Streaming with Change Data Capture to ClickHouse
Ricky Thomas
April 24, 2024
TL;DR
• Streamkap's ClickHouse connector enables high-performance CDC streaming with linear scalability and no performance drop. • ClickHouse creates materialized views on ingestion, delivering significantly faster analytical queries than traditional warehouses. • Support for inserts and upserts, multiple data types, and column-oriented storage for real-time use cases.
Introduction
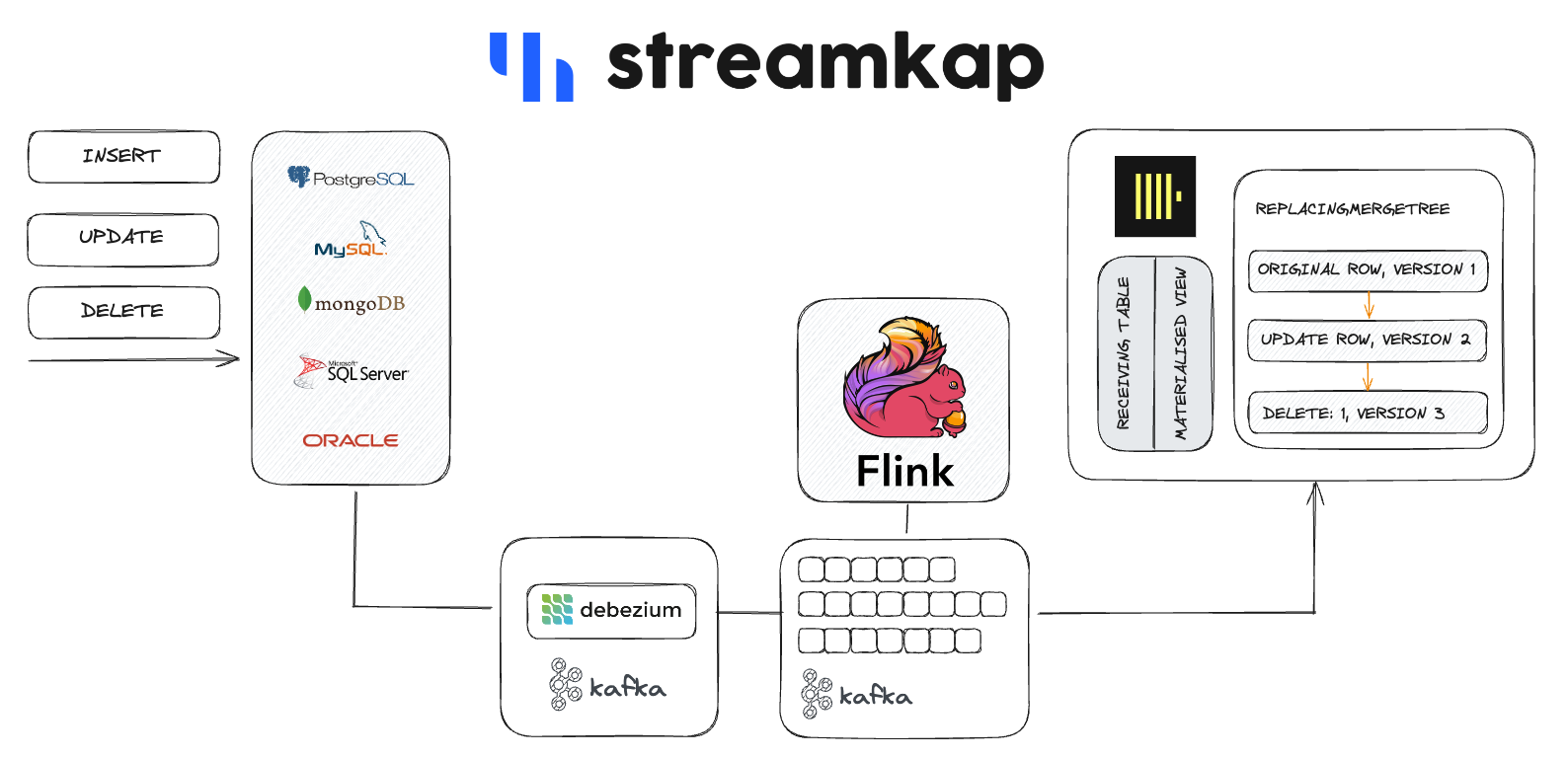
We’re excited to announce our new ClickHouse database connector for streaming CDC (Change Data Capture) data into ClickHouse.
Since ClickHouse is perfect for real-time applications, we have built a high-performance ClickHouse connector that uses change streams that scale linearly with no drop in performance.
If you are not familiar with the concept of Change Data Capture (CDC), you can learn more by reading about Change Data Capture in Streaming to help understand how ClickHouse CDC could be useful to you.
We will take a look at some of the connector features as well as performance throughput.
Technologies
ClickHouse is a real-time open-source column-oriented database. A column-oriented structure means data is stored and retrieved by columns rather than by rows. While there are similarities to data warehouses, a key differentiator is that ClickHouse creates materialized views on ingestion (write) which results in significantly faster analytical queries, making it suitable for real-time use cases.
Streamkap is a high throughput, zero maintenance streaming platform for when you need to move fast and save costs with 24/7 support utilising familiar technologies like Apache Kafka, Kafka Connect, Debezium and Apache Flink.
Here is an overview of how Streamkap streams from a database to ClickHouse.
Data Types Support
Our connector supports the following data types

JSON fields are currently ingested as strings, the use of allow_experimental_object_type=1 is currently under testing.
Inserts/Upsert Mode
We support data ingestion into ClickHouse tables via Inserts (append) and Upserts, while upsert mode is our connector’s default mode.
Insert mode will provide higher throughput and keep a historical set of changes within the ClickHouse tables written to upon ingestion.
Upsert mode will not keep historical changes but can only be used where a primary key can be used from the source to update the destination table.
Insert (Append) Mode
Insert/Append results in every change being tracked and inserted as a new row in ClickHouse. Delete operations at source will be marked in ClickHouse as deleted using the meta value __deleted**.**
To use Insert (Append) mode, the ClickHouse engine MergeTree is used.

Upsert Mode
Upserts are what you may be used to where both inserts and updates are combined. If there is a match on the primary key of the row, the value will be overwritten. Conversely, if there is no match the event will be inserted.
Upsert mode is implemented using ClickHouse’s ReplacingMergeTree engine.
The ReplacingMergeTree engine de-duplicates data during background merges based on the ordering key, allowing old records to be cleaned up.
Upsert Example with basic types
An upsert is shown here in JSON format. The key has only one field `id` which is the primary key on which rows will be de-duplicated:
The resulting table:

Data:

De-duplicated data, using FINAL:

Snapshotting
Snapshotting refers to the process of loading existing data from the database into ClickHouse. The backfilling of data is done with Select statements, unlike streaming mode which reads from the database log.
By default, Streamkap will use incremental snapshots. This is a watermarking approach that is both safe and suitable for large tables creating near-zero impact on the source database. Due to the watermarking, the snapshot process can resume from where it was interrupted if necessary.
Metadata
Streamkap adds additional metadata columns to each insert to the ClickHouse table for better analysis and modelling post-loading, as well as to support upserts.
The following metadata columns are added to each ClickHouse table:
- streamkap_ts_ms: timestamp CDC event reached streamkap
- **__deleted: if the current CDC event is a delete event, for “upsert” mode a secod streamkapdeleted computed column of type UInt8 field is used for ReplacingMergeTree
- streamkappartition: smallint representing the internal Streamkap partition number obtained by applying consistent hashing on the source records key fields
- streamkapsource_ts_ms: timestamp when the change event happened in the source database
- streamkapop: CDC event operation type (c insert, u update, d delete, r snapshot, t truncate)
Handling Semi-Structured Data
Nested Arrays & StructsBelow
Below we provide some examples of how complex structures are mapped to ClickHouse types automatically.
To support Arrays containing structs, Streamkap’s role in ClickHouse must be altered to the following value, flatten_nested to 0:

ALTER ROLE STREAMKAP_ROLE SETTINGS flatten_nested = 0;
Nested Struct field containing sub array
An input record is shown here in JSON format, where the key has only one field id:

The resulting table. Not how the `obj` column has been mapped to an `Tuple(nb Int32, str String, sub_arr Array(Tuple(n Int32, s String)), sub_arr_str Array(String))` to handle the complex structure:

Data:

Nested Array field containing sub struct
An input record is shown here as JSON format, where key has only one field id:

Again the resulting table, with the `arr` column mapped to a `Array(Tuple(nb Int32, str String))`

Data:

Data Consistency & Delivery Guarantees
Streamkap offers at-least-once delivery guarantee for ClickHouse and defaults to upsert mode.
For Insert/Append mode, this could result in additional duplicate rows being inserted to ClickHouse but ClickHouse materialized views can filter them out.
With Upsert mode, the default mode, we carry out deduplication with the source record key.
Transforms
Streamkap supports transformations in the pipeline so that data can be sent to ClickHouse pre-processed. This is carried out by Apache Flink, which will read from the Kafka topic (immutable data inserted), transform within Flink and write back to a new topic to be inserted into ClickHouse.

This is useful for semi-structured data, pre-processing and cleanup tasks. It can also be significantly more efficient than working on the data post-ingestion.
Below we present some common transformations performed by Streamkap.
Fix inconsistencies in semi-structured data
Consider the fixing of an inconsistent semi-structured date field:

Using Streamkap transforms, all records can be converted to a common format for ingestion into the ClickHouse DateTime64 column

Split large semi-structured JSON documents
With document databases, child entities can be modelled as sub-arrays nested inside the parent entity document

In ClickHouse it can make sense to represent these child entities as separate rows. Using Streamkap transforms, the child entity records can be split into individual records

Schema Evolution
Schema evolution or drift handling is the process of making changes to the destination tables to reflect the source changes, such as additional columns being added/removed.
The Streamkap connector automatically handles schema drift within ClickHouse in the following scenarios.
Additional Columns: An additional field will be detected and a new column in the table created to receive the new data.
Removal of Columns: This column will now be ignored and no further action taken.
Changing Column Type: An additional column is created in the table using a suffix to represent the new type. Eg ColumnName_type
Additional tables can be added to the pipeline at any stage.
We show some examples of this schema evolution below.
Add Column
Consider the following input record before schema evolution:

A new column `new_double_col` is added to the upstream schema. This causes the ClickHouse schema to evolve:

ClickHouse data:

Evolve Int to String
An input record before schema evolution:

A new record is ingested after the schema has evolved upstream:

ClickHouse data, after the new column IntColumn_str has been added:

Performance
ClickHouse is for real-time use cases so we made our connector able to scale linearly with increased resources. In our test below we demonstrate linear performance up to 85k CDC records per second in upsert mode but we are confident this can scale as high as you need.
For our test, we used a Clickhouse cluster instance of 3 nodes each of 32GiB with 8 vCPUs.
Input record format contains basic types, a medium string ~100 characters and a large string of approximately 1000 characters and we used upsert mode, which would be slower than insert mode.

Baseline Single Partition
Baselining with a single Streamkap task and Clickhouse partition with multiple bulk sizes.
Throughput:

Latency per bulk size:

For snapshots/backfills, it makes sense to use bulk sizes of over 100,000 records and this is automatically optimized within Streamkap
For streaming mode, smaller bulk sizes are usually desirable but again this is automatically optimized.
These are just some artificial tests with fixed bulk size to demonstrate the tradeoff between throughput and latency. In practice, the bulk size varies with the size of the internal queue and Streamkap will automatically optimize accordingly.
Scalability
Here we tested with 100,000 records per bulk size, and increasing the number of tasks: 1, 2, 4 and 8. We can see that the throughput scales roughly linearly with the number of tasks.

Summary
Streamkap has built the highest-performing CDC connector for ClickHouse while adding many features required for production pipelines.
It’s possible to start streaming CDC data to ClickHouse in minutes with zero maintenance using Streamkap. Sign up at streamkap.com to get started.
Ricky Thomas
LinkedInAuthor Bio
Ricky has 20+ years experience in data, devops, databases and startups.
Published
April 24, 2024
TL;DR
• Streamkap's ClickHouse connector enables high-performance CDC streaming with linear scalability and no performance drop. • ClickHouse creates materialized views on ingestion, delivering significantly faster analytical queries than traditional warehouses. • Support for inserts and upserts, multiple data types, and column-oriented storage for real-time use cases.
Related blog posts
.png)
Why Apache Iceberg? A Guide to Real-Time Data Lakes in 2025
Apache Iceberg brings SQL tables to cloud storage with ACID transactions and time travel. Learn why it's essential for 2025.
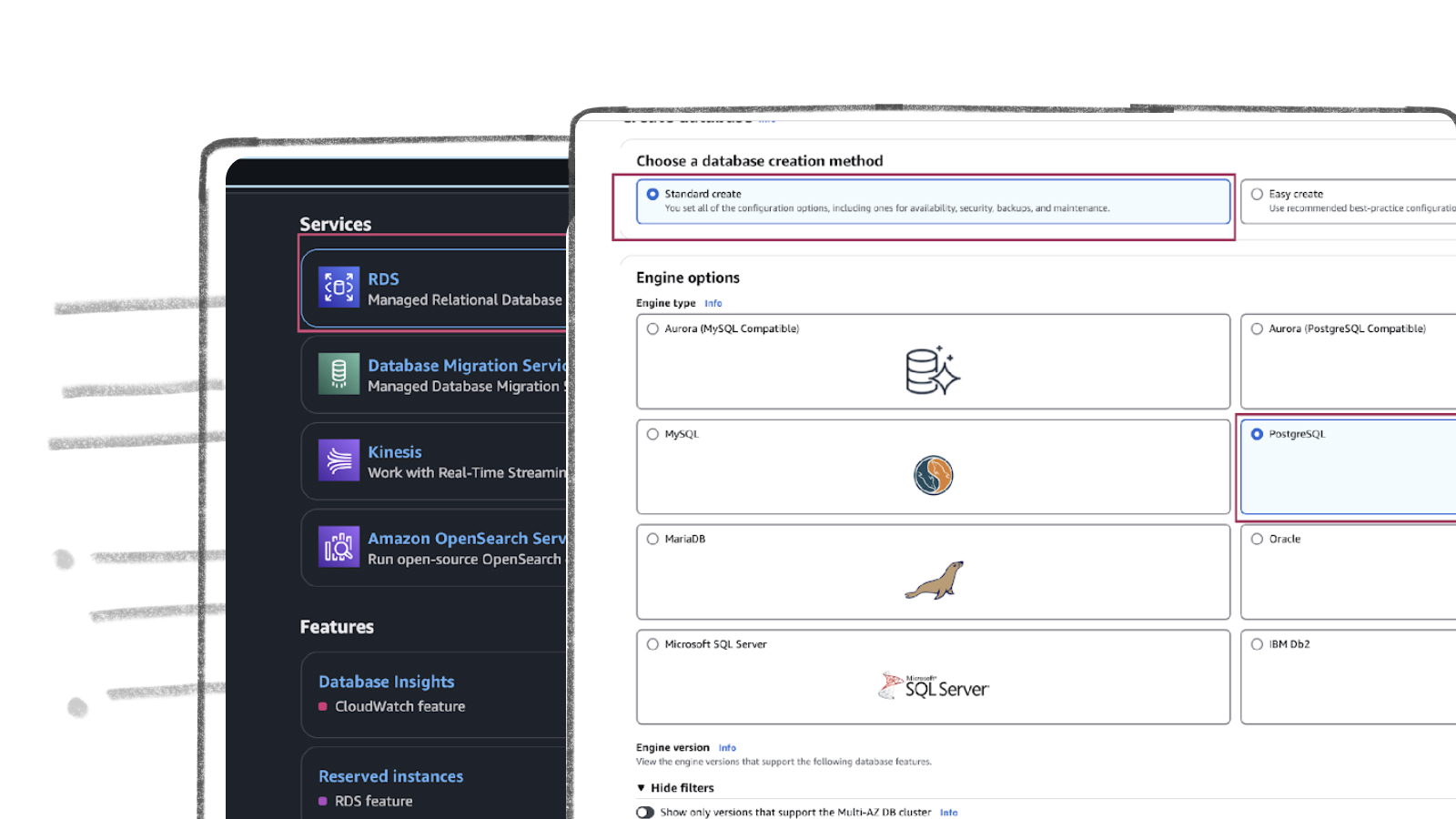
AWS RDS PostgreSQL Set Up
AWS RDS PostgreSQL stands out as one of the most widely used production databases. Its global adoption and everyday usage have prompted Amazon to make it exceptionally user-friendly. New users can set up an RDS PostgreSQL instance from scratch in just a few minutes.
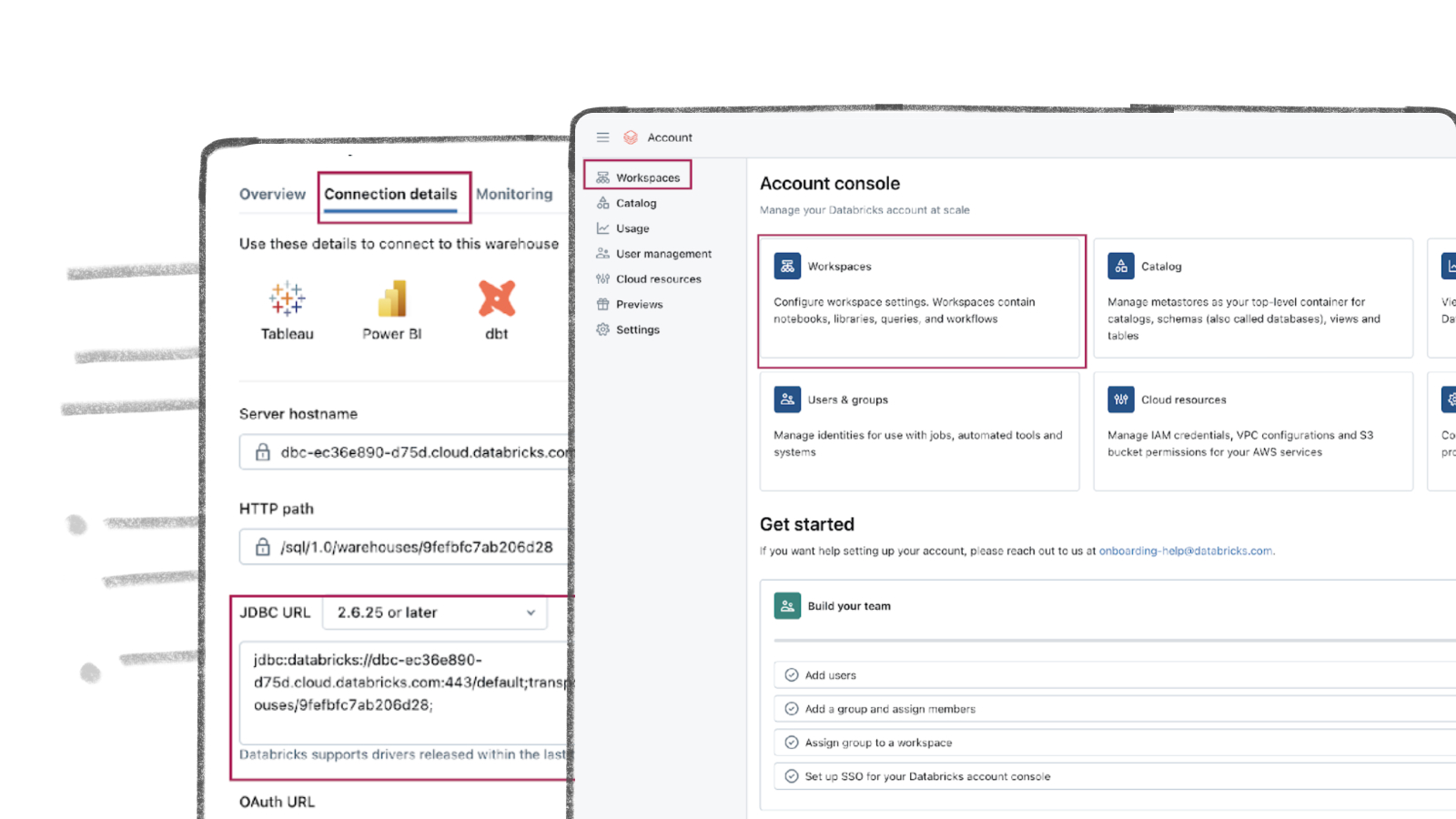
Databricks Warehouse Set Up
Getting started with Databricks is a breeze, regardless of your experience level. This guide provides clear instructions on how to create a new account or use your existing credentials, ensuring a smooth and efficient streaming process.