing an architecture that actually works and won’t fall over when you need it most.
From Source to Insight: The Five Core Components
Every solid data pipeline, no matter how complex, is built on five key stages. The specific tools you use will change, but the job of each component stays the same whether you’re dealing with batch, streaming, ELT, or ETL patterns.
- Sources: This is where your data is born. Sources are anything that generates information your business cares about. Think transactional databases like PostgreSQL and MySQL, SaaS apps like Salesforce and Zendesk, or even real-time event streams from your website and mobile apps.
- Ingestion: This is the collection phase. The ingestion layer acts like a network of aqueducts, gathering raw data from all those different sources and moving it toward a central processing point. This can happen in scheduled batches (say, once an hour) or in real-time as the data is created.
- Processing or Transformation: Here’s where the raw data gets cleaned up and made useful. Just like a water filtration plant, this stage removes impurities like errors and duplicates, enriches the data with more context, and reshapes everything into a consistent, usable format. This is often where your most important business logic lives.
- Storage: Once the data is processed, it needs a home. This is the reservoir of your data pipeline. Common destinations include cloud data warehouses like Snowflake or Google BigQuery, data lakes for raw and unstructured data, or other specialized databases built for specific analytical jobs.
- Consumption or Activation: This is the final step where all that refined data is actually put to work—it’s the “tap” that delivers value. Business intelligence tools like Tableau might connect to it to build dashboards, or it could be fed back into operational systems to power a personalized customer experience.
To give you a clearer picture, here’s a quick summary of how these components fit together.
Key Components of a Data Pipeline Architecture
ComponentPrimary FunctionExample TechnologiesSourcesThe origin points where data is generated.Databases (PostgreSQL, MySQL), SaaS Apps (Salesforce), Event Streams (Kafka), IoT DevicesIngestionCollects and moves raw data from sources.Streamkap, Fivetran, Airbyte, Kafka Connect, AWS KinesisProcessingCleans, validates, enriches, and structures data.Apache Spark, Apache Flink, dbt, SQL, PythonStorageSecurely stores processed data for analysis.Data Warehouses (Snowflake, BigQuery), Data Lakes (Amazon S3), Databases (Redshift)ConsumptionEnables users and systems to access and use the data.BI Tools (Tableau, Looker), ML Platforms (SageMaker), Reverse ETL (Hightouch)
This table lays out the fundamental roles and the kinds of tools you’d typically find at each stage, providing a simple map of the entire data journey.
Why This Structure Matters
Understanding this five-part structure is so important because it helps you make smarter decisions. Each component has its own challenges and needs the right tools for the job. For example, the technology you’d use for real-time ingestion from a Kafka stream is completely different from what you’d use for a nightly batch pull from a CRM.
If you’re ready to get your hands dirty, you can get a much deeper look at the practical steps in our guide on how to build a data pipeline.
The need for well-architected pipelines is absolutely exploding. The global data pipeline market is on track to hit an incredible $43.61 billion by 2032, growing at an annual rate of 19.9%. This massive growth shows just how vital reliable data flow has become for modern business. You can explore more on these market trends at Fortune Business Insights.
By breaking a pipeline down into its core components, you can systematically address potential bottlenecks, ensure data quality at each stage, and select the right technology for each job. This modular approach is the key to building a scalable and maintainable system.
Ultimately, looking at a pipeline this way turns a dauntingly complex concept into a manageable set of steps. It gives you a blueprint for planning, building, and fixing things when they break, ensuring your data doesn’t just move, but actually creates real value.
Choosing Your Architectural Blueprint
Picking the right data pipeline architecture is a lot like deciding on the blueprints for a new building. You wouldn’t use the same plan for a single-family home as you would for a high-rise skyscraper, right? The same logic applies here. The best choice depends entirely on your data’s volume, its speed, and the specific business problems you’re trying to solve. There’s no magic bullet—just the right fit for your reality.
The decision almost always boils down to three main patterns: ETL, ELT, and Streaming. Each one has a completely different philosophy for moving and processing data, with its own set of pros and cons. Getting a handle on these blueprints is the first step to building a data infrastructure that not only gets the job done today but can also grow with you tomorrow.
This decision tree gives you a quick visual for that first big choice: do you need to process data in batches, or does it have to be in real-time?
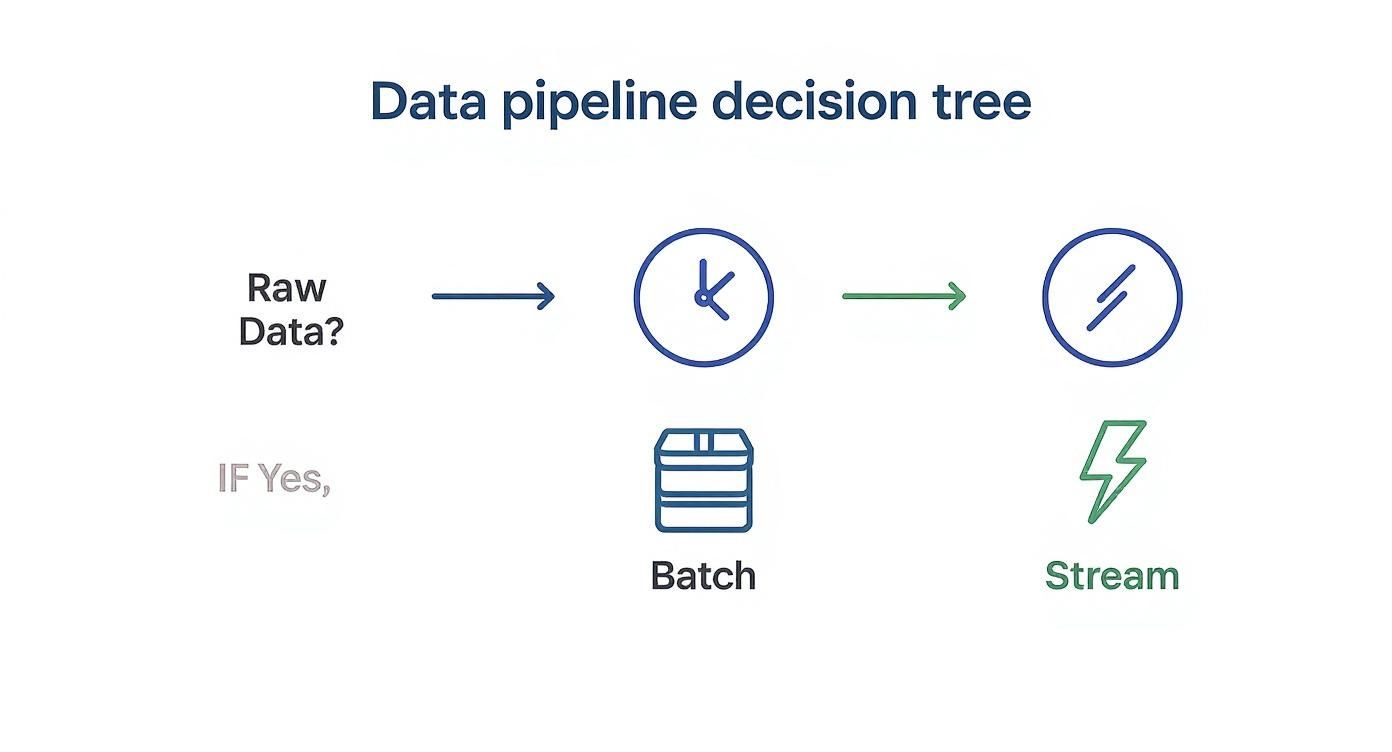
It really comes down to one question: does your data demand immediate action? If the answer is no, a batch approach like ETL or ELT will work just fine. If yes, then streaming is where you need to look.
ETL: The Meticulous Craftsman
ETL, which stands for Extract, Transform, Load, is the classic, old-school approach. Think of it as a master craftsman who carefully preps, sands, and finishes every piece of wood before assembling the final product.
In this model, data is pulled from its sources, sent to a separate processing server where it’s cleaned and reshaped, and only then is the polished, final version loaded into the data warehouse. This was the standard for years, mainly because older data warehouses just didn’t have the muscle to handle heavy-duty transformations. Doing the work upfront protected the warehouse from getting bogged down.
ELT: The Modern Powerhouse
ELT flips that classic model on its head. Standing for Extract, Load, Transform, this modern approach is all about speed and flexibility. You pull the raw data from your sources and dump it straight into a powerful cloud data warehouse like Snowflake or Google BigQuery.
All the heavy lifting—the cleaning, joining, and modeling—happens inside the warehouse, using its massive parallel processing power. This became possible with the explosion of cloud platforms that separate storage from compute, making it cheap to store raw data and spin up compute resources on demand. ELT is generally faster, more adaptable, and—crucially—it keeps the original raw data untouched for future analysis. For these reasons, it’s become the go-to for most cloud-based data stacks.
Key Takeaway: The big difference between ETL and ELT isn’t the work being done, but where it happens. ETL transforms data mid-flight on a separate server. ELT uses the destination warehouse as the transformation engine.
Streaming: The High-Speed Assembly Line
While ETL and ELT work with data in chunks or batches, Streaming architecture is a whole different beast. It processes data continuously, one event at a time, in near real-time. Imagine a high-speed assembly line where each part is processed the second it arrives, instead of waiting for a whole pallet to be ready.
This blueprint is non-negotiable for use cases where every millisecond counts.
- Fraud Detection: Spotting and blocking a bogus credit card transaction as it happens.
- Real-time Analytics: Watching a live e-commerce dashboard update during a Black Friday sale.
- Live Personalization: Suggesting a product based on the last thing a user just clicked on your site.
Built with tools like Apache Kafka and Apache Flink, streaming pipelines are all about minimizing latency. They’re designed to handle a never-ending flow of information, making them a perfect match for our always-on world.
If you want to go deeper, you can explore the nuances of these different data pipeline architectures and see where they fit best. Making the right choice between ETL, ELT, and Streaming is a foundational decision that will dictate how well your organization can turn raw data into a real competitive edge.
How to Design a Resilient Data Pipeline

It’s one thing to build a data pipeline that works on a good day. It’s a whole different challenge to engineer one that can survive the chaos of the real world. The most reliable pipelines aren’t just built—they’re designed from the ground up to handle failure.
Think of it like designing a city’s power grid. It has to handle a massive surge in demand on the hottest day of the year (scalability), automatically reroute power during an outage (fault tolerance), and have sensors to spot failing transformers before they cause a blackout (monitoring).
This mindset forces you to think beyond just moving data. You’re creating a system that anticipates problems—like unexpected changes in a data source, processing delays, or sudden spikes in volume. Without this foresight, you’re just signing up for a future of constant firefighting and unreliable insights.
The key to getting there is adopting principles from DataOps, which brings battle-tested software engineering practices like automation, version control, and continuous testing into the world of data analytics.
Embrace Automation and Orchestration
Manual processes are the arch-nemesis of resilience. Every time a person has to manually kick off a job, copy a file, or check for an error, you’re introducing a weak link. Real resilience comes from automating everything you possibly can.
This is where orchestration tools like Airflow, Dagster, or Prefect come into play. They act as the air traffic controller for your entire pipeline, managing complex job dependencies, handling schedules, and automatically retrying tasks that fail.
Your main goals for automation should be:
- CI/CD for Data Pipelines: Just like with software, any change to your pipeline’s code (like a new SQL transformation) should automatically trigger a suite of tests and then deploy. This is how you catch bugs before they poison your production data.
- Infrastructure as Code (IaC): Using tools like Terraform to define your entire data infrastructure in code is a game-changer. It makes your setup repeatable, version-controlled, and incredibly easy to rebuild if something goes wrong.
The difference this makes is staggering. Gartner predicts that by 2026, data engineering teams using DataOps will be ten times more productive than those who don’t, all thanks to automation. As more data processing moves to the edge, this efficiency becomes non-negotiable. You can dive deeper into this trend in this report on data pipeline efficiency.
Build for Fault Tolerance and Scalability
A resilient pipeline doesn’t just fall over when one part breaks. It’s designed to either self-heal or degrade gracefully. That’s fault tolerance in a nutshell—the ability to keep chugging along even when a component fails.
For instance, if a third-party API your pipeline relies on suddenly goes down, the entire system shouldn’t grind to a halt. A well-designed pipeline will pause, retry the connection after a few minutes, and only then send an alert if the problem continues.
A truly resilient architecture accepts that failures are inevitable and builds mechanisms to handle them automatically. The goal isn’t to prevent all failures, but to minimize their impact.
Scalability is the other side of this coin. Your architecture needs to handle growth without requiring a complete, painful redesign. This is where modern, cloud-native designs really shine, giving you the flexibility to:
- Decouple Storage and Compute: This lets you scale your processing power up or down independently of how much data you’re storing, which is a huge win for cost optimization.
- Use Serverless Functions: For spiky, unpredictable workloads, serverless tools can automatically scale to meet demand in an instant and then scale back down to zero, so you only pay for what you use.
Prioritize Monitoring and Data Quality
You can’t fix what you can’t see. Comprehensive monitoring is the nervous system of your pipeline, giving you a real-time view of its health. And I’m talking about much more than a simple “job succeeded” or “job failed” alert.
Effective monitoring tracks critical metrics at every single stage:
- Data Freshness: How old is the data we’re looking at?
- Data Volume: Did we receive the number of records we expected, or is something off?
- Latency: How long is it taking for data to get from point A to point B?
- Data Quality Checks: Are we suddenly seeing a spike in null values, duplicates, or unexpected schema changes?
Embedding automated data quality tests directly into your pipeline is an absolute must. Think of them as guardrails. These tests act as checkpoints that catch and quarantine “bad” data before it has a chance to corrupt your downstream reports and destroy trust in your entire data platform.
Selecting the Right Tools for the Job
Once you have a solid architectural blueprint, it’s time to pick the tools to actually build your data pipeline. This isn’t about finding the single “best” tool on the market. It’s about assembling the right combination of tools that fits your specific needs, your budget, and—most importantly—your team’s skills. Think of it like equipping a workshop: a master carpenter building custom furniture needs a very different set of tools than a weekend hobbyist fixing a wobbly chair.
The modern data world is flooded with options. You have the massive cloud providers like Amazon Web Services, Microsoft, and Google, but there’s also a thriving ecosystem of specialized providers like Stitch and Fivetran. Today, cloud-based tools dominate the scene because they’re scalable and much easier to get up and running. If you want to dive deeper, you can explore the data pipeline solutions market on datainsightsmarket.com.
With so many choices, it’s easy to get overwhelmed. You need a clear way to make these decisions.
Managed Services vs. Custom Builds
One of the first big forks in the road is deciding between managed services (often called SaaS tools) and building your own custom solutions from open-source parts. Each path has its own set of trade-offs that will directly impact your costs, flexibility, and how much work you’re creating for your team.
- Managed Services (SaaS): This is the “buy” approach. Tools like Fivetran for data ingestion or Snowflake for data warehousing take care of all the messy infrastructure details for you. This route is perfect for teams that need to move fast. You get a quick setup, minimal maintenance, and reliability baked right in, without needing a huge engineering team.
- Custom Builds (Open-Source): This is the “build” approach. Using powerful technologies like Apache Spark, Kafka, or Airflow gives you total control. You can fine-tune every last detail to your exact specifications. While this can be cheaper at massive scale, it demands serious engineering expertise to build, maintain, and keep it running smoothly.
Honestly, most companies land somewhere in the middle. A hybrid approach often makes the most sense—using managed services for common tasks like pulling data from Salesforce, while writing custom code for the unique business logic that sets you apart.
The right toolchain is one that works for your team and helps you meet your business goals. Always prioritize solutions that cut down on operational headaches and get you to insights faster, not just the shiniest new toy on the block.
A Framework for Tool Evaluation
To cut through the noise, it helps to evaluate tools based on the job they need to do in your pipeline. Here are the key questions to ask for each component to make sure your tech stack works together as a cohesive whole.
1. Data Ingestion Tools
This is the front door to your entire pipeline. Get this wrong, and nothing else matters.
- Connectors: Does it have pre-built connectors for all the data sources you rely on?
- Latency: Can it keep up with your needs? Are you looking for real-time streams, batches every few minutes, or just a daily dump?
- Schema Handling: What happens when someone adds a new column in the source system? Does the tool handle it gracefully, or will it break the pipeline and wake someone up at 3 a.m.?
2. Transformation and Processing Tools
This is where the magic happens and raw data becomes valuable insight.
- Skillset Alignment: Does the tool use SQL, Python, or a drag-and-drop interface? Pick something your team is already good at so they can be productive from day one.
- Integration: How easily does it plug into your storage and orchestration layers? Tools like dbt are brilliant because they’re designed to work right inside modern cloud data warehouses.
- Testing: Can you easily test your logic? Good tools have built-in features for validating data quality and ensuring your transformations are doing what you expect.
3. Orchestration and Monitoring Tools
This is the conductor of your data orchestra, making sure every part plays on cue.
- Dependency Management: Can it handle complex workflows where one job can’t start until three others have finished successfully?
- Alerting: When something inevitably breaks, will it tell you? And will the alerts be clear enough to help you fix it quickly?
- Scalability: Can it handle 10 pipelines today and 100 next year without grinding to a halt?
By systematically checking potential tools against these practical needs, you can build a tech stack that not only works today but can also grow and adapt as your business does.
Solving Common Data Pipeline Problems
Let’s be realistic: even the most perfectly designed data pipeline is going to run into trouble. Real-world data is messy and unpredictable, and source systems change on a whim. The difference between a brittle pipeline that constantly breaks and a resilient, production-ready system is how you prepare for these inevitable failures.
Most problems you’ll encounter fall into a few common buckets. You might see data quality slowly degrade over time, or you could face a sudden performance bottleneck that brings everything to a standstill. If you don’t get ahead of these issues, they can erode trust in your data and create a huge operational headache.
Confronting Schema Drift and Data Rot
One of the most common migraines for data engineers is schema drift. This is what happens when someone changes the structure of a source system without telling you. Suddenly, a new column appears, a data type gets changed, or a field is deleted, and your pipeline, which was expecting the old format, either crashes or starts silently losing data.
Then there’s the slow, creeping problem of data rot, where your data’s quality and integrity just get worse over time. This isn’t usually one big event, but a series of small cuts:
- Upstream Errors: A bug in a production application starts feeding garbage data into your system.
- Duplicate Records: A scheduled job hiccups and runs twice, creating duplicate entries that throw off all your analytics.
- Stale Data: A specific process fails overnight, and now all the downstream dashboards are showing yesterday’s numbers.
To get a better handle on these types of challenges, our guide on overcoming common data integration issues dives much deeper into practical solutions.
A data pipeline is only as reliable as its weakest link. Proactive monitoring and automated quality checks are not optional features; they are essential defenses against the inevitable chaos of real-world data.
Solving Bottlenecks and Performance Issues
That pipeline that was lightning-fast a year ago might be crawling today. As your data volume explodes, performance bottlenecks become a serious growing pain, often stemming from inefficient transformations, systems competing for the same resources, or poor data partitioning. The trick is finding the exact chokepoint and fixing it.
Here are a few proven strategies to get ahead of these common problems:
- Implement Schema Contracts: Don’t just hope the source schema stays the same. Use tools that can automatically spot and handle changes. A flexible data pipeline architecture should be able to either adapt on the fly or quarantine the unexpected data and send an alert, protecting your downstream systems from corruption.
- Automate Data Quality Testing: Build your quality checks directly into the pipeline itself. Tools like
dbtare great for this, letting you define tests that check for nulls, duplicates, or broken relationships between tables. If a test fails, the process stops before bad data ever makes it to the warehouse. - Optimize with Parallel Processing: Stop trying to push massive jobs through a single-threaded process. Break them down into smaller, independent tasks that can all run at the same time. This is exactly what modern cloud data warehouses were built for, allowing you to scale up your compute power to handle huge workloads without getting stuck.
Data Pipeline Architecture Questions Answered
As you start putting these concepts into practice, a few common questions always pop up. It’s one thing to understand the theory, but another to actually build the thing. Let’s tackle some of the most frequent hurdles that teams face when they get their hands dirty with data pipeline architecture.
What’s the Real Difference Between a Data Pipeline and ETL?
This one trips a lot of people up, but it’s simpler than it sounds. A data pipeline is the broad, umbrella term for the entire process of moving data from Point A to Point B. Think of it as the whole highway system.
ETL (Extract, Transform, Load) is just one specific route you can take on that highway. It’s a classic pattern where you clean and reshape the data before loading it into its final destination. But there are other routes, like ELT or real-time streaming.
So, to put it simply: every ETL process is a data pipeline, but not every data pipeline uses the ETL pattern.
How Should a Small Team Build Its First Data Pipeline?
When you’re just starting out, don’t try to boil the ocean. The goal is to get a quick, meaningful win. My advice is always to start with a single, high-impact business problem and use managed services to get there fast.
For a small team, the leanest path forward usually looks like this:
- Use low-code tools for ingestion. Tools like Fivetran or Stitch are a lifesaver here. They save you from the nightmare of building and maintaining custom API connectors.
- Pick a cloud data warehouse. Go with something like BigQuery or Snowflake for your storage and processing needs. They manage all the complex infrastructure, so you don’t have to.
- Stick with the ELT pattern. This modern approach is a perfect match for cloud tools. You load the raw data first and transform it later, which dramatically simplifies the initial setup.
This strategy lets you sidestep the heavy infrastructure work and deliver real value quickly, which is crucial for building momentum and getting buy-in for future projects.
An orchestrator acts as the “brain” or “conductor” of your data pipeline. Its primary job is to schedule, monitor, and manage the entire workflow of interconnected tasks.
What Is the Role of an Orchestrator Like Airflow?
An orchestrator like Apache Airflow is the conductor of your data orchestra. It’s what brings order to the chaos. Its main job is to automate your entire workflow, making sure that Task B kicks off only after Task A finishes successfully.
Without it, you’re stuck managing everything manually—a recipe for disaster. An orchestrator handles the critical stuff, like automatically retrying a task if it fails or sending you an alert when something breaks and needs a human to step in.
As your system grows, trying to manage a data pipeline architecture without an orchestrator quickly becomes an unreliable, error-prone headache.
Ready to build modern, real-time data pipelines without all the complexity? Streamkap uses Change Data Capture (CDC) to move data from your databases to your warehouse in real-time, replacing slow batch jobs with an efficient, event-driven approach. See how you can simplify your data pipeline architecture and get started today.
Related resources
Kafka Consumer Lag: Causes, Debugging, and Fixes
Consumer lag is the most common Kafka operational issue. Learn what causes it, how to measure it, and practical strategies to bring it under control.
Kafka on Kubernetes: Real-World Lessons
Running Kafka on Kubernetes sounds like a good idea until you hit storage, networking, and operational challenges. Here's what teams learn the hard way and how to avoid the common pitfalls.
Backpressure in Stream Processing: What It Is and How to Handle It
Learn what backpressure means in streaming pipelines, how to detect it, and practical strategies for handling it in Kafka, Flink, and CDC pipelines without losing data.