How to Stream MongoDB Data to Iceberg on AWS with Streamkap
Paul Dudley
August 21, 2025
TL;DR
• Stream MongoDB e-commerce data to Iceberg on S3 for real-time customized discounts and dynamic inventory management. • Process vast volumes of orders and cart activity with minimal latency using Iceberg's analytical capabilities. • Configure MongoDB network access, obtain connection strings, and set up S3 with proper IAM roles for Streamkap.
Table of Contents
Configuring an Existing MongoDB Database Configuring MongoDB Network for Streamkap Compatibility Fetching MongoDB Connection String for Streamkap Setting up a New S3 Bucket and Gule database from Scratch Configuring Access for an Existing Iceberg on S3 Destination Configuring Streamkap Connectors and Pipeline Step 2 : Adding Iceberg as a destination Connector Validating the Streamkap Pipeline Integration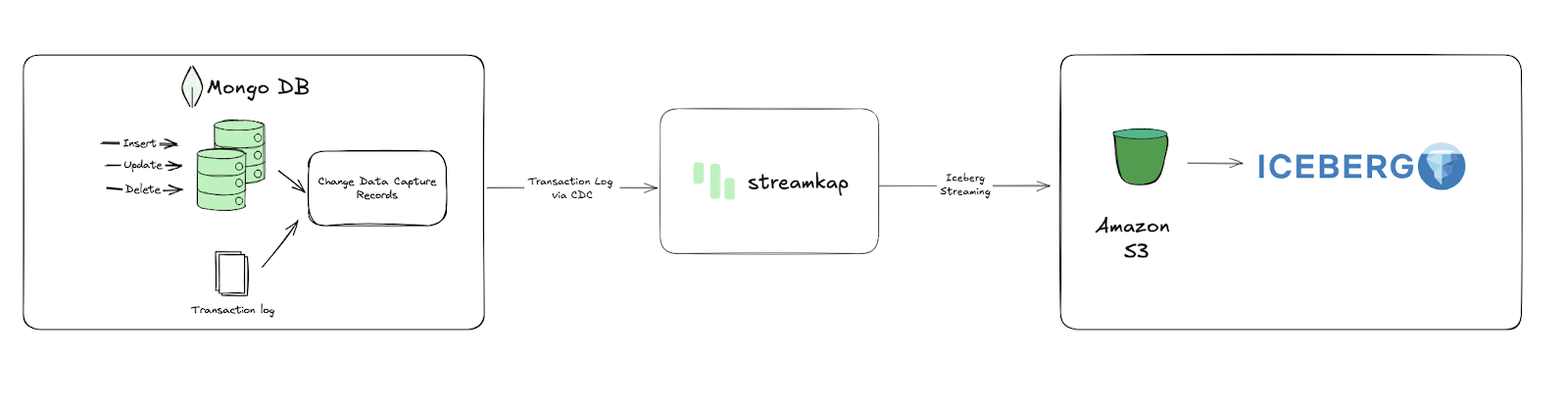
Introduction
Effective, data-driven decision-making hinges entirely on the underlying systems that power it. Unfortunately, many traditional data architectures simply cannot keep pace with the rapid velocity of today’s e-commerce operations. It’s time to move beyond slow data pipelines. Streamkap offers an effortless solution to transfer your e-commerce data from MongoDB to Iceberg on S3 in real-time, ensuring your critical decisions are powered by current insights, not outdated information.
Through this comprehensive guide, businesses can establish a robust, real-time e-commerce order management streaming pipeline directly from MongoDB to Iceberg on S3. This enables functionalities like real-time customized discounts and dynamic inventory management with just a few configurations. By creating a direct, high-performance link between MongoDB’s transactional data and Iceberg’s analytical capabilities on S3, engineering teams can build a powerful analytics system capable of swiftly processing vast volumes of e-commerce orders and cart activity with minimal latency.
Guide Sections:
| Prerequisites | You’ll need accounts for AWS, and Streamkap. |
|---|---|
| Configuring MongoDB Network for Streamkap Compatibility | Configure an existing MongoDB setup to ensure compatibility with Streamkap’s real-time streaming. |
| Fetching Your MongoDB Connection String | The valid connection string for your MongoDB cluster needs to be obtained and ready for use when you configure the Streamkap pipeline. |
| Preparing Your Iceberg on S3 Destination | This section will guide you through preparing your S3 environment and establishing the foundation for your Iceberg tables, which will serve as your real-time data destination. |
| Configuring Access for an Existing Iceberg on S3 Destination | If you already have an existing Iceberg setup on S3, this section will guide you on configuring the necessary AWS permissions (e.g., S3 bucket policies, IAM roles) to allow Streamkap to write data to your Iceberg tables. |
Prerequisites
To follow along with this guide, make sure you have these prerequisites covered:
-
Streamkap Account: You’ll need an active Streamkap account with admin or data admin privileges. If you don’t have one, you can sign up here or request access from your admin.
-
MongoDB Account: To create, modify, or manage databases and tables in MongoDB, you’ll need an active MongoDB account. If you don’t have one yet, you can sign up to get started.
-
Amazon AWS Account: An active AWS account is essential. This account needs the necessary permissions to set up and manage an AWS RDS instance. It also requires permissions for Amazon S3 (to handle your Iceberg data buckets and objects) and AWS Glue Data Catalog if you plan to use it for Iceberg table metadata. If you don’t have an AWS account, you can create one.
MongoDB Setup
MongoDB is a widely recognized NoSQL database, highly valued for its exceptional scalability, high availability, and low-latency performance. Its intuitive design and inherent flexibility make it a preferred choice for managing large datasets in production environments. Getting a new MongoDB instance up and running is typically fast and straightforward, allowing even new users to begin working within minutes.
If you already have an existing MongoDB instance, seamlessly integrating it with Streamkap is a simple process. In this section, we will guide you through the necessary steps to set up and configure MongoDB, ensuring perfect compatibility with Streamkap for reliable and optimized real-time data streaming.
Configuring an Existing MongoDB Database
Step 1: Create a Streamkap User in the Existing Database to Access Data
- Begin by logging into your MongoDB Console.

- Once successfully logged in, you will find yourself on your Dashboard.
- In the left-hand navigation menu, proceed to “Security” and then select “Database Access.”

- Click on “Add New Database User.”

- Choose “Password” as your preferred authentication method.
- Enter a distinct username and a strong, secure password for the new Streamkap user.

- Scroll down to the “Database User Privileges” section. From the dropdown menu, select “Specific Privileges.”
- Under “Specific Privileges,” add the following essential roles/privileges:
- readAnyDatabase
- read on your specific MongoDB database that you intend to stream (for instance, the database containing your e-commerce order inventory data).
- Finally, click “Add User.”

- You will then be redirected back to the Database Access page, where your newly created Streamkap user should now be listed.

- Navigate to the one with your data, then click “Browse Collections”.

Step 2: Enable Snapshots through MongoDB
To ensure reliable and consistent Change Data Capture (CDC), Streamkap requires an initial snapshot of your MongoDB database. This crucial process captures the baseline state of your data before continuous CDC begins. As part of this setup, a dedicated collection must be created to facilitate snapshot tracking and maintain data integrity throughout the streaming process.
To proceed with this, you need to create the streamkap_signal collection. It is mandatory to use this exact collection name for Streamkap to recognize it.
- Navigate to your MongoDB dashboard and select the “Clusters” tab, where you’ll see a list of all available clusters.
- As outlined in this guide, you should have a cluster that encompasses all the collections and documents associated with your e-commerce or other application’s data.
- Navigate to the cluster that contains your data, then click “Browse Collections.”

- You will be directed to the “Collections” page.
- On this page, locate the “Collections” section and click the ”+” icon situated next to your database name to initiate the creation of a new collection.

- Name this new collection exactly streamkap_signal (ensure it’s all lowercase, as this is a mandatory naming convention for Streamkap).

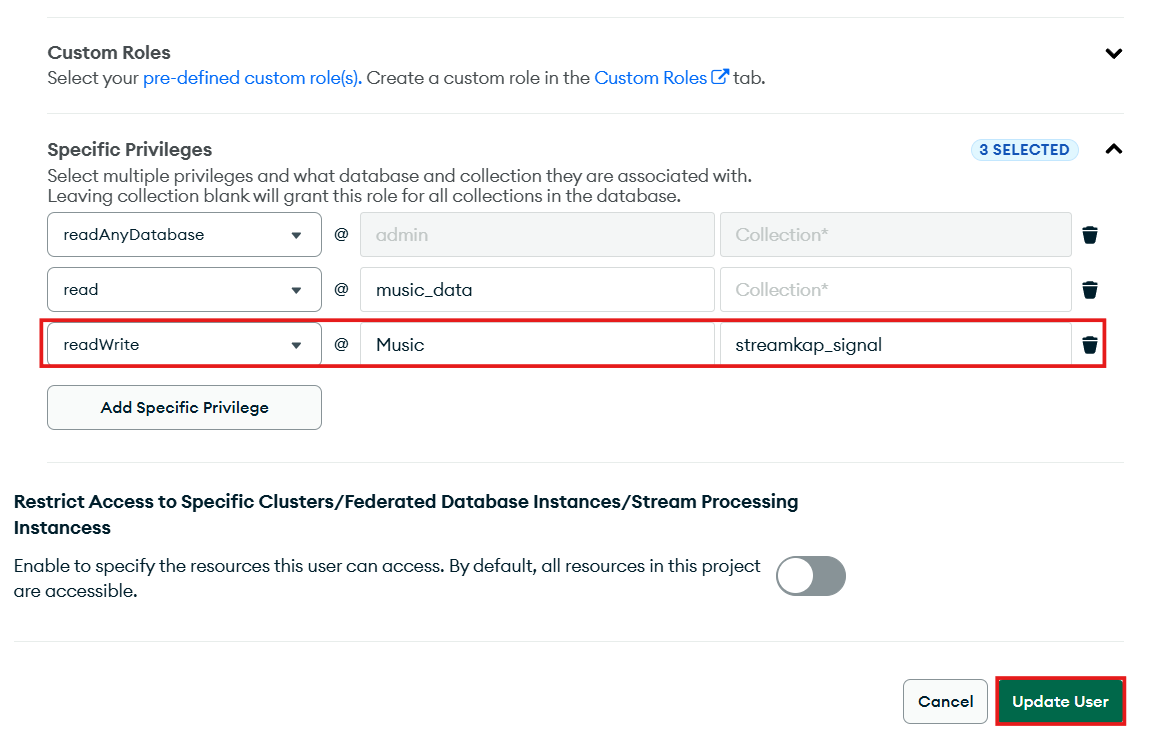
Step 3: Grant Snapshot Permissions to the Streamkap User
The streamkap_user you created in “Step 1” will require readWrite privileges specifically on the streamkap_signal collection. This permission is absolutely necessary for achieving effective Change Data Capture (CDC). Follow the steps below to configure these essential permission changes:
- Go to your “Dashboard” and select “Database Access” from the left-hand menu.
- Under “Database Users,” locate the streamkap_user you created in Step 1 and click on “Edit” next to its entry.

- Scroll down to the “Database User Privileges” drop-down menu and select “Specific Privileges.”
- Under “Specific Privileges,” add the following role/privilege
- readWrite@.streamkap_signal (Ensure you replace with the actual name of your MongoDB database).
- After adding the privilege, click on Update User
Configuring MongoDB Network for Streamkap Compatibility
While MongoDB often whitelists your current IP address automatically, it is essential to manually whitelist Streamkap’s specific IP addresses. This section details how to configure network access rules, allowing seamless connectivity from both Streamkap’s dedicated IP addresses and any other trusted sources you might use, thereby ensuring robust integration and communication.
- On your MongoDB dashboard, navigate to “Network Access” on the left pane and click ”+ Add IP Address.”

- If this is a demonstration project, you can select “Allow Access from Anywhere” and proceed to the next steps.
- For production-grade projects, however, we strongly recommend explicitly whitelisting specific IP addresses rather than allowing access from anywhere. To add “Streamkap’s IP,” refer to the table of Streamkap’s dedicated IP addresses below and add the IP address corresponding to your chosen region as an “Access List Entry.”

Streamkap Dedicated IP Addresses:
| Service | IPs |
|---|---|
| Oregon (us-west-2) | 52.32.238.100 |
| North Virginia (us-east-1) | 44.214.80.49 |
| Europe Ireland (eu-west-1) | 34.242.118.75 |
| Asia Pacific - Sydney (ap-southeast-2) | 52.62.60.121 |
Fetching MongoDB Connection String for Streamkap
To establish a successful connection between Streamkap and your MongoDB instance, a valid connection string is required. You can obtain this essential connection string by diligently following the steps outlined below:
- On your MongoDB dashboard, select “Clusters” from the left-hand panel.
- Beneath your cluster’s name, locate and click on the “Connect” button.

- Carefully copy the provided connection string and ensure you store it securely. You will need to plug this string into Streamkap when you configure your data pipeline later.

Iceberg set up
Whether you’re new to Iceberg or already familiar with data lake technologies, this guide will walk you through the essentials. From setting up your environment to configuring your storage and catalog, we’ll ensure a smooth and efficient experience as you begin working with Apache Iceberg for reliable, scalable data management.
Setting up a New S3 Bucket and Gule database from Scratch
Step 1: Log in to the AWS Management Console
- Log in to your AWS Management Console and select the region you specified in the above section.

Let’s create a bucket now:
- Go to the search bar, type “S3,” and select S3.
- Now click “Create bucket”.


- Give your S3 bucket a unique name that’s easy to identify later.

- Public Access: Uncheck all public access options to avoid giving public permissions. Since the access is via third-party services, it’s better to uncheck these to prevent networking or configuration issues.

- Next, click ‘Create bucket’ to proceed with the setup.

Step 2: Create new AWS Glue database
- Type “Glue” in the search bar and click on “AWS Glue” from the results.

- Select the same region that we had while creating S3 bucket, in this case we used us-west-2.
- From the left side navigation bar navigate to the database to create database for our data.

- Click on “Add database” as depicted in the picture below.

- Provide a unique database name and include a clear, descriptive explanation to define its purpose within AWS Glue.
- Then, click on “Create database” to finalize the creation.

- Once the database is successfully created, it will appear in your list of databases—just like what is shown in the screenshot below.

Step 3: Create new Policy and IAM role for Streamkap connection
- Type “IAM” in the search bar, then select IAM section.

- Navigate to Policies in the left menu and click Create Policy.
- Search for S3 and select AmazonS3FullAccess as a base policy.

-
Permission Requirement for S3 and Glue:
- “s3:GetObject”,
- “s3:PutObject”,
- “s3:DeleteObject”,
- “s3:ListBucket”
- “glue:GetDatabase”,
- “glue:GetDatabases”,
- “glue:CreateTable”,
- “glue:GetTable”,
- “glue:GetTables”,
- “glue:UpdateTable”,
- “glue:DeleteTable”,
- “glue:CreatePartition”,
- “glue:GetPartition”,
- “glue:GetPartitions”,
- “glue:BatchCreatePartition”,
- “glue:UpdatePartition”,
- “glue:DeletePartition”,
- “glue:BatchDeletePartition”
-
It will first display the visual format of the policy. You can either select the policy you want or toggle to the JSON format and paste the following policy for S3 and AWS Glue.

- Click “Next”.
- Plug in Policy Name as Steramkap_warehouse_policy (or any name of your choice)
- Plug in Description as This policy will be used to put data into S3

- Click on “Create Policy” which can be found in the bottom right corner.

- On the left side navigate to “Roles**”** and click on the “Create role” on the top right corner.

- Select Custom Trust policy and enter policy as shown below for Streamkap to allow the Streamkap production tenant access to your AWS Glue instance.

- Next, under Filter by type choose the Custom Managed Policy option. Then, select the policy you just created and click Next to proceed.
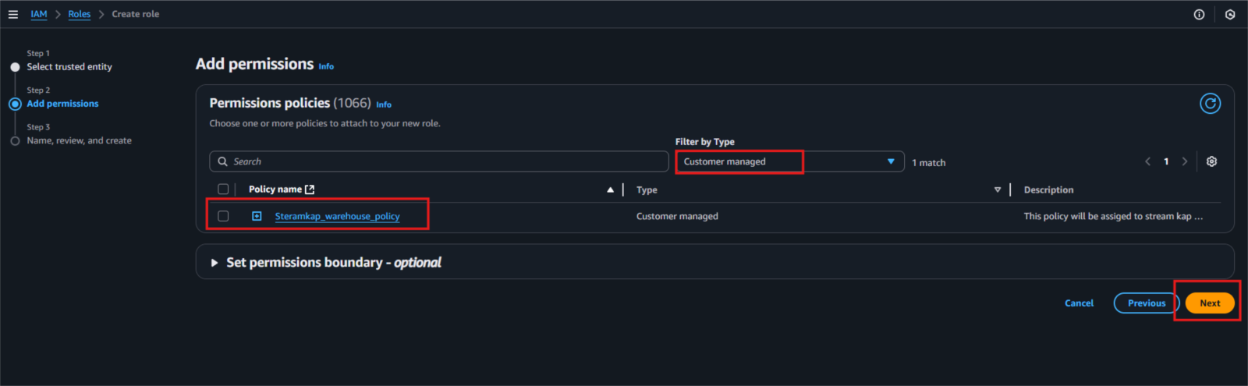
- Provide a meaningful name and a detailed description for the role to help identify its purpose easily in the future. After carefully reviewing all the policy settings to ensure they meet your requirements, click on the “Create role” button to finalize the role creation process.

- After the role is created, it will appear as shown in the picture below, confirming that the setup was successful and the role is ready for use.

Navigate to the IAM role and copy its Role ARN. We’ll use this ARN when setting up the connection with Streamkap.

Step 4 : Add role to AWS glue
- Type “Glue” in the search bar and click on “AWS Glue” from the results.
- Click on “Set up roles and users” to grant AWS Glue access and assign a default IAM role for your account.

- Select the role you created earlier and click Next to continue.

- Choose the specific S3 bucket you want AWS Glue to access, grant it read-only permissions, and then click Next to proceed.

Select the role you created earlier to set it as the default IAM role, then click Next to continue.

- Review all the changes carefully, then click on Apply changes to finalize the configuration.

Configuring Access for an Existing Iceberg on S3 Destination
Step 1: Create new Policy and IAM role for Streamkap connection
- Type “IAM” in the search bar, then select IAM section.
- Navigate to Policies in the left menu and click Create Policy.
- Search for S3 and select AmazonS3FullAccess as a base policy.

-
Permission Requirement for S3 and Glue:
- “s3:GetObject”,
- “s3:PutObject”,
- “s3:DeleteObject”,
- “s3:ListBucket”
- “glue:GetDatabase”,
- “glue:GetDatabases”,
- “glue:CreateTable”,
- “glue:GetTable”,
- “glue:GetTables”,
- “glue:UpdateTable”,
- “glue:DeleteTable”,
- “glue:CreatePartition”,
- “glue:GetPartition”,
- “glue:GetPartitions”,
- “glue:BatchCreatePartition”,
- “glue:UpdatePartition”,
- “glue:DeletePartition”,
- “glue:BatchDeletePartition”
-
It will first display the visual format of the policy. You can either select the policy you want or toggle to the JSON format and paste the following policy for S3 and AWS Glue.
- Click “Next”.
- Plug in Policy Name as Steramkap_warehouse_policy (or any name of your choice)
- Plug in Description as This policy will be used to put data into S3

- Click on “Create Policy” which can be found in the bottom right corner.
- On the left side navigate to “Roles**”** and click on the “Create role” on the top right corner.

- Select Custom Trust policy and enter policy as shown below for Streamkap to allow the Streamkap production tenant access to your AWS Glue instance.
- Next, under Filter by type choose the Custom Managed Policy option. Then, select the policy you just created and click Next to proceed.

- Provide a meaningful name and a detailed description for the role to help identify its purpose easily in the future. After carefully reviewing all the policy settings to ensure they meet your requirements, click on the “Create role” button to finalize the role creation process.
- After the role is created, it will appear as shown in the picture below, confirming that the setup was successful and the role is ready for use.
Navigate to the IAM role and copy its Role ARN. We’ll use this ARN when setting up the connection with Streamkap.
Step 2: Add role to AWS glue
- Type “Glue” in the search bar and click on “AWS Glue” from the results.
- Click on “Set up roles and users” to grant AWS Glue access and assign a default IAM role for your account.
- Select the role you created earlier and click Next to continue.
- Choose the specific S3 bucket you want AWS Glue to access, grant it read-only permissions, and then click Next to proceed.
Select the role you created earlier to set it as the default IAM role, then click Next to continue.
- Review all the changes carefully, then click on Apply changes to finalize the configuration.
Streamkap Setup
Streamkap is a real-time data streaming solution that enables efficient, low-latency transfer of data from transactional sources like MongoDB into Apache Iceberg tables. By replicating high-volume operational data into Iceberg, it supports scalable analytics with ACID guarantees, schema evolution, and time travel, making the data lakehouse ready for complex queries and downstream processing without impacting the performance of source systems.
Configuring Streamkap Connectors and Pipeline
Step 1: Adding MongoDB as a Source Connector
If the above steps were followed as described, MongoDB, by default, should be Streamkap compatible.
Note: You must have admin or data admin privileges to continue with the following steps.
- Log in to Streamkap.
- On the left side navigation pane
- click on “Connectors”
- click on the “Sources” tab
- click the “+ Add” button as shown below
- Enter “MongoDB” in the search bar and select it from the list of available services, as depicted below.

- Plugin the relevant details to the MongoDB connection string from the section “Fetching MongoDB Connection String for Streamkap”.

- Manually add your MongoDB database name and choose all collections you want to stream.

- Once the database and collections are added, click “Save”.
- A new connector will be listed in “Connectors > Sources”.

Step 2 : Adding Iceberg as a destination Connector
- From the side navigation bar, go to Connectors, then switch to the Destinations tab. Search for Iceberg in the list and select it to begin the setup process.
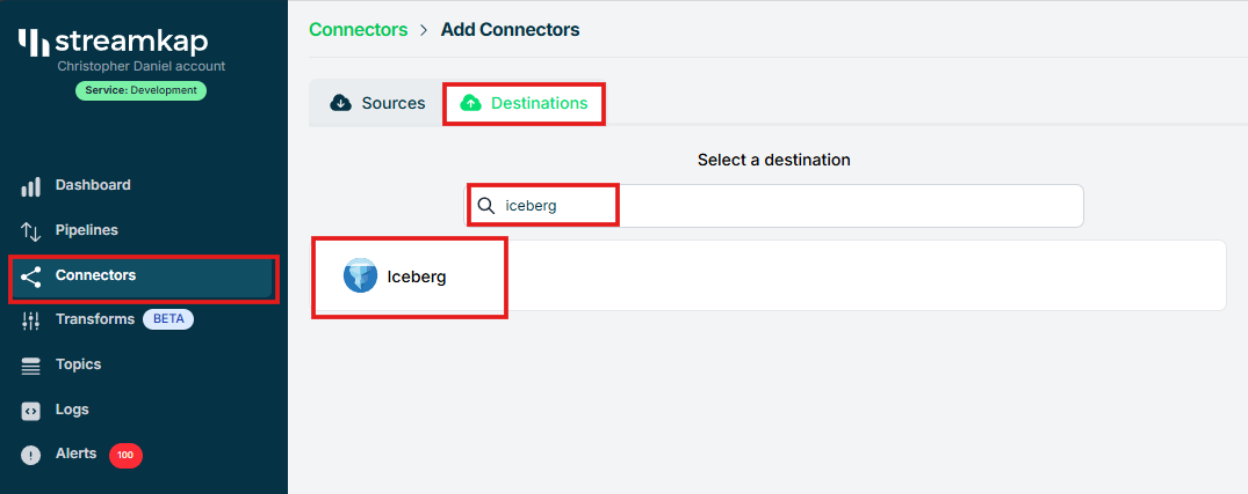
- Enter streamkap_datawarehouse as the name of the destination — if you’ve followed the naming conventions from this guide.
- Select glue as the catalog type to match the setup we’ve configured earlier.
- Paste the IAM Role ARN (arn:aws:iam::…:role/streamkap_role) that you created in the previous steps.
- Choose us-west-2 as the region — assuming you’re using the same region as outlined in this guide.
- Enter s3a://streamkapatawarehouse as the S3 bucket path used in the earlier setup.
- Set the schema name to streamkap_warehouse, which corresponds to the Glue database we created.
- Select insert as the insert mode to define how records will be written into Iceberg.
- Click “Save” to complete the destination setup.

- Once the configuration has been completed successfully, proceed to verify that the active status is properly reflected and functioning as expected.

Step 3: Creating a Streamkap Pipeline
- Navigate to “Pipelines” on the left side and click “Create” to create a pipeline between source and destination.

- Select your MongoDB connector as “Source” and your Iceberg connector as “Destination” and click on “Next” in the bottom right corner.

- Select the database and the collections that you want to stream. Click “Next”.

- Assign a name to the pipeline, add the appropriate tags as needed, enable the snapshot feature for the topic, and then click on the save button to apply the changes.

- Once the pipeline is successfully created, it will appear with its status displayed as “Active”.

Validating the Streamkap Pipeline Integration
To verify the full end-to-end functionality of the pipeline, we will insert a document into the Music collection in MongoDB, which will then be streamed into the Music table within the Apache Iceberg-managed data lake.
- Insert a new document into the `Music` collection.

- Download the files from the S3 bucket, convert the data into a CSV or table format, and then verify the accuracy of the resulting data.

What’s Next?
Thank you for reading this guide. If you have other sources and destinations to connect to in near real-time check out the following guides.
-
[Postgres to Databricks
](https://streamkap.com/blog/stream-data-from-aws-postgresql-to-databricks-using-streamkap)
For more information on connectors please visit here.
Paul Dudley
LinkedInAuthor Bio
Paul is the CEO and Co-Founder of Streamkap
Published
August 21, 2025
TL;DR
• Stream MongoDB e-commerce data to Iceberg on S3 for real-time customized discounts and dynamic inventory management. • Process vast volumes of orders and cart activity with minimal latency using Iceberg's analytical capabilities. • Configure MongoDB network access, obtain connection strings, and set up S3 with proper IAM roles for Streamkap.
Related blog posts
.png)
Why Apache Iceberg? A Guide to Real-Time Data Lakes in 2025
Apache Iceberg brings SQL tables to cloud storage with ACID transactions and time travel. Learn why it's essential for 2025.
AWS RDS PostgreSQL Set Up
AWS RDS PostgreSQL stands out as one of the most widely used production databases. Its global adoption and everyday usage have prompted Amazon to make it exceptionally user-friendly. New users can set up an RDS PostgreSQL instance from scratch in just a few minutes.
Databricks Warehouse Set Up
Getting started with Databricks is a breeze, regardless of your experience level. This guide provides clear instructions on how to create a new account or use your existing credentials, ensuring a smooth and efficient streaming process.