How to Stream PostgreSQL to Databricks with Streamkap
Ricky Thomas
March 30, 2025
TL;DR
• Stream PostgreSQL to Databricks in minutes for predictive maintenance and equipment health monitoring use cases. • Capture operational data in real-time and build high-performance analytics pipelines for sensor readings and telemetry. • Set up sub-second latency pipelines at lower cost than traditional ETL methods.
Introduction
In today’s fast-moving world, businesses need the right data at the right time to make smart decisions. But let’s face it—traditional data processing can be slow and complicated.
That’s where Streamkap steps in to save the day and help you Streamkap-italize your data! With Streamkap, you can set up real-time streaming from AWS PostgreSQL to Databricks in just minutes—not months.
Developers can implement this guide to deploy predictive maintenance and equipment health monitoring on Databricks, leveraging real-time data streaming from PostgreSQL. By capturing operational data from PostgreSQL and streaming it to Databricks, teams can build a high-performance analytics pipeline capable of handling large-scale sensor readings, equipment telemetry, and maintenance records.
Guide Sections:
| Prerequisites | You will need Streamkap and Aws accounts |
|---|---|
| Setting up a New RDS SQL Server From Scratch | This step will help you to set up SQL Server inside AWS |
| Configuring an Existing RDS SQL Server | For existing SQL Server DB, you will have to modify its configuration to make it Streamkap-compatible |
| Creating a New Snowflake Account | This step will help you set up a Snowflake account |
| Fetching credentials from existing Snowflake destination | For the existing Snowflake connection, you will have to modify its permissions to allow Streamkap to write data |
| Streamkap Setup | Adding Postgres as a source, adding Snowflake as a destination, and finally connecting them using a data pipe |
Ready to Streamkap-italize your data? Let’s go!
Prerequisites
To follow along with this guide, ensure you have the following in place:
-
Streamkap Account: To get started, you’ll need an active Streamkap account with admin or data admin privileges. If you don’t have one yet, no worries—you can sign up here or ask your admin to grant you access.
-
Databricks Account: An active Databricks account is required with data warehouse administrative privileges. If you don’t have one yet, sign up here.
-
Amazon AWS Account: An active Amazon AWS account with core RDS and networking permissions to create, configure or modify an AWS RDS instance. If you don’t have one yet, sign up here.
AWS RDS PostgreSQL Set Up
AWS RDS PostgreSQL stands out as one of the most widely used production databases. Its global adoption and everyday usage have prompted Amazon to make it exceptionally user-friendly. New users can set up an RDS PostgreSQL instance from scratch in just a few minutes. Additionally, if you already have an existing instance, it’s straightforward to add the necessary configuration for Streamkap streaming.
In this section, we will explore various methods to set up and configure AWS RDS PostgreSQL to ensure compatibility with Streamkap.
Setting up a New AWS RDS PostgreSQL Instance from Scratch
Note: To set up a new AWS RDS PostgreSQL instance, you need IAM permissions for creating and managing RDS instances, parameter groups, subnet groups, networking, security, monitoring, and optional encryption and tagging.
If you are restricted by permissions, please ask your AWS administrator to grant you core RDS and networking permissions.
Step 1: Access the AWS Management Console
- Log in to your AWS management Console and type “RDS” on the search bar.
- Click on “RDS” as shown below

Step 2: Create a new RDS PostgreSQL Instance
- Step 1 will take you to the RDS dashboard. From there, click on either “Databases” in the top left corner or “DB Instances” under the Resources section as depicted below.

- Select the region where you want your RDS instance to be hosted, then click “Create database” as shown in the following screenshot

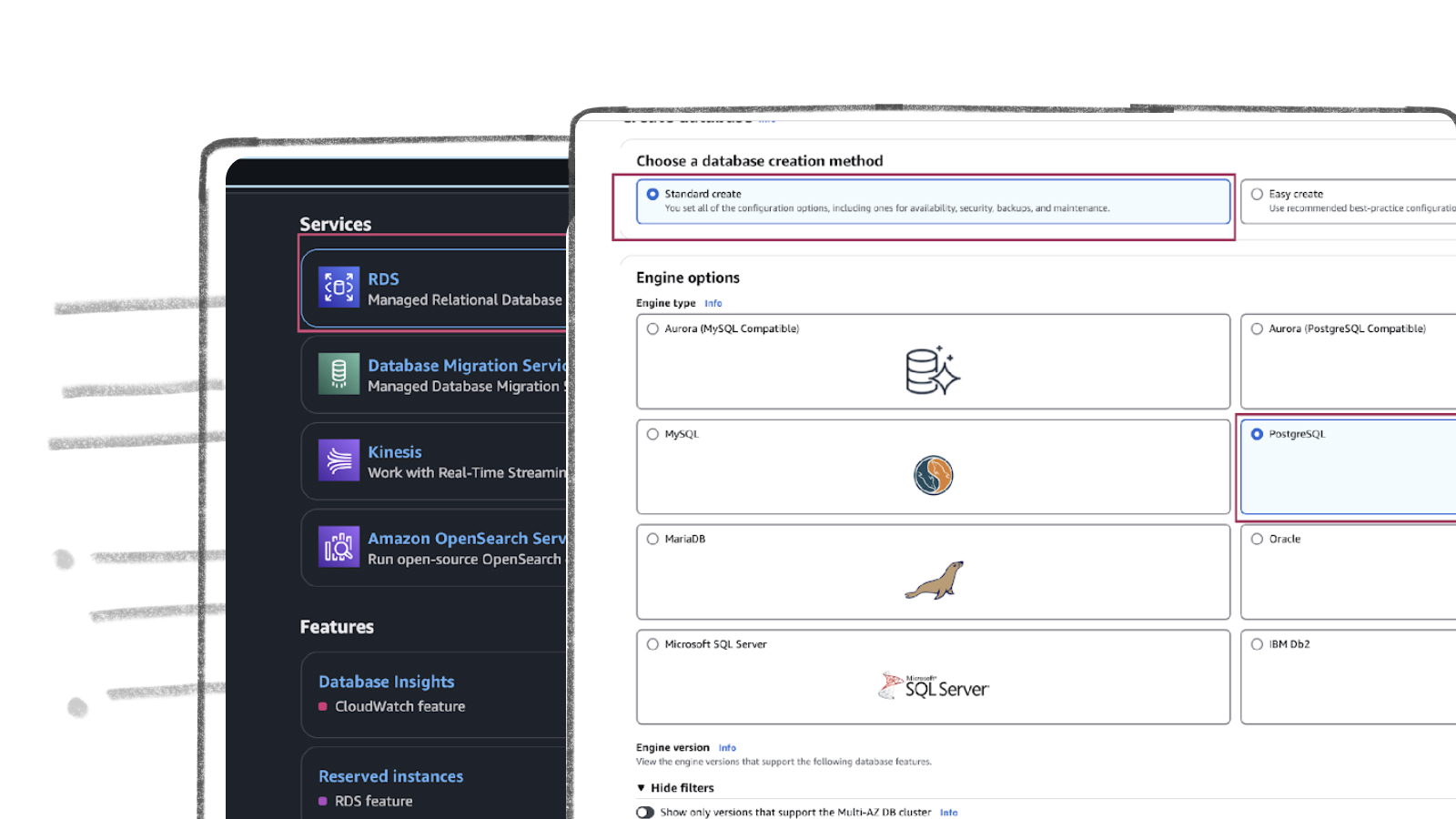
- Click “Standard create” radio button in the Choose a database creation method section
- Click “PostgreSQL” radio button in the Engine option section
- Scroll down and choose “PostgreSQL 16.3-R3” from Engine version drop down menu as shown below

- Under the Templates section choose between “Production”, “Dev/Test”, “Free tier” based on your need.
- If you’re deploying sub-second latency streaming for the first time, we recommend selecting the “Free tier” as shown in the following screenshot to familiarize yourself with the end-to-end process without incurring cloud costs.

- In the Settings section plug in a unique value for
- DB Instance identifier
- Master username
- Click “Self managed” radio button on the Credentials management section and fill in values for Master password
- Confirm master password

- In the Connectivity section, click “Yes” for Public access as illustrated below

- In the Additional Configuration section, plug in an Initial database name as shown below

- Scroll to the bottom and click “Create database”. Wait until your DB instance becomes available as shown below

Step 3: Configuring Your PostgreSQL Instance for Streamkap Compatibility
By default, an AWS RDS PostgreSQL instance is not compatible with Change Data Capture (CDC). To enable sub-second latency streaming, minor adjustments must be made to the database to make it CDC-compatible.
In this section of the guide, we will
- Create a new parameter group
- Modify rds.logical_replication = 1
- Modify wal_sender_timeout = 0
- Attach the new parameter group to our PostgreSQL Instance
- Restart the PostgreSQL Instance to apply changes
- On your RDS dashboard click on “Parameter groups” on the left side and then click on “Create parameter groups” as shown in the following screenshot

- Plug in a “Parameter group name”, “Description”, choose “PostgreSQL” as engine type, choose “postgres16” as parameter group family and choose “DB Parameter Group” as Type and click “Create” as shown below.

Once your parameter group is created, click on your parameter group and click on the “Edit” button on the right-side corner of the screen.
- On the search bar
- Type “rds.logical_replication” and add “1” as value as shown below.
- Type “wal_sender_timeout” and add “0” as value as shown below.


- Click “Save Changes”.
We have successfully created a parameter group configured for Change Data Capture (CDC). The next step is to attach this parameter group to the PostgreSQL instance to enable CDC compatibility for the database.
- Open your PostgreSQL instance from the RDS dashboard page and click “Modify” on the top right corner as illustrated below

- Scroll to the “Additional configuration” section. Under “DB Parameter Group”, choose the newly created parameter group from the list. Scroll to the bottom of the screen and click “Continue”.

- On the Modify DB instance page ensure Change Data Capture compatible parameter group shows as new value, under “Schedule modification”, click “Apply immediately” radio button and then click on “Modify DB instance”.

Step 4: Test Your PostgreSQL Instance for Change Data Capture (CDC) and Streamkap Compatibility
It’s crucial to verify that changes made to the PostgreSQL instance are properly reflected within the database. To do this, connect to your RDS PostgreSQL instance using tools like DBeaver and run the following commands to ensure CDC functionality is working as expected.


Note: If you encounter a timeout error while accessing your AWS PostgreSQL instance from your local machine, it’s possible that the security group is not allowing inbound traffic from your local machine. To resolve this, you’ll need to modify the inbound rules of your security group to permit access from your local machine to your cloud PostgreSQL instance.
Configuring an Existing RDS PostgreSQL Instance for Streamkap Compatibility
If you already have an existing AWS RDS PostgreSQL instance, it may or may not be compatible with change data capture (CDC). To determine if it is compatible, we will perform two tests. Both tests must pass in order to confirm that the instance is CDC-compatible.
To perform these tests, connect to your RDS PostgreSQL instance using tools like DBeaver and run the following commands to ensure CDC functionality is working as expected.
Both tests must return the expected values (wal_level = logical and wal_sender_timeout = 0) for the RDS instance to be CDC-compatible. If either test fails, adjustments to the RDS parameter group may be required.
If these tests do not return the expected values, you will need to modify the existing custom RDS parameter group or create a new parameter group with the necessary changes to enable Change Data Capture (CDC) compatibility. Specifically, you’ll need to configure the following parameters.
If you already have an existing custom RDS parameter group skip to step 2.
Step 1: Create a Customer RDS Parameter Group
- On your RDS dashboard click on “Parameter groups” on the left side and then click on “Create parameter groups” as shown in the following screenshot

- Plug in a “Parameter group name”, “Description”, choose “PostgreSQL” as engine type, choose “{your Postgres engine version}” as parameter group family and choose “DB Parameter Group” as type and click “Create” as show below.

- Once your parameter group is created, click on your parameter group and click on the “Edit” button on the right-side corner of the screen.
- On the search bar
- Type “rds.logical_replication” and add “1” as value as shown below.
- Type “wal_sender_timeout” and add “0” as value as shown below.


- Click “Save Changes”.
We have successfully created a parameter group configured for Change Data Capture (CDC). The next step is to attach this parameter group to your existing PostgreSQL instance to enable CDC compatibility for the database.
Step 2: Attaching Parameter Group to RDS PostgreSQL Instance
- Open your PostgreSQL instance from the RDS dashboard page and click “Modify” on the top right corner as illustrated below

- Scroll to the “Additional configuration” section. Under “DB Parameter Group” choose the newly created parameter group from the list. Scroll to the bottom of the screen and click “Continue”.
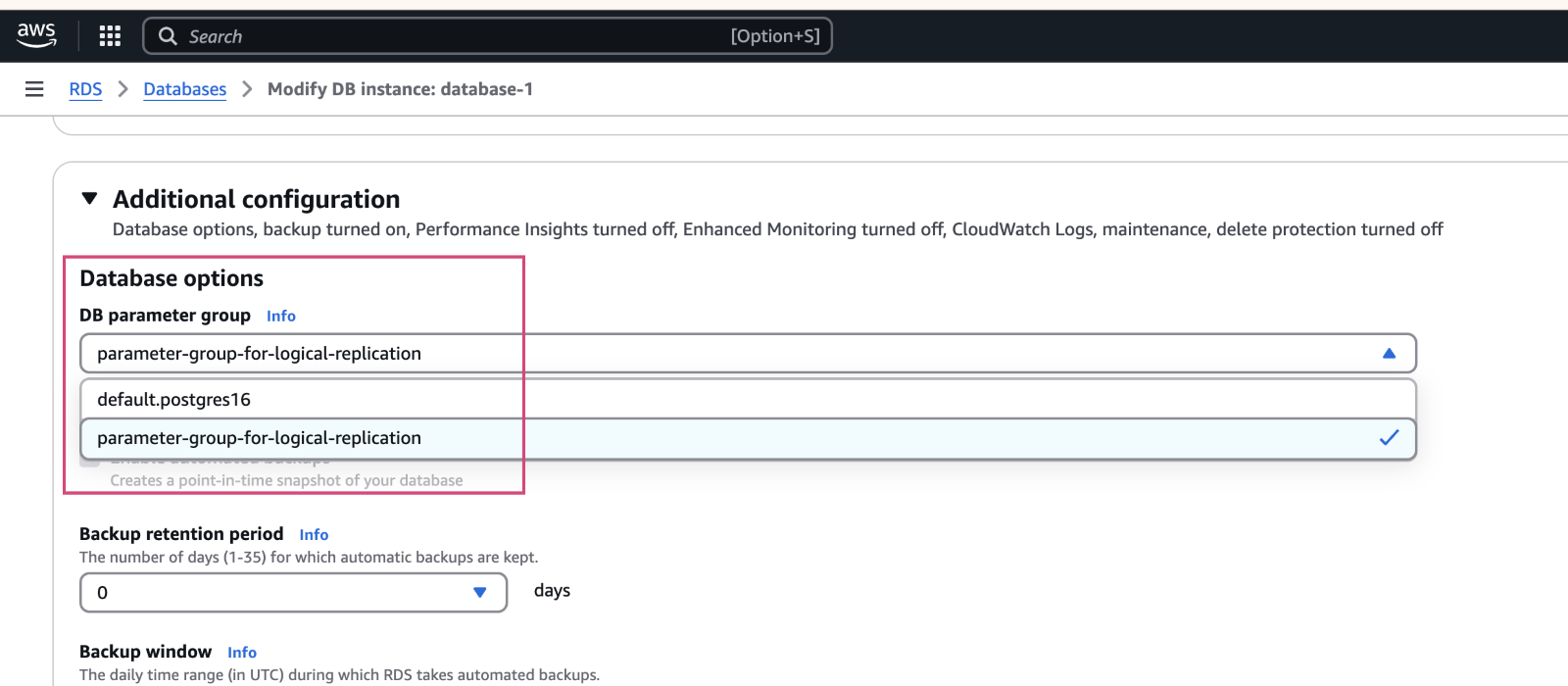
- On the Modify DB instance page ensure Change Data Capture compatible parameter group shows as new value, under “Schedule modification”, click “Apply immediately” radio button and then click on “Modify DB instance”.

- After the modification of your RDS PostgreSQL instance is complete, run the following commands again to ensure CDC functionality is working as expected.
Databricks Warehouse Set Up
Getting started with Databricks is a breeze, regardless of your experience level. This guide provides clear instructions on how to create a new account or use your existing credentials, ensuring a smooth and efficient streaming process.
Creating a New Databricks account
Step 1: Sign up and create a Databricks account
- Visit Databricks’ website and click on “Try Databricks.”
- Fill in the requested details and create a Databricks account.
- When you log in to the account that was created a few seconds ago you will land on the “Account console” page that looks like the following.

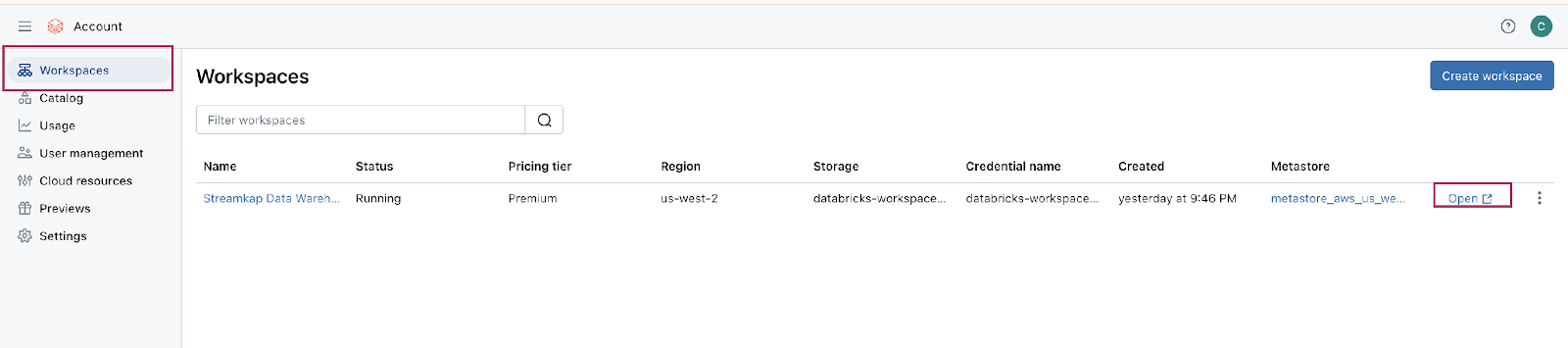
Step 2: Create a new Databricks Workspace
- Click on “Workspaces” on the top left corner of the screen and then click on “Create workspace” on the top right corner of the screen. A page like the one presented below should appear

- Choose “Quickstart (Recommended)” and click next.
- Fill in the workspace name.
- Choose your desired region and click “Start Quickstart”. Databricks will take you to your AWS console.
- Scroll down and Click “Create stack”. After a few minutes, return to your Databricks workspace and it will be ready, as illustrated below.
Step 3: Create a new SQL Data warehouse
- On your Databricks workspace page click on “Open” and you will be taken to your new data warehouse.
- On your new data warehouse click on “+ New” and then on “SQL warehouses” as highlighted in below image.

- Click on “Create SQL warehouse” and the following configuration modal will appear

- Plug your new SQL warehouse details. For this guide we recommend you use the minimum available cluster size, which is 2X-Small, to reduce cost.
- Click “Create” and within seconds your new data warehouse will be up and running.
Step 4: Fetch credentials from your new data warehouse
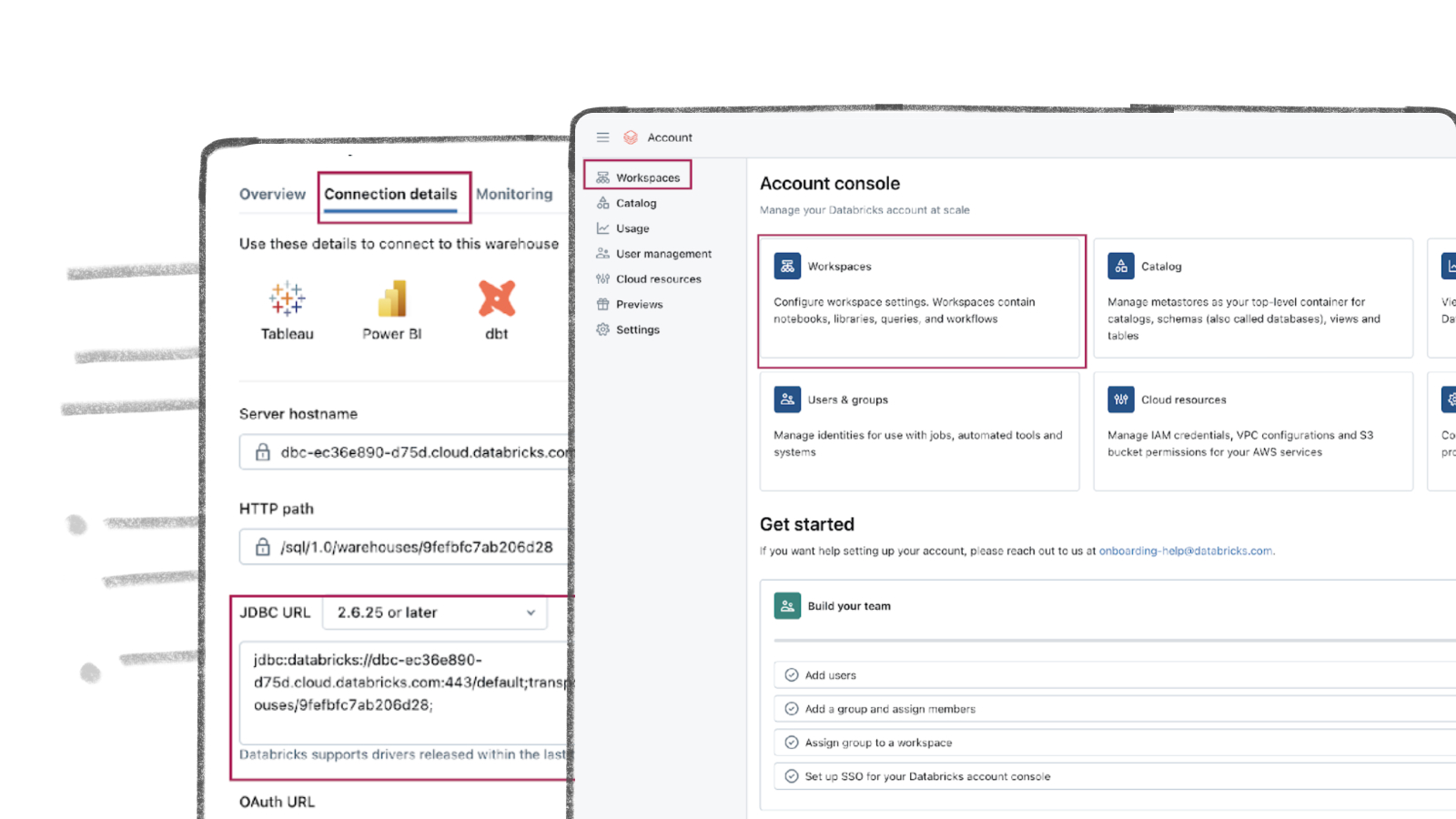
- On your new data warehouse click on the “Connection details” tab as presented in the following illustration.

- Copy the JDBC URL into a secure place.
- Create a personal access token from the top right corner of the screen and store it in a secure place.
- We will need the JDBC URL and personal access token to connect Databricks to Streamkap as a destination connector.
Fetching credentials from existing Databricks warehouse
Step 1: Log in to Your Databricks Account
- Navigate to the Databricks login page.
- Plug in your email and hit “Continue”. A six digit verification code will be sent you your email.
- Plug in the six digit verification code and you will land in the “Account console” page that looks like the following

Step 2: Navigate to your Databricks warehouse
- Click on “Workspaces” and then click on “Open” button next to the corresponding workspace as illustrated below.

- Once you land on your desired workspace, click on “SQL Warehouses”. This will list your SQL warehouses as outlined below.

Step 3: Fetch credentials from your existing data warehouse
- Choose the data warehouse you wish to fetch credentials from. Click on the “Connection details” tab as presented in the following illustration.
- Copy the JDBC URL into a secure place.
- Create a personal access token from the top right corner of the screen and store it in a secure place.
- We will need the JDBC URL and personal access token to connect Databricks to Streamkap as a destination connector.
Note: If you cannot access the data warehouse or create a personal access token, you may have insufficient permissions. Please contact your administrator to request the necessary access.
Streamkap Set Up
To connect Streamkap to AWS RDS PostgreSQL, we need to ensure the database is configured to accept traffic from Streamkap by safelisting Streamkap’s IP addresses in the PostgreSQL instance.
Note: If your AWS RDS PostgreSQL instance accepts traffic from anywhere from the world you can move on to the “Configuring AWS RDS PostgreSQL Database for Streamkap Integration” section.
Safelisting Streamkap’s IP Address
Streamkap’s dedicated IP addresses are
| Service | IPs |
|---|---|
| Oregon (us-west-2) | 52.32.238.100 |
| North Virginia (us-east-1) | 44.214.80.49 |
| Europe Ireland (eu-west-1) | 34.242.118.75 |
| Asia Pacific - Sydney (ap-southeast-2) | 52.62.60.121 |
When signing up, Oregon (us-west-2) is the default region. Let us know if you need it to be elsewhere. For more information about our IP addresses please visit this link.
- In order to safelist one of our IPs, open your RDS PostgreSQL instance’s security group with type = “CIDR/IP - Inbound” and click “Edit inbound rules”.
- Click on “Add rule”, choose “PostgreSQL” as type, “Custom” as source, and paste any of our relevant IP addresses followed by “/32”. For instance, if you want to add IP address for Oregon in the custom box it would look like “52.32.238.100/32” as shown in the below image.

Configuring AWS RDS PostgreSQL Database for Streamkap Integration
Streamkap recommends creating a dedicated user and role within your PostgreSQL instance to facilitate secure and controlled data streaming. This approach ensures granular access management and follows best practices for database security.
Access your PostgreSQL database via a tool like Dbeaver and run the following code
Step 1: Create a dedicated user and role for Streamkap
```sql
Note: You must plug in your own password
Step 2: Attach role to user and grant replication privileges to the role
```sql
Step 3: Grant permissions on the database```sql
Note: In this guide our initial database at the time of configuration was “source_database”. Plug in your own database name if it is different from the one mentioned earlier.
Step 4: Grant permissions on schema(s), table(s), and future table(s)
```sql
Note: In this guide our initial schema at the time of configuration was “public”. Plug in your own schema name if it is different from the one mentioned earlier.
```sql
Step 5: Enabling Streamkap signal schema and table
Streamkap will use the following schema and table to manage snapshot collections.
```sql
Step 6: Creating sample table
Let’s create a sample table from which Streamkap will stream data. If you already have an existing table(s), you would like to stream from, you can skip this step.
```sql
Step 7: Create publication(s), and replication slot
We can create publication(s) for all tables or for only the sample orders table that was created few seconds ago or for a select group of tables
```sql
```sql
Adding RDS PostgreSQL as a Source Connector
Before proceeding to add RDS PostgreSQL as a source connector
- Ensure that our IP address is safelisted, or that your RDS PostgreSQL instance is configured to accept traffic from Streamkap by default.
- Make sure you have successfully ran all SQL code mentioned in the “Configuring AWS RDS PostgreSQL Database for Streamkap Integration” section
The above two points mentioned are mandatory in order to successfully connect your AWS RDS PostgreSQL as a source with Streamkap.
Note: If you are using PostgreSQL 16, you can connect your clone to Streamkap, and it will function as expected. However, for PostgreSQL 15 or earlier, you must connect directly.
Step 1: Sign-in to Streamkap
- Visit the Streamkap sign-in link and log in. You will land in the dashboard page.
Note: You need admin or data admin privileges to proceed with the subsequent steps.
Step 2: Create a PostgreSQL source connector
- Click “Connectors” on the left side, then click on “Sources” tab, and then click on the “+ Add” button as depicted below.

- Scroll and choose “PostgreSQL”. You will land on the new connector page.
- You will be requested to fill
- Name – Your preferred name for the PostgreSQL source within Streamkap
- Hostname – Copy Endpoint under the “Connectivity & security” tab on your RDS PostgreSQL instance
- Port - The default port is 5432. If you have changed the port number, make sure to replace it accordingly.
- Username – Streamkap_user. We created this in the previous section
- Password – Your user’s password
- Database – source_database if you followed the guide or your own database name
- Signal Table Schema – Streamkap_signal if you followed the previous step or enter your own schema name.
- Note: By default, you will see “public” as Signal Table Schema. Please replace accordingly - Heartbeat – Turn the toggle “On” and fill Streamkap_signal as value if you followed the previous step or enter your own schema name.
- Replication Slot Name - Streamkap_pgoutput_slot if you followed the previous step or enter your replication slot name.
- Publication Name – Streamkap_pub if you followed the previous step or enter your publication name.

If you decide to not use SSH Tunnel press “Next” and go to step 3.
If you decide to connect to your AWS RDS PostgreSQL via an SSH Tunnel ensure
- Your bastion host / SSH Tunnel server is connected with your PostgreSQL instance
- Your bastion host / SSH Tunnel server allows traffic from anywhere or safe listed Streamkap IP Address
Login to your Linux SSH Tunnel host and run the following commands. If you are using a Windows server visit our SSH Tunnel guide for Windows.
After running the above commands, fetch the SSH Public Key from Streamkap’s PostgreSQL source as depicted below.

Replace with the SSH Public key copied from earlier and run the following code
After your SSH Tunnel server is restarted plug in your SSH Tunnel server’s public IP address as SSH Host in Streamkap and press “Next”. You will land on the schema and table selection page like the following.
Step 3: Plugging in Schema and Table Names

If you followed the guide, your PostgreSQL database should now include an “orders” table in the “public” schema. If you are using a different schema, update the relevant schema and table names, then click “Save.”
If all the steps were completed correctly, you should be able to successfully create a PostgreSQL source connector as shown below.

- In case you encounter any fatal errors, they could be caused by one of the following:
- Our IP addresses were not safelisted.
- Incorrect credentials.
- Incorrect database, schema, or table name.
- Insufficient permissions to query the table.
Adding a Destination Connector
To add Databricks as a destination connector click on “Connectors” on the left side, then click on “Destinations” and press the “+ Add” button.

You will land in the Databricks destination connection configuration page as shown below.

Plug in your desired
- Name
- Choose “append” or “insert” as ingestion mode
- Paste the personal access token and JDBC url retrieved from Databricks Warehouse Set Up section of this guide
- Key in the destination schema of your choice
Press “Save” on the right-side bottom of the screen.
If all goes well your Databricks destination will be created with status as “Active” as shown below.
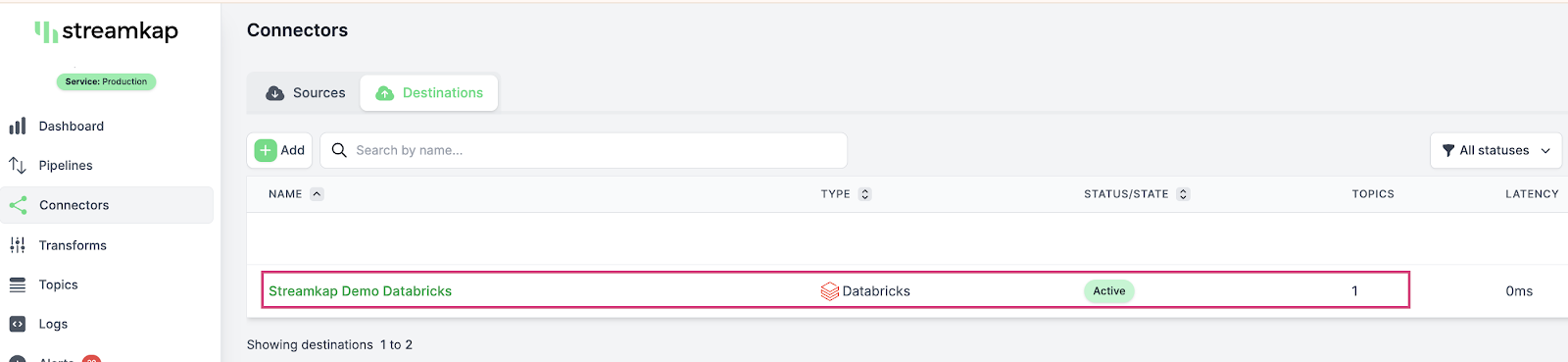
Adding a Pipeline
Click on “Pipelines” on the left side of the screen, click on “+ Create” and then choose your relevant Postgres source from “select a Source” and your Databricks destination from “select a Destination” as depicted below.

Select the “Orders” table and the “Public” schema if you followed the guide. Otherwise, make the appropriate selections and click “Save.”

Upon successful creation of the pipeline, it should look similar to the below screenshot with status as “Active”.

Go to your Databricks warehouse and query the “orders” table to see sub-second latency streaming in action as shown below.

By design Your “Orders” in the destination will have the following meta columns apart from the regular columns.
| Column Name | Description |
|---|---|
| _STREAMKAP_SOURCE_TS_MS | Timestamp in milliseconds for the event within the source log |
| _STREAMKAP_TS_MS | Timestamp in milliseconds for the event once Streamkap receives it |
| __DELETED | Indicates whether this event/row has been deleted at source |
| _STREAMKAP_OFFSET | This is an offset value in relation to the logs we process. It can be useful in the debugging of any issues that may arise |
What’s Next?
Thank you for reading this guide. If you have other sources and destinations to connect in near real-time check out the following guides.
For more information on connectors please visit here
Ricky Thomas
LinkedInAuthor Bio
Ricky has 20+ years experience in data, devops, databases and startups.
Published
March 30, 2025
TL;DR
• Stream PostgreSQL to Databricks in minutes for predictive maintenance and equipment health monitoring use cases. • Capture operational data in real-time and build high-performance analytics pipelines for sensor readings and telemetry. • Set up sub-second latency pipelines at lower cost than traditional ETL methods.
Related blog posts
.png)
Why Apache Iceberg? A Guide to Real-Time Data Lakes in 2025
Apache Iceberg brings SQL tables to cloud storage with ACID transactions and time travel. Learn why it's essential for 2025.
AWS RDS PostgreSQL Set Up
AWS RDS PostgreSQL stands out as one of the most widely used production databases. Its global adoption and everyday usage have prompted Amazon to make it exceptionally user-friendly. New users can set up an RDS PostgreSQL instance from scratch in just a few minutes.
Databricks Warehouse Set Up
Getting started with Databricks is a breeze, regardless of your experience level. This guide provides clear instructions on how to create a new account or use your existing credentials, ensuring a smooth and efficient streaming process.