A Guide to Data Stream Processing


September 27, 2025
So, what exactly is data stream processing? At its core, it's the practice of analyzing and acting on data as it's being created—data in motion—instead of waiting to store it first.
Think of it like having a live, real-time conversation with your data. This approach allows you to react instantly to events the very moment they happen, which is a world away from traditional methods that analyze data in large, delayed chunks.
What Is Data Stream Processing Anyway?

Let's stick with the conversation analogy. Imagine trying to understand a discussion by reading a full transcript hours after it's over. You'll get the facts, but the moment has passed. Now, compare that to participating in the conversation live, where you can react, ask questions, and influence the outcome on the spot.
That's the fundamental difference between old-school data analysis and modern data stream processing.
Traditional methods, often called batch processing, are like reading that delayed transcript. They work by collecting huge volumes of data over a set period—maybe an hour, a day, or even a week—and then running complex queries on that stored dataset. It’s perfect for historical reporting, like putting together end-of-quarter sales figures. The catch? It’s always reactive. You're always looking in the rearview mirror.
Data stream processing is the live conversation. It processes data the instant it's generated, handling a continuous, real-time flow. This is what experts call "unbounded" data because it has no defined start or end; it just keeps on coming.
At its heart, data stream processing is about shrinking the time between a business event and the decision made in response to it. The goal is to move from "what happened yesterday?" to "what is happening right now, and what should we do about it?"
The Shift From Batches to Streams
The business world moves fast. The ability to react in milliseconds isn't just a nice-to-have anymore; it's a competitive must. Organizations simply can't afford to make today's decisions using yesterday's news. This demand for immediacy is driving a massive shift from batch-based thinking to real-time streams.
Just think about these scenarios where waiting is simply not an option:
- Fraud Detection: An algorithm needs to spot and block a fraudulent credit card transaction in the milliseconds between a card swipe and the transaction's approval.
- Dynamic Pricing: An e-commerce site has to adjust product prices on the fly based on real-time user traffic, competitor pricing, and current inventory to maximize sales.
- Predictive Maintenance: An IoT sensor on a factory floor detects an unusual vibration, instantly triggering an alert to prevent a catastrophic and expensive equipment failure.
In every one of these cases, the data's value plummets with each second that ticks by. Data stream processing is the engine that lets you capture that value before it disappears.
To really nail down how these two approaches differ, it helps to see them side-by-side.
Data Stream Processing vs Traditional Batch Processing
Here’s a quick breakdown of the core differences between processing data in real-time streams versus in historical batches.
Ultimately, the choice isn't about one being universally "better" than the other. It's about matching the right tool to the job. For a deeper dive into how these methods compare, our guide on batch processing vs. real-time stream processing is a great resource. It’s a foundational concept that really highlights why so many modern businesses are leaning into real-time capabilities.
Building Your Digital Nervous System
To make data stream processing work, you need a well-defined architecture—think of it as a digital nervous system for your entire organization. This system is designed to sense what’s happening across your business, process that information instantly, and trigger an intelligent reaction. Each component plays a specific role in turning a raw event into a valuable business outcome.
The whole process can be broken down into three essential stages: data ingestion, real-time processing, and the final data destination. You can think of them as the senses, brain, and muscles of your real-time data operations.
This visual shows that flow, from raw data sources through the processing engine to the final applications that use the insights.
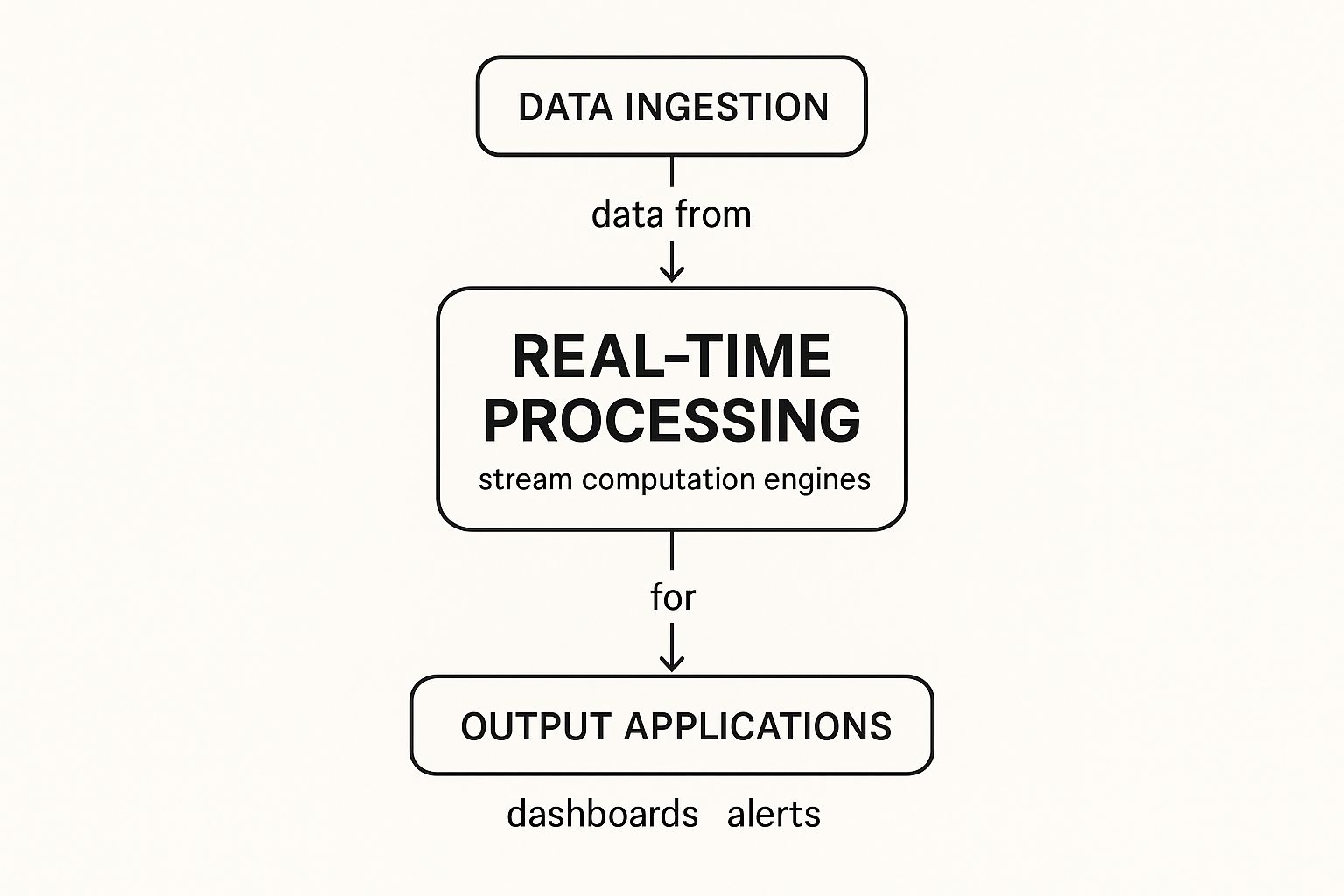
The key takeaway here is that these pieces form a continuous, interconnected pipeline. Data moves seamlessly from the moment it's created to the moment it drives an action, with virtually no delay.
The Senses: Data Ingestion
The first stage, data ingestion, is where your system "senses" the world. It’s all about collecting event data from a huge variety of sources and funneling it into your streaming pipeline. These sources are the digital pulse of your business, constantly generating new information.
Events can come from just about anywhere:
- Application Logs: Capturing user actions, errors, and performance metrics from your software.
- User Interactions: Tracking clicks, searches, and navigation patterns on a website or mobile app.
- IoT Devices: Receiving continuous sensor readings from factory machinery, delivery vehicles, or smart home devices.
- Database Changes: Monitoring updates, inserts, and deletes in transactional databases as they happen.
A really powerful technique for this last point is Change Data Capture (CDC). Instead of running slow, clunky queries, CDC captures every single change in a source database and streams it as a distinct event. It’s incredibly efficient. For a deep dive, check out our guide on change data capture for streaming ETL, which explains how it fuels modern data pipelines.
In short, the ingestion layer is the entry point, making sure this torrent of raw data is reliably captured and ready for the next step.
The Brain: The Streaming Engine
Once the data is collected, it flows into the streaming engine—the brain of the operation. This is where the real-time computation and analysis happen. The engine processes the incoming stream of events on the fly, without ever needing to park them in a traditional database first.
This "brain" performs all sorts of complex tasks in milliseconds:
- Filtering and Transformation: It can clean up messy data, enrich it with extra information, or just filter out the noise.
- Aggregations: It calculates running totals, averages, or counts over specific time windows. Think questions like, "How many users signed up in the last minute?"
- Pattern Detection: It can spot specific sequences of events that might signal fraud, a sales opportunity, or a potential system failure.
The whole point of the streaming engine is to apply business logic to data in motion. It's not just about moving data from A to B; it's about making sense of it as it happens, giving the system the context behind each event.
Popular tools like Apache Flink, Spark Streaming, and Kafka Streams are the powerhouses that make this possible, handling massive volumes of data with incredibly low latency.
The Muscles: Data Destination
The final stage is the data destination, which acts as the "muscles" of your digital nervous system. After the streaming engine has processed the data and pulled out valuable insights, that information needs to be sent somewhere to trigger an action. The destination is where the results are delivered.
This is where the rubber meets the road and insights turn into real outcomes. Common destinations include:
- Real-Time Dashboards: Updating analytics dashboards to give business leaders a live, up-to-the-second view of operations.
- Alerting Systems: Firing off an immediate email, SMS, or Slack notification to a team when a critical threshold is breached.
- Downstream Applications: Triggering an automated response in another system, like adjusting an ad campaign's budget or placing a hold on a suspicious account.
- Data Warehouses: Loading the processed, real-time data into a warehouse like Snowflake or BigQuery for longer-term historical analysis.
Together, these three components—ingestion, processing, and destination—form a complete and powerful architecture. They create a seamless loop from event to insight to action, letting any organization operate with true real-time awareness.
Choosing Your Streaming Architecture and Tools
Once you've got a handle on the basic building blocks of a stream processing pipeline, the real design work begins. Picking the right architecture is a bit like choosing between building a versatile hybrid car or a specialized, high-speed race car. Both will get you to the finish line, but they're engineered for very different tracks and performance trade-offs.
Two main architectural patterns dominate the world of modern streaming: the Lambda Architecture and the Kappa Architecture. Which one you choose really boils down to your specific needs for speed, data accuracy, and how much operational complexity you're willing to take on.
Comparing Lambda and Kappa Architectures
Think of the Lambda Architecture as the hybrid model. It was designed to give you the best of both worlds: the immediate results of real-time processing and the complete accuracy you get from traditional batch processing. It pulls this off by running two data pipelines in parallel.
- The Speed Layer: This is your pure, real-time stream processing path. It gives you immediate answers, even if they're sometimes just good approximations.
- The Batch Layer: This layer methodically processes all the data in large, precise batches. The output is a master dataset that acts as the ultimate source of truth.
- The Serving Layer: This is where everything comes together. It combines the real-time views from the speed layer with the historical records from the batch layer to answer any query.
This dual-path approach is great because you get up-to-the-second insights without sacrificing historical accuracy. The major downside? It's complex. You have to build, manage, and debug two entirely separate systems, which can be a huge operational headache.
The Kappa Architecture came along as a simpler, more elegant alternative. It was born from the idea that if your streaming system is powerful enough, you don't need two separate pipelines—you can handle both real-time and historical processing with just one.
The core idea behind the Kappa Architecture is to treat everything as a stream. Instead of a separate batch and speed layer, you use a single, powerful streaming engine to process incoming data and, when needed, reprocess historical data from an immutable log.
This approach massively simplifies things by getting rid of redundant code and complex infrastructure. The main challenge, however, is performance. If you need to re-run your analytics over several years of historical data, your system has to be fast enough to make that practical.
If you want to dive deeper into these designs, our guide on what is streaming architecture offers a much more detailed comparison.
Key Data Stream Processing Tools
With an architectural pattern in mind, the next big decision is picking the right tools. The open-source world is full of incredible options, each with its own unique strengths.
Data stream processing has really hit the mainstream in the enterprise world. In fact, more than 80% of Fortune 100 companies now use Apache Kafka, which has cemented its place as the go-to platform for event streaming. Across the globe, it's estimated that over 100,000 organizations depend on Kafka for reliable, scalable data pipelines.
Here’s a quick rundown of the heavy hitters you'll likely encounter:
- Apache Kafka: This is the undisputed king of the ingestion layer. Think of it as a distributed, super-resilient central nervous system for your data. It’s fantastic at handling massive volumes of events from all kinds of sources and feeding them to different processing engines.
- Apache Flink: If Kafka is the nervous system, Apache Flink is the brain. It's a true stream processing framework built from the ground up for low-latency, high-throughput calculations. It truly shines when you're dealing with complex event processing, stateful computations, and out-of-order data.
- Spark Streaming: Built on the famous Apache Spark engine, Spark Streaming takes a slightly different approach by processing data in tiny, rapid-fire "micro-batches." This allows for excellent throughput and gives you seamless access to Spark's massive ecosystem of tools for machine learning, SQL, and more.
Each of these tools is a powerful component in its own right. The best combination for you will depend entirely on your latency requirements, how complex your processing logic needs to be, and how it all fits into your existing tech stack.
To help you see how they stack up, this table highlights their core strengths.
Comparison of Top Data Streaming Frameworks
Choosing the right framework is crucial, as each one is optimized for different scenarios. The table below breaks down the key differences between the most popular choices in the streaming ecosystem.
Ultimately, Kafka is often used for data ingestion, while Flink and Spark Streaming are used for the actual computation. Many modern architectures even use them together to get the best of all worlds.
The Business Case for Real-Time Data
It’s one thing to understand the architecture behind data stream processing, but the real question is always: what’s the payoff? Why should a business care? The shift from stale, batch-processed reports to live, flowing data gives companies a serious competitive advantage.
You stop reacting to what happened yesterday and start responding to what’s happening right now. The benefits aren't just small tweaks; they completely change how you operate and serve customers. This value often comes to life through things like real-time data analytic dashboards, which give decision-makers a live pulse on the business.
Let’s look at four areas where this really makes a difference.
Deliver Hyper-Personalized Customer Experiences
Generic, one-size-fits-all customer experiences just don't cut it anymore. Data stream processing lets you understand and act on customer behavior in the moment, making your interactions feel personal and relevant.
Think about an e-commerce site tracking a user's clicks as they browse. A streaming system can instantly suggest products they might actually want, offer a timely discount on an item they keep looking at, or even rearrange the homepage to match their current interests. That kind of responsiveness makes customers feel seen and understood, which is a game-changer for engagement and sales.
Enhance Operational Efficiency
Relying on end-of-day reports to spot problems is like waiting for a fire alarm to go off when you could have smelled the smoke ten minutes earlier. Streaming analytics lets you monitor the health of your systems, supply chains, and processes as they run.
For example, a logistics company can process live GPS data from its delivery fleet. If a truck hits unexpected, gridlocked traffic, the system can automatically find a better route and send new directions. This proactive fix prevents delays, saves on fuel, and keeps customers happy—all of which directly boosts the bottom line.
Real-time data processing closes the gap between insight and action. It allows businesses to move at the speed of their customers and markets, turning potential crises into manageable events and fleeting opportunities into captured revenue.
Proactively Manage Risk and Fraud
In industries like finance and banking, a few seconds can mean the difference between stopping a fraudulent transaction and dealing with a major security breach. Data stream processing is what powers modern fraud detection.
When a credit card is swiped, a streaming application can analyze dozens of data points in milliseconds—the location, the amount, the time, the purchase history—and flag a suspicious transaction before it's ever approved. This immediate response is absolutely critical for cutting financial losses and maintaining customer trust.
Unlock New Revenue Streams
Beyond just making current operations better, real-time data can spark entirely new business models. Companies can actually monetize their data streams by creating premium services for their customers.
A great example is a utility company using smart meter data. They can offer customers personalized tips on how to save energy or send alerts during peak usage hours to help them avoid higher rates. This adds a new layer of value, strengthens the customer relationship, and opens up brand-new ways to generate revenue.
The demand for this kind of instant insight is making the market explode. The global stream processing market, recently valued around $5 billion, is on track to hit nearly $15 billion by 2033. This growth is being driven by the massive increase in IoT devices and a universal need for analytics that keep pace with reality.
How Top Industries Use Data Streaming
It's one thing to talk about architectures and tools, but the real magic of data stream processing happens when you see it at work in the real world. This is where theory hits the pavement, and industries use real-time analytics to solve some of their biggest headaches. Across sectors, from finance to manufacturing, companies are tapping into continuous data flows to make smarter, faster decisions that were simply out of reach with older batch-processing methods.
This move toward instant insight is what’s fueling some serious market growth. The global streaming analytics market was recently valued at USD 27.84 billion, but it's on track to explode to USD 176.29 billion by 2032. That's a staggering 26.0% CAGR, which tells you just how essential real-time decision-making has become for everything from stopping fraud to improving customer experiences. You can dig deeper into these trends in this detailed streaming analytics report.
So, let's look at a few solid examples of how data streaming is shaking things up.
Finance and Fraud Detection
In the world of finance, every millisecond counts. Being able to spot and stop fraud before a transaction is even complete is a massive advantage for banks and fintechs. When a customer swipes their card, a data stream processing system can analyze dozens of variables in the time it takes to blink.
- Real-Time Transaction Scoring: Is the purchase happening in an odd location? Is the amount wildly different from the user's normal spending habits? The system weighs all these factors instantly to spit out a risk score.
- Instantaneous Blocking: If that score crosses a certain line, the transaction is automatically blocked and an alert goes out. This stops the financial loss in its tracks and keeps customer accounts safe.
This need for speed is just as crucial in algorithmic trading. Many sophisticated AI investment platforms lean heavily on data streaming to chew through market data as it happens. This allows them to execute trades at the perfect moment, jumping on tiny market shifts that might only exist for a few seconds.
E-commerce and Dynamic Personalization
For any online retailer, data streaming is the secret sauce for creating a shopping experience that feels alive and personal. The days of static websites with generic recommendations are long gone. Today’s e-commerce leaders use real-time data to react to every single click and search.
Picture a customer who starts searching for running shoes. A streaming system can immediately start tailoring their visit:
- Adjusting Recommendations: The homepage might instantly start showing related athletic gear and accessories.
- Implementing Dynamic Pricing: If a popular shoe is flying off the virtual shelves, its price could tick up slightly to reflect the demand in real time.
- Managing Inventory: As people buy, inventory counts are updated across the board instantly, which is crucial for preventing overselling during a big flash sale.
By processing user behavior as it happens, retailers can create a shopping journey that feels uniquely tailored to each individual, significantly boosting engagement and conversion rates.
Manufacturing and Predictive Maintenance
On a factory floor, an unexpected equipment failure is a recipe for disaster, leading to expensive downtime and production delays. Data stream processing, powered by sensors from the Internet of Things (IoT), flips this problem on its head, turning a reactive mess into a proactive solution.
Sensors attached to machinery constantly stream data on temperature, vibration levels, and overall performance. A streaming analytics platform keeps a 24/7 watch on these feeds, searching for subtle clues that might signal a future breakdown. If a machine's vibration pattern starts to look off, the system can automatically:
- Generate an Alert: It notifies the maintenance crew about the specific part at risk, long before it actually fails.
- Schedule a Repair: The system can even book the maintenance for a planned shutdown, avoiding the chaos and cost of an emergency stop.
This approach, known as predictive maintenance, is all about maximizing uptime and getting more life out of critical equipment. In the same way, logistics companies use GPS streams to tweak delivery routes on the fly, and telecom providers monitor network traffic to head off outages before customers are affected. Each of these examples shows a fundamental shift from looking in the rearview mirror to looking ahead—a shift driven entirely by the power of processing data in motion.
Avoiding Common Implementation Pitfalls

Knowing the theory of data stream processing is one thing, but actually building a system that can take a punch is another story. A successful rollout comes down to smart planning that anticipates the real-world problems that can turn a promising project into a maintenance nightmare. The goal is a pipeline that won't buckle under pressure.
Too many teams underestimate just how messy real-world data can be and how often systems fail. You have to design for these headaches from the very beginning, not treat them as an afterthought. That means an early focus on data quality, scalability, and how your system will handle its memory and recover from crashes.
Ensuring Data Quality and Consistency
In a streaming environment, the old "garbage in, garbage out" rule happens at the speed of light. Bad data can poison your analytics and trigger all the wrong automated actions. It's absolutely critical to validate and clean data the moment it enters your system, not after it's already rippled downstream.
Your strategy needs to account for a few common culprits:
- Late or Out-of-Order Events: Network hiccups and other delays mean events won't always arrive in perfect sequence. Your system needs built-in logic, usually involving event-time processing and watermarks, to piece together the correct timeline.
- Duplicate Messages: It’s almost a guarantee that a source will send the same message more than once. Your processing logic must be idempotent, which is a fancy way of saying that processing the same message twice (or ten times) has the exact same outcome as processing it just once.
- Schema Evolution: Data formats change over time. Your pipeline needs a way to handle these updates without breaking everything. A schema registry is the standard tool for this, letting you track versions and ensure new and old data can coexist peacefully.
Planning for Massive Scale from Day One
A streaming system that hums along with a thousand events per second can completely choke when faced with a million. Scalability isn't a feature you can just tack on later; it has to be part of the blueprint. This means picking tools that can scale horizontally—think adding more nodes to a Kafka or Flink cluster to spread out the work.
A classic mistake is building a system that runs perfectly in a clean test environment, only to watch it crumble under the chaotic spikes and sheer volume of production traffic. Always design for your peak load, not your average.
Smart scaling also involves partitioning your data streams. By splitting a stream based on a key (like a userID), you can make sure all related events get processed together on the same machine. This approach lets the overall system handle huge throughput without creating a single, massive bottleneck, ensuring data keeps flowing as your business expands.
Effectively Managing State and Fault Tolerance
Most stream processing jobs need to remember things. Think about calculating a running total of a user's purchases or tracking their session activity. This memory is called "state," and you have to manage it carefully. Keeping state in memory is fast, but if a processing node goes down, that memory is wiped clean.
This is why resilient systems use fault-tolerant state management. They periodically save snapshots of the in-memory state to durable storage, like a distributed file system. If a node fails, a new one can spin up, load the last snapshot, and pick up right where the old one left off without missing a beat. Designing for failure isn't being pessimistic—it's the only way to build a professional-grade streaming pipeline.
A Few Common Questions About Data Streaming
As you start working with data stream processing, a few tricky concepts always come up. Getting these right is often the difference between a fragile data pipeline and one that’s truly reliable and accurate. Let's tackle some of the questions that frequently trip people up.
First off, how do you deal with the messy reality of data in motion? In a perfect world, every piece of data would show up instantly, right in the order it was created. But we live in the real world, where network lag and distributed systems mean events often arrive late or completely out of sequence. So, how can any system make sense of that chaos?
The solution is a clever idea called a watermark. Think of a watermark as a progress marker in the stream. It essentially tells the processing system, "I don't expect to see any more events that happened before this specific time." This gives the processor the confidence to finalize calculations for a given time window—like "all sales from 10:01 AM"—and move on, even if a few straggler events trickle in later.
Event Time vs. Processing Time
That brings us to another critical distinction: the difference between when something happened and when your system found out about it.
- Event Time: This is the timestamp from the real world, marking the exact moment something occurred. A user clicking the "buy" button is a perfect example. For accurate analysis, this is the time you really care about.
- Processing Time: This is simply the time when the event finally reached your processing engine. It's easy to capture, but it can be really misleading because of all the potential network delays.
Picture this: a customer makes a purchase on their phone at 10:05 AM (that's the event time). But due to a spotty mobile connection, the data doesn't hit your servers until 10:08 AM (the processing time). If you were only looking at processing time, you'd incorrectly group that sale with events from the 10:08 AM window, which could seriously skew your analytics. Real data stream processing always prioritizes event time to piece together what actually happened, in the right order.
Is Stream Processing Only for Huge Datasets?
It’s a common myth that you only need stream processing if you're dealing with "big data" on a massive scale. And while it definitely shines there, the core benefit isn't just about handling volume—it's about enabling immediate responsiveness.
The decision to use stream processing isn't about the size of your data; it's about the speed of your decisions. If the value of an event decays quickly, you need to process it in real time.
Even a small company can get huge value from this. Think about a mobile app sending a welcome notification the second a new user signs up. Or a small online store that needs to update inventory live during a flash sale. These are powerful examples that don't require petabytes of data. It’s all about shrinking the time between an event happening and you taking meaningful action on it.
Ready to replace slow, costly batch ETL jobs with efficient, real-time data pipelines? Streamkap uses Change Data Capture (CDC) to stream data from your databases to your warehouse in milliseconds, without impacting source system performance. Learn how you can build a modern, event-driven architecture.

Related blog posts
