Resources & Guides
In-depth guides on change data capture, Kafka, Flink, data pipelines, and streaming architecture best practices.
All resources
Real-Time Data Streaming for Small Teams: How to Power AI Agents Without Enterprise Budgets
Learn how small teams and startups can build real-time AI agent data pipelines without enterprise budgets. Compare managed streaming costs vs DIY Kafka and batch ETL tools.
Data Infrastructure for Agentic AI: The 5 Layers Every Autonomous Application Needs
Discover the 5 essential data infrastructure layers that agentic AI applications need to make autonomous decisions with fresh, reliable data.
Sub-50ms Data Streaming for AI Agents: Benchmarks, Architecture, and Platform Comparison
Compare real-time data streaming platforms by latency performance for AI agent workloads. See how sub-50ms delivery changes agent decision quality and accuracy.
Managed CDC for LLM Applications: How to Feed Real-Time Data to Large Language Models
Learn how managed CDC services feed real-time data to LLM applications. Compare platforms for RAG pipelines, context freshness, and embedding generation workflows.
Real-Time AI Agents: What They Are, How They Work, and Why Streaming Data Changes Everything
The definitive guide to real-time AI agents. Learn what makes agents truly real-time, the architecture behind event-driven agent systems, and why streaming data is the foundation.
Real-Time Data Pipelines for AI Agents: Architecture, Patterns, and Implementation Guide
A practical guide to building real-time data pipelines that feed AI agents with fresh context. Covers architecture patterns, streaming transforms, and step-by-step implementation.
The Startup Guide to AI Agents: Ship Your First Real-Time Agent in a Weekend
A step-by-step guide for startup teams to build their first AI agent powered by real-time streaming data. Go from zero to a working agent in a weekend.
Streaming to Vector Databases: Comparing Managed Platforms for AI Teams
Compare managed streaming platforms for building real-time pipelines to vector databases. Covers Pinecone, Weaviate, Qdrant, and pgvector integration patterns.
Best CDC Platform for AI Workloads: What to Look For
Evaluating CDC platforms for AI and GenAI use cases? Compare Streamkap, Confluent, Estuary, Fivetran, Airbyte, AWS DMS, and Striim across latency, transforms, agent support, and cost.
Do AI Agents Need Kafka? When Managed Streaming Makes More Sense
AI agents need real-time event streams, but that doesn't mean you need to run Kafka yourself. Learn when self-managed Kafka makes sense for agent workloads and when a managed streaming platform is the better choice.
Fivetran vs Streaming CDC for AI Agents: Why Batch Sync Falls Short
A direct comparison of Fivetran's batch sync and streaming CDC for powering AI agents. Covers latency, data freshness, cost, MCP support, and the specific agent scenarios where the difference matters.
AI Agent Data Infrastructure: How to Build the Data Layer Autonomous Agents Need
A practical architecture guide to building data infrastructure for autonomous AI agents. Covers five infrastructure layers from source databases through CDC, stream processing, context stores, and agent interfaces.
Best Data Platforms for AI Agent Workflows: A Technical Comparison
Compare streaming CDC, batch ETL, warehouse-native AI, vector databases, and agent orchestration platforms for AI agent workflows. Scored on latency, freshness, MCP support, cost, and more.
How to Keep LLM Context Fresh with Live Data
Learn practical patterns for keeping LLM context fresh using streaming data. Covers RAG freshness, tool call responses, prompt injection, freshness SLAs, and monitoring.
Real-Time Data Pipelines for GenAI: How to Keep Generative AI Applications Current
Learn how to build real-time data pipelines that keep generative AI applications fed with fresh data. Covers streaming architectures for RAG, embeddings, prompt context, and LLM-powered applications.
Streaming Data to AI Models in Real-Time: Patterns and Architecture
A deep technical guide to the five main patterns for delivering streaming data to AI models during inference — from RAG context injection to cache-aside and direct event processing.
Best Data Replication Software in 2026: 10 Tools Compared
Compare 10 data replication software options — CDC-based, log-based, and trigger-based. Features, pricing, latency, and which fits your architecture.
Database Replication Patterns: Active-Active, CDC, and Beyond
A practical guide to database replication patterns — active-passive, active-active, CDC-based, snapshot, and multi-region. When to use each and common pitfalls.
ETL Workflow Automation: From Manual Scripts to Real-Time Pipelines
How to automate ETL workflows — orchestration tools, CDC-based streaming, error handling patterns, and the shift from batch scripts to continuous pipelines.
7 Oracle GoldenGate Alternatives for Real-Time Data Replication
Oracle GoldenGate is powerful but expensive and complex. Here are 7 alternatives for real-time replication — from open-source CDC to fully managed platforms.
How to Give Your AI Agent Real-Time Database Access
Step-by-step guide to connecting AI agents to live database data using CDC and MCP. Build agents that act on current state, not stale snapshots.
Real-Time vs Batch Data for AI Agents: Why Freshness Matters
AI agents built on batch data make confident but wrong decisions. Here's why data freshness is the single biggest factor in agent reliability.
SQL Server Change Data Capture: Step-by-Step Setup Guide
How to enable and configure CDC on SQL Server — T-SQL commands, capture jobs, cleanup, troubleshooting, and streaming changes to external systems.
Stream Processing Tools Compared: Flink, Kafka Streams, Spark, and More
Side-by-side comparison of 8 stream processing tools. Latency, throughput, state management, SQL support, and when to use each one.
What Is Real-Time Data? The Engineer's Guide to Sub-Second Pipelines
Everything you need to know about real-time data — what it is, how it works, CDC vs polling, architecture patterns, and how to build sub-second pipelines.
Context Graphs: The Next System of Record for AI Agents
Context graphs capture not just data, but the relationships and reasoning behind every decision. Learn why they're becoming essential infrastructure for autonomous AI agents.
Decision Traces: Building Audit Trails for Autonomous AI Agents
Decision traces record why AI agents made specific choices, creating accountable and auditable autonomous systems. Learn how streaming infrastructure makes decision tracing possible.
Apache Flink Agents: Event-Driven AI Agents with Streaming Guarantees
Flink Agents bring exactly-once consistency to AI agent orchestration. Learn how event-driven streaming agents differ from batch-oriented frameworks like LangChain and CrewAI.
Flink Agents vs LangChain vs CrewAI: Choosing an AI Agent Framework
Compare event-driven Flink Agents with request-response frameworks like LangChain and CrewAI. Understand the trade-offs between streaming and batch agent orchestration.
Managed Flink Agents: Run AI Agents Without the Infrastructure Burden
Self-managing Flink Agents means operating Flink clusters, managing checkpoints, scaling resources, and debugging failures. A managed platform handles all of this so you can focus on agent logic.
Real-Time Context Engines: Why Agents Need Streaming Data
Research shows real-time context improves agent prediction accuracy by 40% and reduces hallucinations by 40%. Learn how streaming context engines work and why batch data falls short.
Streamkap CLI: Manage Streaming Pipelines from the Command Line
The Streamkap CLI brings pipeline management to your terminal. Create connectors, monitor pipelines, and automate workflows without leaving the command line.
Introducing the Streamkap MCP Server: Connect AI Agents to Real-Time Data
The Streamkap MCP Server lets AI agents query pipeline status, monitor data flows, and interact with streaming infrastructure through the Model Context Protocol standard.
Systems of Decision: The Third Pillar of Enterprise Architecture
After systems of record and systems of engagement, enterprises need systems of decision to power autonomous AI agents. Learn what they are and how streaming data makes them work.
Why Data Warehouses Can't Power AI Agents
Data warehouses were built for analytical queries, not real-time agent context. Learn why Snowflake, BigQuery, and Databricks fall short and what agents actually need.
Agentic Data Streaming vs Traditional ETL: What Changes When Agents Are the Consumer
Traditional ETL was designed to load warehouses for analysts. Agentic data streaming is designed to feed real-time context to autonomous agents. Here's how they differ and why it matters.
Alternatives to AWS Bedrock AgentCore for Real-Time Data Streaming
Evaluating alternatives to AWS Bedrock AgentCore for streaming real-time data to AI agents. A comparison of approaches from managed CDC to full agent orchestration platforms.
How to Build a Real-Time AI Agent with Streaming Data
A practical tutorial for building an AI agent that acts on real-time database changes. From CDC setup to agent framework integration, step by step.
The Context Layer: What AI Agents Need Beyond Raw Data
Raw data isn't enough for AI agents. They need business context: what metrics mean, which tables to trust, how your company defines success. Here's what a context layer looks like and why it matters.
From Data Freshness to Context Freshness: The Next Wave of Real-Time Infrastructure
Wave 1 was fresh data (CDC to warehouses). Wave 2 is fresh context (streaming semantic layers for agents). Here's why context freshness is the next frontier and what it means for your data stack.
Decision Governance: How to Trust AI Agents That Make Thousands of Decisions per Hour
When AI agents move from experiments to production, the question shifts from capability to trust. Decision governance gives you the visibility and control to trust agent decisions at scale.
MCP and CDC: The Two Protocols AI Agents Need for Live Data
Model Context Protocol defines how agents ask for data. Change Data Capture defines how data stays fresh. Together, they give agents real-time access to your databases without hammering production systems.
The Real-Time Agent Stack: What Your AI Agents Actually Need
Building production AI agents requires more than a model and a prompt. Here's the data infrastructure stack that keeps agents accurate, fast, and governable.
Real-Time Decisioning: How Streaming Data Powers Instant Decisions
Real-time decisioning replaces batch-driven choices with instant, data-driven actions. Here's how streaming infrastructure makes it possible and why it matters for AI agents.
Scalable AI Data Streaming: Platforms and Vendors Compared
A practical comparison of platforms that support scalable AI data streaming, from managed CDC to full streaming platforms. What to look for and how the vendors stack up.
Streaming Semantic Layers: Why Batch Definitions Break AI Agents
Semantic layers were designed for BI tools and human analysts. When AI agents become the consumer, batch-updated definitions create a new class of failures. Here's why streaming semantic layers are the next evolution.
Streamkap vs Confluent for AI Agent Infrastructure
Comparing Streamkap and Confluent for powering AI agent data pipelines. How they differ on latency, cost, complexity, and agent-readiness.
What Is Agentic Data Streaming? The Category Gartner Says Will Define 2026
Agentic data streaming is the practice of streaming real-time data to AI agents so they can make decisions on current information. Here's what it means, why it matters, and how it works.
Why AI Agents Can't Use Batch Data
Batch ETL was built for humans looking at dashboards. AI agents that make thousands of decisions per hour need something fundamentally different. Here's why batch breaks down for agentic workloads.
Why Your AI Agents Keep Getting the Wrong Answer
Most AI agent failures aren't model problems. They're data problems. Agents fail because they lack context, freshness, or both. Here's what's actually going wrong and how to fix it.
Debezium PostgreSQL Replication Slot Issues: Causes and Fixes
Replication slot bloat is the most dangerous failure mode in Debezium CDC pipelines. Learn why slots grow, how to monitor them, and what to do when WAL files fill your disk.
Debezium Initial Snapshot: Strategies to Speed It Up
Debezium's initial snapshot can take hours or days on large databases. Learn about snapshot modes, performance bottlenecks, and practical strategies to get through the snapshot phase faster.
Kafka Consumer Lag: Causes, Debugging, and Fixes
Consumer lag is the most common Kafka operational issue. Learn what causes it, how to measure it, and practical strategies to bring it under control.
Kafka on Kubernetes: Real-World Lessons
Running Kafka on Kubernetes sounds like a good idea until you hit storage, networking, and operational challenges. Here's what teams learn the hard way and how to avoid the common pitfalls.
Backpressure in Stream Processing: What It Is and How to Handle It
Learn what backpressure means in streaming pipelines, how to detect it, and practical strategies for handling it in Kafka, Flink, and CDC pipelines without losing data.
Migrating from Batch to Streaming: A Practical Playbook
A step-by-step guide for teams moving from batch ETL to streaming pipelines - covering readiness assessment, parallel running, validation, and common pitfalls.
Best CDC Tools Compared: A 2026 Guide to Change Data Capture Platforms
A thorough comparison of the leading CDC tools in 2026 - Debezium, Fivetran, AWS DMS, Airbyte, Streamkap, Striim, and HVR/Qlik - evaluated on latency, deployment model, pricing, connector breadth, and stream processing.
CDC to Destination: Architecture Patterns for Every Target
A complete reference for CDC delivery architecture patterns - direct streaming, hub-and-spoke, and transform-in-flight - with destination-specific guidance for Snowflake, BigQuery, ClickHouse, and more.
Getting Started with CDC: Your First Real-Time Data Pipeline
A practical, beginner-friendly guide to change data capture (CDC). Learn what CDC is, how it works under the hood with WAL, binlog, and oplog, and how to build your first real-time data pipeline.
CDC Soft Deletes and Tombstones: Handling Deletions in Streaming Pipelines
Learn how to handle database deletions in CDC streaming pipelines. Implement soft deletes, tombstone records, and delete propagation for data warehouses and analytics.
CDC to Apache Iceberg: Building a Real-Time Lakehouse
Stream database changes to Apache Iceberg tables for a real-time lakehouse. Learn how CDC and Iceberg's row-level operations enable ACID-compliant data lake analytics.
CDC to ClickHouse: Sub-Second Analytics Pipeline
Stream database changes to ClickHouse for real-time analytics. Learn how to use CDC with ReplacingMergeTree, handle updates and deletes, and build sub-second dashboards.
CDC to Kafka: Building an Event Backbone from Database Changes
Use CDC to publish database changes as Kafka events, creating an event-driven backbone for microservices, analytics, and real-time applications without changing application code.
CDC to Redis: Real-Time Cache Invalidation and Sync
Use Change Data Capture to keep Redis caches perfectly in sync with your database. Eliminate stale cache problems, reduce read load, and build real-time cache layers.
CDC to Star Schema: Building Dimensional Models from Change Streams
How to transform CDC event streams into star schema dimensional models in real time. Covers fact table loading, dimension handling, and SCD patterns with Flink.
CDC vs ETL: Key Differences and When to Use Each
A clear, in-depth comparison of Change Data Capture and traditional Extract-Transform-Load. Understand how they differ architecturally, how they affect source system performance, which delivers fresher data, and real-world scenarios where one outperforms the other.
Change Log to Snapshot: Materializing CDC Streams into Current State
How to convert CDC change log streams into point-in-time snapshots representing the current state of your data. Covers compaction, upsert patterns, last-value-per-key semantics, and Flink deduplication.
Computed Columns in Streaming: Deriving New Fields On-the-Fly
Learn how to add computed columns to streaming data - derived fields, calculations, lookups, and business logic applied in real time as data flows through your pipeline.
CQRS and Stream Processing: Separating Reads and Writes at Scale
How to implement CQRS using CDC and stream processing. Build optimized read models from write-side changes in real time with Kafka and Flink.
Real-Time Currency Conversion in Streaming Data Pipelines
How to implement accurate currency conversion in real-time streaming pipelines. Covers temporal joins for point-in-time rates, rate source integration, and handling edge cases.
Data Completeness in Streaming: Detecting Missing Events
Learn how to detect missing events, gaps, and data loss in streaming pipelines. Build completeness checks that ensure every record from the source reaches the destination.
Data Contracts for Streaming: Defining Producer-Consumer Agreements
Learn how to implement data contracts in streaming architectures - formal agreements between data producers and consumers that prevent breaking changes and ensure data quality.
Real-Time Data Deduplication: Eliminating Duplicates in Streams
Learn how to detect and eliminate duplicate records in real-time streaming pipelines. Implement deduplication with Flink SQL, Kafka, and idempotent sinks.
Data Freshness Monitoring: How to Know Your Real-Time Pipeline Is Actually Real-Time
Learn how to monitor and measure data freshness in streaming pipelines. Build alerting for stale data, track end-to-end latency, and ensure your real-time data is truly real-time.
Data Lineage in Streaming Pipelines
How to track data from source to dashboard in streaming systems. Covers OpenLineage, Apache Flink lineage, end-to-end tracking patterns, and using lineage for debugging production data issues.
Data Masking in Streaming Pipelines: PII Protection in Real Time
Learn how to mask, hash, and redact PII in real-time streaming pipelines. Implement data masking for GDPR, HIPAA, and SOC 2 compliance without slowing down your data flow.
Data Observability for Streaming Pipelines: Metrics That Matter
Learn which metrics to monitor for streaming data pipeline health - throughput, latency, error rates, and data quality indicators that prevent outages and data corruption.
Data Partitioning Strategies for Streaming Pipelines
How to design partitioning strategies in streaming systems for downstream query performance. Covers Kafka topic partitioning, warehouse partitioning, partition key selection, repartitioning in Flink, and hot partition mitigation.
Data Quality in Streaming Pipelines: A Practical Framework
A practical framework for maintaining data quality in real-time streaming pipelines. Covers validation, schema enforcement, anomaly detection, dead letter queues, and monitoring.
Dead Letter Queues in Stream Processing: Handling Bad Data Gracefully
Learn how to use dead letter queues (DLQs) in streaming pipelines to handle malformed, invalid, or unprocessable records without stopping the entire pipeline.
Migrating from Self-Managed Debezium to Managed CDC
A practical guide for migrating from self-managed Debezium to a managed CDC service. Covers operational costs, migration planning, zero-downtime cutover, and feature comparison.
The True Cost of DIY CDC Infrastructure: Kafka + Debezium + Flink
Building your own CDC pipeline with Kafka, Debezium, and Flink sounds like the right engineering choice. Here's what it actually costs in infrastructure, staffing, and opportunity cost.
DynamoDB to Snowflake: Syncing NoSQL to Your Data Warehouse
Stream DynamoDB changes to Snowflake in real time using DynamoDB Streams and CDC. Learn how to handle document flattening, schema mapping, and keep analytics fresh.
Event Sourcing with CDC: Deriving Events from Database State
How CDC bridges the gap between traditional CRUD databases and event sourcing patterns. Learn to retrofit event streams onto existing systems without rewriting your application.
Exactly-Once vs At-Least-Once: Choosing Delivery Guarantees
A practical comparison of exactly-once and at-least-once processing guarantees in stream processing. When each one matters, how they work, and what they actually cost.
Fan-Out and Fan-In Patterns in Stream Processing
How to implement fan-out (one-to-many) and fan-in (many-to-one) patterns in streaming pipelines. Covers topic routing, parallel processing, and stream merging with Kafka and Flink.
Field Mapping and Renaming in Streaming Pipelines
Learn how to map, rename, and reorganize fields in real-time streaming data. Align source schemas with destination conventions, handle naming conflicts, and standardize column names.
Your First Flink Job: A Beginner's Tutorial
A hands-on tutorial for writing your first Apache Flink job. Covers local environment setup, Flink SQL basics, connecting to Kafka, and monitoring your running job.
Replacing Fivetran with Real-Time CDC: A Migration Guide
A practical guide for migrating from Fivetran's batch-based syncs to real-time streaming CDC. Covers latency differences, cost comparison, connector mapping, and step-by-step migration.
Flattening Nested JSON in Streaming Pipelines
Learn how to flatten deeply nested JSON structures in real-time streaming pipelines. Handle arrays, nested objects, and mixed schemas for analytics-ready output.
Anomaly Detection in Streaming Data with Flink
How to detect anomalies in real-time data streams using Apache Flink. Covers statistical methods, windowed baselines, z-score detection, and integration with ML models.
Flink Checkpointing Explained: How Fault Tolerance Actually Works
Understand how Flink checkpointing provides fault tolerance and exactly-once semantics. Learn checkpoint internals, configuration, troubleshooting, and production tuning.
Clickstream Analytics with Flink: Real-Time User Behavior Tracking
Learn how to build real-time clickstream analytics with Apache Flink. Covers sessionization, funnel analysis, page-view aggregations, and powering live dashboards.
Building a Real-Time Customer 360 View with CDC and Apache Flink
Learn how to build a continuously updated Customer 360 profile using change data capture and Apache Flink. Covers multi-source CDC, identity resolution, profile aggregation, serving the unified view, and keeping it fresh.
Flink Exactly-Once Semantics: How It Works End-to-End
Understand how Flink achieves exactly-once processing end-to-end - from source to sink. Learn the two-phase commit protocol, checkpoint coordination, and sink requirements.
Processing Financial Market Data in Real Time with Apache Flink
Learn how to build a real-time financial market data pipeline with Apache Flink. Covers tick data ingestion, VWAP calculation, moving averages, order book aggregation, and latency requirements.
Real-Time Fraud Detection with Apache Flink
How to build a real-time fraud detection system using Apache Flink. Covers rule-based detection, windowed aggregations, pattern matching, and ML model scoring.
IoT Sensor Data Processing with Apache Flink
Learn how to process IoT sensor data with Apache Flink. Covers high-throughput ingestion, out-of-order event handling, downsampling, threshold alerting, and edge vs cloud processing patterns.
Flink Job Monitoring: Key Metrics and Alerting Strategies
Learn which Flink metrics to monitor in production - throughput, latency, checkpoints, state size, and backpressure. Build dashboards and alerts that catch issues before they become outages.
Real-Time Log Analytics with Flink: From Raw Logs to Insights
Learn how to build real-time log analytics with Apache Flink. Covers log parsing, structured extraction, error rate monitoring, log-level aggregations, and alerting pipelines.
Flink Memory Tuning: Preventing OutOfMemoryErrors in Production
Learn how to configure Flink memory to prevent OutOfMemoryErrors. Understand the Flink memory model, tune heap and off-heap settings, and diagnose memory issues in production.
Building a Real-Time Notification Engine with Stream Processing
Learn how to build a real-time notification engine using Apache Flink. Covers event-driven notifications, deduplication, rate limiting, multi-channel delivery, and user preference filtering.
Flink Parallelism and Scaling: Right-Sizing Your Stream Processing
Learn how to set and tune Flink parallelism for optimal throughput. Understand task slots, operator chaining, key groups, and scaling strategies for production workloads.
Running Flink in Production: The Operations Guide
A complete guide to operating Apache Flink in production. Covers checkpointing, state backends, memory tuning, parallelism, monitoring, deployment models, and upgrade strategies.
Building a Real-Time Recommendation Engine with Apache Flink
Learn how to build a real-time recommendation engine using Apache Flink. Covers collaborative filtering on streams, feature computation, session-based recommendations, and writing to serving stores.
Flink Savepoints vs Checkpoints: When to Use Each
Understand the difference between Flink savepoints and checkpoints. Learn when to use each for upgrades, migrations, scaling, and disaster recovery in production.
Real-Time Aggregations in Flink SQL: COUNT, SUM, AVG Over Streams
Learn how to compute real-time aggregations in Flink SQL - windowed and non-windowed COUNT, SUM, AVG, MIN, MAX over streaming data with practical examples.
Flink SQL CDC Connectors: Reading Database Changes with SQL
Learn how to read real-time database changes in Flink SQL using CDC connectors for PostgreSQL, MySQL, MongoDB, and more. Build streaming pipelines from database changelogs.
Flink SQL Cookbook: 20 Ready-to-Use Query Patterns
A practical cookbook of 20 Flink SQL query patterns for common stream processing tasks - filtering, aggregations, joins, deduplication, Top-N, and more. Copy, adapt, and deploy.
Debugging Flink SQL Jobs: Common Errors and How to Fix Them
A practical troubleshooting guide for Flink SQL - common error messages, their root causes, and step-by-step fixes for type mismatches, state issues, watermark problems, and more.
Flink SQL: The Complete Guide to Stream Processing with SQL
Master Flink SQL for real-time stream processing. Learn dynamic tables, continuous queries, window functions, joins, and deployment patterns with practical examples.
Flink SQL Joins: Regular, Temporal, and Lookup Joins Explained
Learn every join type in Flink SQL - regular joins, interval joins, temporal joins, and lookup joins. Understand when to use each with practical streaming examples.
Flink SQL MATCH_RECOGNIZE: Complex Event Processing with SQL
Learn how to detect complex event patterns in streaming data using Flink SQL's MATCH_RECOGNIZE clause. Build fraud detection, anomaly detection, and sequence matching with SQL.
Flink SQL Session Windows: Detecting User Activity Patterns
Learn how session windows in Flink SQL group events by periods of activity separated by gaps. Build user session analytics, timeout detection, and engagement tracking.
Flink SQL Sliding (Hop) Windows: When and How to Use Them
Master sliding windows in Flink SQL for overlapping time-based aggregations. Learn syntax, use cases, and performance tuning with real-world streaming examples.
Flink SQL Tumbling Windows Explained with Examples
Learn how tumbling windows work in Flink SQL for fixed-interval stream aggregations. Practical examples for counting, summing, and grouping events over time.
Flink SQL User-Defined Functions (UDFs): Extending SQL with Custom Logic
Learn how to create and use User-Defined Functions in Flink SQL - scalar functions, table functions, and aggregate functions for custom stream processing logic.
Flink SQL vs ksqlDB: Which Stream SQL Engine Should You Use?
A detailed comparison of Flink SQL and ksqlDB for stream processing. Compare architecture, SQL capabilities, state management, ecosystem, and production readiness.
Flink State Management: RocksDB, Heap, and Choosing the Right Backend
Master Flink state management - understand state backends, keyed vs operator state, TTL configuration, and how to choose between RocksDB and heap for your workload.
Upgrading Flink Jobs Without Downtime: Schema Evolution and State Compatibility
Learn how to upgrade Flink jobs without data loss - savepoint-based upgrades, state compatibility rules, schema evolution, and blue-green deployment patterns.
Apache Flink Use Cases: Real-World Stream Processing Examples
Explore real-world Apache Flink use cases across fraud detection, IoT, recommendations, and ETL - with a decision matrix for when Flink is the right choice.
Flink Watermarks and Event Time: Handling Out-of-Order Events
Master Flink watermarks and event time processing. Learn how watermarks track progress, handle out-of-order data, and configure watermark strategies for production.
Geo-Enrichment in Streaming Pipelines: Adding Location Context
How to enrich streaming events with geographic data in real time. Covers IP geolocation, coordinate lookups, geofencing, and implementation patterns in Flink.
Idempotency in Streaming Pipelines: Exactly-Once Without the Headaches
Learn how to build idempotent streaming pipelines that produce correct results even with retries, reprocessing, and at-least-once delivery. Practical patterns for every destination.
Incremental Aggregation in Streaming Pipelines
How to compute running totals, counts, and metrics in real time using incremental aggregation. Covers non-windowed aggregations, changelog output, retraction handling, and state management in Apache Flink.
IP-to-Company Enrichment for Real-Time Analytics
How to identify companies visiting your site by enriching streaming events with IP-to-company data. Covers data providers, implementation patterns, and accuracy trade-offs.
Kafka vs Flink: Understanding When to Use Each
A practical comparison of Apache Kafka and Apache Flink - what each tool does, how they differ, when they complement each other, and how modern data stacks use both together.
The Kappa Architecture: Simplifying Data Pipelines with Streaming
A practical guide to the Kappa architecture pattern. Learn how replacing batch layers with a single streaming pipeline reduces complexity, and when it works best.
Handling Late-Arriving Data in Stream Processing
Learn how to handle late-arriving and out-of-order data in streaming pipelines. Configure watermarks, allowed lateness, and side outputs in Flink for correct results.
MongoDB to Snowflake: Real-Time Document Sync
Stream MongoDB document changes to Snowflake in real time using CDC. Learn how to flatten nested documents, handle schema-on-read data, and build a reliable sync pipeline.
Multi-Source CDC to a Single Destination: Merging Streams
Learn how to merge CDC streams from multiple databases into a single destination table. Handle schema conflicts, ordering guarantees, and identity resolution across sources.
MySQL to Databricks: Streaming CDC to Your Lakehouse
Stream real-time MySQL changes to Databricks using CDC. Learn how to build a lakehouse pipeline with Delta Lake, handle schema evolution, and enable real-time analytics.
Handling NULLs in Streaming Data: Strategies and Pitfalls
How to deal with NULL values in real-time streaming pipelines. Covers NULL semantics in Flink SQL, common bugs, default value strategies, and NULL-safe join patterns.
The Outbox Pattern Explained: Reliable Event Publishing for Microservices
Learn how the transactional outbox pattern solves the dual-write problem in microservices, how it integrates with Change Data Capture, and how to implement it reliably.
PostgreSQL to BigQuery with CDC: Real-Time Analytics Pipeline
Build a real-time data pipeline from PostgreSQL to BigQuery using Change Data Capture. Learn architecture patterns, schema mapping, and best practices for sub-minute analytics.
PostgreSQL to Elasticsearch: Real-Time Search Index Sync
Keep Elasticsearch search indexes in sync with PostgreSQL using CDC. Learn how to build a real-time sync pipeline for full-text search, autocomplete, and faceted navigation.
PostgreSQL to Snowflake in Real Time: A Step-by-Step Guide
Learn how to stream data from PostgreSQL to Snowflake in real time using CDC. Compare approaches, understand architecture patterns, and build a sub-second latency pipeline.
Real-Time Data Enrichment: Joining Streams with Reference Data
Learn how to enrich streaming data with reference data using lookup joins, temporal joins, and stream-to-stream joins - with practical architecture patterns.
Real-Time Data Preparation: Getting Raw Data Analytics-Ready as It Flows
Learn how to normalize, clean, and transform raw CDC and streaming data into analytics-ready datasets - schema handling, timestamps, NULLs, and star schemas.
Real-Time Feature Computation: From Raw Events to ML-Ready Features
How to compute machine learning features in real time using stream processing. Covers feature types, windowed aggregations, feature stores, and the training-serving skew problem.
Schema Drift Detection: Catching Breaking Changes Automatically
Learn how to detect and handle schema drift in streaming pipelines - column additions, type changes, and renames that can silently break your data pipeline.
Schema Registry in Stream Processing: Why Your Streams Need a Contract
Learn why schema registry is essential for production streaming pipelines. Understand schema evolution, compatibility modes, and how to prevent breaking changes in real-time data.
Self-Managed Debezium: The Operational Reality of DIY CDC
Debezium is the best open-source CDC tool available. It's also a full-time job to run in production. Here's what you'll actually deal with when you self-manage Debezium and Kafka Connect.
Why Self-Managed Apache Flink Is Harder Than You Think
Running Flink in production requires deep expertise in state management, checkpointing, memory tuning, and job lifecycle. Here's what you'll actually deal with when you self-manage Flink.
The Hidden Costs of Self-Managed Kafka: What They Don't Tell You
Running your own Kafka clusters sounds simple until it isn't. Learn about the real operational costs, common failures, and staffing requirements of self-managed Apache Kafka.
Slowly Changing Dimensions in Streaming: Handling SCD Type 1 and Type 2
How to implement slowly changing dimensions in real-time streaming pipelines. Covers SCD Type 1, Type 2, and hybrid approaches using CDC and Flink.
Migrating from Spark Structured Streaming to Apache Flink
A practical guide to migrating from Spark Structured Streaming to Apache Flink. Covers API differences, state migration challenges, checkpoint incompatibility, and a parallel running strategy.
Stream Data Transformation: Patterns for Shaping Data in Real Time
A complete guide to stream data transformation patterns - filtering, enrichment, masking, and more. Learn when to use Kafka SMTs vs Flink SQL vs no-code tools.
Real-Time Data Validation: Catching Bad Data Before It Lands
Learn how to validate streaming data in real time - schema checks, business rule validation, and anomaly detection that catches bad data before it reaches your warehouse.
Stream Filtering and Routing: Sending the Right Data to the Right Place
Learn how to filter, split, and route streaming data to multiple destinations based on content, type, or business rules. Build efficient multi-destination pipelines.
Stream Lookup Joins: Enriching Events with Database Lookups
Learn how stream lookup joins work in Flink SQL and stream processing. Practical patterns for enriching real-time events with dimension data from databases.
Stream Processing Anti-Patterns: 10 Mistakes to Avoid
Common stream processing mistakes that cause production outages, data loss, and performance problems. Learn what not to do with Kafka, Flink, and real-time pipelines.
Stream Processing Architecture: Patterns for Real-Time Data Systems
An architect's guide to stream processing patterns - Lambda, Kappa, event sourcing, CQRS, materialized views, and exactly-once semantics - with decision frameworks for each.
Stream Processing for Data Engineers: What You Need to Know
A practical guide to stream processing for data engineers moving from batch to real-time. Covers the mental model shift, key concepts like event time, watermarks, windows, and state, and when streaming actually beats batch.
Stream-to-Stream Joins: Correlating Events Across Data Sources
How to join two unbounded event streams in real time using Flink SQL. Covers interval joins, windowed joins, state management, and practical patterns.
Streaming Pipeline Cost Optimization: Getting More for Less
A practical guide to reducing the cost of real-time streaming pipelines. Covers infrastructure sizing, partition tuning, compression, tiered storage, managed vs self-hosted cost tradeoffs, and monitoring spend.
Streaming Data Catalog: Documenting and Discovering Real-Time Data Assets
How to build a data catalog for streaming systems. Covers topic registries, schema registries, lineage metadata, discovery tools, and practical patterns for documenting real-time data assets in Kafka and Flink pipelines.
Streaming ETL vs Batch ETL: Which Approach Is Right for Your Data Pipeline?
A practical guide to understanding the architectural differences, latency tradeoffs, cost implications, and ideal use cases for streaming ETL and batch ETL - including when a hybrid approach makes the most sense.
Streaming Materialized Views: Always-Fresh Query Results
How to build materialized views that update in real time using CDC and stream processing. Eliminate stale data without periodic batch refreshes.
String Normalization in Real-Time Streaming Pipelines
How to clean and normalize string data as it flows through streaming pipelines. Covers case normalization, trimming, encoding fixes, regex transforms, and unicode normalization in Kafka and Flink.
Temporal Joins in Flink: Point-in-Time Correct Enrichment
Deep dive into Flink temporal joins for point-in-time lookups against versioned tables. Learn the syntax, when to use them, and how they differ from lookup and regular joins.
Timestamp Handling in Streaming Pipelines: Timezones, Formats, and Event Time
A practical guide to handling timestamps correctly in real-time data pipelines. Covers timezone conversion, format normalization, event time extraction, and common pitfalls.
Data Type Conversion in Real-Time Pipelines
Learn how to handle data type conversions in streaming pipelines - timestamps, numeric precision, string encodings, and cross-database type mapping for reliable data delivery.
Why Managed Streaming Beats Self-Hosted: A Practical Comparison
Compare managed streaming platforms against self-hosted Kafka, Flink, and Debezium. Real operational costs, failure scenarios, and the engineering tradeoffs of build vs buy.
Zero-Downtime Database Migration with Change Data Capture
A practical engineering guide to migrating databases without downtime using Change Data Capture - covering the full process from initial sync through cutover, with validation strategies and common pitfalls.
CDC for ML Feature Pipelines: Real-Time Feature Engineering from Database Changes
Learn how Change Data Capture powers real-time ML feature pipelines. Build fresh feature stores, reduce training-serving skew, and improve model performance with streaming data.
How to Get CDC Without Managing Kafka: A Complete Guide
Learn how to implement Change Data Capture without the complexity of self-managed Kafka. Compare DIY CDC stacks vs fully managed alternatives.
Cloud ETL Tools Pricing Comparison: Fivetran vs Airbyte vs Confluent vs Streamkap
Compare pricing models and total cost of ownership for leading cloud ETL and data streaming platforms. Includes Fivetran, Airbyte, Confluent, and Streamkap.
Model Context Protocol (MCP) Explained: What It Means for Data Infrastructure
A complete guide to Model Context Protocol (MCP)—what it is, how it works, why it matters for AI agents, and what it means for your data infrastructure strategy.
MongoDB Change Data Capture: A Complete Guide to Real-Time CDC
Learn how to implement MongoDB Change Data Capture (CDC) for real-time streaming. Covers Change Streams, replica sets, Atlas setup, and managed CDC solutions.
Real-Time Data for AI Agents: Why Your Agents Need Fresh Data Infrastructure
Learn why AI agents require real-time data access, how CDC powers agentic workflows, and how to build data infrastructure that keeps AI agents accurate and responsive.
Real-Time RAG Pipelines: How CDC Keeps Your AI Context Fresh
Learn how to build RAG pipelines with real-time data using CDC. Keep your AI's retrieval context fresh with streaming updates to vector databases and knowledge bases.
Automated Schema Change Management in Data Pipelines: The Complete Guide
Learn how automated schema change management eliminates pipeline failures. Compare manual vs automatic schema evolution approaches for ETL and CDC pipelines.
Infrastructure as Code for Data Pipelines: Terraform, Pulumi, and API-First Approaches
Learn how to manage real-time data pipelines with Terraform and Infrastructure as Code. Includes HCL examples, GitOps workflows, and platform comparisons.
Data Integration Challenges: Master Solutions for Unified Data
Explore data integration challenges and how to overcome silos, latency, and quality issues with proven, actionable strategies for seamless data flow.
10 Essential Data Integration Techniques for Real-Time Analytics in 2026
Discover 10 essential data integration techniques, from CDC to streaming. Learn the pros, cons, and use cases to build efficient, real-time data pipelines.
What Is Data Synchronization and How It Works
Discover what is data synchronization and how it powers modern business by keeping data consistent across all systems for faster, smarter decisions.
What is message queuing: A Guide to Resilient, Scalable Apps
What is message queuing and how does it power resilient, scalable apps? Learn core concepts, real-world use cases, and essential patterns.
ETL Tools Comparison Choosing Your Modern Data Integration Solution
Explore our in-depth ETL tools comparison to choose the right solution. We analyze batch, ELT, and real-time CDC for modern data stacks and complex use cases.
A Guide to the Modern Data Streaming Platform
Explore how a modern data streaming platform transforms business with real-time data. This guide covers core technologies, architecture, and use cases.
A Practical Guide to Building Your First ETL Data Pipeline
Build a robust ETL data pipeline from the ground up. This guide covers architecture, tools, and modern strategies for real-time data integration.
Data in Motion Your Complete Guide to Real-Time Streaming
Unlock the power of real-time data streaming. This guide explains data in motion, its core technologies like CDC and Kafka, and how to build powerful pipelines.
10 Real-World Event Driven Architecture Examples Transforming Industries in 2025
Explore 10 detailed event driven architecture examples from finance, e-commerce, and IoT. Learn how real-time data streaming unlocks new capabilities.
Discover the business intelligence tools comparison: BI vs Tableau & Looker
Discover which platform wins in this business intelligence tools comparison of Power BI, Tableau, and Looker.
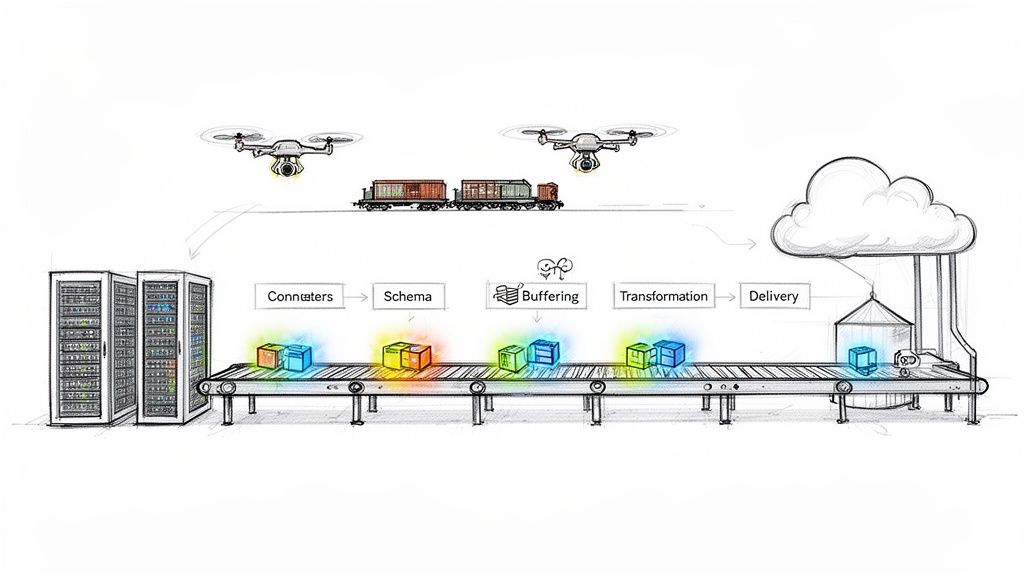
Build a Modern Data Ingestion Pipeline from Scratch
Learn how to build a scalable data ingestion pipeline. Explore batch vs. streaming, CDC, and the key components for real-time data flows.
What Is Data Orchestration: what is data orchestration in practice
Discover what is data orchestration and how it streamlines complex workflows, automates tasks, and unlocks reliable insights.
What Is a Data Flow Explained for Real-Time Business
Understand what is a data flow and how it moves data from source to destination. Explore real-time streaming, key components, and best practices.
What Is Stream Data A Guide to Real-Time Processing
Understand what is stream data with our complete guide. Learn how real-time processing, architectures, and use cases are transforming modern business.
Mastering Replication Of Data For Resilience And Analytics
Discover how replication of data enhances resilience, global availability, and analytics readiness with practical strategies, trade-offs, and best practices.
What Is Snowflake Marketplace Capacity Drawdown Explained
What is Snowflake Marketplace Capacity Drawdown? This guide explains how it works, its benefits, and how to manage costs to maximize your Snowflake investment.
Discover: snowflake marketplace and streamkap is now available on it
Discover how snowflake marketplace and streamkap is now available on it unlocks real-time data streaming for analytics with easy setup tips.
Understanding webhook source to kafka with streamkap: A Quick Guide
Learn webhook source to kafka with streamkap and how to stream data to Kafka in real time with practical, production-ready pipelines.
Kafka Pub Sub: A Practical Guide to kafka pub sub in Real-Time Streaming
Explore how kafka pub sub powers real-time data streaming, with topics and partitions, producers, and consumers, plus practical examples.
A Practical Guide to S3 Source to Kafka with Streamkap
Learn how to build a real-time S3 source to Kafka with Streamkap. This guide provides actionable steps for setup, configuration, and optimization.
What is data latency: what is data latency and its impact on your systems
Uncover what is data latency, its causes, and practical steps to measure and reduce it for faster, more reliable performance.
operational reporting vs analytical reporting: A Practical Guide
Discover the key differences between operational reporting vs analytical reporting and when to use each to drive better decisions.
How to Improve Data Quality: A Practical Guide to Clean, Trusted Data
Discover how to improve data quality with a practical, step-by-step guide to assessment, cleansing, and governance that builds trust in your data.
10 Data Architecture Best Practices for Scalable Systems in 2025
Explore 10 actionable data architecture best practices for building scalable, secure, and modern data systems. Master DDD, streaming, governance, and more.
Top 12 Data Warehouse Automation Tools for 2025
Explore our curated list of the top data warehouse automation tools for 2025. Compare features, pricing, and use cases to find the perfect solution.
how to read/write direct to kafka: A Developer's Guide
how to read/write direct to kafka: A practical guide with code samples, configs, and best practices for developers.
what are kafka smts? A quick guide to Kafka SMTs
what are kafka smts? Find out what they are and how SMTs in Kafka Connect simplify data pipelines with real-world examples.
10 Powerful Real Time Analytics Use Cases for 2025
Explore 10 powerful real time analytics use cases revolutionizing industries. See practical examples, tech stacks, and how to implement them today.
Apache Flink Java Support with Streamkap A How-To Guide
Unlock real-time data pipelines with our guide on Apache Flink Java support with Streamkap. Build, deploy, and monitor high-performance Java Flink jobs.
Apache Flink Python Support with Streamkap
Unlock Apache Flink Python support with Streamkap. This guide shows you how to build real-time data pipelines using PyFlink and Streamkap for CDC streams.
Apache Flink TypeScript Support with Streamkap Explained
Unlock Apache Flink TypeScript support with Streamkap. This guide shows you how to manage real-time data pipelines using TypeScript, APIs, and CDC.
Tuning Kafka for Sub Second Pipelines
A practical guide to tuning Kafka for sub second pipelines. Learn how to optimize producers, brokers, and consumers for ultra-low latency data streams.
Change data capture with ssh tunnels and port forwarding
Discover how to implement change data capture with ssh tunnels and port forwarding for secure, scalable data replication.
Finding the Right Estuary Alternative for Your Data
Explore top Estuary alternative platforms for real-time data pipelines. Our guide compares performance, cost, and use cases to help you choose wisely.
Top 12 Redpanda Alternative Solutions for 2025
Discover the best Redpanda alternative for your data streaming needs. Compare 12 top solutions for performance, cost, and operational overhead.
What Is Event Driven Architecture Explained
What is event driven architecture? This guide explains how it works with real-world examples, core patterns, and benefits for building scalable, modern systems.
12 Best Confluent Alternative Platforms in 2025
Discover the best Confluent alternatives for your data streaming needs. Compare managed Kafka, CDC platforms, and cloud-native solutions for performance, cost, and operational simplicity.

What Is Change Data Capture? A Practical Guide
Discover what is change data capture, how it works, and why it's essential for real-time data integration, analytics, and modern data pipelines.

Streaming Data Platform: Real-Time Insights for Businesses
Explore how a streaming data platform delivers real-time insights and powers agile decision-making for modern businesses.

Change Data Capture SQL Server A Modern Explainer
Discover how Change Data Capture SQL Server works. Learn to set up CDC, query change data, and leverage it for real-time analytics in this complete guide.

data engineering best practices for faster pipelines
Discover data engineering best practices to boost pipeline speed and reliability with practical, scalable patterns.

Data Migration Best Practices: 10 Steps for a Flawless 2025
Discover data migration best practices to safely move data, minimize downtime, and ensure a flawless 2025 rollout.

A Guide to Streaming Data Pipelines
Discover how streaming data pipelines unlock real-time insights. This guide covers architectures, key components, benefits, and best practices.

What Is Streaming Data and How Does It Work
Discover what is streaming data with this simple guide. Learn how real-time data streams power modern business, from analytics to instant customer experiences.

A Practical Guide: what is data pipelines and why it matters
Learn what is data pipelines, how they move data, core components, architectures, and practical examples to optimize your data workflow.

Top 10 Best Practices in Data Warehousing for 2025
Discover 10 expert-backed best practices in data warehousing. Master dimensional modeling, real-time CDC, and cloud architecture to build a modern DW.

Real Time Database Synchronization Explained
A complete guide to real time database synchronization. Learn how modern data pipelines work, from core concepts and architectures to business use cases.

Mastering Change Data Capture MySQL for Real-Time Data
Discover how Change Data Capture MySQL transforms data pipelines. Learn how CDC works, compare methods, and implement best practices for real-time insights.

Build a Modern Data Pipeline Architecture
Explore modern data pipeline architecture. Learn to design scalable, resilient systems with key patterns like ETL vs. ELT and the right cloud tools.

change data capture tools: 12 Real-Time Pipelines for 2025
Discover top change data capture tools and how they power real-time pipelines. Compare features, use cases, and pricing for 2025.

automate data pipeline: build robust, efficient workflows
Learn how to automate data pipeline with proven strategies, tools, and architecture tips to design scalable, reliable data workflows.

Data Lake House vs Data Warehouse: Key Differences Explained
Discover the core differences between data lake house vs data warehouse architectures to choose the best data strategy for your business. Learn more!

A Guide to Real Time Data Processing
Discover how real time data processing is transforming modern business. Our guide covers key concepts, architectures, and real-world applications.

Batch vs Stream Processing: Which Data Method Is Right for You?
Learn the key differences between batch vs stream processing to choose the best data approach for your needs. Find out more now!

How to Implement Change Data Capture Without Complexity
Discover how to implement change data capture without complexity. Our guide offers simple, modern methods for real-time data integration. Learn more!

Master DynamoDB Change Data Capture for Real-Time Insights
Learn how DynamoDB change data capture enables real-time data syncing. Discover best practices and use cases for modern applications.

Top Business Intelligence Dashboard Examples for 2025
Discover key business intelligence dashboard examples to inspire your data visualization and decision-making in 2025.

Top 12 Database Replication Tools for 2025
Explore the 12 best database replication tools for real-time synchronization. Compare features, pros, cons, and use cases to find your ideal solution.

Boost Business Efficiency with Real Time Data Integration
Learn how real time data integration enhances decision-making and operational agility. Discover tools and strategies to implement it effectively.

How to Reduce Latency: Proven Tips for Faster Systems
Learn how to reduce latency effectively. Discover actionable strategies to minimize delays and boost your system's performance today!

9 Data pipelines examples You Should Know
Discover the top 9 data pipelines examples strategies and tips. Complete guide with actionable insights.

What is an ETL Pipeline? Essential Data Workflow Explained
Learn what is an ETL pipeline, how it works, and why it's vital for data success. A simple, clear guide for beginners to master data integration.

Solve Data Integrity Problems: Tips for Reliable Data
Discover effective strategies to identify and prevent data integrity problems. Ensure your data is accurate and trustworthy with our expert guide.

Neo4j Real-Time Analytics for Instant Insights
Discover how to leverage Neo4j real-time capabilities for instant analytics, fraud detection, and recommendations. Your guide to dynamic graph data.

Mastering Real Time Data Analytics
Unlock the power of real time data analytics. This guide covers key architectures, tools like Streamkap, and practical strategies for instant business insights.

How to Build Data Pipelines From Scratch
Learn how to build data pipelines with our expert guide. Discover modern architecture, real-time CDC tools like Streamkap, and optimization best practices.

Guide to Azure SQL Database Change Data Capture
Explore Azure SQL Database Change Data Capture with our expert guide. Learn how CDC works, its setup, real-world use cases, and best practices.

A Guide to Data Stream Processing
Unlock real-time insights with our guide to data stream processing. Learn key concepts, architectures, and how to turn continuous data into business value.

A Guide to Database Replication Software
Explore how database replication software works with our complete guide. Learn about key architectures, use cases, and best practices for data availability.

A Guide to PostgreSQL Change Data Capture
Explore this comprehensive guide to PostgreSQL change data capture. Learn how logical decoding, Debezium, and best practices enable real-time data streaming.

A Guide to Snowflake Snowpipe Streaming
A practical guide to Snowflake Snowpipe Streaming. Learn how to configure real-time data ingestion for low-latency analytics and faster insights.

A Practical Guide to Managed Flink
Discover how managed Flink helps you build powerful real-time apps, not infrastructure. Explore practical comparisons, benefits, and expert tips.

MySQL CDC Multi-Tenant Architecture Guide
A practical guide to MySQL CDC multi-tenant architecture. Learn schema design, tenant isolation, and how to build scalable CDC pipelines for SaaS.

PlanetScale PostgreSQL an Explainer Guide
Explore PlanetScale PostgreSQL, a guide to its sharded architecture, developer features, and performance. Learn how it solves database scaling challenges.

Mastering Change Data Capture SQL in 2024
Unlock real-time data insights. This guide to Change Data Capture SQL covers setup, querying changes, and best practices for modern data pipelines.

What is Event Driven Programming? Key Concepts & Examples
Discover what is event driven programming, with clear examples and explanations of core concepts, architectures, and real-world applications. Learn more now!

PostgreSQL CDC Multi-Tenant Setups Done Right
A practical guide to building scalable PostgreSQL CDC multi-tenant systems. Learn schema design, security, and real-world streaming configurations.

A Guide to Managed Kafka Services
Discover how managed Kafka simplifies data streaming. This guide covers architecture, use cases, and best practices to help you scale efficiently.

A Practical Guide to S3 Real-Time Data Pipelines
Build a high-performance S3 real-time data pipeline. This guide provides actionable steps for low-latency data ingestion into Amazon S3 using modern tools.

7 Top Data Streaming Tools Comparison for 2025
Explore our data streaming tools comparison with 7 key insights to boost your data handling skills and project success in 2025.

Real-Time ETL Step by Step: Master Data Integration
Learn real-time ETL step by step to seamlessly integrate and process data streams for faster analytics and insights.

Understanding Redis Real Time Analytics for Data Insights
Explore redis real time analytics to understand its importance, functionality, and applications in data-driven decision making.

What is Debezium? Understanding Change Data Capture
Discover what is Debezium, its importance in data engineering, and how it captures changes with comprehensive explanations and insights.

7 Key Benefits of Real-Time ETL You Should Know
Discover 7 essential benefits of real-time ETL that can enhance data efficiency and decision-making for your analytics teams.

Understanding Why Automate ETL for Data Success
Explore why automate ETL is vital for data success, emphasizing comprehensive understanding and its impact on data management efficiency.

Understanding What is Streaming Architecture for Data
Explore what is streaming architecture, its importance, workings, and key concepts for data engineers and architects seeking comprehensive understanding.

8 Must-Know Database Connectors List for 2025
Explore this database connectors list featuring 8 essential tips for connecting and integrating your data systems effectively.

Understanding What is Batch vs Streaming Data Processing
Discover what is batch vs streaming and learn the differences, importance, and how these data processing methods work for effective analytics.

Understanding the Role of Kafka in Analytics
Explore the role of Kafka in analytics to gain a comprehensive understanding of its significance and functionality in data processing and analysis.

What is Real-Time Data? Understanding Its Importance and Functions
Discover what is real-time data and understand its significance, functionality, and applications in today's data-driven landscape.

Streaming CDC Data into Motherduck: A Step-by-Step Guide
Learn to stream CDC data into Motherduck effortlessly with our detailed step-by-step guide, ensuring smooth data processing and integration.

Understanding Real-Time ETL Challenges Explained Clearly
Explore real-time ETL challenges explained in detail, covering complexities, importance, and practical insights for better data integration understanding.

Understanding Real-Time Supabase CDC for Data Teams
Explore the concept of real-time Supabase CDC, its importance, workings, and key concepts for data professionals in this comprehensive guide.

7 Essential Tips for Understanding PlanetScale Real-Time CDC Streaming
Learn 7 essential tips for mastering PlanetScale real-time CDC streaming and enhance your data management skills effectively.

Master Postgresql to Snowflake Streaming Efficiently
Follow this step-by-step guide for Postgresql to Snowflake streaming to ensure seamless data integration and real-time analytics.

Understanding Most Cost-Effective Solutions for Streaming Data to Snowflake
Explore the most cost-effective solutions for streaming data to Snowflake, focusing on comprehensive understanding and practical insights.

Understanding Shift Left: Enhancing Data Quality Early
Explore shift left and its importance in improving data quality and efficiency in engineering and analytics processes for better outcomes.

What is Kafka? Understanding Its Purpose and Functionality
Explore kafka what is and gain a comprehensive understanding of its importance, functionality, and key concepts in the data engineering world.

Understanding Why Streaming CDC Matters for Data Professionals
Explore why streaming CDC matters in data engineering and analytics, emphasizing its role in real-time data processing and decision-making.

Master Your Real-Time Analytics Workflow for 2025
Follow this step-by-step guide to streamline your real-time analytics workflow and enhance data-driven decision-making.

What is Apache Flink? Understanding Stream Processing
Explore what is Apache Flink, a powerful stream processing framework, and understand its importance, architecture, and core concepts.
Agent Context Consistency Patterns for Eventually-Consistent Streaming Pipelines
Practical patterns for handling consistency challenges when AI agents read from CDC-powered streaming pipelines — from version checks to read barriers.
Agent Decision Latency Budget: Where Time Goes in Every AI Agent Request
Break down the latency budget for AI agent requests — LLM inference, context retrieval, tool execution — and learn how to optimize each stage.
Agent Tool Use vs. Streaming Context: Two Ways to Give Agents Fresh Data
Compare tool-use (direct DB queries) vs. streaming context (CDC-fed caches) for AI agents — latency, cost, failure modes, and when to use each.
Build an AI Agent with Real-Time Streaming Context
Step-by-step tutorial: set up CDC from PostgreSQL, stream to Redis, and build a Python agent that reads fresh data instead of querying the source DB.
CDC Schema Evolution at Zero Downtime: A Practical Playbook
What happens when you ALTER TABLE with an active CDC pipeline. A practical playbook for column changes, schema registries, and safe deploys.
CDC to Elasticsearch: Building Real-Time Search from Database Changes
How to stream database changes to Elasticsearch for real-time search — covering index mapping, document ID strategies, handling deletes, and zero-downtime reindexing.
Control Plane vs Data Plane Separation in Streaming Systems
Learn how control plane and data plane separation works in streaming architectures, why it matters for security and compliance, and how BYOC models implement it.
Debug Kafka Consumer Lag: A Step-by-Step Runbook
A practical runbook for triaging Kafka consumer lag — from checking group state to identifying slow partitions, rebalances, and sink bottlenecks.
Event-Driven Agent Orchestration: Triggering AI Agents from Database Changes
Learn how to use CDC events to trigger AI agent workflows — from architecture patterns to filtering, batching, error handling, and dead letter queues.
Exactly-Once Delivery: How It Actually Works Under the Hood
A deep technical breakdown of exactly-once delivery in streaming systems — idempotent producers, Kafka transactions, consumer offsets, and when you need it.
MCP Servers Backed by Streaming Data
How to build an MCP server that exposes live pipeline state to AI tools like Claude and Cursor — architecture, authentication, and practical examples.
MySQL Binary Log CDC Deep Dive: Formats, GTIDs, and Replication
Technical deep dive into MySQL binary log internals for CDC — covering row-based logging, GTID replication, event structure, and purge policies.
PostgreSQL Logical Replication Internals: WAL, Slots, and Decoding
Deep dive into PostgreSQL logical replication internals covering WAL segments, logical decoding, replication slots, publications, and slot management.
Streaming API Design Patterns: SSE, WebSockets, gRPC, and Webhooks
How to expose streaming data to downstream applications using SSE, WebSockets, gRPC streaming, webhooks, and long polling — with code examples and trade-offs.
Building a Real-Time Embedding Pipeline with CDC and Vector Stores
Learn how to build a streaming embedding pipeline that captures database changes, generates embeddings, and upserts to vector stores in real time.
The Streaming Feature Store Pattern: Real-Time ML Features from CDC
Learn how streaming feature stores eliminate training-serving skew by computing ML features from CDC events in real time instead of batch jobs.
Load Testing Streaming Pipelines: A Practical Guide
How to load test CDC and streaming pipelines before production — tools, techniques, metrics, and a step-by-step approach to finding breaking points.
Streaming CDC Events to Vector Databases for Real-Time AI
How to build a CDC pipeline to vector databases — covering embedding generation, incremental updates, delete handling, chunking strategies, and metadata filtering.
Managing Streaming Pipelines with Terraform
How to define CDC pipelines, connectors, and transforms as Terraform code — with CI/CD integration, drift detection, and secrets management.
Webhook to Kafka: Reliable Ingestion at Scale
How to build a reliable webhook ingestion layer using Kafka as a durable buffer — covering deduplication, ordering, retries, and dead letter queues.