Snowflake Snowpipe Streaming with Change Data Capture (CDC)
Ricky Thomas
August 27, 2023
TL;DR
• Stream CDC data into Snowflake with sub-second latency using Snowpipe Streaming API. • Streamkap customers stream billions of records into Snowflake with support for inserts, upserts, and schema drift. • Set up Snowflake streaming in less than 5 minutes, including snapshotting, backfilling, and cost-effective data loading.
Table of Contents
No sectionsSnowflake is a data warehouse, often now referred to as Snowflake Data Cloud with all the Snowflake features it provides. It is now possible to stream data into Snowflake with low latency using a new feature called Snowpipe Streaming, which is a snowflake streaming API to load data. This is a significant change over the previous methods for bulk loads with files.
Organizations are increasingly moving away from batch processing and towards real-time streaming while capturing data using Change Data Capture (CDC).
In this blog, we will look at how to stream into Snowflake with Streamkap in less than 5 minutes as well as cover some important components such as inserts vs upserts, schema drift, snapshotting/backfilling, metadata, costs, and monitoring.

What is Snowflake Streaming CDC (Change Data Capture)?
- Snowflake Change Data Capture (CDC) is a technique used to track and capture data changes from source databases and transmit them to Snowflake. It involves the extraction of data from various source databases such as PostgreSQL, MongoDB, MySQL, SQL Server, and Oracle using each database log file.
- Snowflake Streaming, also known as Snowpipe Streaming, enables streaming inserts whereas Batch ETL occurs at predefined intervals. Explore our blog on Batch vs Real-Time Stream Processing for more information.
- Learn more at Change Data Capture for Streaming ETL

Why use Snowflake for Streaming CDC Data?
Key advantages of Snowflake for streaming data include:
- Real-Time Data Ingestion: The new Snowpipe Streaming API supports Kafka and real-time vs the previous solutions which involved S3 as a staging area. Streamkap has customers streaming billions of records into Snowflake.
- Cost: Inserting data using the new Snowflake Streaming API is very cost-effective.
- Scalability: Snowflake’s cloud-native architecture allows it to effortlessly scale up or down, ensuring efficient resource allocation for various workloads. This enables organizations to manage large volumes of streaming CDC data and support numerous concurrent users without performance degradation.
- Elasticity: Snowflake’s ability to independently scale storage and compute resources allows it to adapt to changing workloads or data sizes seamlessly.
- Data Sharing: Snowflake’s data-sharing capabilities allow organizations to share streaming CDC data securely and in real-time with both internal and external partners.
- Use Cases: Perfect for data warehousing use cases including real-time analytics and data science applications.
- Open Source tools like Apache Kafka or Apache Flink, combined with Debezium connectors and Snowflake’s Kafka Connector empower you to stream real-time Change Data Capture (CDC) directly into Snowflake.
- Streamkap is a managed platform built on top of Apache Kafka & Debezium that leverages its capabilities along with production-ready connectors to enable fast and efficient data ingestion into Snowflake within just minutes. By simplifying the process, Streamkap removes the need for extensive resources, steep learning curves, and continuous support typically required to maintain a data streaming platform. This seamless integration with Snowflake ensures real-time data processing and analytics for organizations.
Snapshotting
In the context of Streamkap and Snowflake data streaming, an initial snapshot and incremental snapshots refer to distinct stages of capturing and processing data changes from source databases. Here’s a brief description of the differences between the two:
Initial Snapshot
The initial snapshot is a process that captures the complete dataset from a source table when creating a connector. This step establishes a baseline for future change data capture operations. During the initial snapshot, Streamkap reads the data present in the source table, generates corresponding events, and forwards them to the specified Snowflake target system. This process guarantees that Snowflake tables begin with a comprehensive and consistent copy of the data from the source database.
Incremental Snapshots
Incremental snapshots address the problem with initial snapshots in that new data is not streamed until the snapshot is complete. Conversely, incremental snapshots enable concurrent snapshotting and change data streaming. This method divides the snapshot process into smaller segments using low and high watermarks in the transaction log. The system captures a part of the table’s data between the two watermarks while simultaneously monitoring database changes that occur between them. If any records are snapshotted and modified during this window, the system reconciles the changes with the snapshotted values.
Incremental snapshots provide several advantages, such as:
- Elimination of the need for an extended snapshot process at the connector’s start, enabling faster data streaming.
- Enhanced fault tolerance, as the snapshotting process can resume from the last completed segment in the event of configuration changes or other interruptions.
Working with Inserts (Append-Only) Data
Snowpipe Streaming supports inserts (append-only) at present. Usually, customers wish to work with a set of cleaned tables presenting only the upserted versions and this can be achieved in several ways but before we look at this, let’s just cover Inserts vs Upserts.
INSERTS will add records for each value and not overwrite/update any other values. The benefit of INSERTS is that they are often cheaper to perform, faster, and allow for point-in-time analysis. If you work with Inserts you will likely need to clean up the older data from time to time.
UPSERTS, as mentioned above, is both an UPDATE+INSERT. If there is a match on a key, the value will be overwritten and if there is no match the event will be inserted.
For example, there is a diagram below showing this in simplified terms.
- Starting with 3 rows here, represented as Green, Blue & Grey.
- The new rows to process are Blue & Pink.
- The resulting table has an updated row for Blue and a new row for Pink.
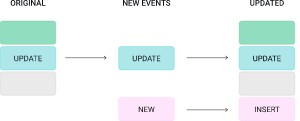
How to work with Inserts (Append_Only) data
Tables via Merge
It’s possible to run MERGE regularly using Scheduled Tasks merging the inserted data into a new target table. The MERGE syntax looks like this:
This will operate under a Snowflake Warehouse and thus will add a small amount of incremental cost to the data ingestion.
Tables via Incremental DBT Models
Similar to using the Merge statement, it’s possible to create incrementally updated tables via DBT. A good walkthrough on how to do this is available here on the topic of Data Activation.
Views
Views are slow on Snowflake when looking at large amounts of data using the window function, but is still useful when querying the source table.
View syntax will look like this:
Dynamic Tables (Private Preview feature from Snowflake)
Dynamic tables in Snowflake represent a novel table type that allows teams to use straightforward SQL statements to declaratively define their data pipeline results. As data changes, Dynamic Tables automatically refresh, operating solely on new changes since the last update. Snowflake transparently manages the scheduling and orchestration needed to accomplish this, simplifying the overall process.
Dynamic Tables provide real-time fast performance with streaming data and simplify the overall process. Here is an example of a simple SQL statement to create a Dynamic Table
And this shows you the simplification:

Historical Data Clean Up
A result of using Inserts as an ingestion method with Change Data Capture (CDC) is that you have a full audit of every change that has happened from the source databases. This can be very useful for point-in-time analysis or understanding how values have changed over time. On the flip side, you may not need this raw data and therefore would like to delete the stale data.
Here is an example script to clean up old records, which you may want to run once daily using Snowflake Scheduled Queries.
Metadata
When inserting data into Snowflake, Streamkap provides some additional metadata dimensions to be added to your Snowflake tables.
- SOURCE_TS_MS - This is the timestamp of the row within the source table from the source database. Timestamp in milliseconds.
- OFFSET - This is the record offset in Kafka.
- __DELETED - 0 or 1. Allows you to handle deleted records.
Transformations
Transformations can happen within Snowflake or using in-stream processing.
With in-stream processing, we can transform the data in real-time as it processes through the pipeline to perform actions such as filtering, masking, and aggregations. This new/modified data may be inserted into the Snowflake data warehouse or could also be sent to other destinations for varying use cases.
Monitoring Streaming Data Pipelines with Snowflake
Due to the nature of distributed systems, monitoring is often the biggest issue for organizations and the reason they turn to managed solutions for their production pipelines. Streamkap keeps the pipelines stable and scalable and provides real-time metrics such as Lag in both time and number of events.
Schema Drift with Snowflake Streaming
Schema drift is essential for production pipelines. Streamkap supports the handling of schema drift on all data sources and ensures these schema changes are evolved in Snowflake.
Snowpipe Streaming API vs Snowpipe
The Snowpipe Streaming API is designed to complement Snowpipe, rather than replace it. Previously, if organizations wished to load data faster, they kept sending lots of files to Snowpipe. This is inefficient and costs soon add up. Snowpipe Streaming is perfect for real-time data at lower costs than previously available.
How does it work?
Compared to bulk data loads or Snowpipe, which writes data from staged files, the streaming insert API directly writes rows of data to Snowflake tables. The write-directly approach leads to reduced load latencies and lower costs for loading similar volumes of data, making it a highly effective tool for handling real-time data streams.
The API operates by writing rows from channels into blobs in cloud storage, which are then committed to the target table. Initially, the streamed data is stored in a temporary intermediate file format within the target table, resulting in a “mixed table” where partitioned data is stored in a combination of native and intermediary files. As required, an automated background process migrates the data from the active intermediary files to native files that are optimized for query and DML operations.
Cost of using Snowflake Streaming
Types of Charges
There are two costs related to Snowpipe Streaming and the total cost is therefore the total of both Service Migration Costs. Migration in this instance refers to the automatic background process mentioned above.
Service Cost
- This is the streaming insert time.
- Calculated per hour of each client runtime multiplied by 0.01 credits.
- Client runtime is collected in seconds, meaning that 1 hour of client runtime is 3600 seconds.
- If Streamkap is actively sending rows in every second of a 30-day month, the Snowpipe Streaming cloud services charge for the month will be: 30 days * 24 hrs * 1 client * 0.01 credits = 7.2 credits.
- Query Snowpipe Streaming Service costs in this table: SNOWPIPE_STREAMING_CLIENT_HISTORY View view (in Account Usage).
Migration Cost
- This is the automated background process with Snowflake.
- It is approximately 3-10 credits per TB of data. It will vary on the number of files generated which also depends on the rate of inserts.
- Query Snowpipe Streaming Migration costs in this table: SNOWPIPE_STREAMING_FILE_MIGRATION_HISTORY View view (in Account Usage).
Summary
Snowflake is a high-performance data warehouse platform that is well-suited for real-time data processing. The recent release of Snowpipe Streaming and the upcoming Dynamic Tables features further enhance its capabilities and position it as a prominent player in the development of real-time applications.
At Streamkap, we leverage the Snowpipe Streaming API to enable real-time data processing for our clients. Combined with our cost-effective pricing structure, organizations can now transition to real-time data processing at a lower cost than their current solutions.
Ricky Thomas
LinkedInAuthor Bio
Ricky has 20+ years experience in data, devops, databases and startups.
Published
August 27, 2023
TL;DR
• Stream CDC data into Snowflake with sub-second latency using Snowpipe Streaming API. • Streamkap customers stream billions of records into Snowflake with support for inserts, upserts, and schema drift. • Set up Snowflake streaming in less than 5 minutes, including snapshotting, backfilling, and cost-effective data loading.
Related blog posts
.png)
Why Apache Iceberg? A Guide to Real-Time Data Lakes in 2025
Apache Iceberg brings SQL tables to cloud storage with ACID transactions and time travel. Learn why it's essential for 2025.
AWS RDS PostgreSQL Set Up
AWS RDS PostgreSQL stands out as one of the most widely used production databases. Its global adoption and everyday usage have prompted Amazon to make it exceptionally user-friendly. New users can set up an RDS PostgreSQL instance from scratch in just a few minutes.
Databricks Warehouse Set Up
Getting started with Databricks is a breeze, regardless of your experience level. This guide provides clear instructions on how to create a new account or use your existing credentials, ensuring a smooth and efficient streaming process.