A Guide to Managed Kafka Services


September 17, 2025
Think of Managed Kafka as getting all the power of Apache Kafka without any of the headaches. A third-party vendor builds, runs, and takes care of your entire Kafka infrastructure for you. This "as-a-service" approach lets your team tap into real-time data streaming without the massive operational lift of managing servers, patching software, or scrambling to fix things when they break.
What Is Managed Kafka and Why Does It Matter

Picture Apache Kafka as the central nervous system of your business—a powerful engine constantly moving massive streams of data between all your applications, databases, and analytics tools. Now, imagine you could hire a dedicated team of world-class engineers to build, monitor, and maintain that system around the clock. That, in a nutshell, is the promise of managed Kafka.
This model completely sidesteps the immense operational burden of doing it all yourself, which includes everything from tricky initial setups to late-night emergency calls. Before we get into the details, it helps to have a solid grasp of what Kafka is at its core: a distributed streaming platform. With a managed service, you’re simply handing off all that underlying complexity to the experts.
Solving the Operational Puzzle
The biggest problem managed Kafka solves is operational overhead. Running Kafka in-house requires deep, specialized expertise that’s not only hard to find but also expensive to hire. It’s a constant battle.
A self-managed setup puts your team on the hook for:
- Complex Setup and Configuration: Properly provisioning servers, configuring brokers, and setting up Zookeeper (or its replacement, KRaft) is a serious undertaking with a steep learning curve.
- Constant Monitoring and Alerting: You need 24/7 eyes on the system to catch performance bottlenecks, broker failures, or disk space issues before they bring everything down.
- Scalability Challenges: Need more capacity? Adding or removing it in a self-hosted cluster is a manual, high-stakes procedure that can easily lead to downtime if you get it wrong.
- Security and Compliance: Implementing encryption, managing access controls, and keeping everything patched to meet security standards is a never-ending job.
A managed solution hides all that complexity. It frees up your engineers to focus on building great applications that create business value, not on babysitting infrastructure. To dive deeper, check out our guide on what Kafka is and how it works at https://streamkap.com/blog/what-is-kafka-en.
The Rise of Kafka as a Service
The industry has clearly voted with its feet, embracing this service model wholeheartedly. Apache Kafka is now the gold standard for real-time data, with over 70% of Fortune 500 companies using it to power their data pipelines.
This massive adoption has been supercharged by the growth of managed services that offer incredible reliability, automatic scaling, and solid uptime guarantees. The numbers tell the story: the global managed Kafka service market is on track to hit $5.7 billion by 2025, a huge leap from $1.4 billion in 2021. It's not just a trend; it's a fundamental shift in how modern data architecture is built.
Comparing Self-Hosted vs Managed Kafka
Deciding whether to run your own Apache Kafka cluster or go with a managed service is a huge fork in the road for any engineering team. On the surface, it looks like a simple trade-off: do you want total control, or do you want convenience? But when you dig in, the choice gets a lot more complex, touching on everything from your budget and team expertise to your long-term strategic goals.
Going the self-hosted route gives you the keys to the kingdom. You can fine-tune every last configuration, hand-pick your hardware, and build an environment that's a perfect match for your needs. But that level of control comes with a heavy price—not just in money, but in engineering hours, late-night alerts, and a constant operational burden.
The True Cost of Ownership
The initial price tag for a few servers is just the tip of the iceberg when you're managing Kafka yourself. The real total cost of ownership (TCO) is a long list of expenses that often catch teams by surprise.
These "hidden" costs are where the budget really balloons:
- Specialized Talent: Kafka experts are rare, in high demand, and expensive. You need a dedicated team that lives and breathes distributed systems to build, maintain, and troubleshoot a cluster effectively.
- 24/7 On-Call Rotations: Your data streams don't clock out at 5 PM. That means someone on your team has to be on call, ready to jump on an alert at 3 AM. This is a fast track to burnout and pulls your best engineers away from building your actual product.
- Infrastructure and Tooling: It’s not just servers. You also have to pay for networking, storage, and a whole suite of software for monitoring, logging, and alerting just to keep the lights on.
- Downtime and Opportunity Cost: Every minute your cluster is down or lagging, you're losing data, delaying critical business insights, and potentially losing revenue.
In fact, some studies show that self-hosting Kafka can have a 40% higher TCO once you add up all the costs for people, hardware, and downtime. It's no surprise that a whopping 60% of companies who make the switch to a managed Kafka service say their main motivation wasn't just saving money, but reducing operational risk and getting products to market faster.
Speed and Reliability as a Service
A managed Kafka provider’s entire business is built around one thing: running Kafka reliably and efficiently at massive scale. They benefit from economies of scale and have a depth of specialized expertise that's almost impossible for a single company to match internally.
The real value of a managed service is focus. It frees your team from the Sisyphean task of managing infrastructure so they can become experts in using data to solve real business problems.
This is where you see the practical differences in uptime and the ability to scale.
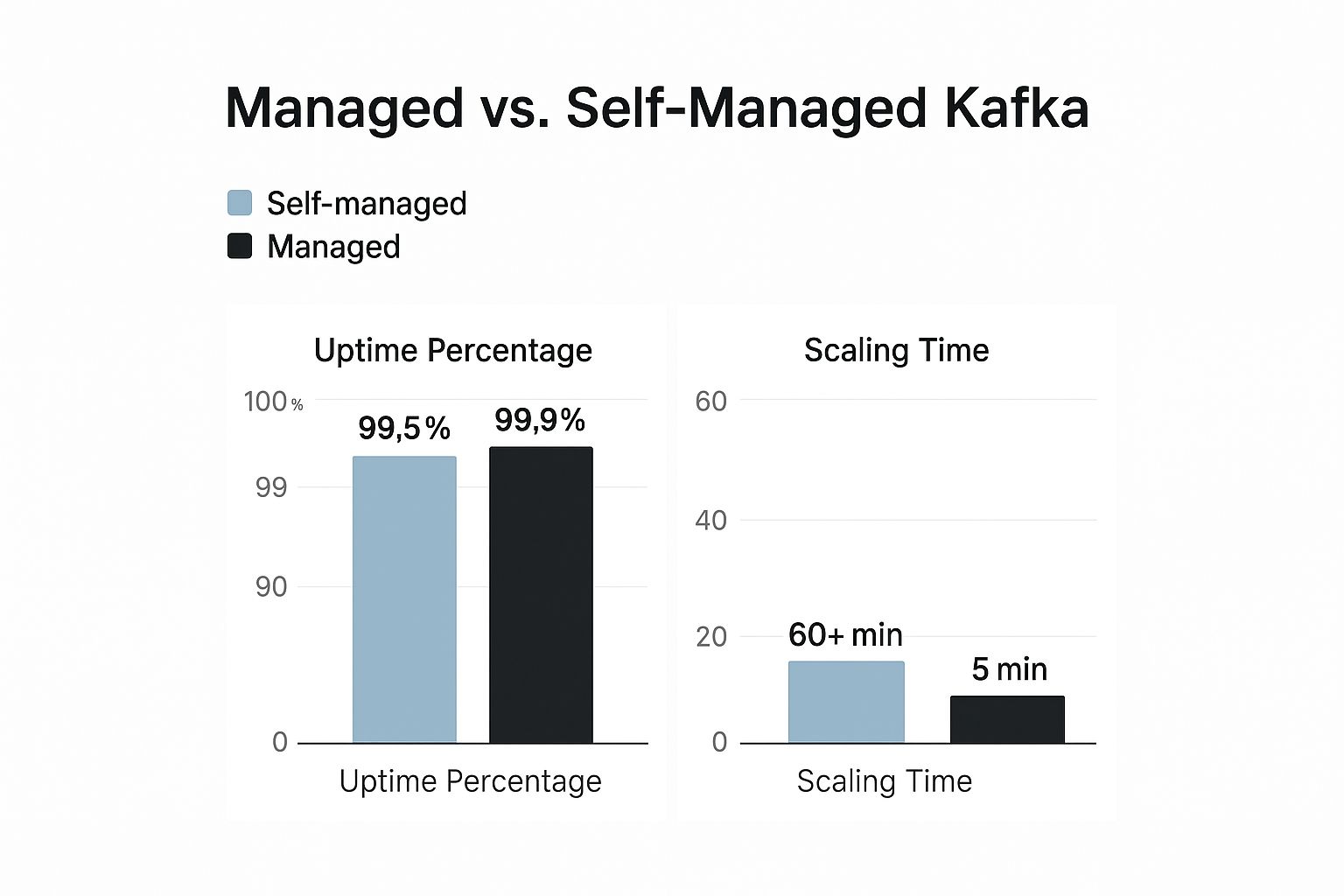
Managed services consistently deliver higher reliability and can adapt to new demands almost instantly. Trying to achieve that same agility with a self-hosted setup is a slow, difficult, and often risky process.
Self-Managed vs Managed Kafka Key Differences
To lay it all out, this table breaks down how the two approaches stack up across the factors that matter most to your team and your business.
Ultimately, the right choice really hinges on your company's priorities. If you have unique, non-standard requirements and a battle-hardened team of Kafka experts on standby, self-hosting could work. For most teams, however, a managed service offers a faster, more reliable, and ultimately more cost-effective way to get value from real-time data.
And if you're still weighing your options, you might find it useful to explore our guide on Kafka alternatives to improve data pipelines.
Understanding the Core Managed Kafka Architecture

To get a real feel for what a managed Kafka service does, it helps to peek under the hood, but let's skip the dense technical diagrams. A great way to think about it is like a massive, hyper-efficient automated warehouse for data. Your data messages are the packages, and the Kafka cluster is the entire logistics operation—sorting, storing, and delivering everything in near real-time.
In this warehouse, the brokers are the robotic floor managers. These are the actual servers that make up the cluster, and they have two main jobs: receive packages (data) from the delivery trucks (producers) and make them ready for pickup (by consumers). In a managed service, the provider's job is to make sure these robotic managers are always online, healthy, and working in perfect sync.
How Data Stays Organized
This warehouse isn't just one big open space; it's meticulously organized. That's where topics come in. A topic is essentially a dedicated aisle for a specific category of package, like user-clicks or order-confirmations. This simple act of categorization keeps different data streams neat and tidy, making it easy for your applications to find exactly what they need.
But the organization goes a step further. Inside each aisle, you have partitions, which you can think of as the individual shelves.
- Parallel Processing: Splitting an aisle (topic) into multiple shelves (partitions) lets different workers (consumer applications) grab packages from different shelves at the same time. This dramatically speeds up how quickly you can process everything.
- Scalability: When an aisle starts getting too much traffic, you can just add more shelves. A managed service handles this expansion for you without any downtime.
- Fault Tolerance: The provider also makes copies (replicas) of each shelf and stores them in different parts of the warehouse. If a shelf breaks, there’s an identical backup ready to go. No data is ever lost.
This relationship between brokers, topics, and partitions is the secret to Kafka's power. With a managed setup, the provider is the master architect of this entire system. They balance workloads, add capacity, and ensure everything is safely replicated. This frees you up to focus on the bigger picture, like how this data fits into the evolution from Lambda to Kappa architecture.
KRaft Protocol: A Major Engine Upgrade
For years, Kafka relied on a separate system called ZooKeeper to act as the warehouse's main office. It kept track of every robotic manager and what they were doing. It worked, but it was an extra piece to manage and a potential point of failure. The introduction of the KRaft protocol (short for Kafka Raft) completely changed the game.
KRaft essentially moves the main office's duties directly into the robotic managers themselves. They can now coordinate with each other, making the separate office obsolete.
This isn't just a small update; it’s a massive architectural improvement. Since Kafka 4.0 fully adopted KRaft, the real-world benefits have become clear. Cluster setup time has dropped from over 15 minutes to just a few minutes, and the hardware needed for a high-availability cluster has been cut by up to 20%.
Service providers have reported a 35% reduction in unplanned downtime and can onboard new customers 50% faster. You can dig into more details about these managed Kafka advancements on GitHub. This simplification is a huge reason why modern managed Kafka platforms are so incredibly stable and efficient.
Real-World Use Cases for Managed Kafka
The theory behind managed Kafka is great, but what does it actually do for a business? This is where the technology really comes to life. It’s not just about infrastructure; it's about building a nervous system for your company that lets you react to events the moment they happen.
By becoming the central hub for data in motion, managed Kafka unlocks capabilities that were once too complex or slow to be practical. Let's look at a few real-world scenarios where it makes a massive difference.
E-commerce Personalization and Inventory Management
Think about a major online retailer. Every click, every search, every item added to a cart is a signal. The challenge is to capture and act on this flood of signals instantly to give customers a great experience and keep the warehouse in sync. This is a perfect job for managed Kafka.
When a shopper adds a pair of sneakers to their cart, that action becomes an event fired into a Kafka topic. Immediately, several different parts of the business can listen in and react:
- The Inventory System: It sees the event and instantly puts a hold on that pair of sneakers, preventing someone else from buying the last one in stock. This simple step cuts down on overselling and disappointed customers.
- The Recommendation Engine: It consumes the same event, cross-references it with the shopper’s history, and suggests a matching hoodie on the very next page they visit. This kind of real-time personalization can boost the average order value by 5-15%.
- The Analytics Team: Their live dashboards update on the fly, showing which marketing campaigns are driving sales and which products are suddenly trending.
Without a high-speed pipeline like Kafka, these actions would happen in slow, clunky batches. Inventory would be out of date, recommendations would be generic, and business insights would be stale.
Instant Fraud Detection in Financial Services
In finance, speed is everything. A few seconds can be the difference between stopping a fraudulent purchase and a customer losing thousands of dollars. Banks and fintech companies have to analyze a dizzying number of transactions, checking them against risk models in the blink of an eye.
Managed Kafka acts as the high-speed backbone for this critical process.
- When a credit card is swiped, the transaction data is immediately published to a
transactionsKafka topic. - A stream processing application grabs that event the moment it arrives.
- The application quickly pulls in other relevant data—like the user's normal spending habits or recent location—from other data streams.
- All this enriched information is fed into a machine learning model, which calculates a fraud risk score in milliseconds.
- If the score is too high, the system can block the transaction before it even goes through.
This isn't just a minor improvement; it's a complete shift in capability. Companies that adopt this event-driven approach have reported cutting fraudulent transactions by as much as 70%, all while annoying fewer legitimate customers with false declines.
To get a deeper look at how this works in practice, this guide on real-time data ingestion with Kafka offers some great insights.
Predictive Maintenance in IoT and Manufacturing
Modern factories are packed with sensors streaming constant updates on equipment health, temperature, and vibration. This Internet of Things (IoT) data is incredibly valuable, but only if you can collect and analyze it at a massive scale. That’s where a managed Kafka platform comes in.
Imagine a manufacturer places vibration sensors on a critical assembly line machine. These sensors continuously stream data points to a central Kafka cluster. A stream processing engine listens to this data, looking for tiny changes in vibration patterns that might signal an impending failure.
The moment the system spots a pattern that deviates from the norm, it can automatically create a maintenance ticket and notify an engineer. This proactive approach lets the company fix the machine before it breaks down, saving a fortune in unplanned downtime and expensive emergency repairs. Shifting from reactive to predictive maintenance has been shown to boost operational efficiency by over 20%.
How to Choose the Right Managed Kafka Provider

Picking a vendor for your managed Kafka service can feel like a make-or-break decision, but you can simplify it by focusing on a few core criteria. The right partner isn't just hosting your cluster; they're becoming a central piece of your data infrastructure. Your job is to find one that lines up with your tech stack, your budget, and where you want your business to be in a few years.
To get past the flashy marketing claims, you need a solid evaluation framework. By methodically looking at each potential provider through the lens of pricing, performance, security, and deployment options, you can make a choice you won't regret. Let's break down the most important things to look for.
Evaluating Pricing and Performance
Let’s be honest, the first thing everyone looks at is the price tag. Most providers will offer one of two models, and the right one for you comes down to how your applications behave.
- Pay-as-you-go: This is a fantastic fit for workloads that are spiky or just plain unpredictable. You only pay for what you actually use, which gives you a ton of flexibility for development environments or apps with inconsistent traffic patterns.
- Provisioned Capacity: If you're running steady, high-volume workloads, this is almost always the more cost-effective route. You commit to a certain amount of capacity upfront, which usually gets you a much better rate than paying on demand.
But price is only half the story. You have to dig into performance. Don't get distracted by big throughput numbers on a landing page; you need to ask about latency guarantees, especially if your consumers are spread out across different regions. A crucial question is how they handle scaling. Can you add more capacity with a few clicks in minutes, or do you have to open a support ticket and wait? A provider's ability to scale on the fly is a dead giveaway of how mature their architecture really is.
Security, Compliance, and Ecosystem
When you're dealing with data, security is everything. A simple "we're secure" banner on a website just doesn't cut it. You need to look for hard proof of a serious security posture.
Start with certifications. Does the provider have key compliance reports like SOC 2 Type II or ISO 27001? These aren't just for show; they prove the company has passed rigorous third-party audits of their security controls. You should also get specifics on their encryption policies for data both in transit and at rest.
A rich connector ecosystem is a massive force multiplier. The more pre-built integrations a provider offers, the faster your team can connect data sources and sinks without writing custom code, drastically reducing development time.
This ecosystem of connectors is where a managed service really starts to shine. See if the provider has a deep library of fully managed connectors for the databases, warehouses, and apps you’re already using. Getting seamless integrations with tools like Snowflake or Google BigQuery out of the box can save you hundreds of engineering hours.
Deployment Models and Vendor Questions
Another critical fork in the road is the deployment model. Your choice here directly impacts your level of control, your costs, and what your team is ultimately responsible for.
- Fully-Managed: Here, the provider handles everything on their own cloud infrastructure. This is the simplest path, offering the quickest setup and the lowest operational headache for your team.
- Bring Your Own Cloud (BYOC): With this model, the provider deploys and manages the Kafka service inside your own cloud account (AWS, GCP, Azure). This gives you much more control over networking and ensures your data never leaves your security perimeter, which can be a game-changer for compliance.
To tie it all together, come prepared with a list of direct questions for any provider you're seriously considering. Getting clear, specific answers will tell you more about their service quality than any marketing brochure ever could.
Key Questions for Vendors:
- What are your exact uptime SLAs, and what are the penalties if you miss them?
- How do you manage Kafka version upgrades? Will we have to plan for downtime?
- Can you share your compliance reports and give me a detailed breakdown of your security measures?
- What level of technical support is included in the base plan, and what do the premium tiers offer?
- What tools do you give us to monitor cluster health, track performance, and keep an eye on costs?
Best Practices for Getting Kafka Right
Picking the right managed service is a huge first step, but how you design your Kafka implementation is what truly determines its success. A solid, efficient streaming system is about more than just spinning up a cluster. Following some battle-tested best practices will help you sidestep common traps, keep costs in check, and get your performance humming from day one.
Think of these not just as technical checkboxes, but as strategic decisions that will directly shape how your applications perform and scale down the road.
Nail Your Topic and Partition Strategy
The way you structure topics and partitions is the absolute bedrock of your Kafka architecture. A topic is like a dedicated logbook for a certain type of data (say, user_signups), while partitions are like adding more scribes to write in that logbook simultaneously. Getting this balance right is crucial for pushing through massive amounts of data without hitting a wall.
A classic mistake is creating a new topic for every little thing, which bogs down the brokers with unnecessary overhead. A smarter approach is to use a single topic for related events, using a key to differentiate them. When it comes to partitioning, the name of the game is spreading the workload evenly.
- More Partitions = More Parallel Power: Adding partitions to a topic lets you add more consumers from the same group to read at the same time. It's a direct way to ramp up your processing speed.
- Ordering is Key (Literally): Don't forget, Kafka only promises that messages will be in order within a single partition. If you need a strict sequence for a set of events—like all updates for a single customer—you have to make sure they all go to the same partition. You do this by using a consistent key, such as the
customer_id.
A great rule of thumb is to start with a conservative number of partitions and keep an eye on consumer lag. You can always add more partitions later, but you can never, ever take them away from a topic.
Use a Schema Registry to Avoid Data Chaos
As your system grows, so does the chance of your data pipelines descending into chaos. All it takes is one producer adding a new field or changing a data type to break every downstream consumer that wasn't ready for the change. This is where a Schema Registry comes in—it’s like a centralized constitution for your data.
It enforces a contract for what your data should look like, ensuring anything written to a topic follows a predefined structure. This simple practice is a game-changer for data quality and pipeline stability. If a producer tries to send a message with an invalid schema, the registry stops it in its tracks, shielding all your applications from bad data. It makes your whole system more predictable and a lot easier to manage.
Make Security a Day-One Priority
Even though your managed provider is handling the heavy lifting on infrastructure security, you're still the one responsible for protecting your data and who can access it. Security can't be an afterthought you bolt on later; it needs to be baked into your design from the very beginning.
Here are the non-negotiables for locking down your cluster:
- Encrypt Everything, Everywhere: Flip the switch on TLS/SSL to encrypt data in transit. This scrambles the information flowing between your apps and the Kafka cluster, making it useless to any network eavesdroppers. You should also make sure your provider encrypts the data while it’s sitting on the disk (encryption at rest).
- Control Who Gets In: Use strong authentication, like SASL, to make sure every client connecting to your cluster is exactly who they say they are.
- Follow the Principle of Least Privilege: Get granular with your permissions using Access Control Lists (ACLs). An application should only have the exact permissions it needs to do its job. For instance, a producer should only have
WRITEaccess to its specific topic—noREADpermissions, and certainly noADMINrights. This dramatically shrinks your attack surface and limits the blast radius if a client ever gets compromised.
Got Questions About Managed Kafka? We've Got Answers.
Even when the benefits seem clear, it's natural to have a few practical questions before diving into a managed Kafka service. Let's tackle some of the most common ones we hear from teams who are on the fence.
What's Really the Difference Between Kafka and a Managed Service?
Think of it this way: Apache Kafka is the high-performance engine, while a managed Kafka service is the entire car, complete with a professional driver and pit crew. The provider gives you the fully assembled, ready-to-use platform and handles all the behind-the-scenes work—the infrastructure, maintenance, scaling, and security—so you can just focus on building your applications.
Can We Move Our Existing Self-Hosted Cluster?
Absolutely. Migrating an existing Kafka setup is a well-trodden path. Leading managed providers have dedicated tools and support teams to make this happen smoothly.
The typical process involves setting up your new managed cluster and then using a replication tool, like MirrorMaker 2, to sync data from your old cluster to the new one. This ensures you can cut over with little to no downtime.
A word of advice from experience: a smooth migration is all about the prep work. Sit down with your provider beforehand to map out everything—topic configurations, security rules, and the final switch-over plan. That's how you avoid unwelcome surprises.
Is Managed Kafka Secure Enough for Our Sensitive Data?
For most companies, a good managed Kafka provider delivers a security setup that’s actually stronger than what they could build and maintain themselves. Security isn't an afterthought; it's a core feature.
Here's what you should expect right out of the box:
- Total Encryption: Your data is protected with TLS/SSL while it's moving between systems and encrypted again when it's stored on disk.
- Airtight Access Control: With robust authentication and authorization (like SASL and ACLs), you have fine-grained control over which applications can read from or write to specific topics.
- Compliance Ready: Top providers hold certifications for major standards like SOC 2, ISO 27001, and HIPAA, which is a non-negotiable for anyone in a regulated industry.
Ready to build real-time data pipelines without the operational headaches? Streamkap uses Change Data Capture (CDC) to stream data changes from your databases to your warehouse in real-time, all built on a fully managed, high-performance architecture. Discover the difference at Streamkap.

Related blog posts
