How to Stream SQL Server to Snowflake with Streamkap
Ricky Thomas
March 8, 2025
TL;DR
• Stream SQL Server data to Snowflake with sub-second latency for zero-maintenance data pipelines and live business intelligence. • Create a foundation for AI/ML workflows and cross-organization data sharing without code or complexity. • Follow this guide for AWS SQL Server setup, Snowflake configuration, and Streamkap pipeline creation.
Introduction
In an era demanding instant insights, your data can’t afford lag**.**When milliseconds determine outcomes, delayed data becomes a liability. Legacy systems throttle progress, but transformation is within reach.
In this guide, we have our data hosted in AWS SQL Server and in order to run scalable and durable analytics we will be streaming data from SQL Server to Snowflake.
Streaming SQL Server data to Snowflake creates powerful opportunities for data sharing across your organization while establishing a robust data lake architecture that serves as the foundation for advanced AI/ML workflows.
This guide reveals how Streamkap redefines data mobility through effortless integration and performance. For engineers prioritizing zero-maintenance pipelines or executives demanding live business intelligence, discover how to harness SQL Server’s full potential in Snowflake without code or complexity.
Guide sections:
| Prerequisites | You will need Streamkap and Aws accounts |
|---|---|
| Setting up a New RDS SQL Server From Scratch | This step will help you to set up SQL Server inside AWS |
| Configuring an Existing RDS SQL Server | For existing SQL Server DB, you will have to modify its configuration to make it Streamkap-compatible |
| Creating a New Snowflake Account | This step will help you set up a Snowflake account |
| Fetching credentials from existing Snowflake account | For an existing Snowflake account, you will have to modify its permissions to allow Streamkap to write data |
| Streamkap Setup | Adding SQL Server as a source, adding Snowflake as a destination, and finally connecting them using a data pipe |
Ready to Supercharge Your Data Pipeline?
Prerequisites
To follow along with this guide, ensure you have the following in place:
-
Streamkap Account: To get started, you’ll need an active Streamkap account with admin or data admin privileges. If you don’t have one yet, no worries—you can sign up here or ask your admin to grant you access.
-
Amazon AWS Account: To set up and manage an AWS RDS instance, you’ll need an active Amazon AWS account with core RDS permissions. These permissions are essential for creating and managing database instances, configuring networking, and ensuring proper security settings. If you don’t already have an AWS account, you can create one from here to get started.
-
Ensure you have an active Snowflake account with data warehouse admin privileges. These privileges are essential for managing databases and setting up data integrations. If you haven’t signed up yet, you can get started by creating a Snowflake account here.
SQL Server Set-Up
AWS RDS SQL Server is a scalable database solution designed for enterprise applications, offering strong performance and reliability trusted by organizations worldwide. Amazon has streamlined the RDS SQL Server experience, enabling users to set up an SQL Server instance from scratch in just a few minutes. For those migrating existing SQL Server databases, configuring the necessary settings for StreamKap streaming is a simple process.
In this section, we will dive into the various methods to set up and configure AWS RDS SQL Server, ensuring seamless integration and full compatibility with StreamKap.
Setting up a New RDS SQL Server from Scratch
Note: To set up a new AWS RDS SQL Server instance, you’ll need IAM permissions for creating and managing RDS instances, parameter groups, subnet groups, networking, security, monitoring, and optional encryption and tagging.
Step 1: Access the AWS Management Console
- Log in to your AWS management Console and type “RDS” on the search bar.
- Click on “RDS” as shown below.
Step 2: Create a new RDS SQL Server Instance
- On the RDS dashboard, select the region where you want to host your RDS instance. Be sure it aligns with your application’s requirements.
Note: To integrate with Streamkap, ensure that the selected region is one of the following:
Oregon (us-west-2)
North Virginia (us-east-1)
Europe Ireland (eu-west-1)
Asia Pacific - Sydney (ap-southeast-2)
- Navigate to the “Databases” section or select “DB Instances” under the “Resources” section.
- Click on “Create database” to kick off the setup process.
- In the “Choose a database creation method” section, choose “Standard create” option.
- Under the “Engine options” section, select “SQL Server” as the database engine.
- In the “Database management type” section, select “Amazon RDS” for a fully managed RDS service.
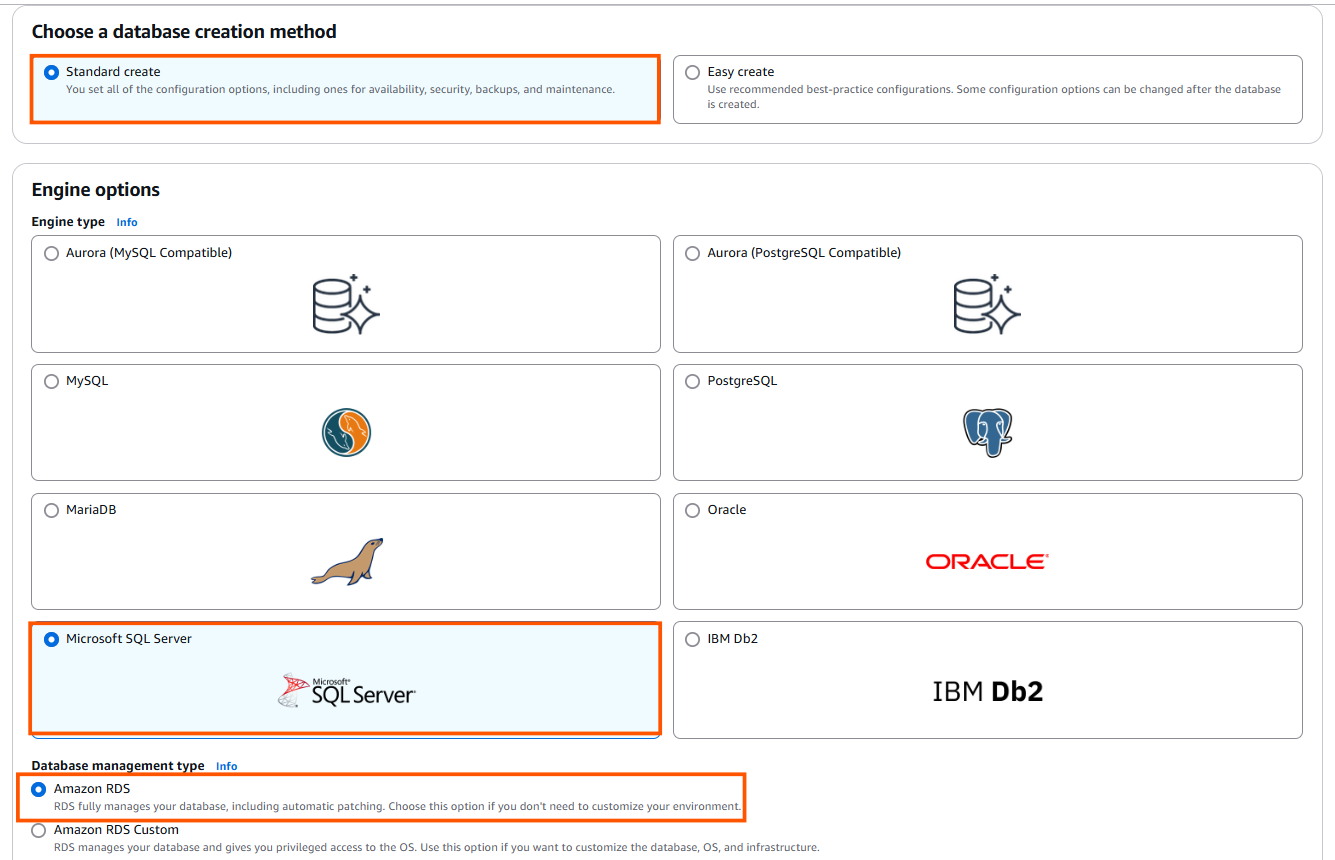
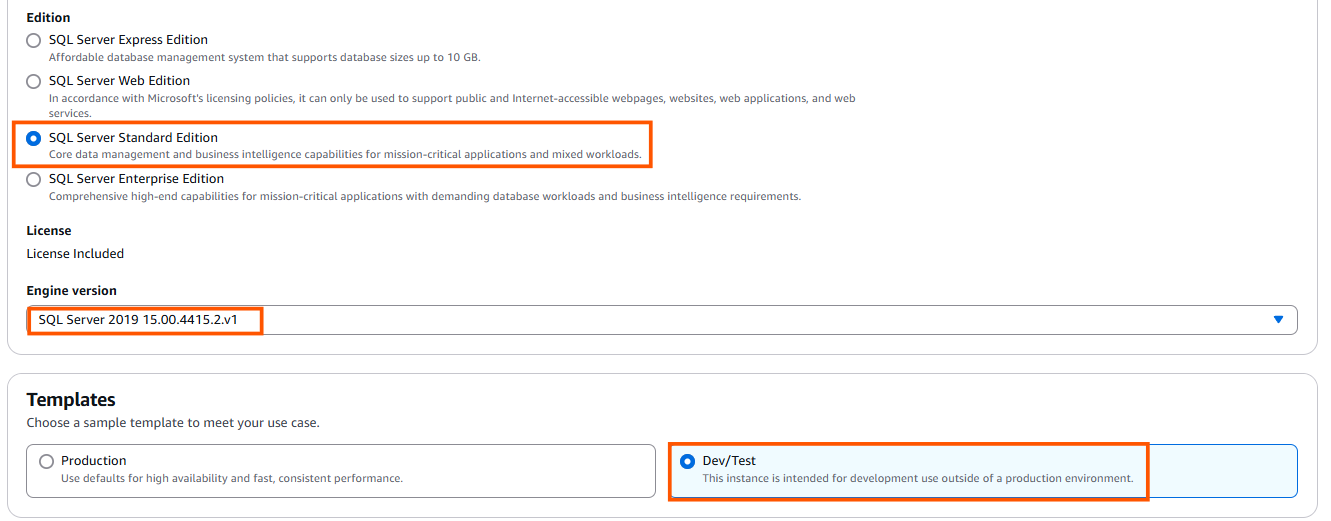
- Choose the “Standard Edition” for cost-effective, small-to-medium workloads with essential features, or opt for the “Enterprise Edition” for high scalability, advanced security, and complex workloads that require features like advanced analytics and high availability.
- Select “SQL Server version 2016 or higher” to ensure compatibility and optimal performance.
- If you are setting up for the first time, opt for a “Dev/Test environment” to ensure proper configuration.
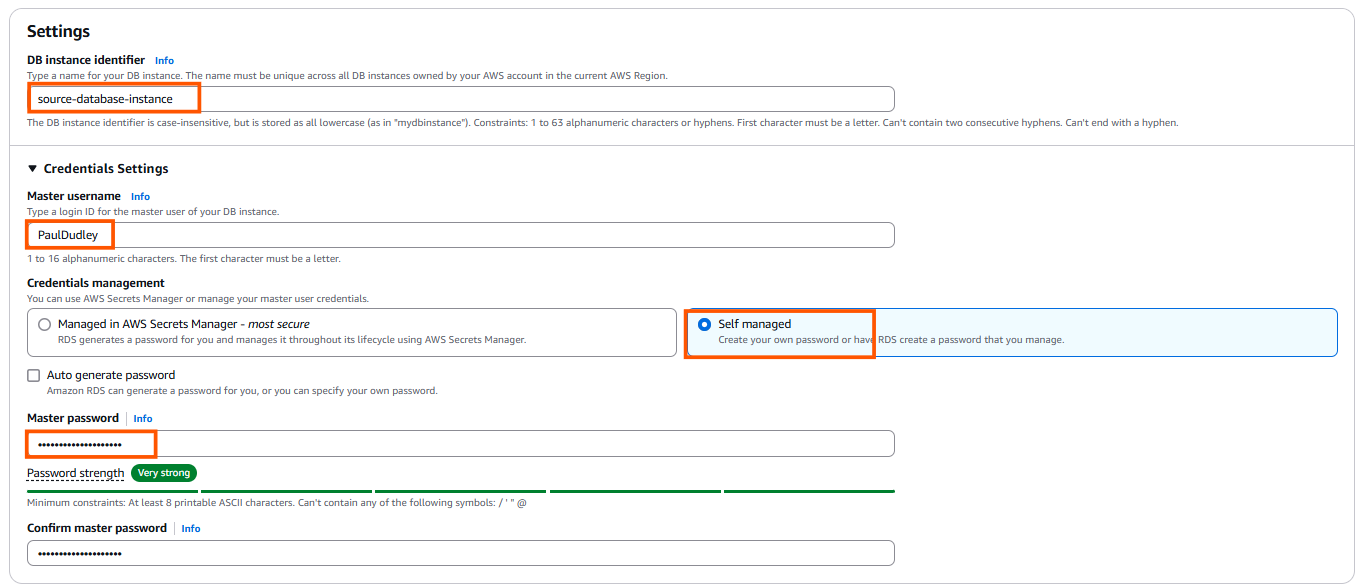
- Use “source-database-instance” as your database identifier name to follow standard naming conventions for clarity and consistency. If you’d like something more personalized, feel free to choose a name that suits your style.
- Pick a “master username” that’s easy for you to remember and aligns with your setup.
- Opt for a “Self-managed password”, enter a strong, secure password, and make sure to save it in a safe place-you’ll need it later.
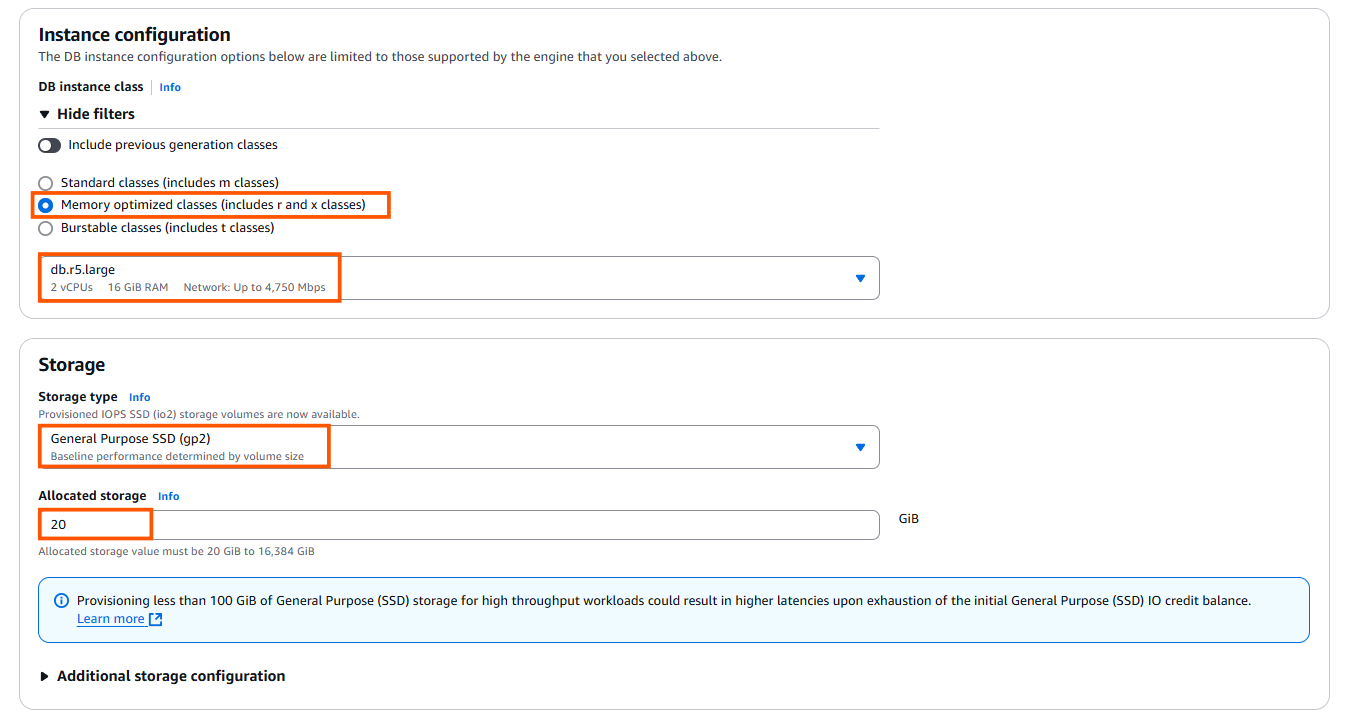
- If you’re just getting started, it’s a good idea to gain some hands-on experience before going live. Choose “memory optimized classes (r and x classes)” and select “db.r5.large” for a cost-effective and suitable instance type for testing.
- Select “General Purpose SSD” for a balanced performance-to-cost ratio. If you have specific needs, you can choose a different storage option that best fits your requirements.
- In “Availability and Durability”, select No for redundancy if you don’t need high availability or failover capabilities at this stage.
- Choose “Don’t connect EC2” to simplify your setup and focus only on the database instance.
- Select “Create new VPC,” then set up a new subnet using the dropdown menu in the VPC Settings section for streamlined connectivity.
- Enable local access by clicking “Yes” for public access in the Connectivity section, which is ideal for easy management and access.

- Head to the VPC settings section, select “Choose existing VPC,” and use the “default VPC” for a simple and hassle-free configuration.

- Uncheck “Performance Insights”—to reduce complexity.
- Once you’ve reviewed all the settings and configurations, take a final look at everything, and then click on “Create Database” to initiate the creation process.

- Wait for the status to change to “Available,” as displayed below.

Step 3: Configuring Your SQL Server Instance for Streamkap CompatibilityNote: This query can be executed locally using Azure Data Studio or DBeaver.
- To adhere to naming conventions, create the database with the name “source-database” using the following query:
```sql
- Verify if the database has been created by running the query shown below. It will display the name of the database if it has been created successfully.
```sql
- To enable Change Data Capture (CDC) on the “source-database”, allowing you to track and capture changes for further analysis or replication purposes, run the following query:
```sql
- To verify whether CDC has been enabled or not, run the following query:
```sql
- It should return an output that matches the one shown in the picture, indicating the status of CDC for the database.

Configuring an Existing RDS SQL Server for Streamkap Compatibility
If you already have an existing AWS RDS SQL Server instance, it might not be CDC-compatible. To check its compatibility, we’ll run a verification query. You need to verify if Change Data Capture (CDC) is enabled on the instance.
To check if CDC is enabled on your database, execute the query below:
Note: Make sure to replace “your-database-name” with the actual name of your database for all queries.
```sql
If CDC is already enabled, you’ll see “1” and can skip this section and proceed with your setup.
Enable CDC on database
- To enable Change Data Capture (CDC) on the your database, allowing you to track and capture changes for further analysis or replication purposes, run the following query:
```sql
- To verify whether CDC has been enabled or not, run the following query:
```sql
- It should return an output that matches the one shown in the picture, indicating the status of CDC for the database.
Configuring RDS SQL Server for Streamkap Integration
Access your RDS SQL Server database using a tool like Azure Data Studio or Dbeaver and run the following script:
- This script will create a new user with the necessary privileges for the Connector.
- The new user will have the required access and permissions to interact with the database for streaming or integration tasks.
```sql
- Executing the following query will create a new schema, which will be used to verify the successful data transfer.
```sql
- To allow the Connector to perform “Snapshots” for data backfilling, you need to create a dedicated table for this process.
- Run the following query to create the required table:
Note: Ensure the table name is exactly “STREAMKAP_SIGNAL”. Any variation will not be recognized
```sqlNote: Microsoft recommends storing CDC data files separately from primary database files. However, in RDS SQL Server, direct access to file paths is not available.
- To enable CDC on a table, execute the following query:
- Make sure to replace {schema} and {table} with the correct schema and table names. In our case, the schema is “hr”, and the table is “employee”.
```sql
- For enabling CDC on the STREAMKAP_SIGNAL table, use:
```sql
Snowflake Warehouse Set Up
Getting started with Snowflake is easy, whether you are a beginner or an experienced user. This guide will take you through the steps to create a new account or modify your existing account to be compatible with Streamkap.
Creating a New Snowflake Account
Step 1: Signup and create a Snowflake account
Head over to Snowflake’s website, enter the required information to sign up, and click “Continue.”
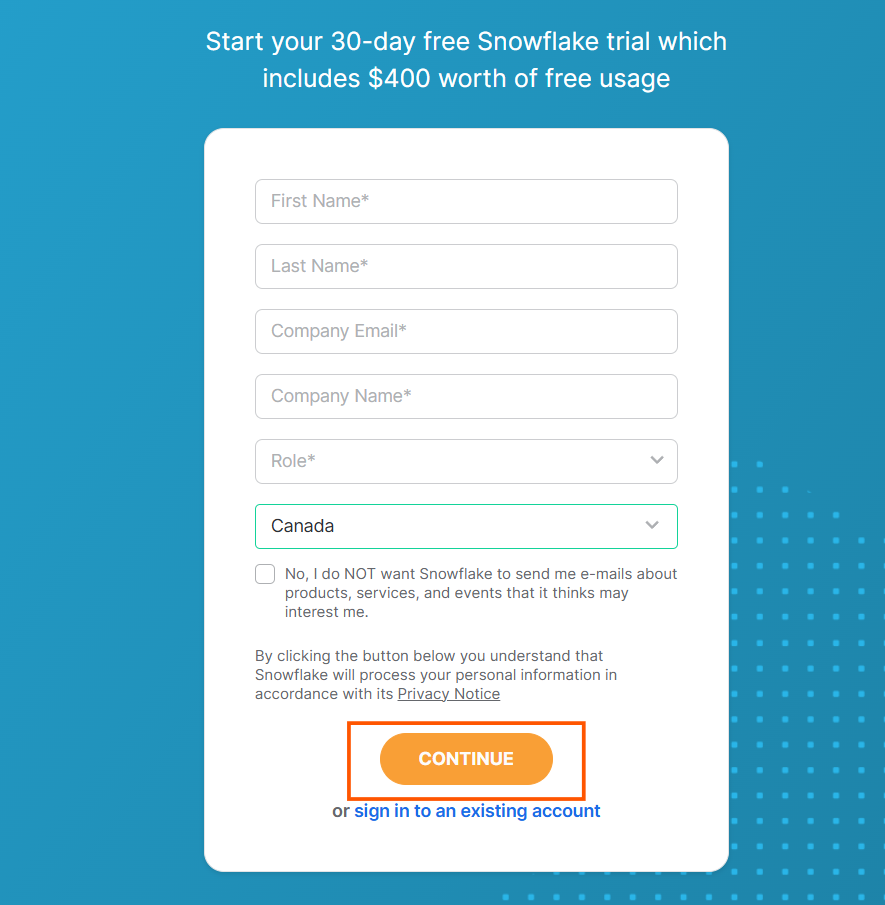
- You’ll receive a signup email with instructions. Simply follow the steps provided, and you’ll be prompted to enter your username and password to complete the signup process.

- Once your account is activated, you’ll receive an email containing a unique URL. Be sure to save this URL, as it is essential for establishing a connection with Streamkap.

Step 2: Access Your Snowflake Warehouse
-
After logging in, you’ll be taken to the Snowflake dashboard, where you can manage your account, access data, and execute queries efficiently.
-
To begin working with your queries, click on “+Create” in the left-hand navigation bar and select “SQL Worksheet.” This will open a new workspace where you can start executing your queries.

- In the SQL Worksheet, ensure you’re in the “Databases” section, as shown below. This is where you’ll need to run your query.

Step 3: Ensuring Snowflake Compatibility with Streamkap
- To get Snowflake ready for integration with Streamkap, you’ll need to execute the following script.
Note: Follow the comments for each query to ensure you’re executing the steps correctly before running the script.
```sql
- Once you’ve written the script, hit “Run All” from the top right corner to execute it. This will ensure all your queries run smoothly.

- If your network access is restricted to third-party connections, be sure to add StreamKap’s IP addresses to your network policy. This will ensure a seamless connection between your Snowflake instance and StreamKap.
| Service | IPs |
|---|---|
| Oregon (us-west-2) | 52.32.238.100 |
| North Virginia (us-east-1) | 44.214.80.49 |
| Europe Ireland (eu-west-1) | 34.242.118.75 |
| Asia Pacific - Sydney (ap-southeast-2) | 52.62.60.121 |
-
Generate an encrypted RSA private key in your machine for secure communication and authentication between Streamkap and your systems. Here’s the command to create your private key:
-
Generate your public key: The public key is created from your private key and is used for encryption, allowing secure data exchange with Streamkap. Run the following command to generate your public key:
-
To copy the key, run the following command, make sure to replace “copy command” with the correct clipboard command for your operating system:
-
For macOS: Use “pbcopy” to copy the contents of the key file to the clipboard.
-
For Windows: Use “clip” to copy the contents of the key file to the clipboard.- For Linux: Use “xclip” or “xsel” to copy the key to the clipboard.
-
Attach public key to “STREAMKAP_USER” by running the below SQL queries
```sql
Fetching credentials from existing Snowflake Warehouse
To successfully connect Snowflake with StreamKap and enable smooth data transfer and integration, you’ll need to gather the following credentials:
- Username- Snowflake URL- Private Key- Private Key Phrase- Warehouse Name- Database Name- Schema Name- Snowflake Role
Ensure you have access to all of these details to complete the integration.
- To get started with your Snowflake setup, navigate to your login page.
- Once logged in, to create a new SQL Worksheet, click on “+Create” in the left navigation bar, then select “SQL Worksheet” to begin running your queries.
- Make sure you’re in the “Database” section in your SQL Worksheet.
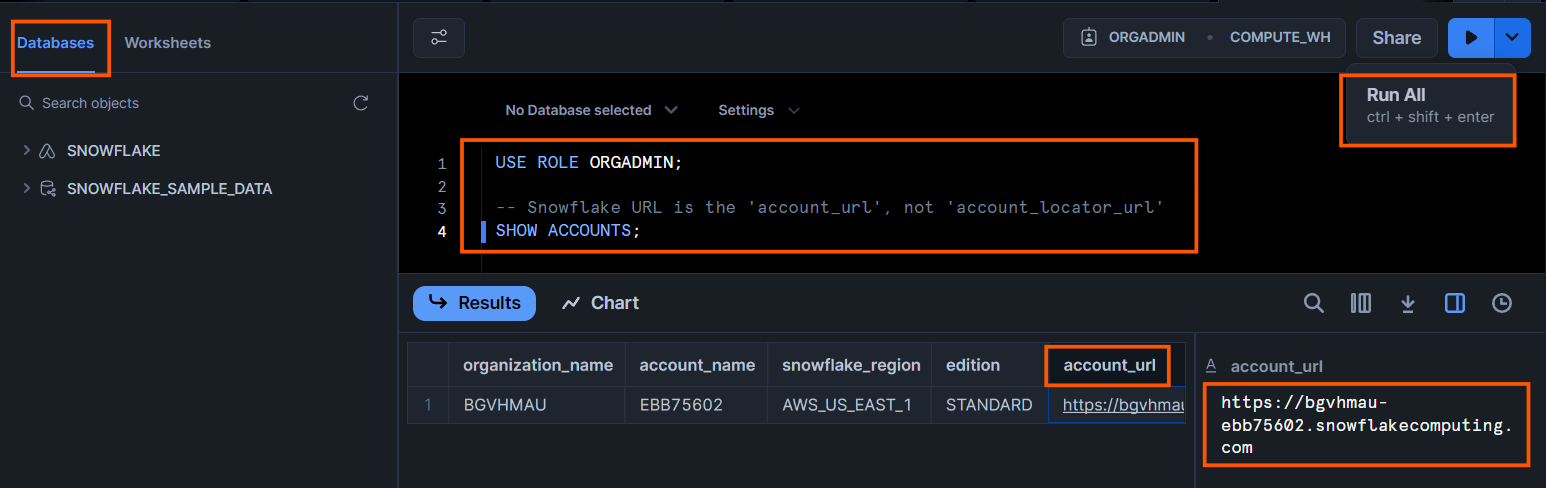
- Enter the SQL query and click on “Run All.”
```sql
- Once the query has executed, check the results for the “account_url” field.
- Click on the “account_url” to copy the URL.
- Username: The username will be STREAMKAP_USER, or whatever username you assigned to Streamkap.
```sql
-
Generate an encrypted RSA private key on your local machine for secure communication and authentication between Streamkap and your systems. Here’s the command to create your private key:
-
Generate your public key: The public key is created from your private key and is used for encryption, allowing secure data exchange with Streamkap. Run the following command to generate your public key:
-
Private Key: Copy your private key by running the command below (just swap out the copy command with the one that fits your system):
-
Private Key Phrase: This is the passphrase you set when creating your encrypted private key.
-
Warehouse Name: The warehouse name is usually STREAMKAP_DATAWAREHOUSE, or whatever name you assigned to it.
```sql
- Database Name: The database name is STREAMKAPDB, or whatever name you assigned to it.
```sql- Schema Name: The schema name is STREAMKAP, or whatever name you assigned to it.
```sql- Snowflake Role: The role is STREAMKAP_ROLE, or whatever role name you assigned to it.
```sql
Streamkap Set Up
To connect Streamkap to SQL Server, we need to ensure the database is configured to accept traffic from Streamkap by safelisting Streamkap’s IP addresses.
Note: If SQL Server accepts traffic from anywhere from the world you can move on to the “Configuring SQL server for Streamkap Integration” section.
Safelisting Streamkap’s IP Address
Streamkap’s dedicated IP addresses are:
| Service | IPs |
|---|---|
| Oregon (us-west-2) | 52.32.238.100 |
| North Virginia (us-east-1) | 44.214.80.49 |
| Europe Ireland (eu-west-1) | 34.242.118.75 |
| Asia Pacific - Sydney (ap-southeast-2) | 52.62.60.121 |
When signing up, Oregon (us-west-2) is set as the default region. If you require a different region, let us know. For more details about our IP addresses, please visit this link.
- To safelist one of our IPs, access your RDS SQL Server instance’s security group with type “CIDR/IP - Inbound” and select “Edit inbound rules.”
- Click “Add rule,” choose “SQL Server-RDS” as the type, select “Custom” as the source, and enter any of our relevant IP addresses followed by “/32.” For example, to add an IP address for North Virginia you would enter “44.214.80.49/32” as shown in the image below.

Adding RDS SQL Server Database as a Source Connector
Before adding SQL Server RDS as a source connector, ensure the following:
- IP Address Safelisting: Ensure that your IP address is added to the safelist, or configure your SQL Server RDS instance to allow traffic from Streamkap by default. This step is essential for establishing a secure connection between Streamkap and your RDS instance.
- SQL Configuration: Verify that you have executed all required SQL commands from the “Configuring AWS RDS SQL Server for Streamkap Integration” section. This includes setting up users, roles, permissions, and enabling Change Data Capture (CDC) on the required tables.
Both of these steps are critical for establishing a seamless connection between AWS RDS SQL Server and Streamkap.
Note: If you’re using SQL Server 2016 or later, you can integrate with Streamkap using CDC. For older versions, additional configuration may be required.
Step 1: Log in to Streamkap
- Sign in to the Streamkap. This will direct you to your dashboard.
Note: You need admin or data admin privileges to proceed with the steps below.
Step 2: Set Up a SQL Server Source Connector
- On the left sidebar, click on “Connectors,” then select the “Sources” tab.
- Click the “+ Add” button to begin setting up your SQL Server source connector.

- Enter “SQL Server” in the search bar and select “SQL Server RDS.”
- This will take you to the new connector setup page.

- You’ll be asked to provide the following details:
- Name: Choose a name for the SQL Server source in Streamkap.
- Endpoint: Copy the Endpoint from the “Connectivity & Security” tab of your SQL Server RDS instance.
- Port: The default port is 1433, If you’ve changed the port, update it accordingly.
- Signal Table Schema: Enter “STREAMKAP” if you followed the previous step or provide your own schema name.
- Username: Use “STREAMKAP_USER” which was created earlier.
- Password: Enter the password for the user.
- Source Database: Use “source-database” (or specify a custom database name if necessary).

If you choose not to use an SSH Tunnel, click “Next” and proceed to step 3.
If you opt to connect to your AWS RDS SQL Server through an SSH Tunnel, ensure the following:
- Your bastion host / SSH Tunnel server is connected to your SQL Server RDS instance.
- Your bastion host /SSH Tunnel allow traffic from any source or has the Streamkap IP Address safelisted
Log in to your Linux SSH Tunnel host and execute the commands below. If you are using a Windows server, refer to our SSH Tunnel guide for Windows.
- After running the commands above, fetch the “SSH Public Key” from Streamkap’s SQL Server source as shown below.

- Replace with the SSH Public key copied from earlier and run the code below.
After your SSH Tunnel server is restarted, enter the public IP address of your SSH Tunnel server as the SSH Host in Streamkap and click Next. You’ll then be directed to the schema and table selection page, like the one below.
Step 3: Plug in Schema and Table Names
If you’ve followed the guide, your SQL server should now have a “hr” schema within the “employees” table.
- If you’re using a different schema, plug in your own details.
- Once you’ve updated click Save to proceed.

- Once all the steps are completed correctly, you should be able to successfully create a SQL Server source connector as shown below.

In case you encounter any fatal errors, they could be caused by one of the following:
- Our IP addresses were not safelisted.
- Incorrect credentials.
- Incorrect database, schema, or table name.
- Insufficient permissions to query the table.
Adding a Snowflake Connector
- In order to add Snowflake as a destination, navigate to “Connection” on the left side, then click on “Destination” and press the “+Add” button.

- Search for Snowflake in the search bar and click on “Snowflake”.

You will see the configuration page below. The settings for Snowflake are as follows:
- Name: Enter a unique and memorable name for the destination (e.g., Streamkap_Snowflake).
- Snowflake URL: The URL provided by Snowflake after your account activation.
- Username: Your Streamkap user name (e.g., STREAMKAP_USER).
- Private Key: The private key generated from the .p8 file using your bash/terminal.
- Private Key Passphrase: Required only if your private key is encrypted. Otherwise, leave it blank.
- Warehouse Name: The name of your Snowflake warehouse (e.g., STREAMKAP_DATAWAREHOUSE).
- Database Name: The name of your Snowflake database (e.g., STREAMKAPDB).
- Schema Name: The name of your database schema (e.g., STREAMKAP).
- Snowflake Role: The specific role assigned to Streamkap (e.g., STREAMKAP_ROLE).
- Ingestion Mode:- Append Mode: Choose this if you’re adding new, unique data each time and don’t need to update or deduplicate existing records.
- Upsert Mode: Choose this if you need to update existing records or handle potential conflicts between new and existing data (e.g., updating customer information).
- Dynamic Tables (Optional):- Use Dynamic Tables: If you need to manage real-time data (e.g., frequent updates to customer information), dynamic tables ensure you’re always working with the latest records in Snowflake.
- Skip Dynamic Tables: If real-time updates and automatic deduplication are not required for your use case, you can skip creating dynamic tables.
- Click “Save” and wait until the status becomes active

- If everything is set up correctly, your Snowflake destination will be created successfully, and its status will be displayed as “Active,” as shown below. This means that Streamkap has successfully connected to your Snowflake instance and is ready to start streaming data from your RDS SQL Server source.

Adding a Pipeline
- Navigate to “Pipelines” on the left side and then press “+Create” in order to create a pipeline between source and destination.

- Select source and destination and click on “Next” on the bottom right corner.

- Select all the schemas or the specific schema you wish to transfer.

- Plug in a pipeline name and click “Save”.

- Once the pipeline is successfully created, it should appear like the screenshot below, with its status displayed as “Active.”

- Go to “Snowflake” and navigate to “SQL Querysheet”. Run the query as shown below in order to verify the transferred data.
```sql

By design Your “Table” in the destination will have the following meta columns apart from the regular columns.
| Column Name | Description |
|---|---|
| _STREAMKAP_SOURCE_TS_MS | Timestamp in milliseconds for the event within the source log |
| _STREAMKAP_TS_MS | Timestamp in milliseconds for the event once Streamkap receives it |
| __DELETED | Indicates whether this event/row has been deleted at source |
| _STREAMKAP_OFFSET | This is an offset value in relation to the logs we process. It can be useful in the debugging of any issues that may arise |
If you’re looking to modify the schema of the table, you must follow SQL Server’s schema evolution process, as outlined below, or choose to skip it.
SQL Server Schema Evolution
Structural changes to a source table in SQL Server, such as adding or removing columns, do not automatically reflect in Snowflake. To ensure that your Snowflake tables reflect the updated schema, you’ll need to follow a specific process. Here’s a step-by-step guide to handle schema evolution.
Step 1: Modify the Source Table
- First, make the desired changes to your source table in SQL Server. For example, to delete the last_name column from the hr.employees table:
```sql
Step 2: Refresh the Change Data Capture (CDC) Table
- Refresh the CDC table by running the following script. Replace the placeholders with relevant values.
Note: There cannot be more than 2 change tables for every source table.
```sql
Step 3: Verify Changes in Snowflake
- Once you’ve refreshed the CDC table and confirmed with Streamkap Support that your SQL Server Source has started streaming from the refreshed change table, verify the changes in Snowflake. To verify, run the following query:
```sql

Step 4: Disable CDC on the Outdated Change Table
- Once the change has been confirmed on the new refresh table outdated previous CDC table needs to be disabled using the following script.
```sql
By following these steps, you can ensure that schema changes in your SQL Server source tables are properly reflected in your Snowflake environment, maintaining data consistency and integrity across your systems.
What’s Next?
Thank you for reading this guide. If you have other sources and destinations to connect in near real-time check out the following guides.
- AWS RDS PostgreSQL to S3 using Streamkap
- Streamkap empowers Nala Money to optimize real-time money transfers to Africa.
For more information on connectors please visit here
Ricky Thomas
LinkedInAuthor Bio
Ricky has 20+ years experience in data, devops, databases and startups.
Published
March 8, 2025
TL;DR
• Stream SQL Server data to Snowflake with sub-second latency for zero-maintenance data pipelines and live business intelligence. • Create a foundation for AI/ML workflows and cross-organization data sharing without code or complexity. • Follow this guide for AWS SQL Server setup, Snowflake configuration, and Streamkap pipeline creation.
Related blog posts
.png)
Why Apache Iceberg? A Guide to Real-Time Data Lakes in 2025
Apache Iceberg brings SQL tables to cloud storage with ACID transactions and time travel. Learn why it's essential for 2025.
AWS RDS PostgreSQL Set Up
AWS RDS PostgreSQL stands out as one of the most widely used production databases. Its global adoption and everyday usage have prompted Amazon to make it exceptionally user-friendly. New users can set up an RDS PostgreSQL instance from scratch in just a few minutes.
Databricks Warehouse Set Up
Getting started with Databricks is a breeze, regardless of your experience level. This guide provides clear instructions on how to create a new account or use your existing credentials, ensuring a smooth and efficient streaming process.