A Guide to Snowflake Snowpipe


September 30, 2025
When you need to get fresh data into Snowflake for immediate analysis, Snowpipe is the answer. It’s Snowflake’s service for continuous, automated data ingestion, and it fundamentally changes how you think about loading data.
Instead of running large batch jobs on a fixed schedule (say, once a night), Snowpipe uses an event-driven approach. It essentially "listens" for new files to arrive in a cloud storage stage and loads them automatically, in micro-batches, just moments after they land.
What Is Snowflake Snowpipe and Why Does It Matter

Think of traditional data loading like a weekly cargo ship. It can carry a huge amount of goods, but it only sails on a set schedule. If you miss the boat, you're waiting another week. This creates a big delay between when the "goods" (your data) are produced and when they actually arrive for use.
Snowpipe is more like a fleet of autonomous delivery drones. The moment a new package (a data file) is dropped into your designated pickup zone (like an S3 bucket or Azure Blob Storage container), a drone is automatically dispatched to grab it and deliver it straight to your Snowflake warehouse. This continuous flow gets rid of the long waits common with batch processing.
The Problem with Yesterday's Data
For many businesses today, working with data that’s hours or even a full day old just doesn't cut it anymore. That kind of data latency can lead to missed opportunities and poor decisions because you're always looking in the rearview mirror.
Modern business operations—from marketing analytics to fraud detection—demand up-to-the-minute information.
Snowpipe is built to solve this exact problem by enabling:
- Near Real-Time Analytics: Your business intelligence (BI) dashboards can finally reflect what's happening right now, not what happened yesterday.
- Immediate Decision-Making: Teams can spot and react to customer behavior, supply chain issues, or market trends as they unfold.
- Efficient AI and ML Model Feeding: Machine learning models are only as good as the data they're trained on. Snowpipe provides a steady stream of fresh data to keep them accurate and relevant.
By automating the ingestion process, Snowpipe frees data engineering teams from the tedious task of managing and monitoring complex ETL schedules. This shifts their focus from pipeline maintenance to higher-value activities.
Ultimately, Snowpipe is the engine behind a modern data architecture. It ensures your data warehouse stays in sync with your operational systems, making your entire data ecosystem more responsive. It’s a foundational piece for any company serious about making decisions based on current, actionable insights.
Snowpipe vs Traditional Batch Loading
To really see the difference, it helps to put them side-by-side. Snowpipe represents a complete shift from the old way of doing things, moving from scheduled, high-latency jobs to a continuous, low-latency flow.
The takeaway is clear: for any scenario where data freshness is critical, Snowpipe is the superior approach. It was designed from the ground up to support the continuous data needs of modern applications and analytics.
How the Snowpipe Architecture Works
To really get what makes Snowpipe so powerful, you have to look under the hood. It’s not just magic; it's a clever, automated system that takes what used to be a tedious, manual process and turns it into a smooth, continuous flow of data. It all kicks off the second a new data file lands in your cloud storage.
Think of your cloud storage bucket—whether it's an Amazon S3 bucket or Azure Blob Storage—as a designated drop-off point for data. Instead of forcing an engineer to constantly check that spot for new arrivals, Snowpipe hooks into the storage provider's event notification system. This acts like a doorbell, instantly pinging Snowpipe the moment a new file appears.
This event-driven approach is the secret sauce. It completely gets rid of the old-school methods of constantly checking for new files (polling) or running a load job on a fixed schedule. Both of those are inefficient and introduce delays. With Snowpipe, the process starts automatically.
This graphic breaks down the simple, three-step journey a file takes from your cloud storage right into a Snowflake table.
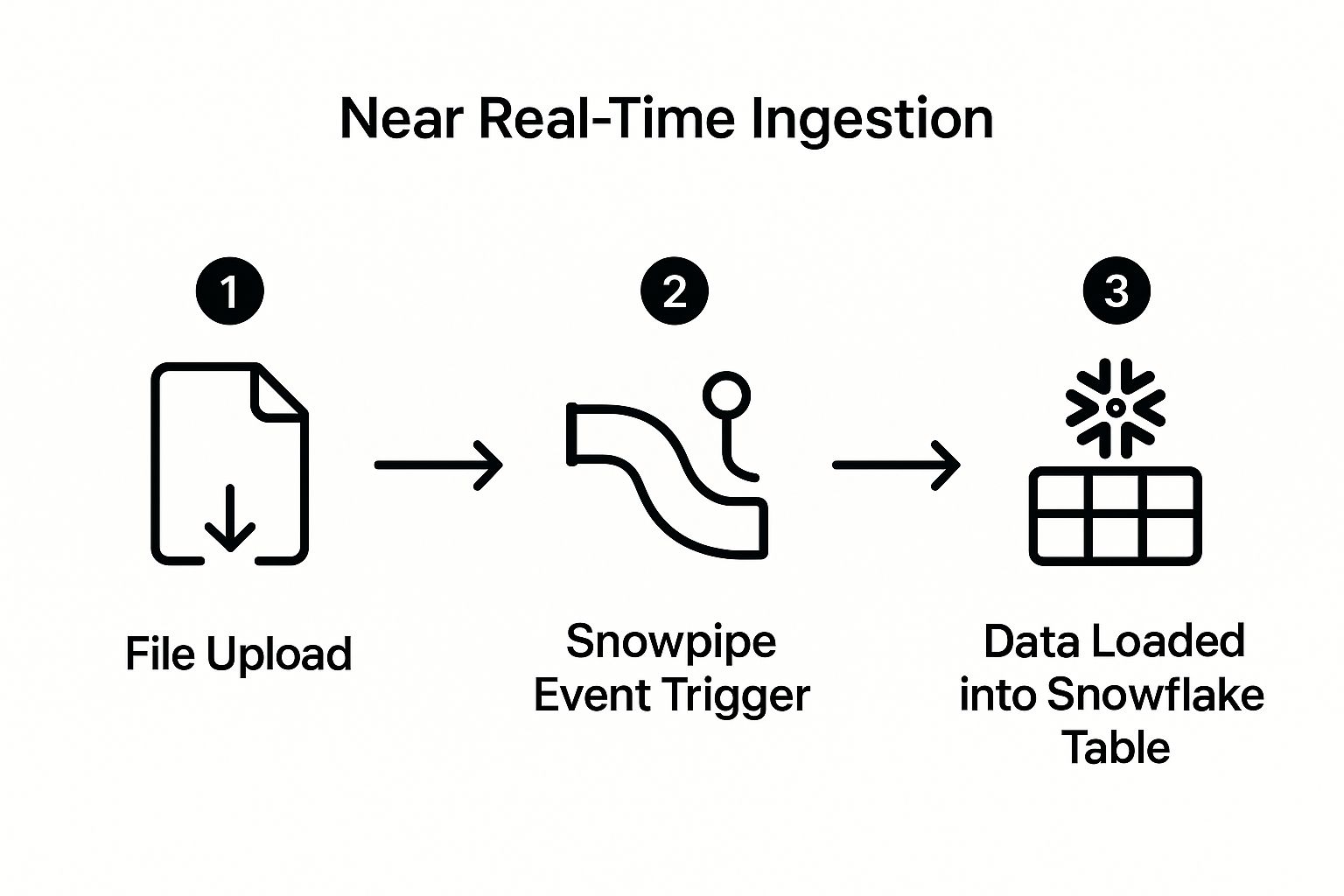
As you can see, Snowpipe acts as a seamless, event-triggered bridge, making sure data is ingested almost as soon as it’s generated.
The Role of Stages and Pipe Objects
So, how does Snowflake know where to look? The connection between your cloud storage and your Snowflake account is established using an external stage. This is just a named object in Snowflake that points to your specific storage location. It’s like giving Snowflake a key and the exact address to your data drop-off zone.
The real brains of the operation, though, is the pipe object. This is where you lay out the rules of engagement for ingestion. A pipe essentially wraps a COPY INTO command, telling Snowpipe everything it needs to know:
- The Source: Which external stage to watch.
- The Destination: The specific table where the data should land.
- The Format: How to interpret the incoming files (e.g., CSV, JSON, Parquet).
When an event notification comes in, Snowpipe finds the right pipe, reads these instructions, and runs the COPY command to load the new data.
The Serverless Compute Advantage
Maybe the most brilliant part of Snowpipe's architecture is how it handles computing power. With traditional bulk loading, you have to spin up a virtual warehouse, manage it, and pay for it while it runs. Snowpipe is completely serverless.
It operates on a separate, Snowflake-managed pool of compute resources used exclusively for data ingestion.
This is a game-changer for costs. You are billed only for the compute time used to load your files—often measured in mere seconds. You're not paying for an idle warehouse, which makes Snowpipe incredibly cost-effective for continuous, small-batch loading.
This serverless model takes all the hassle of resource management off your plate. Snowflake automatically handles the scaling and availability of the compute resources needed to work through the queue of incoming files. This ensures data gets loaded efficiently without ever disrupting your primary analytics workloads.
For more advanced scenarios, like streaming Change Data Capture (CDC) from databases, you can see how to connect Snowflake with modern data platforms that take full advantage of this powerful architecture.
Why Bother With Snowpipe? The Business Case

The technical side of Snowpipe is cool, no doubt. But what really matters is what it does for the business. Making the switch to Snowpipe is about moving away from sluggish, scheduled data updates and stepping into a world where your data is always fresh. This isn't just a win for the data team; its impact is felt everywhere, from day-to-day operations to high-level strategic planning.
When you ditch the old-school batch jobs for an automated, event-driven approach, you start seeing real benefits almost immediately. These advantages really boil down to three main things: making your operations more efficient, saving money, and gaining a strategic edge with real-time data.
Drive Efficiency Through Automation
Right off the bat, the biggest win with Snowpipe is that you can stop babysitting your data loading processes. Traditional ETL jobs need constant attention—scheduling, monitoring, and fixing things when they inevitably break. Your data engineers end up spending way too much time building and nursing fragile pipelines.
Snowpipe just handles it. Once you set up a pipe, it works on its own, picking up new files as they land in your cloud storage without anyone needing to lift a finger. This gives your skilled engineers their time back, letting them focus on bigger, more valuable projects like data modeling or developing new data-driven products.
This shift to automation leads directly to:
- Reduced Operational Overhead: No more wasting hours managing schedules or hunting down the cause of a failed load.
- Increased Team Productivity: Your team can finally stop "keeping the lights on" and start creating genuine business value.
- Improved Reliability: Automation means fewer chances for human error, leading to more dependable data pipelines.
Optimize Costs with a Serverless Model
Keeping a virtual warehouse fired up 24/7 just in case a new file shows up is a massive waste of money. This is where Snowpipe’s serverless, pay-per-use model really shines. You only pay for the exact compute power used to load each file, often billed by the second.
By moving to a consumption-based model, organizations can dramatically lower their ingestion costs compared to maintaining an always-on virtual warehouse. This is especially true for workloads with unpredictable or sporadic data arrival patterns.
This pay-as-you-go pricing means you’re never burning cash on idle compute. For a closer look at how this impacts your budget, it's worth learning more about optimizing Snowflake for lower costs with the Snowpipe Streaming API, which applies the same cost-saving ideas to row-based data.
Gain a Competitive Edge with Real-Time Data
Finally, we get to the most powerful benefit: getting your hands on data, fast. When your dashboards and applications are running on data that’s minutes old—not hours or days—you can do things you simply couldn’t before.
This empowers business functions that thrive on immediate information. Think about it. You could spot and block fraudulent transactions the moment they happen, not well after the damage is done. Or you could personalize a customer's experience on your website based on what they are clicking right now.
This is the kind of advantage near real-time data delivers. It turns your data warehouse from a static repository into a dynamic, strategic tool that helps you win.
Introducing Snowpipe Streaming for True Real-Time Data
The original Snowpipe was a game-changer, shrinking data latency from hours down to just minutes. But the need for speed never stops, and that hunger for instant insight is what led to the next step in data ingestion: Snowpipe Streaming. This isn't just a minor update; it's a complete shift from loading small batches of files to streaming data row-by-row, in real time.
Think of the original Snowpipe as a super-efficient courier. It waits for small packages (files) to show up at a drop-off point (your cloud storage) and then zips them over to Snowflake. Snowpipe Streaming, on the other hand, is like having a direct pneumatic tube. It sends individual items (single rows of data) straight from the source into your Snowflake tables the very second they’re created. The whole process of creating and staging files is gone.
This direct, row-by-row method slashes ingestion latency. We're no longer talking about minutes; we're talking about data being ready to query in a matter of seconds. For some use cases, it’s practically instant. This opens the door to a whole new world of applications that depend on having the freshest data possible.
How Streaming Differs from File-Based Ingestion
The fundamental change is how the data gets into Snowflake. Traditional Snowpipe watches a cloud storage bucket, gets a notification when a new file appears, and then loads that file. Snowpipe Streaming provides a dedicated API, letting your applications push rows directly into Snowflake tables without ever writing them to an intermediate file first.
This might sound like a technical detail, but it has huge architectural implications. Data ingestion used to be all about batch processing—collecting data for hours or days before a big load. Snowpipe turned that on its head with automated, near real-time micro-batches. This was a massive leap forward for industries like e-commerce fraud detection and supply chain logistics, where minutes matter. Now, Snowpipe Streaming pushes the boundary even further, bringing latency down to the millisecond scale by sending a continuous flow of data right into your tables. You can dig deeper into this evolution in this guide to Snowflake streaming.
Ideal Use Cases for Snowpipe Streaming
This isn't just about making things faster for the sake of it. Low-latency ingestion unlocks real business value in situations where you need to act on information the moment it arrives.
It’s a perfect fit for a ton of powerful applications:
- IoT Sensor Data: Pulling in millions of data points from factory floor sensors or logistics trackers to spot problems as they're happening.
- Live Application Logging: Streaming logs and performance metrics directly from your apps to catch and fix issues in real time.
- Real-Time Financial Tickers: Fueling analytics platforms with stock and market data that’s accurate down to the millisecond.
- Feeding Live ML Models: Keeping machine learning models constantly updated with fresh data for things like dynamic pricing or immediate threat detection.
Snowpipe Streaming effectively turns Snowflake from a near real-time analytics platform into a true streaming data platform. It’s built to handle the most demanding, low-latency workloads you can throw at it.
By getting rid of the file-staging step, Snowpipe Streaming directly addresses the growing demand for immediate data visibility. It gives you the power to build incredibly responsive, data-driven applications that react to events as they unfold. For many businesses, that's not just a nice-to-have—it's a critical competitive edge. The Snowflake Snowpipe ecosystem now offers a complete solution, covering everything from simple micro-batching to true, real-time streaming.
Real-World Use Cases for Snowpipe

The theory behind Snowflake Snowpipe is great, but its real power shines when you see it solving actual business problems. By creating a continuous flow of data, Snowpipe completely changes how industries work. It turns traditional, static data warehouses into living, breathing analytics platforms that can react to events as they happen.
Let's look at a few examples. In the hyper-competitive world of e-commerce, understanding customer behavior right now is the name of the game. Companies use Snowpipe to funnel huge volumes of clickstream data from their websites and apps straight into Snowflake, all in near real-time.
This steady stream of information isn't just for reports; it feeds immediate actions that directly impact the bottom line.
- Live Personalization: When you're browsing an online store, Snowpipe can feed your clicks into an analytics model. The site can then instantly tweak the product recommendations you see on the page, making a purchase far more likely.
- Abandoned Cart Recovery: A customer leaves items in their cart. That event is streamed through Snowpipe, triggering an automated, personalized reminder email in minutes, not hours. That speed makes a huge difference in winning back the sale.
Powering FinTech and Media
The financial tech industry is built on speed and trust. For them, Snowpipe is an essential tool for streaming transaction data the second it’s created. This enables instant fraud detection algorithms to spot and block suspicious activity in its tracks, stopping financial damage before it can spread.
It’s a similar story in media and entertainment. Companies ingest live engagement data—video views, likes, shares, you name it—to fine-tune their recommendation engines. That "what to watch next" suggestion that keeps you on the platform? It's often powered by this kind of real-time data ingestion.
Snowpipe is the bridge between raw data being created and the business insights you can act on. It’s what makes being "data-driven" a practical reality, ensuring the data you analyze reflects this very moment, not just what happened yesterday.
Unlocking Database Changes with CDC
One of the most compelling use cases for the Snowflake Snowpipe ecosystem is Change Data Capture (CDC). CDC is a technique for identifying and capturing every change made in a source database—every insert, update, and delete—and then streaming those changes to another system in real-time.
Modern data platforms like Streamkap are built for this. They use CDC to stream changes from operational databases like PostgreSQL or MongoDB directly into Snowflake. Snowpipe and Snowpipe Streaming are the perfect landing zones for this data, guaranteeing your data warehouse is an up-to-the-second mirror of your production systems. This is a game-changer for offloading heavy analytical queries from your primary database.
For a deeper look at this process, check out our guide on streaming MongoDB to Snowflake with Snowpipe Streaming.
This move toward live data is more than just a feature; it's a fundamental shift in how we think about data architecture. Snowflake is clearly all-in on this trend, recently announcing upgrades to Snowpipe Streaming and significant cost reductions that make real-time ingestion much more accessible at scale. It’s all part of a larger industry move away from clunky batch jobs and toward a single, unified platform for live data.
Answering Your Top Snowpipe Questions
As you start thinking about building a continuous data pipeline, you're bound to have questions. How does this thing actually work? What’s it going to cost me? Can I trust it with my data? These are the practical, real-world questions that come up when you move from theory to implementation with Snowflake Snowpipe.
Getting these answers straight is the key to feeling confident about putting Snowpipe into your data stack. So, let's dive into the most common questions we hear and give you clear, straightforward answers to help you make the right call.
What Is the Difference Between Snowpipe and a Standard COPY Command?
The biggest difference between Snowpipe and a COPY command comes down to how they run and what compute resources they use.
Think of the COPY command as a manual process. You decide exactly when to run it, and it needs an active virtual warehouse that you manage and pay for. It’s powerful and gives you total control, but you're on the hook for scheduling it and footing the bill for the warehouse's uptime.
Snowpipe is the complete opposite—it's an automated, "set it and forget it" service. It runs quietly in the background, automatically kicking off when a new file lands in your staging area. Critically, it uses a separate pool of Snowflake-managed compute resources, not your own virtual warehouse. This makes it perfect for loading lots of small files frequently without any manual babysitting.
How Does Snowpipe Pricing Work?
Snowpipe’s pricing is built for its event-driven style and is completely different from how warehouses are billed. You're not paying for a warehouse to be "on." Instead, you're charged based on the actual work done to load your data, measured in "Snowpipe credits."
The cost breaks down into two main parts:
- Compute Usage: You’re billed per-second for the precise amount of time it takes to load each file.
- File Overhead: A small, flat fee is charged for every file Snowpipe discovers through an event notification.
This pay-for-what-you-use model is incredibly cost-effective for continuous, small-batch ingestion. But for a huge, one-time data migration, you might find that firing up a dedicated warehouse and running a
COPYcommand is cheaper.
Does Snowpipe Guarantee Exactly-Once Processing?
Yes, it does. Snowpipe provides exactly-once processing guarantees for every single file, which is a massive win for data integrity.
How does it pull this off? By keeping a detailed internal record of every file it has already loaded within a 14-day window. If a duplicate notification comes in for a file it’s already seen and processed, Snowpipe simply ignores it. This built-in safety net prevents duplicate rows from ever hitting your tables, saving you from the headache of building your own deduplication logic.
When Should I Use Snowpipe Streaming Instead of Regular Snowpipe?
Deciding between the standard file-based Snowpipe and Snowpipe Streaming boils down to one thing: latency. How fast do you really need your data?
You should reach for Snowpipe Streaming when your use case demands near-instant data availability—we're talking seconds or even milliseconds. It's built for high-velocity data from sources like IoT sensors, real-time ad bidding platforms, or live application logs where every moment counts.
On the other hand, the regular, file-based Snowflake Snowpipe is the workhorse for near-real-time needs, where a latency of a few minutes is perfectly fine. It’s fantastic when your data naturally arrives in small files or micro-batches. The cost models are different, so you’ll want to save Snowpipe Streaming for those scenarios where having data right now gives you a clear business advantage.
Ready to build a true real-time data pipeline into Snowflake? Streamkap uses Change Data Capture (CDC) and Snowpipe Streaming to deliver your data with sub-second latency, ensuring your analytics are always up-to-date. See how Streamkap can help you.

Related blog posts
