MySQL CDC Multi-Tenant Architecture Guide


September 22, 2025
When you're running a modern multi-tenant SaaS application, old-school data replication just doesn't cut it. It quickly becomes a massive bottleneck for both performance and security. The real challenge is streaming isolated, real-time data for potentially thousands of tenants without grinding your entire system to a halt. This is precisely where Change Data Capture (CDC) comes in, providing the perfect balance of speed and security.
The Multi-Tenant CDC Performance Bottleneck
For any SaaS platform, a snappy, real-time user experience is table stakes. If your architecture is serving hundreds or thousands of tenants from a single, shared MySQL database, how you handle data movement can make or break your product. The traditional approach of running batch ETL jobs on a schedule is way too slow and clunky for the dynamic nature of a multi-tenant world.
These outdated methods trigger a cascade of issues. Think about a customer success platform where agents need to see support ticket updates the second they happen. A five-minute delay from a batch process means confused agents and unhappy customers. The fundamental problem is that batch processing treats all your data like one giant blob, making it nearly impossible to separate and prioritize data for a specific tenant.
Why Old Methods Create New Problems
The core tension in multi-tenant systems is the need for both data isolation and real-time synchronization. You have to ensure Tenant A never, ever sees Tenant B's data, but at the same time, their own dashboards and connected services need to be updated instantly.
Trying to hack this together with frequent, complex queries against your production database is a recipe for disaster. This strategy puts a crushing load on your primary MySQL server, slowing down application performance for everyone. It’s like trying to have a thousand different conversations in one room at the same time—pretty soon, it's just noise. This is where a modern mysql cdc multi-tenant strategy becomes absolutely essential.
The Real-World Impact of Data Lag
In a SaaS environment, slow or stale data isn't just a technical hiccup; it directly hits your bottom line. These aren't theoretical problems—I've seen them play out time and again:
- Tenant-Specific Dashboards: A B2B software company offers each client a custom analytics dashboard. If that data is even a few minutes old, your clients might make bad decisions based on outdated information, which completely erodes their trust in your platform.
- Microservice Synchronization: A fintech app uses microservices for billing, notifications, and compliance for each tenant. A delay in syncing transaction data from the main database to the billing service could lead to wrong invoices or, even worse, missed payments.
- Personalization Engines: An e-commerce platform personalizes the shopping experience for each of its merchant's customers. If user activity isn't streamed in real-time, the personalization engine can't react to what's happening now, leading to missed sales opportunities.

Key Takeaway: In a multi-tenant architecture, data latency isn't just a technical problem; it's a business problem. It directly affects user experience, operational efficiency, and customer trust.
CDC cuts through this mess by capturing row-level changes in your database as they occur, effectively turning your database into a real-time stream of events. This lets you replicate and filter data for each tenant individually without ever hammering your source database. The same concepts hold true for other databases too; you can see a similar approach in our guide to PostgreSQL CDC in a multi-tenant setup. This is how you build data pipelines that are truly scalable, responsive, and secure.
Choosing Your Multi-Tenant Schema for CDC
Before you even think about streaming data, you have to get your database architecture right. This is the foundation for your entire multi-tenant application, and your choice here will make or break your MySQL CDC multi-tenant pipeline. How you decide to separate tenant data directly impacts the complexity, performance, and future scalability of your entire Change Data Capture setup.
There are really three ways to slice this. Each approach has its own set of trade-offs, especially when you're trying to capture and route data changes in real time. If you pick the wrong one, you could be setting yourself up for a world of pain with tangled filtering logic, performance bottlenecks, and a constant stream of operational headaches.
Pattern 1: Separate Databases for Each Tenant
The most straightforward, locked-down approach is giving every single tenant their own database. This offers the strongest possible data privacy and isolation—Tenant A’s data never even sees Tenant B’s at the database level.
For CDC, this looks simple on the surface. You just spin up a new CDC connector for each tenant's database. This makes routing a breeze because any change from a specific database obviously belongs to that one tenant. But this simplicity is deceptive and falls apart quickly as you grow. Imagine trying to manage CDC connectors for hundreds, or even thousands, of individual databases. It becomes an operational nightmare.
This is where you start seeing issues like replication lag creep in, as the system struggles under the weight of so many moving parts.
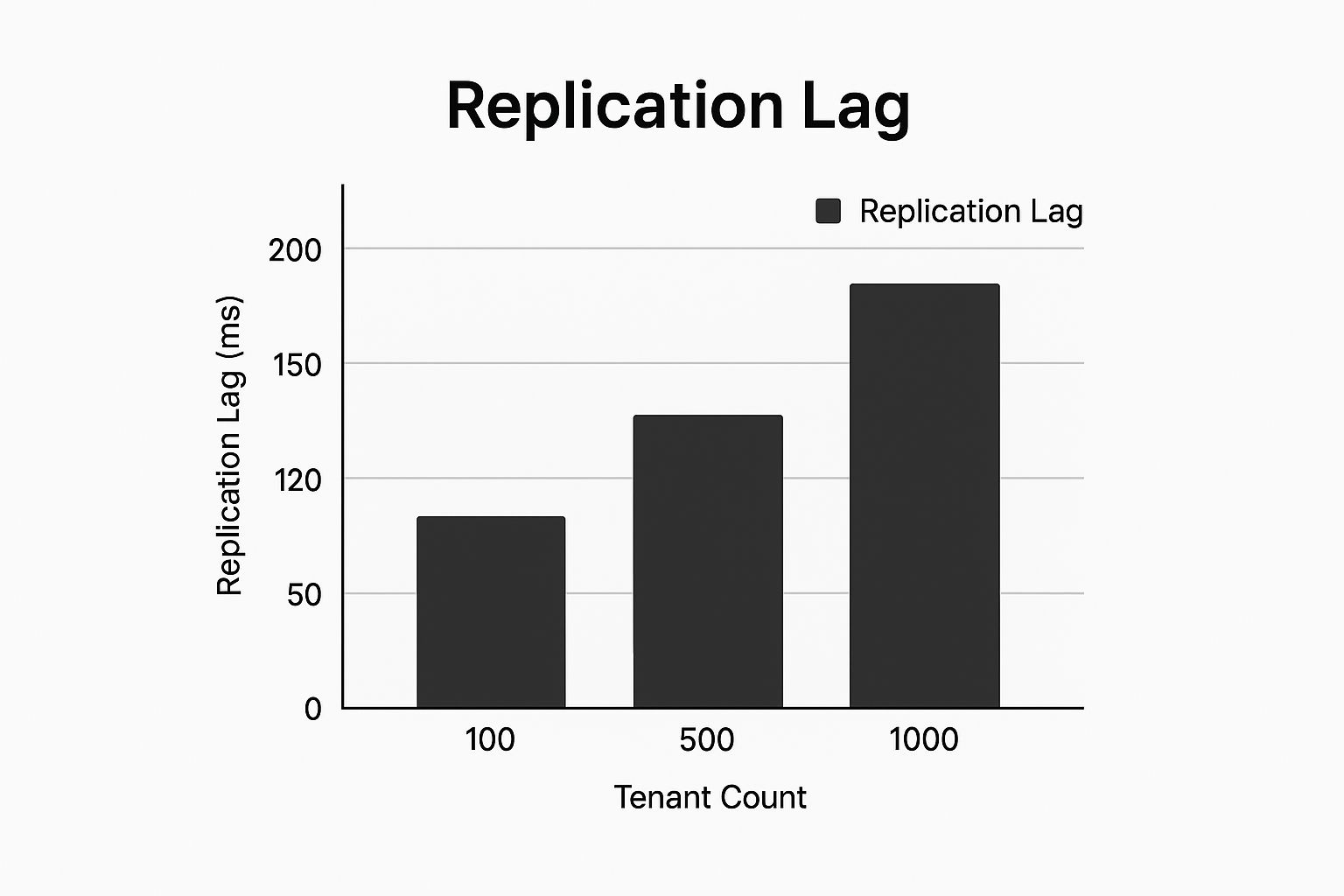
As you can see, as the tenant count skyrockets, the time it takes for data to replicate can lag significantly, which is a dealbreaker for most real-time applications.
Pattern 2: Shared Database with Separate Schemas
A popular middle-ground is using a single database instance but giving each tenant their own dedicated schema (a set of tables). Think of it as apartments in a single building—everyone's under one roof, but they have their own private space. This approach cuts down on infrastructure overhead compared to the separate database model while still giving you pretty solid logical isolation.
When you implement CDC here, you can often get away with a single connector monitoring the entire database. The real challenge shifts to routing the data correctly. Your pipeline needs to be smart enough to look at each change event, figure out which schema it came from, and send it to the right place.
A little tip from experience: You can configure your CDC platform's transformations to automatically pull the schema name from the event metadata. Use that as a routing key to send data to the correct tenant-specific topic in Kafka or a dedicated table in your data warehouse.
This model is a solid, balanced choice for a lot of SaaS applications. It gives you a good mix of isolation and manageability. Just be aware of the "noisy neighbor" problem—one super-active tenant could hog database resources and slow things down for everyone else.
Pattern 3: Shared Schema with a Tenant ID Column
The most common pattern, especially for large-scale applications, is the shared schema. All your tenants' data lives together in the same tables, distinguished only by a tenant_id column.
From a resource standpoint, this is incredibly efficient. You have fewer database objects and connections to manage. The massive growth in multi-tenant data centers—a market that shot past USD 56.10 billion in 2022 and is on track to hit USD 167.86 billion by 2032 with a 12.95% CAGR—is a testament to this shared-everything model.
But for CDC, this approach requires the most sophisticated logic. Every single change event—inserts, updates, deletes—must be correctly tagged with its tenant_id. Your streaming pipeline is now responsible for the mission-critical job of filtering and routing every event based on that ID. This is a crucial step covered in-depth in most guides on the fundamentals of Change Data Capture for SQL. If your filtering isn't perfect, you risk catastrophic data leaks between tenants.
Comparing Multi-Tenant Schema Designs for CDC
To help you decide, let's break down how these three patterns stack up when you're building a MySQL CDC pipeline. Each has a sweet spot depending on your specific needs for isolation, complexity, and scale.
Ultimately, choosing the right schema for your MySQL CDC multi-tenant pipeline is a balancing act between isolation and scalability. While the shared schema with a tenant_id is often the most future-proof choice, it absolutely requires a smart, reliable data streaming platform to handle the crucial task of getting the right data to the right place, every single time.
Tuning MySQL for Peak CDC Performance
Your MySQL CDC multi-tenant pipeline is only as good as its source. A poorly configured MySQL server will absolutely torpedo your efforts, creating a domino effect of data loss, performance drag, and late-night operational fires. Getting the database settings right from the start is the bedrock of a reliable and fast Change Data Capture stream.
This isn't just a matter of tweaking a few lines in your my.cnf file. It's about fundamentally understanding how MySQL records changes and then making sure your CDC tool can tap into that stream efficiently and securely. For any serious CDC setup, applying essential database management best practices in your MySQL environment isn't optional; it's a requirement.
Activating the Binary Log
First things first: you absolutely must enable the binary log, or binlog. This is MySQL's own transaction log, meticulously recording every data-altering event—all the INSERT, UPDATE, and DELETE statements. If the binlog is off, CDC is a non-starter. There's simply no record of changes for any tool to capture.
You'll need to jump into your MySQL server configuration file and add a few key directives:
server_id: Every server needs a unique number, even if it's a standalone instance. This is non-negotiable for replication.log_bin: This sets the base name for your binlog files, likemysql-bin. MySQL then appends suffixes, creatingmysql-bin.000001,mysql-bin.000002, and so on.binlog_format: Set this toROW. Period.
A Word of Experience: The
ROWformat is absolutely critical for data integrity in CDC. The olderSTATEMENT-based logging just records the SQL query, which can be ambiguous.ROWformat, on the other hand, logs the actual changed data—the "before" and "after" image of the row. This gives you a complete, unambiguous picture of what happened, which is exactly what you need for accurate replication.
Why You Should Use GTID-Based Replication
In a multi-tenant world where things can and do go wrong, relying on the old-school method of tracking binlog file names and positions is asking for trouble. If your primary server fails, trying to manually reconnect a CDC stream is a painful, error-prone exercise. This is precisely the problem Global Transaction Identifiers (GTID) were designed to solve.
GTIDs give every single transaction a unique ID that's consistent across your entire replication setup. This brilliant little feature allows a CDC tool to track transactions automatically, making failovers and reconnections a smooth, hands-off process. To turn it on, just set gtid_mode=ON and enforce_gtid_consistency=ON in your configuration.
Lock Down Your CDC User Permissions
Your CDC tool needs its own dedicated MySQL user, and you should grant it only the permissions it absolutely needs to do its job. Giving it superuser privileges is a massive security hole, especially when you're dealing with isolated tenant data.
Here are the minimal permissions your CDC user needs:
REPLICATION SLAVE: This lets the user connect to the primary and request the stream of binlog events.REPLICATION CLIENT: This allows the user to run commands likeSHOW MASTER STATUSto figure out where in the binlog to start reading from.SELECT: Your CDC tool needs this to perform an initial snapshot of existing data before it begins streaming live changes.
Following this "least privilege" principle means your connector can read change data and run initial syncs without ever having the power to modify data or mess with your database schema. It's a simple, powerful way to protect your production environment.
Don't Let Your Binlogs Run Wild
If you're not careful, binlogs can grow relentlessly, eating up disk space and even slowing down write performance on your database. You have to put a sensible retention policy in place. The expire_logs_days setting (or binlog_expire_logs_seconds in MySQL 8.0+) is your friend here, as it automatically purges old binlog files.
Finding the right retention period is a balancing act. Too short, and your CDC connector might not be able to catch up after a long outage. Too long, and you're just wasting disk space. For most production systems, a retention policy of 3 to 7 days is a solid and safe place to start.
Building Your Multi-Tenant Pipeline with Streamkap
Now that you’ve tuned your MySQL instance, it’s time to bring your architecture to life. This is where we’ll build the actual mysql cdc multi-tenant pipeline, connecting your source database to its destinations and putting the logic in place to keep every tenant’s data completely separate. Using a platform like Streamkap really takes the sting out of this process, handling the heavy lifting of CDC so you can focus on the important stuff: configuration and data flow.
Let's walk through how to construct a solid, multi-tenant pipeline, from making that first connection to applying the critical transformations that guarantee data integrity and isolation.
Here’s a look at the Streamkap UI, which will be your command center for managing sources, destinations, and the pipelines that connect them.

This dashboard gives you a clean, centralized view of your entire data infrastructure, which is a lifesaver when you're monitoring and managing complex multi-tenant data flows.
Connecting to Your MySQL Source
First things first, you need to establish a secure connection to your MySQL database. This means giving Streamkap the necessary credentials—hostname, port, database name, and that dedicated CDC user you created earlier. It's incredibly important that this user has only the minimum required permissions (REPLICATION SLAVE, REPLICATION CLIENT, SELECT) to keep your security posture tight.
If you’re running on a cloud database like AWS RDS for MySQL, the process is pretty much the same. You'll just need to double-check that your security groups and network ACLs are configured to allow traffic from Streamkap's IPs. We've got a detailed guide that dives deep into these networking specifics right here: https://streamkap.com/blog/how-to-stream-data-from-aws-rds-mysql-using-streamkap
Once you’re connected, Streamkap runs a quick validation to make sure it can access the binary log and read the schema. This sets the stage for everything that comes next.
Configuring the CDC Connector for Multi-Tenancy
This is the make-or-break phase for your multi-tenant setup. The way you configure the connector will dictate exactly how data is captured, filtered, and ultimately routed. Your approach here is tied directly to the schema pattern you chose earlier.
- For Separate Schemas: This is straightforward. You can simply configure the connector to listen to all schemas in the database. The schema name itself naturally acts as the routing key for each tenant.
- For a Shared Schema with a Tenant ID: Things get a bit more nuanced here. You'll set the connector to capture changes from all the shared tables, like
usersororders. The real magic happens later, in the transformation layer, where you'll use thattenant_idcolumn to untangle the data stream.
This is also the point where you decide on your initial data load strategy. As you get started, reviewing some data migration best practices can help you sidestep common traps and ensure a much smoother launch.
Expert Tip: I always recommend starting small. Only include the absolute essential tables in your CDC configuration at first. You can always add more later without breaking the existing flow. This approach minimizes the initial load on your source database and keeps your pipeline lean and focused.
Implementing Transformations for Data Isolation
With a raw stream of changes now flowing, transformations are what you'll use to turn it into a clean, isolated, multi-tenant pipeline. Streamkap lets you apply Single Message Transforms (SMTs) to manipulate the data while it's in flight, long before it ever touches your destination.
For the shared schema pattern, the ExtractField transform is your best friend. You can use it to pull the tenant_id out of the record’s payload and pop it into the record’s key or a header. This effectively tags every single change event with its rightful owner.
Another powerful technique is to use a Router transform. This SMT can intelligently direct records to different destination topics or tables based on the value of a field—in our case, the tenant_id. This is how you achieve true physical isolation at the destination, whether you're sending data to Kafka, Snowflake, or BigQuery.
For instance, a change for tenant 123 can be automatically routed to a Kafka topic named tenant-123-orders or a Snowflake table called TENANT_123_ORDERS. This kind of dynamic routing is the cornerstone of a scalable and secure mysql cdc multi-tenant architecture.
Setting Up the Destination
Finally, you configure where all this processed data is going to land. You’ll connect Streamkap to your destination—say, a Snowflake data warehouse or a Kafka cluster. The platform handles the tedious work of schema creation and evolution for you, automatically creating new tables or topics based on the routing rules you defined.
This automated schema management is a huge time-saver. When a developer adds a new column to a source table, Streamkap detects the change and propagates it to all the corresponding destination tables without you having to lift a finger. This prevents pipeline failures and keeps data flowing smoothly. The demand for these kinds of automated, real-time capabilities is exactly why the ETL market is projected to skyrocket from $8.85 billion in 2025 to $18.60 billion by 2030. By following this blueprint, you're not just building a pipeline that works today—you're building one that's resilient and ready to grow with your business.
Scaling and Managing Your CDC Pipeline
Getting your mysql cdc multi-tenant pipeline up and running is a huge win, but the real work starts now. Day-to-day operations are where the rubber meets the road. This isn't a "set it and forget it" system; keeping your data flowing reliably requires a proactive approach to monitoring, maintenance, and planning for growth.
Think of it as the difference between building a car and being its full-time mechanic and driver. To keep it running at peak performance, you need to know what's happening under the hood, from tracking latency for each tenant to handling the inevitable schema changes that developers will throw your way.
Monitoring What Actually Matters
Effective monitoring isn’t just about getting a green light that the pipeline is "on." In a multi-tenant world, you need a much finer-grained view to spot trouble before it snowballs and affects your customers. A blind spot for one tenant can quickly become a performance nightmare for everyone.
Here's where I'd focus my dashboard:
- End-to-End Latency: This is your north star metric. How long does it take for a change committed in MySQL to show up in the destination? If you see a sudden spike for a single tenant, you might have a "noisy neighbor" on your hands or an issue with their specific workload.
- Source Database Load: Keep a close watch on the replication slot lag and the growth rate of your MySQL binary logs. If that lag is constantly creeping up, it's a huge red flag that your CDC connector is falling behind the write volume.
- Resource Consumption: You have to know how much CPU and memory your CDC components are eating up. This data is crucial for scaling your infrastructure before it hits a wall and becomes a bottleneck.
Setting Up Meaningful Alerts
Alerts are your first line of defense, but we’ve all been burned by alert fatigue. The goal is to create alerts that are so specific and actionable that you know exactly where to look when one fires. A generic "pipeline stalled" message at 3 AM is next to useless.
Instead, let’s get targeted.
- High Latency Thresholds: Don't use a one-size-fits-all threshold. Set dynamic alerts that fire if any single tenant's end-to-end latency blows past your SLO—for example, anything > 5 minutes.
- Schema Change Detection: Get an immediate notification for any DDL statement that comes through the binlog. This gives you a crucial heads-up to verify that an
ALTER TABLEstatement propagated correctly to all the right places. - Connector Failures: This one's a no-brainer. An alert should fire the instant a connector enters a failed state. It's often the first symptom of a misconfiguration or a network issue between your systems.
My Pro Tip: Don't just alert on complete failures. You can get ahead of problems by alerting on the conditions that lead to them. Monitoring the rate of change in your replication lag can warn you of an impending disaster long before the pipeline actually breaks.
Handling Schema Evolution Gracefully
Let's be realistic: database schemas are not static. Developers are always adding columns, changing data types, and creating new tables. A resilient mysql cdc multi-tenant pipeline has to roll with these punches without needing downtime or a frantic call to the on-call engineer.
This is where a platform like Streamkap really shines. It's designed to automatically detect schema drift right from the MySQL source. When it sees an ALTER TABLE statement, it can propagate that change to the destination tables for every single tenant, all without missing a beat. This kind of automation is what separates a brittle pipeline from a truly robust one.
Onboarding and Offboarding Tenants
As your user base grows, you’ll be bringing new tenants online all the time. This process has to be smooth and automated. Manually configuring the pipeline for every new customer is a recipe for mistakes and delays.
Ideally, your application's tenant provisioning process should trigger an API call that automatically updates your CDC configuration, adding the new tenant's schema or tenant_id to the data stream's scope.
The same goes for offboarding. When a customer leaves, you need a clean, scripted process to remove their data from the destination and stop streaming their changes. This isn't just about good housekeeping; it's a fundamental part of meeting your contractual and compliance obligations.
Enforcing Security at the Destination
Finally, let's talk about the last line of defense: security. While the pipeline is in charge of routing the right data to the right place, your destination system is where you lock it all down. You have to ensure that each tenant's data lands in a sandboxed table, schema, or project that is completely inaccessible to anyone else.
This is where you implement strict role-based access control (RBAC) in your data warehouse. It’s your safety net. In the extremely unlikely event that a bug in your pipeline’s routing logic were to misdirect a piece of data, the database's own security model would be the final backstop preventing a data leak.
Common Questions on Multi-Tenant MySQL CDC
When you're in the trenches architecting a MySQL CDC multi-tenant pipeline, you’ll naturally run into some tricky questions. Getting the details right on performance, security, and day-to-day operations is what separates a smooth, scalable system from a constant headache. Let's walk through some of the most common challenges I've seen engineers tackle.

How Do You Handle Large Backfills for a New Tenant?
Onboarding a new tenant is a big moment, but it often kicks off with a massive data synchronization—the backfill. Trying to snapshot a huge amount of data while live changes are streaming for your other tenants is a delicate dance. You absolutely have to avoid overwhelming your primary MySQL database and slowing things down for everyone.
The common-sense approach is to schedule these big data loads during off-peak hours if you can. But even better, a modern CDC platform should handle this for you. A good system will perform the initial snapshot and then, without missing a beat, switch over to streaming changes directly from the binary log. This ensures a complete data set without any gaps.
Can CDC Capture Schema Changes Automatically?
Yes, and honestly, this is where CDC really shines. A well-configured CDC setup isn't just watching for INSERT or UPDATE statements; it’s also reading the DDL statements like ALTER TABLE right from the MySQL binlog. So, as your application evolves and your developers change table structures, the pipeline sees those changes instantly.
Here's the key: a solid CDC platform doesn't just see the change—it acts on it. When a developer adds a new column in MySQL, the platform should automatically propagate that change to the destination. That means the new column gets created in the tenant's Snowflake or BigQuery table, preventing data loss and keeping your pipeline from breaking.
What Is the Performance Impact on the Source MySQL Database?
This is the question every DBA asks, and for good reason. The great thing about log-based CDC is how little impact it has compared to old-school, query-based methods. Instead of hammering your tables with constant queries to check for new data, the CDC connector is just passively reading the binary log that MySQL is already writing anyway.
The actual overhead is minimal and comes from a couple of places:
- Binary Log Storage: You’ll need some disk space for the binlog files. It's crucial to set a reasonable retention policy—something like 3-7 days is typical—to keep it from growing out of control.
- Network Bandwidth: The connector streams log data, but the footprint is generally light. It's still something to keep an eye on, of course.
All in all, the performance hit on your source database is usually negligible. We're often talking about less than 2-5% CPU overhead, which makes it a safe bet even for production systems under heavy load. The real thing to avoid is batch CDC, which polls logs periodically. That approach can force the database to hold onto older data and put it under serious stress.
How Do You Secure Data in a Multi-Tenant Pipeline?
Security has to be your top priority. The pipeline is responsible for maintaining strict data isolation from the moment data leaves the source until it lands at its destination. This takes a multi-layered approach.
First, always stick to the principle of least privilege for the database user the CDC tool connects with. It should only have the bare minimum permissions it needs to do its job: REPLICATION SLAVE, REPLICATION CLIENT, and SELECT for snapshots. Nothing more.
Next, the logic inside your pipeline is your main line of defense. The transformations that filter and route data based on the tenant_id or schema have to be bulletproof. One mistake here could send data to the wrong place.
Finally, access controls at the destination—your data warehouse—are your final backstop. Every tenant's data should land in a completely separate table or schema with permissions locked down tight. This ensures that even if a pipeline error were to happen, one tenant could never see another's data.
Ready to build a scalable and secure multi-tenant CDC pipeline without the operational overhead? Streamkap handles the complexities of real-time data movement, from automated schema evolution to dynamic tenant routing, so you can focus on building your application. Get started with Streamkap today.

Related blog posts
