How to Stream AWS Postgres Data to Iceberg on AWS with Streamkap
Paul Dudley
August 12, 2025
TL;DR
• Stream PostgreSQL to Iceberg on S3 in minutes for advanced analytics like predictive maintenance and equipment monitoring. • Build high-performance data lake architectures capable of handling massive sensor readings and telemetry. • Leverage Iceberg's time-travel capabilities and ACID transactions for reliable analytical workloads.
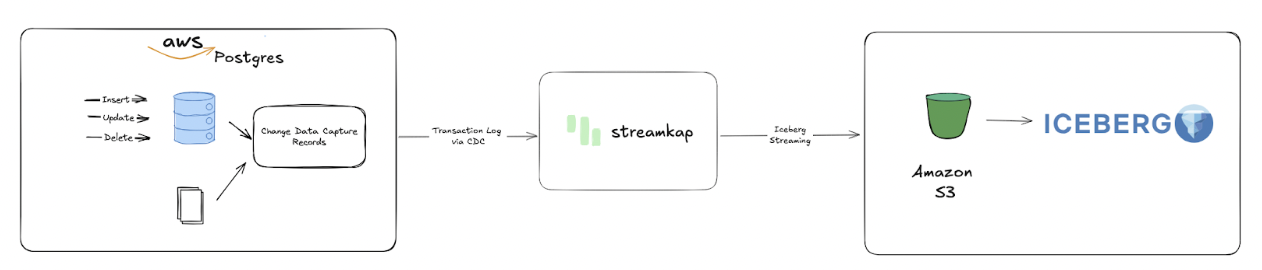
Introduction
In today’s fast-moving world, businesses demand timely data to fuel smart decisions. However, traditional data processing methods often introduce significant delays and complexity, hindering agility. That’s where Streamkap steps in, enabling you to Streamkap-italize your data! With Streamkap, you can establish real-time streaming pipelines from AWS PostgreSQL to Iceberg on S3 in minutes, not months.
Developers can leverage this guide to deploy advanced analytics, such as predictive maintenance and equipment health monitoring, directly on data stored in Iceberg on S3. By capturing operational data live from PostgreSQL and streaming it to Iceberg on S3, teams can build high-performance data lake architectures capable of handling massive sensor readings, equipment telemetry, and maintenance records with unmatched speed and reliability.
Guide Sections:
| Prerequisites | You’ll need accounts for AWS, and Streamkap. |
|---|---|
| Setting up a New AWS RDS PostgreSQL Instance from Scratch | This section will guide you through the process of setting up a new PostgreSQL database instance within AWS. |
| Configuring an Existing AWS RDS PostgreSQL Instance | For an existing AWS RDS PostgreSQL database, this section will detail how to modify its configuration to ensure Streamkap compatibility. |
| Preparing Your Iceberg on S3 Destination | This section will guide you through preparing your S3 environment and establishing the foundation for your Iceberg tables, which will serve as your real-time data destination. |
| Configuring Access for an Existing Iceberg on S3 Destination | If you already have an existing Iceberg setup on S3, this section will guide you on configuring the necessary AWS permissions (e.g., S3 bucket policies, IAM roles) to allow Streamkap to write data to your Iceberg tables.. |
Ready to Streamkap-italize your data? Let’s go!
Prerequisites
To follow along with this guide, ensure you have the following in place:
- Streamkap Account: You’ll need an active Streamkap account with either admin or data admin privileges. If you don’t have one, you can easily sign up here or request access from your admin.
- Amazon AWS Account: An active AWS account is essential. This account must have the necessary RDS and networking permissions to create, configure, or modify an AWS RDS PostgreSQL instance. Additionally, you’ll need permissions for Amazon S3 (to store your Iceberg data) and AWS Glue Data Catalog (to store Iceberg metadata). If you don’t have an AWS account, you can sign up here to get started.
Note: Setting up your AWS account requires a valid credit or debit card for verification.
AWS RDS PostgreSQL Set Up
AWS RDS PostgreSQL is a highly popular and user-friendly production database. Amazon’s streamlined services allow even new users to set up an RDS PostgreSQL instance in minutes. Similarly, integrating Streamkap’s necessary configurations into an existing instance is a straightforward process.
This section will guide you through various methods to set up and configure your AWS RDS PostgreSQL instance to ensure seamless compatibility with Streamkap’s real-time streaming capabilities.
Setting up a New AWS RDS PostgreSQL Instance from Scratch
Note on IAM Permissions: To set up a new AWS RDS PostgreSQL instance, ensure your IAM user or role has permissions for creating and managing RDS instances, parameter groups, subnet groups, networking, security, monitoring, and optional encryption and tagging. If you encounter permission restrictions, please ask your AWS administrator to grant you core RDS and networking permissions.
Step 1: Access the AWS Management Console
- Log in to your AWS Management Console.
- Type “RDS” in the search bar and click on “RDS” from the results.

Step 2: Create a new RDS PostgreSQL Instance
- Step 1 will take you to the RDS dashboard. From there, click on either “Databases” in the top left corner or “DB Instances” under the Resources section as depicted below.

- Select your desired region to host the RDS instance, then click “Create database.”

- Click “Standard create” radio button in the Choose a database creation method section
- Click “PostgreSQL” radio button in the Engine option section
- Scroll down and choose “PostgreSQL 16.4-R3” from Engine version drop down menu as shown below

- Under the “Templates” section, you can choose between “Production,” “Dev/Test,” or “Free tier,” depending on your specific requirements.
- Recommendation for Beginners: If you are setting up sub-second latency streaming for the first time, we highly recommend selecting the “Free tier.” This approach allows you to gain valuable hands-on experience with the entire setup process without incurring additional cloud costs.

- Within the “Settings” section, you will need to input a unique value for both your DB Instance identifier and your Master username.
- For “Credentials management,” select the “Self managed” radio button, and then proceed to fill in a strong, secure Master password and confirm it.

- In the Connectivity section, click “Yes” for Public access as illustrated below

- In the Additional Configuration section, plug in an Initial database name as shown below

- Finally, scroll to the bottom of the page and click “Create database” to initiate the database creation process. You will need to wait until your DB instance’s status changes to “Available.”
Step 3: Configuring Your PostgreSQL Instance for Streamkap Compatibility
By default, an AWS RDS PostgreSQL instance is not configured for Change Data Capture (CDC), which is essential for enabling sub-second latency streaming with Streamkap. To achieve this, several minor yet crucial adjustments must be made to the database parameters.
In this section of the guide, we will undertake the following key steps:
- Create a new parameter group
- Modify rds.logical_replication = 1
- Modify wal_sender_timeout = 0
- Attach the new parameter group to our PostgreSQL Instance
- Restart the PostgreSQL Instance to apply changes
- On your RDS dashboard click on “Parameter groups” on the left side and then click on “Create parameter groups” as shown in the following screenshot

- Provide a clear “Parameter group name” (e.g., streamkap-pg-params) and an optional “Description.” Ensure you choose “PostgreSQL” as the Engine type, “postgres16” as the Parameter group family, and “DB Parameter Group” as the Type. After inputting these details, click “Create.”

Once your parameter group is created, click on your parameter group and click on the “Edit” button on the right-side corner of the screen.
-
On the search bar
- Type “rds.logical_replication” and add “1” as value as shown below.
- Type “wal_sender_timeout” and add “0” as value as shown below.


-
After making these modifications, click “Save Changes.”
-
You have now successfully configured a parameter group for Change Data Capture (CDC). The subsequent step involves attaching this newly configured parameter group to your PostgreSQL instance to enable full CDC compatibility for the database.

- Scroll to the “Additional configuration” section. Under “DB Parameter Group”, choose the newly created parameter group from the list. Scroll to the bottom of the screen and click “Continue”.

- On the Modify DB instance page ensure Change Data Capture compatible parameter group shows as new value, under “Schedule modification”, click “Apply immediately” radio button and then click on “Modify DB instance”.

Step 4: Test Your PostgreSQL Instance for Change Data Capture (CDC) and Streamkap Compatibility
It is critically important to verify that the modifications made to your PostgreSQL instance have been correctly applied and are accurately reflected within the database. To perform this verification, establish a connection to your RDS PostgreSQL instance using a database management tool such as DBeaver, and then execute the following commands to confirm that CDC functionality is working as expected:
Show wal_level;
— We expect “logical” as output
Show wal_sender_timeout;
— We expect “0” as output


Configuring an Existing RDS PostgreSQL Instance for Streamkap Compatibility
If you already have an AWS RDS PostgreSQL instance, it might be compatible with change data capture (CDC), but this isn’t guaranteed. To confirm compatibility, you need to run two specific tests—both must succeed to verify CDC support.
Use a tool like DBeaver to connect to your RDS PostgreSQL instance and execute the following commands to check whether CDC is functioning properly.
Show wal_level;
— We expect “logical” as output
Show wal_sender_timeout;
— We expect “0” as output
For the RDS instance to be CDC-compatible, both tests must return the expected values: wal_level = logical and wal_sender_timeout = 0. If either test fails, the RDS parameter group will need to be updated.
In such cases, you’ll need to either modify the current custom RDS parameter group or create a new one with the required settings to support Change Data Capture (CDC). Specifically, you’ll need to adjust the following parameters.
If you already have a custom RDS parameter group, you can proceed directly to step 2.
Step 1: Create a Custom RDS Parameter Group
- On your RDS dashboard click on “Parameter groups” on the left side and then click on “Create parameter groups” as shown in the following screenshot

- Provide a clear “Parameter group name” (e.g., streamkap-pg-params) and an optional “Description.” Ensure you choose “PostgreSQL” as the Engine type, “postgres16” as the Parameter group family, and “DB Parameter Group” as the Type. After inputting these details, click “Create.”

-
Once your parameter group is created, click on your parameter group and click on the “Edit” button on the right-side corner of the screen.
-
On the search bar
- Type “rds.logical_replication” and add “1” as value as shown below.
- Type “wal_sender_timeout” and add “0” as value as shown below.


- After making these modifications, click “Save Changes.”
We have successfully created a parameter group configured for Change Data Capture (CDC). The next step is to attach this parameter group to your existing PostgreSQL instance to enable CDC compatibility for the database.
Step 2: Attaching Parameter Group to RDS PostgreSQL Instance
- Open your PostgreSQL instance from the RDS dashboard page and click “Modify” on the top right corner as illustrated below

- Scroll to the “Additional configuration” section. Under “DB Parameter Group” choose the newly created parameter group from the list. Scroll to the bottom of the screen and click “Continue”.

- On the Modify DB instance page ensure Change Data Capture compatible parameter group shows as new value, under “Schedule modification”, click “Apply immediately” radio button and then click on “Modify DB instance”.

- After the modification of your RDS PostgreSQL instance is complete, run the following commands again to ensure CDC functionality is working as expected.
Show wal_level;
— We expect “logical” as output
Show wal_sender_timeout;
— We expect “0” as output
Iceberg set up
Whether you’re new to Iceberg or already familiar with data lake technologies, this guide will walk you through the essentials. From setting up your environment to configuring your storage and catalog, we’ll ensure a smooth and efficient experience as you begin working with Apache Iceberg for reliable, scalable data management.
Preparing your Iceberg on S3 destination
Step 1: Log in to the AWS Management Console
- Log in to your AWS Management Console and select the region you specified in the above section.

Let’s create a bucket now:
- Go to the search bar, type “S3,” and select S3.
- Now click “Create bucket”.


- Give your S3 bucket a unique name that’s easy to identify later.

- Public Access: Uncheck all public access options to avoid giving public permissions. Since the access is via third-party services, it’s better to uncheck these to prevent networking or configuration issues.

- With default settings and click ‘Create bucket’ to proceed with the setup.

Step 2: Create new AWS Glue database
- Type “Glue” in the search bar and click on “AWS Glue” from the results.

- Select the same region that we had while creating S3 bucket, in this case we preferred us-west-2.
- From the left side navigation bar, navigate to the database to create database for our data.

- Click on “Add database” as depicted in the picture below.

- Provide a unique database name and include a clear, descriptive explanation to define its purpose within AWS Glue.
- Then, click on “Create database” to finalize the creation.

- Once the database is successfully created, it will appear in your list of databases—just like what is shown in the screenshot below.

Step 3: Create new Policy and IAM role for Streamkap connection
- Type “IAM” in the search bar, then select IAM section.

- Navigate to Policies in the left menu and click Create Policy.
- Search for S3 and select AmazonS3FullAccess as a base policy.

-
Permission Requirement for S3 and Glue:
- “s3:GetObject”,
- “s3:PutObject”,
- “s3:DeleteObject”,
- “s3:ListBucket”
- “glue:GetDatabase”,
- “glue:GetDatabases”,
- “glue:CreateTable”,
- “glue:GetTable”,
- “glue:GetTables”,
- “glue:UpdateTable”,
- “glue:DeleteTable”,
- “glue:CreatePartition”,
- “glue:GetPartition”,
- “glue:GetPartitions”,
- “glue:BatchCreatePartition”,
- “glue:UpdatePartition”,
- “glue:DeletePartition”,
- “glue:BatchDeletePartition”
-
It will first display the visual format of the policy. You can either select the policy you want or toggle to the JSON format and paste the following policy for S3 and AWS Glue.

- Click “Next”.
- Plug in Policy Name as Steramkap_warehouse_policy (or any name of your choice)
- Plug in Description as This policy will be used to put data into S3

- Click on “Create Policy” which can be found in the bottom right corner.

- On the left side navigate to “Roles**”** and click on the “Create role” on the top right corner.

- Select Custom Trust policy and enter policy as shows below for Streamkap to allows the Streamkap production tenant access to your AWS Glue instance.

- Next, under Filter by type choose the Custom Managed Policy option. Then, select the policy you just created and click Next to proceed.
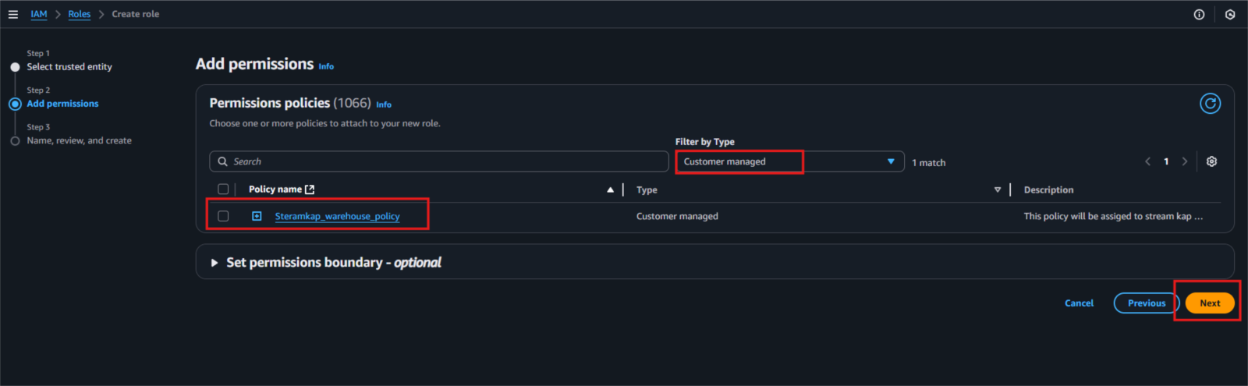
- Provide a meaningful name and a detailed description for the role to help identify its purpose easily in the future. After carefully reviewing all the policy settings to ensure they meet your requirements, click on the “Create role” button to finalize the role creation process.

- After the role is created, it will appear as shown in the picture below, confirming that the setup was successful and the role is ready for use.

Navigate to the IAM role and copy its Role ARN. We’ll use this ARN when setting up the connection with Streamkap.

Step 4 : Add role to AWS glue
- Type “Glue” in the search bar and click on “AWS Glue” from the results.
- Click on “Set up roles and users” to grant AWS Glue access and assign a default IAM role for your account.

- Select the role you created earlier and click Next to continue.

- Choose the specific S3 bucket you want AWS Glue to access, grant it read-only permissions, and then click Next to proceed.

Select the role you created earlier to set it as the default IAM role, then click Next to continue.

- Review all the changes carefully, then click on Apply changes to finalize the configuration.

Configuring Access for an Existing Iceberg on S3 Destination
Step 1: Create new Policy and IAM role for Streamkap connection
- Type “IAM” in the search bar, then select IAM section.
- Navigate to Policies in the left menu and click Create Policy.
- Search for S3 and select AmazonS3FullAccess as a base policy.
-
Permission Requirement for S3 and Glue:
- “s3:GetObject”,
- “s3:PutObject”,
- “s3:DeleteObject”,
- “s3:ListBucket”
- “glue:GetDatabase”,
- “glue:GetDatabases”,
- “glue:CreateTable”,
- “glue:GetTable”,
- “glue:GetTables”,
- “glue:UpdateTable”,
- “glue:DeleteTable”,
- “glue:CreatePartition”,
- “glue:GetPartition”,
- “glue:GetPartitions”,
- “glue:BatchCreatePartition”,
- “glue:UpdatePartition”,
- “glue:DeletePartition”,
- “glue:BatchDeletePartition”
-
It will first display the visual format of the policy. You can either select the policy you want or toggle to the JSON format and paste the following policy for S3 and AWS Glue.
- Click “Next”.
- Plug in Policy Name as Steramkap_warehouse_policy (or any name of your choice)
- Plug in Description as This policy will be used to put data into S3
- Click on “Create Policy” which can be found in the bottom right corner.
- On the left side navigate to “Roles**”** and click on the “Create role” on the top right corner.
- Select Custom Trust policy and enter policy as shows below for Streamkap to allows the Streamkap production tenant access to your AWS Glue instance.
- Next, under Filter by type choose the Custom Managed Policy option. Then, select the policy you just created and click Next to proceed.
- Provide a meaningful name and a detailed description for the role to help identify its purpose easily in the future. After carefully reviewing all the policy settings to ensure they meet your requirements, click on the “Create role” button to finalize the role creation process.
- After the role is created, it will appear as shown in the picture below, confirming that the setup was successful and the role is ready for use.
Navigate to the IAM role and copy its Role ARN. We’ll use this ARN when setting up the connection with Streamkap.
Step 2: Add role to AWS glue
- Type “Glue” in the search bar and click on “AWS Glue” from the results.
- Click on “Set up roles and users” to grant AWS Glue access and assign a default IAM role for your account.
- Select the role you created earlier and click Next to continue.
- Choose the specific S3 bucket you want AWS Glue to access, grant it read-only permissions, and then click Next to proceed.
Select the role you created earlier to set it as the default IAM role, then click Next to continue.
- Review all the changes carefully, then click on Apply changes to finalize the configuration.
Streamkap Set Up
To connect Streamkap to AWS RDS PostgreSQL, we need to ensure the database is configured to accept traffic from Streamkap by safelisting Streamkap’s IP addresses in the PostgreSQL instance.
Note: If your AWS RDS PostgreSQL instance accepts traffic from anywhere from the world you can move on to the “Configuring AWS RDS PostgreSQL Database for Streamkap Integration” section.
Safelisting Streamkap’s IP Address
Streamkap’s dedicated IP addresses are
| Service | IPs |
|---|---|
| Oregon (us-west-2) | 52.32.238.100 |
| North Virginia (us-east-1) | 44.214.80.49 |
| Europe Ireland (eu-west-1) | 34.242.118.75 |
| Asia Pacific - Sydney (ap-southeast-2) | 52.62.60.121 |
When signing up, Oregon (us-west-2) is the default region. Let us know if you need it to be elsewhere.
In order to safelist one of our IPs, open your RDS PostgreSQL instance’s security group with type = “CIDR/IP - Inbound” and click “Edit inbound rules”.
Click on “Add rule”, choose “PostgreSQL” as type, “Custom” as source, and paste any of our relevant IP addresses followed by “/32”. For instance, if you want to add IP address for Oregon in the custom box it would look like “52.32.238.100/32” as shown in the below image.

Configuring AWS RDS PostgreSQL Database for Streamkap Integration
Streamkap recommends creating a dedicated user and role within your PostgreSQL instance to facilitate secure and controlled data streaming. This approach ensures granular access management and follows best practices for database security.
Access your PostgreSQL database via a tool like Dbeaver and run the following code
Step 1: Create a dedicated user and role for Streamkap
```sql
Note: You must plug in your own password
Step 2: Attach role to user and grant replication privileges to the rol
```sql
Step 3: Grant permissions on the database
```sql
Note: In this guide our initial database at the time of configuration was “sourcedatabase”. Plug in your own database name if it is different from the one mentioned earlier.
Step 4: Grant permissions on schema(s), table(s), and future table(s)
```sql
Note: In this guide our initial schema at the time of configuration was “public”. Plug in your own schema name if it is different from the one mentioned earlier.
```sql
```
Step 5: Enabling Streamkap signal schema and table
Streamkap will use the following schema and table to manage snapshot collections.
```sql
Step 6: Creating sample table
Let’s create a sample table from which Streamkap will stream data. If you already have an existing table(s), you would like to stream from, you can skip this step.
```sql
```
Step 7: Create publication(s), and replication slot
We can create publication(s) for all tables or for only the sample orders table that was created few seconds ago or for a select group of tables
```sql
```
```sql
```
Adding RDS PostgreSQL as a Source Connector
Before proceeding to add RDS PostgreSQL as a source connector
- Ensure that our IP address is safelisted, or that your RDS PostgreSQL instance is configured to accept traffic from Streamkap by default.
- Make sure you have successfully ran all SQL code mentioned in the “Configuring AWS RDS PostgreSQL Database for Streamkap Integration” section
The above two points mentioned are mandatory in order to successfully connect your AWS RDS PostgreSQL as a source with Streamkap.
Note: If you are using PostgreSQL 16, you can connect your clone to Streamkap, and it will function as expected. However, for PostgreSQL 15 or earlier, you must connect directly.
Step 1: Sign-in to Streamkap
- Visit the Streamkap and log in. You will land in the dashboard page.
Note: You need admin or data admin privileges to proceed with the subsequent steps.
Step 2: Create a PostgreSQL source connector
- Click “Connectors” on the left side, then click on “Sources” tab, and then click on the “+ Add” button as depicted below.

- Scroll and choose “PostgreSQL”. You will land on the new connector page.

- You will be requested to fill
- Name – Your preferred name for the PostgreSQL source within Streamkap
- Hostname – Copy Endpoint under the “Connectivity & security” tab on your RDS PostgreSQL instance
- Port - The default port is 5432. If you have changed the port number, make sure to replace it accordingly.
- Username – Streamkap_user. We created this in the previous section
- Password – Your user’s password
- Database – sourcedatabase if you followed the guide or your own database name
- Note: By default, you will see “public” as Signal Table Schema. Please replace accordingly - Heartbeat – Turn the toggle “On” and fill Streamkap_signal as value if you followed the previous step or enter your own schema name.
- Replication Slot Name - Streamkap_pgoutput_slot if you followed the previous step or enter your replication slot name.
- Publication Name – Streamkap_pub if you followed the previous step or enter your publication name.

If you decide to not use SSH Tunnel press “Next” and go to step 3.
If you decide to connect to your AWS RDS PostgreSQL via an SSH Tunnel ensure
- Your bastion host / SSH Tunnel server is connected with your PostgreSQL instance
- Your bastion host / SSH Tunnel server allows traffic from anywhere or safe listed Streamkap IP Address
Login to your Linux SSH Tunnel host and run the following commands. If you are using a Windows server visit our SSH Tunnel guide for Windows.
After running the above commands, fetch the SSH Public Key from Streamkap’s PostgreSQL source as depicted below.

Replace with the SSH Public key copied from earlier and run the following code
After your SSH Tunnel server is restarted plug in your SSH Tunnel server’s public IP address as SSH Host in Streamkap and press “Next”. You will land on the schema and table selection page like the following.
Step 3: Plugging in Schema and Table Names

If you followed the guide, your PostgreSQL database should now include an “orders” table in the “public” schema. If you are using a different schema, update the relevant schema and table names, then click “Save.”
If all the steps were completed correctly, you should be able to successfully create a PostgreSQL source connector as shown below.

-
In case you encounter any fatal errors, they could be caused by one of the following:
- Our IP addresses were not safelisted.
- Incorrect credentials.
- Incorrect database, schema, or table name.
- Insufficient permissions to query the table.
Step 3 : Create Iceberg destination connector
- From the side navigation bar, go to Connectors, then switch to the Destinations tab. Search for Iceberg in the list and select it to begin the setup process.

- Enter streamkap_datawarehouse as the name of the destination — if you’ve followed the naming conventions from this guide.
- Select glue as the catalog type to match the setup we’ve configured earlier.
- Paste the IAM Role ARN (arn:aws:iam::…:role/streamkap_role) that you created in the previous steps.
- Choose us-west-2 as the region — assuming you’re using the same region as outlined in this guide.
- Enter s3a://streamkapatawarehouse as the S3 bucket path used in the earlier setup.
- Set the schema name to streamkap_warehouse, which corresponds to the Glue database we created.
- Select insert as the insert mode to define how records will be written into Iceberg.
- Click “Save” to complete the destination setup.

- Once the configuration has been completed successfully, proceed to verify that the active status is properly reflected and functioning as expected.

Adding a Pipeline
- Click on “Pipelines” on the left side of the screen, click on “+ Create” and then choose your relevant Postgres source from “select a Source” and your Iceberg destination from “select a Destination” as depicted below.

Select the “Public” schema if you followed the guide. Otherwise, make the appropriate selections and click “Next”.

- Assign a name to the pipeline, add the appropriate tags as needed, enable the snapshot feature for the topic, and then click on the save button to apply the changes.

- Upon successful creation of the pipeline, it should look similar to the below screenshot with status as “Active”.

- Download the files from the S3 bucket, convert the data into a table format, and then verify the accuracy of the resulting data.

By design Your “Music” table in the destination will have the following meta columns apart from the regular columns.
| Column Name | Description |
|---|---|
| _STREAMKAP_SOURCE_TS_MS | Timestamp in milliseconds for the event within the source log |
| _STREAMKAP_TS_MS | Timestamp in milliseconds for the event once Streamkap receives it |
| __DELETED | Indicates whether this event/row has been deleted at source |
| _STREAMKAP_OFFSET | This is an offset value in relation to the logs we process. It can be useful in the debugging of any issues that may arise |
What’s Next?
Thank you for reading this guide. If you have other sources and destinations to connect in near real-time check out the following guides.
For more information on connectors please visit here
Paul Dudley
LinkedInAuthor Bio
Paul is the CEO and Co-Founder of Streamkap
Published
August 12, 2025
TL;DR
• Stream PostgreSQL to Iceberg on S3 in minutes for advanced analytics like predictive maintenance and equipment monitoring. • Build high-performance data lake architectures capable of handling massive sensor readings and telemetry. • Leverage Iceberg's time-travel capabilities and ACID transactions for reliable analytical workloads.
Related blog posts
.png)
Why Apache Iceberg? A Guide to Real-Time Data Lakes in 2025
Apache Iceberg brings SQL tables to cloud storage with ACID transactions and time travel. Learn why it's essential for 2025.
AWS RDS PostgreSQL Set Up
AWS RDS PostgreSQL stands out as one of the most widely used production databases. Its global adoption and everyday usage have prompted Amazon to make it exceptionally user-friendly. New users can set up an RDS PostgreSQL instance from scratch in just a few minutes.
Databricks Warehouse Set Up
Getting started with Databricks is a breeze, regardless of your experience level. This guide provides clear instructions on how to create a new account or use your existing credentials, ensuring a smooth and efficient streaming process.