Streaming Database Replication
Database Replication
Power agents and applications with streaming CDC and event data from databases, applications, and more.
Trusted by teams at
USE CASES
Where Milliseconds Matter
Real-Time Analytics
Dashboards and alerts powered by live data. Spot trends as they emerge.
Explore Analytics- Event-to-Action
- <50ms
- Connectors
- 60+
- Uptime SLA
- 99.99%
- Lower Cost at Scale
- 14x
WHY STREAMKAP
Stream data to apps, warehouses, and agents
The developer platform for real-time data — from source to action in under 50ms.
Real-time
Sub-50ms event-to-action. CDC streams changes to agents, apps, and warehouses as they happen.
Developer-first
SQL, Python, and JS transforms. 60+ connectors. CLI, API, and MCP. Set up pipelines in minutes.
Zero ops
Managed Kafka and Flink. No clusters to provision, no tuning, no on-call. 14x lower cost at scale.
Deploy anywhere: SaaS • BYOC • Snowflake Marketplace
Book a DemoPLATFORM OVERVIEW
One platform from source to action
Databases
Events & Files
Deployment Options
Agents
Destinations
AI AGENTS
Why do agents choose Streamkap?
Context-aware agents make better decisions. Streamkap streams every change to your agents as it happens — in under 50ms.
Your Sources
Transform, enrich, filter, join
Your Agents
Event-driven context
Agents receive database changes the moment they happen. Always-on context, always current.
Enriched, not raw
Stream processing transforms, filters, joins, and masks data across sources before it reaches your agent.
Connect however agents work
MCP Server for Claude and Cursor. CLI for pipelines. REST API for custom integrations. One platform, every interface.
Always on, never behind
Streaming agents listen continuously. No missed events, no processing gaps, no batch windows to wait for.
DEVELOPER TOOLS
Connect in minutes
MCP Server, CLI, Terraform, and REST API included on every plan.
Works with Claude Code, Cursor, Windsurf, and Claude Desktop. Claude Code example:
claude mcp add --transport http \
--header "X-Streamkap-Client-ID: $ID" \
--header "X-Streamkap-Client-Secret: $SECRET" \
streamkap https://mcp.streamkap.com/mcpInstall, authenticate, and verify your setup:
npm install -g @streamkap/tools
export STREAMKAP_CLIENT_ID=...
export STREAMKAP_SECRET=...
streamkap doctorManage pipelines as code with the Streamkap provider:
provider "streamkap" {
client_id = var.client_id
secret = var.secret
}Exchange client credentials for a token, then call any endpoint:
curl -X POST https://api.streamkap.com/auth/access-token \
-d '{"client_id":"$ID","secret":"$SECRET"}'
curl https://api.streamkap.com/topics/details \
-H "Authorization: Bearer $TOKEN"Trusted by teams powering real-time applications at scale
SpotOn case study
Realtime
Sub-second latency
14x Lower Cost at Scale
Lower total cost of ownership

TESTIMONIALS
Why our customers love Streamkap
Great technology and a great team
Streamkap was 4x faster and had 3x lower total cost of ownership than our previous solution
Marcin Migda
Staff Data Engineer
Streamkap provides that speed at a cheaper cost, and combined with the other tools, we can build and raise the sophistication of the work that we can deliver. Without Streamkap, that was very difficult. That's really what it comes down to.
Dai Renshaw
Head of Data
Streamkap is a big part of our stack now because these data products that we're releasing heavily rely on the data that Streamkap is producing to Snowflake. If there's ever any issues, Streamkap can recover itself. Compared to our old tool, if one small thing happened, it would just completely break. On top of that, the cost that we have in Snowflake now for loading data on Streamkap is like next to nothing.
John Michael Mizerany
Senior Software Engineer
The old pipeline had a lot of overhead. Our old data pipeline was not running in near real-time and was very limited in scope. As I got to know the Streamkap platform, I decided — we should implement it, full steam ahead. From that set-up and configuration perspective, I don't even think we spent even a day. Then we did a cost-benefit analysis, and cost-wise, it was just a no-brainer to move to Streamkap.
Vikram Chauhan
Head of Data Engineering
The migration to Streamkap has resulted in clear and predictable billing, reducing unexpected costs. Success metrics include a 54% reduction in data-related costs. GCP Datastream lacked reliable support channels for issue resolution, but Streamkap provides prompt assistance through Slack, making it easy to consult and resolve problems quickly.
Kohei Hasegawa
CTO


Latest articles
CDC Cost Optimization for Streaming Destinations: Transparent Credit Math and Trade-Offs
Navigate per-row vs micro-batch pricing models for Snowflake, BigQuery, and Redshift CDC sinks. Learn how to forecast streaming costs before adoption and avoid bill surprises.
Silent CDC Failures and Timeout Detection: Building Durable Alerting
Most CDC pipelines alert on crashes but miss the slow failures that cost you most. Learn to detect latency creep early, recover from checkpoint without a full re-snapshot, and route alerts to the tools your on-call team already watches.
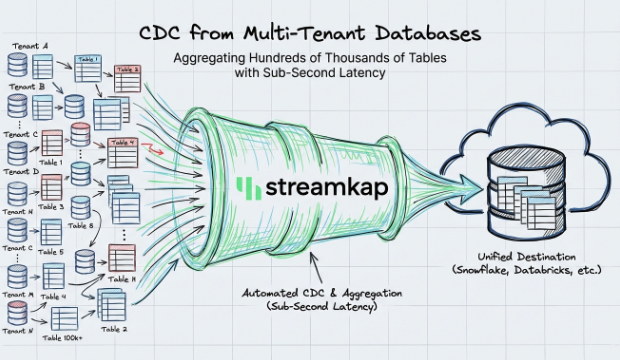
CDC from Multi-Tenant Databases with Sub-Second Latency
How Streamkap handles CDC at scale across multi-tenant databases with thousands of schemas, delivering sub-second latency without managing Kafka or Flink.