<--- Back to all resources
Build Robust ETL Data Pipelines
Discover how ETL data pipelines transform raw data into business intelligence. Learn to build and manage robust workflows with our expert guide.

ETL data pipelines are the workhorses of the modern data stack. At their core, they are automated processes that take raw data from a bunch of different places (Extract), clean it up and get it into the right shape (Transform), and then deliver it to a central destination like a data warehouse (Load).
Think of it as a digital factory. Raw, messy materials come in one end, and a polished, valuable product comes out the other, ready for your business intelligence teams to use for making critical decisions.
What Does an ETL Data Pipeline Actually Do?
Let’s use a more down-to-earth analogy. Imagine you’re a chef trying to make a signature dish. You get ingredients from all over the place—vegetables from one supplier, spices from another, and meat from a local butcher. In their raw state, you can’t just throw them all in a pot. This jumble of ingredients is just like the raw data coming from your company’s sales software, website analytics, and customer support tools.
An ETL data pipeline is your entire kitchen staff, all working in perfect sync.
First, they gather all the ingredients from the different suppliers. That’s the Extract phase. Then, they wash the vegetables, chop the onions, measure the spices, and marinate the meat according to a specific recipe. This is the crucial Transform phase. Finally, they combine everything, cook it, and plate it beautifully before sending it out to the dining room. That’s the Load phase, where your analysis-ready data is delivered to a data warehouse, ready for dashboards, reports, or machine learning models.
From Raw Data to a Strategic Asset
Without this process, your data is just a pile of uncooked ingredients sitting in different corners of the kitchen—siloed, disorganized, and not very useful. It’s almost impossible to see the big picture. The whole point of an ETL data pipeline is to tear down those silos and create a single, reliable source of truth.
This structured workflow makes sure the data that lands in your warehouse is:
- Consistent: Everything follows the same rules, like using a single date format across all datasets.
- Clean: Errors, duplicate entries, and missing values have been fixed or removed.
- Enriched: Data from different sources is combined to paint a fuller picture. You can learn more about how this process works in our complete guide to what is an etl pipeline.
- Reliable: The data is trustworthy and ready for analysis right out of the box.
That last point is everything. When a CEO looks at a sales dashboard, they need to trust those numbers implicitly. That trust is built on the back of a solid ETL pipeline that has already scrubbed, validated, and organized the data. It’s what turns messy, raw information into a strategic asset that fuels confident, data-driven decisions.
Powering the Modern Data Ecosystem
It’s no surprise that the ETL market is booming. Valued at roughly $7.63 billion in 2021, it’s projected to skyrocket to $29.04 billion by 2029. This isn’t just hype; it’s a direct result of businesses needing to integrate data faster and more reliably to keep up with the demand for real-time analytics and automation.
The chart below shows just how significant this projected growth is.
This sharp upward curve tells a clear story: efficient data processing has become non-negotiable for any company that wants to stay competitive. This trend is also creating a huge demand for skilled engineers, with a steady increase in remote data pipeline job opportunities. At the end of the day, ETL isn’t just a technical task—it’s a foundational business capability.
Deconstructing The Three Stages of an ETL Pipeline
To really get a feel for how an ETL pipeline turns a mountain of raw data into a strategic asset, you have to break it down into its three core stages. Think of it like a specialized assembly line. Each station has a critical job, and if one part of the line goes down, the whole operation grinds to a halt.
This infographic lays out the journey perfectly, showing how data moves from its raw state, gets refined, and finally lands in its new home as a polished, ready-to-use product.
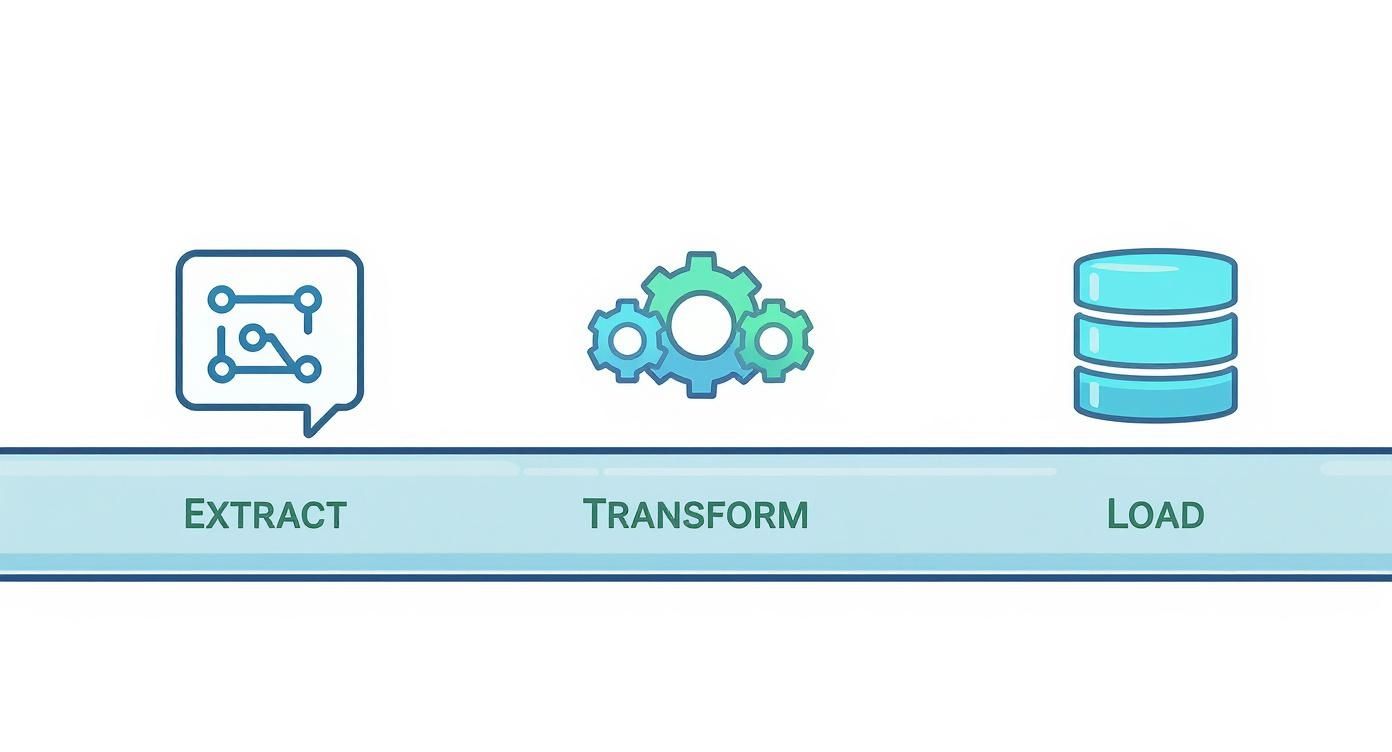
As you can see, each stage is sequential. You can’t transform data you haven’t extracted, and you can’t load data that hasn’t been transformed. This rigid, step-by-step flow is the classic signature of ETL.
Stage 1: Extract
It all starts with extraction—the process of gathering up the raw materials. Data rarely lives in one neat and tidy place. It’s usually scattered across dozens of different systems, each with its own quirks, formats, and access methods.
Extraction is all about pulling that data from its various homes, which might include:
- Structured Sources: These are your classic relational databases like PostgreSQL or MySQL, where data is organized into clean rows and columns.
- Semi-Structured Sources: Think of data from SaaS tool APIs, like Salesforce or Google Analytics, which often comes in a JSON format.
- Unstructured Sources: This is the messy stuff—plain text files, server logs, or even customer feedback emails that have no predefined structure.
The immediate goal is to get the data out of its native environment and into a temporary staging area where the real work can begin. One of the first big decisions you have to make here is how to extract it. A full load yanks the entire dataset every single time. It’s simple, but it becomes a massive bottleneck with large tables. The smarter approach is an incremental load, which only grabs the data that has changed since the last time you ran the pipeline. This saves a ton of time and computing power.
Stage 2: Transform
Now we get to the heart of the operation. The transform stage is where all the magic happens because raw data is almost always messy, inconsistent, and completely useless for analysis in its original state. This is where we clean it, reshape it, and enrich it to make it truly valuable.
Let’s say we’re working with e-commerce order data. The transformation process would look something like this:
- Cleaning: First, we tackle data quality. We might find orders with missing customer IDs, so we’d either flag them for review or filter them out entirely.
- Standardizing: Next, we enforce consistency. This could be as simple as converting all date formats to a universal
YYYY-MM-DDstandard or making sure all currency values are listed in USD. - Enriching: This is where we add context. We might join the order data with a separate customer database to pull in the customer’s name and location, making each order record far more insightful.
- Aggregating: Finally, we can perform calculations to create new metrics. A classic example is calculating the
total_order_valueby multiplying theitem_priceby thequantityfor each order.
By the end of this stage, that chaotic jumble of data is now structured, clean, and perfectly formatted for the destination system. Make no mistake, this is almost always the most computationally intensive part of any ETL pipeline.
Stage 3: Load
The final step is the load stage. Here, our newly polished and transformed data is delivered to its new home. This destination is usually a central repository built for analytics, like a data warehouse such as Snowflake or Google BigQuery. The whole point is to make the data easily accessible to BI tools, dashboards, and data science models.
Just like with extraction, you have choices on how you load the data. A full load might completely overwrite the destination table with the new data. It’s straightforward, but it can create downtime. A more elegant approach is an upsert (a combination of “update” and “insert”), which intelligently updates existing records that have changed while inserting any brand-new ones, all without disrupting the table.
The growing need for these complex data pipelines is fueling a massive market boom. The global data pipeline tools market is projected to skyrocket from $6.21 billion in 2025 to $16.74 billion by 2033. This incredible growth is driven by the sheer explosion of data and the rise of cloud platforms that make building and scaling these pipelines easier than ever before. You can dive deeper into these numbers in the full data pipeline tools market research.
By moving data methodically through these three stages, an ETL pipeline builds a reliable, high-quality data foundation that the entire organization can trust to make its most critical decisions.
Understanding Core Architecture and Key Components
Knowing that ETL stands for Extract, Transform, and Load tells you what a data pipeline does. But the architecture is all about how it gets the job done. A solid pipeline isn’t just a simple three-step process; it’s more like a well-rehearsed orchestra, with a whole suite of specialized components working in harmony.
Each piece has a specific role to play. You have the sources where the data is created, the tools that pull it all together, and the orchestrator that acts as the conductor, making sure everything happens at the right time.
Think of it like building a high-performance car. You need an engine, a chassis, a fuel system, and an onboard computer. Each part is critical, but they also have to be perfectly integrated for the car to run smoothly and reliably. The exact same principle applies to modern ETL data pipelines.

The Building Blocks of a Pipeline
When you look under the hood, every ETL pipeline is built from a handful of fundamental components. Getting a handle on these parts and how they interact is the first step toward designing a system that’s both powerful and efficient.
- Data Sources: This is where it all begins—the origin of your information. Sources can be anything from a transactional database like PostgreSQL, a SaaS platform like Salesforce, or even raw log files generated by a web server.
- Data Ingestion Layer: This component is the “Extract” muscle. It uses connectors and APIs to reach out to all your sources, pull the raw data, and bring it into a staging area where the real work can begin.
- Transformation Engine: This is the brains of the whole operation. Heavy-duty engines like Apache Spark or cloud services like AWS Glue take that raw data and do all the necessary cleaning, standardizing, and re-shaping to get it ready for analysis.
- Data Storage Target: Think of this as the pipeline’s library—the final destination for all that processed, analysis-ready data. It’s usually a cloud data warehouse like Snowflake or Google BigQuery, or sometimes a data lake, built for super-fast queries.
- Orchestration and Scheduling: This is the conductor that makes sure every step runs in the right order and on schedule. Tools like Apache Airflow or Prefect are used to map out the entire workflow, manage dependencies between tasks, and handle retries when things go wrong.
The Conductor Orchestrating the Flow
Without an orchestrator, an ETL pipeline would just be a messy collection of disconnected scripts. Orchestration tools are what turn those scripts into a reliable, automated process. They’re the ones that define the “what, when, and how” for every single task.
For instance, an orchestrator ensures a transformation job won’t even think about starting until the data has been successfully extracted from every single source. It also handles the timing, letting you run pipelines on a schedule—like every night at 2 AM—or trigger them based on specific events. This level of automation is what makes modern ETL so powerful; it gets rid of manual babysitting and guarantees consistency.
A well-orchestrated pipeline is like a perfectly timed relay race. Each runner (or component) knows exactly when to start and seamlessly passes the baton to the next, ensuring the race is completed efficiently and without any dropped batons.
The Rise of Cloud-Native Architecture
Not too long ago, ETL pipelines were built on-premises, which meant huge investments in physical servers and all the headaches that come with managing them. Today, the game has completely changed, with a massive shift toward cloud-native architectures. This approach taps into the power of the cloud to deliver incredible scale and flexibility.
Instead of buying and managing your own hardware, you can use services from cloud providers like AWS, Azure, or Google Cloud. This brings a few huge advantages to the table:
- Scalability: Cloud platforms can automatically scale resources up or down to match your workload. Got a massive transformation job? The platform can spin up hundreds of machines to crush it and then shut them down when it’s done, so you only pay for what you actually use.
- Flexibility: Cloud-native tools are designed to work together, plugging into a massive ecosystem of other cloud services, from machine learning platforms to business intelligence tools.
- Managed Services: Many of the key components, like transformation engines (AWS Glue) and data warehouses (BigQuery), are offered as fully managed services. This frees your data team from the drudgery of managing infrastructure so they can focus on building things that create real value.
This shift has made sophisticated ETL data pipelines more accessible than ever. To get a closer look at modern design patterns, check out our guide to data pipeline architecture. By understanding these core components and embracing a cloud-first mindset, you can build data systems that are not just functional, but genuinely game-changing.
Navigating Common ETL Challenges and Solutions
Getting an ETL data pipeline up and running is a great first step, but the real test is keeping it humming along, day in and day out. These systems are intricate, and they can fail in a hundred different ways—from a sudden explosion in data volume to a tiny, almost unnoticeable change in a source system’s format. The key to a reliable data flow isn’t just building the pipeline; it’s anticipating where it might break.
Think of your pipeline like a city’s water system. As long as it works, nobody even thinks about it. But one little clog, a sudden pressure spike, or a contaminated source can create a massive headache for everyone downstream. The best ETL pipelines are built with that reality in mind, designed to handle disruptions before they ever become a business problem.

Tackling Data Quality and Integrity
Let’s start with the most persistent headache in data engineering: the classic “garbage in, garbage out” problem. If you let messy data into your pipeline, you’ll get messy analytics out of it. This inevitably leads to flawed insights and, even worse, bad business decisions. The root cause could be anything from a simple user typo to a glitch in an upstream system.
The only way to win this fight is to treat the entrance to your pipeline like a heavily guarded checkpoint. You need robust data validation and cleansing rules right at the start of the transformation stage.
- Schema Validation: Be strict. Enforce rules that ensure incoming data looks exactly how you expect it to. If a record has the wrong data type or is missing a crucial column, it gets rejected or flagged for review.
- Integrity Checks: Go beyond structure and check for logic. A simple rule like ensuring an
order_datealways comes before ashipping_datecan catch a surprising number of errors. - Automated Cleansing: Don’t waste time on manual fixes for common problems. Build automated steps to standardize date formats, trim extra whitespace, or correct known misspellings.
Managing Scalability and Performance
Your business is growing, which means your data is growing with it. A pipeline that comfortably handles one million records a day might completely choke when it’s suddenly hit with ten million. Scalability isn’t a feature you can bolt on later; it has to be baked into the design from day one. In fact, this is one of the most common challenges of data integration teams run into.
Building for scale means assuming that today’s data volume is just a fraction of tomorrow’s. This mindset forces you to choose tools and architectures that can grow with you, not hold you back.
To build a pipeline that can keep up, look to cloud-native architectures that provide elastic computing. Services like AWS Glue or Google Cloud Dataflow can automatically spin up more resources when traffic spikes and then scale back down to save you money. It’s also smart to prioritize incremental loading (processing only new or changed data) over constantly reloading entire tables, which drastically cuts down on processing time.
Handling Schema Evolution and Source Changes
Source systems are never static. The team managing your CRM might push a software update that adds a new field, renames an old one, or changes a data format—often without telling you. This is called schema drift, and it’s a top-tier pipeline killer. A pipeline built with rigid expectations will shatter the moment the source schema deviates.
The antidote is to design your pipeline for flexibility from the ground up.
- Decouple Extraction and Transformation: Keep the logic that pulls data separate from the logic that cleans and shapes it. That way, a change in the source schema won’t automatically torch your entire transformation code.
- Use Schema Detection: Implement tools that can automatically spot changes in source schemas. When a change is found, the pipeline can either try to adapt on the fly or, more safely, send an alert to the data team to take a look.
- Implement Versioning: Treat your pipeline code and schemas just like any other software project. Use version control (like Git) to track every change, making it easy to see what happened and roll back to a stable version if an update causes chaos.
By getting out in front of these common issues, you can turn your ETL pipelines from fragile, high-maintenance systems into resilient, automated assets that your organization can truly rely on.
Best Practices for Modern ETL Data Pipelines
Getting an ETL data pipeline up and running is one thing. Building one that’s efficient, tough, and easy to maintain is what truly sets great data operations apart. Following modern best practices isn’t just about technical box-ticking; it’s about creating a framework that builds deep-seated trust in your data.
Think of it like this: you can slap together a rickety bridge that works on a calm day, or you can engineer one to withstand a hurricane. Both get you across, but only the second one is truly reliable. A proactive design approach ensures your data infrastructure can handle the unexpected, whether it’s a sudden flood of new data or a subtle change in a source system.
Automate and Orchestrate Everything
Manual work is the natural enemy of a scalable data operation. At the heart of any modern ETL pipeline is complete automation, typically managed by an orchestration tool like Apache Airflow. These tools act as the brain of your data workflows, figuring out dependencies, scheduling jobs, and automatically retrying tasks when they stumble.
This isn’t just about scheduling. It’s about building programmatic data quality checks, setting up automated alerts for failures, and managing deployments with version control. The ultimate goal is a “lights-out” system that runs itself, only needing a human touch for genuine emergencies, not routine upkeep.
Implement Comprehensive Logging and Monitoring
You can’t fix what you can’t see. When a pipeline fails without good logging, it becomes a black box, forcing engineers to spend hours playing detective to find the cause. Proper logging gives you a clear, step-by-step account of what happened, when it happened, and why it went wrong.
A mature ETL pipeline doesn’t just move data; it tells a story about its journey. Logging and monitoring are how you read that story, giving you the visibility needed to diagnose issues quickly and optimize performance over time.
This means keeping a close eye on key metrics to understand pipeline health:
- Data Volume: How many records did we actually process?
- Processing Time: How long did each stage of the journey take?
- Error Rates: What percentage of records failed our quality checks?
- Latency: How fresh is the data in our destination warehouse?
Design for Fault Tolerance and Scalability
A single hiccup should never crash your entire data ecosystem. Designing for fault tolerance means building pipelines that can handle the unexpected—like a brief network outage or a corrupted file—without falling apart. This involves smart retry logic and isolating workflows so a problem in one doesn’t trigger a domino effect across others.
At the same time, you have to build for scale. A big part of modern ETL is moving to the cloud and leveraging cloud platforms like Microsoft Azure to dynamically scale resources as needed. This flexibility is a huge reason why the data pipeline tools market is projected to hit $30 billion by 2030, driven by the demand for elastic systems that can power everything from sales reports to complex machine learning models. You can learn more about this explosive market growth on polarismarketresearch.com.
To tie these ideas together, here’s a quick summary of the most critical best practices for building and maintaining robust ETL pipelines.
Key Best Practices for Robust ETL Pipelines
Best PracticePrimary BenefitImplementation TipEnd-to-End AutomationReduces manual errors and frees up engineering time for higher-value work.Use an orchestration tool like Apache Airflow or Prefect to manage dependencies and schedules.Incremental Data LoadingMinimizes processing load and reduces run times by only handling new or changed data.Implement change data capture (CDC) or use watermarking with timestamps.Data Quality FrameworkBuilds trust in the data by catching issues early, before they impact business decisions.Integrate automated data validation tests (e.g., using Great Expectations) at key stages.Comprehensive MonitoringProvides real-time visibility into pipeline health, enabling proactive problem-solving.Set up dashboards and alerts for key metrics like latency, error rates, and data volume.Decoupled ArchitectureIncreases resilience by preventing a failure in one component from cascading to others.Use a message queue (e.g., Kafka) or cloud storage to buffer data between stages.Scalable InfrastructureEnsures the pipeline can handle growing data volumes without performance degradation.Design for the cloud, using services that can auto-scale compute and storage resources.
Adopting these practices shifts the focus from reactive firefighting to proactive engineering, ensuring your data pipelines are not just functional, but truly dependable assets for the business.
A Few Common Questions About ETL Pipelines
Even when you’ve got the basics down, a few practical questions always pop up when you’re in the trenches building or managing ETL data pipelines. Let’s clear up some of the most common ones.
What’s the Real Difference Between ETL and ELT?
The biggest difference boils down to one simple thing: when you transform the data.
With old-school ETL (Extract, Transform, Load), all the data cleaning, shaping, and structuring happens before it ever touches your data warehouse. Think of it as preparing ingredients in your kitchen before putting them in the oven. This approach ensures that only clean, ready-to-use data lands in your final destination.
ELT (Extract, Load, Transform) flips that script. It yanks the raw, untouched data out of the source and dumps it directly into the data warehouse first. All the transformation work then happens inside the warehouse itself, taking advantage of its massive processing power. ELT is generally faster to get started with and a lot more flexible for messy, unstructured data. The trade-off? You have to be disciplined, or you risk creating a chaotic “data swamp” inside your warehouse.
How Do I Choose the Right ETL Tool?
There’s no single “best” tool—the right one is whatever fits your team’s specific situation. It’s less about a tool’s bells and whistles and more about how it solves your problems.
Here’s what to think about:
- Your Stack: Does the tool actually connect to the databases, SaaS apps, and data warehouses you use every day? If it doesn’t have the right connectors, it’s a non-starter.
- Your Team: Be honest about your team’s skills. If you’re not a squad of seasoned coders, a tool with a slick visual interface is going to serve you far better than a complex, code-heavy framework.
- Your Data Load: Can the tool keep up? Make sure it can handle the amount of data you’re pushing and at the speed you need it—whether that’s big batches overnight or constant, real-time streams.
- Your Future: Will this tool still work for you in two years? Look for cloud-based platforms that can scale up or down automatically. It’s the smartest way to manage costs and avoid getting stuck with a tool you’ve outgrown.
The best tool is the one that makes your team’s life easier, not harder. It should get you to the finish line faster without piling up a mountain of technical debt along the way.
Can ETL Pipelines Actually Handle Real-Time Data?
Absolutely. The old image of ETL is a once-a-night batch job that chugs along while everyone’s asleep. And for a long time, that’s exactly what it was. But the game has completely changed.
Modern ETL platforms have evolved. They’ve borrowed ideas from the world of data streaming and now often include real-time capabilities.
Using clever techniques like Change Data Capture (CDC), these tools can grab and process data the instant it’s created. We’re talking about delays of seconds, not hours. This is what powers the live dashboards, instant fraud alerts, and up-to-the-minute operational systems that modern businesses rely on. So, while “ETL” might sound like a batch process, today’s pipelines are more than capable of keeping up with the speed of your business.
Ready to move beyond slow, cumbersome batch jobs? Streamkap leverages real-time Change Data Capture (CDC) to build streaming ETL data pipelines that are 90% more efficient than legacy solutions. See how it works and start building for free.