CDC from Multi-Tenant Databases with Sub-Second Latency
Streamkap Team
January 6, 2026
Multi-tenant databases have become a cornerstone for SaaS providers, ISVs, and enterprises handling diverse customer bases. These architectures allow multiple tenants—whether individual users or entire organizations—to share a single application instance while keeping their data isolated. However, as tenant numbers grow into the thousands, table proliferation explodes, often reaching tens or hundreds of thousands of tables or schemas. This fragmentation poses significant hurdles for Change Data Capture (CDC), the process of detecting and replicating data changes.
Streamkap solves this by offering an automated CDC platform that aggregates proliferated tables efficiently. The platform leverages Kafka for high-throughput streaming and Flink for stream processing to deliver sub-second latency without any of the complexity traditionally associated with managing those distributed systems. Streamkap is a low total cost of ownership (TCO) way to solve for streaming data in hybrid, on-prem, and cloud environments. Whether you’re dealing with shared databases, separate schemas, or fully isolated databases, Streamkap ensures real-time data flows to destinations like Snowflake, Databricks, ClickHouse, and more, while automating schema evolution, tenant tagging, and security measures.
This comprehensive guide explores multi-tenant database architectures, their benefits and limitations, the unique CDC challenges they present, and how Streamkap provides an enterprise-grade solution that scales effortlessly—even for setups with 100,000+ tenants—without coding or high maintenance overhead.
Understanding Multi-Tenant Databases: The Foundation of Modern SaaS
Multi-tenant databases are designed to store data from multiple customers (tenants) within a single database instance, balancing efficiency with isolation. SaaS applications like CRM, ecommerce platforms, ERP, and more can leverage multi-tenant architecture to offer a separate table or schema per customer, rather than a separate database per customer as in a single-tenant model, for optimized resource utilization.
Types of Multi-Tenant Database Architectures
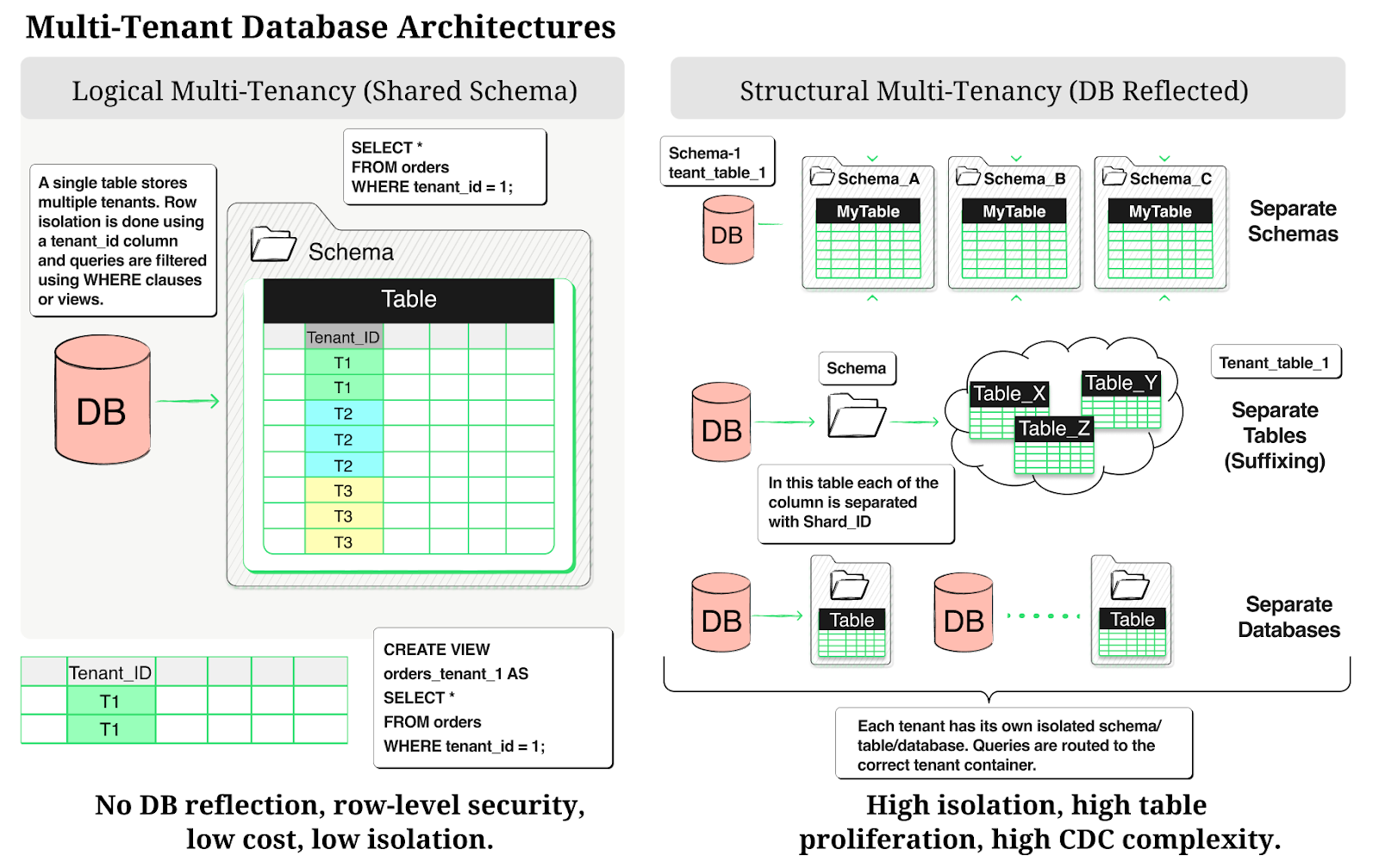
Multi-tenant databases can be implemented in various ways, but they generally fall into two broad categories based on how tenancy is reflected in the database structure. These models balance isolation, cost, and scalability, with the latter often leading to significant table proliferation.
-
Logical Multi-Tenancy (No Reflection in DB Schema): In this approach, multi-tenancy is handled entirely at the application level without altering the underlying database schema. All tenants share the same database and schema, with isolation achieved through row-level security mechanisms, such as adding a Tenant ID column to every table and enforcing access controls via queries or views. This is the most cost-effective and simplest to manage but provides the least physical isolation, making it ideal for low-risk, high-volume applications where performance and resource sharing are prioritized over strict separation.
-
Structural Multi-Tenancy (Reflected in DB Schema): Here, multi-tenancy is embedded in the database design, leading to physical or logical separation that can result in tens or hundreds of thousands of tables. This includes:
-
Separate schemas within a shared database (common in Postgres), where each tenant gets its own schema for better logical isolation while sharing resources.
-
Tables split per tenant within a single schema, often using numeric suffixes (e.g., “customers_001” to “customers_250k”), which we’ve seen in production environments handling up to 250,000 tables in one database/schema.
-
Fully separate databases per tenant or group of tenants, frequently sharded across clusters in a cell-based architecture for maximum security and customization, though this increases complexity and costs.
-
This structural approach enhances isolation and compliance but amplifies challenges in data aggregation and CDC, as the sheer number of tables demands efficient grouping and merging strategies.
Database-Specific Implementations
Multi-tenancy approaches vary by database system, influencing CDC strategies:
- Postgres: Supports separate schemas within a single database, making it flexible for structural multi-tenancy. Each schema can mirror the full table set for a tenant, leading to proliferation when scaled to thousands of tenants. Additionally, we’ve seen cases with numerous Postgres databases where customers faced significant challenges setting up CDC due to the sheer number of databases. Streamkap successfully used regex-based grouping across schemas or databases to aggregate changes into unified streams with sub-second latency.
- MySQL: Lacks native schema separation like Postgres, so multi-tenancy often relies on separate databases per tenant or table suffixing within a single database (e.g., “tenant1_orders,” “tenant2_orders”). This can result in extreme table counts in one database, requiring careful sharding and CDC tools that manage high-volume, suffixed tables without performance hits.
- SQL Server: Similar to MySQL, it favors separate databases for isolation, especially in Always On availability groups for high availability. Multi-tenancy might involve sharding across databases, with CDC needing to handle failovers and tag data with Database IDs. In shared setups, row-level security via Tenant IDs is common, but structural separation dominates for enterprise compliance.
- Oracle: Employs Multitenant architecture with Container Databases (CDBs) that consolidate multiple Pluggable Databases (PDBs), where each PDB can function as an isolated tenant environment. This provides strong isolation and resource sharing, ideal for enterprise-scale multi-tenancy. CDC in such setups requires capturing changes across PDBs, often using tagging or regex grouping to aggregate data into unified streams without disrupting pluggability.
- MongoDB: As a document-oriented NoSQL database, multi-tenancy is achieved through separate databases per tenant for maximum isolation, separate collections within a shared database for logical separation, or shared collections with tenant-specific fields (e.g., Tenant ID) for row-level access control. This can lead to the proliferation of collections (similar to tables), and CDC tools must efficiently aggregate across these flexible structures, handling schema-less data and high-velocity changes.
Hybrid models combine these, such as using separate databases for high-value enterprise tenants and shared schemas for smaller ones. Regardless of the model, as tenants multiply, so do tables—leading to proliferation that can overwhelm traditional CDC tools.
[Placeholder: Insert infographic here comparing the two multi-tenant models:]
Why Aggregate
Multi-tenant databases isolate data per customer to mitigate risks, but consolidation downstream has several benefits:
- Analytics: Consolidate shards—like “customers_001” through “customers_999”—into unified views for cross-tenant analysis, trend detection, and KPI tracking, avoiding cumbersome manual ETL delays.
- Client Aggregation: Aggregation unifies these into a cohesive view per client, simplifying custom reporting and personalization without cross-table joins.
- Operational: Enable real-time decisions, such as inventory across sharded products or event monitoring, with tenant-specific filtering to maintain isolation.
- Cost Reduction: By merging streams into fewer destination tables (e.g., in Snowflake), aggregation minimizes query costs and the labour involved in maintenance.
Streamkap’s Innovative Solution: Automated, IaC or No-Code CDC for Multi-Tenant Aggregation
Streamkap transforms multi-tenant CDC into a streamlined process, automating aggregation of hundreds of thousands of tables with sub-second latency. Built on Kafka for robust streaming and Flink for parallel, stateful processing, Streamkap handles everything from change capture to destination merging. It supports all major databases (Postgres, SQL Server, Oracle, MySQL) and destinations, ensuring enterprise-grade replication even in complex, sharded environments.
Core Features of Streamkap for Multi-Tenant CDC- Automated Tenant Tagging and Isolation: Streamkap automatically adds Tenant ID, Database ID, or Shard ID to records during capture, enabling secure aggregation while allowing downstream filtering to maintain privacy.
- Sub-Second Latency with High Throughput: Using log-based CDC, Streamkap captures changes in real time, propagating them via Kafka’s low-latency partitions. Flink enables parallel multi-threaded loading, handling terabytes without bottlenecks.
- Schema Evolution Handling: Detects and applies schema changes (DDL) automatically, syncing sources and destinations seamlessly—even without primary keys—preventing pipeline failures.
- Compression and Optimization: Built-in compression minimizes data transfer costs, while optimized partitioning ensures efficient resource use, keeping TCO low.
- High Availability Support: Capturing changes during failovers without data loss.
- Data Masking and Security: Applies masking to sensitive fields during replication, complying with GDPR and other regulations.
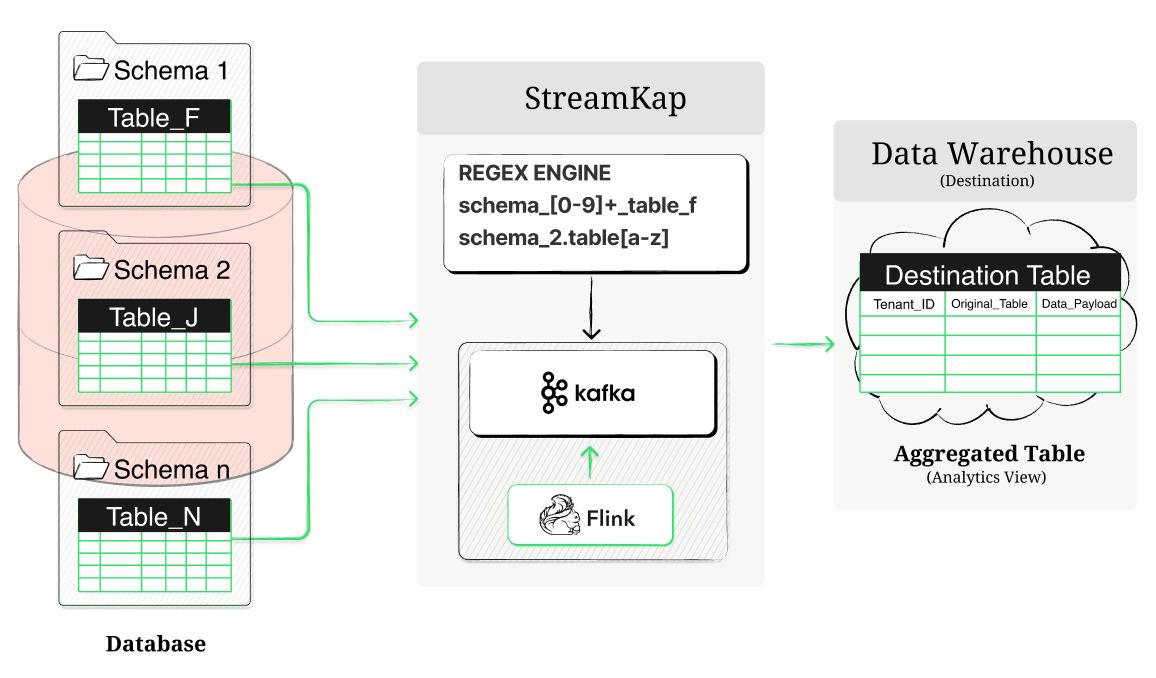
Strategy 1: Regex-Based Grouping for Extreme Scale
Ideal for hundreds of thousands of tables in separate schemas or databases:
-
Use regex (e.g., “tenant_[0-9]+_table”) to group sharded tables into unified Kafka topics.
-
Stream changes sub-second via Kafka, with Flink for optional enrichments like SCD Type 2 history.
-
Aggregate into a single destination table, tagged for tenant traceability.
In a real-world example, a SaaS provider with 5,000 tenant schemas used this to consolidate data to Databricks, achieving sub-second analytics on cross-tenant trends without custom scripts.
[Placeholder: Insert screenshot or animated GIF here of Streamkap’s UI for regex setup and tenant tagging. Include a throughput graph showing sub-second latency. Label it “Streamkap’s Regex Grouping: Scaling Multi-Tenant CDC.”]
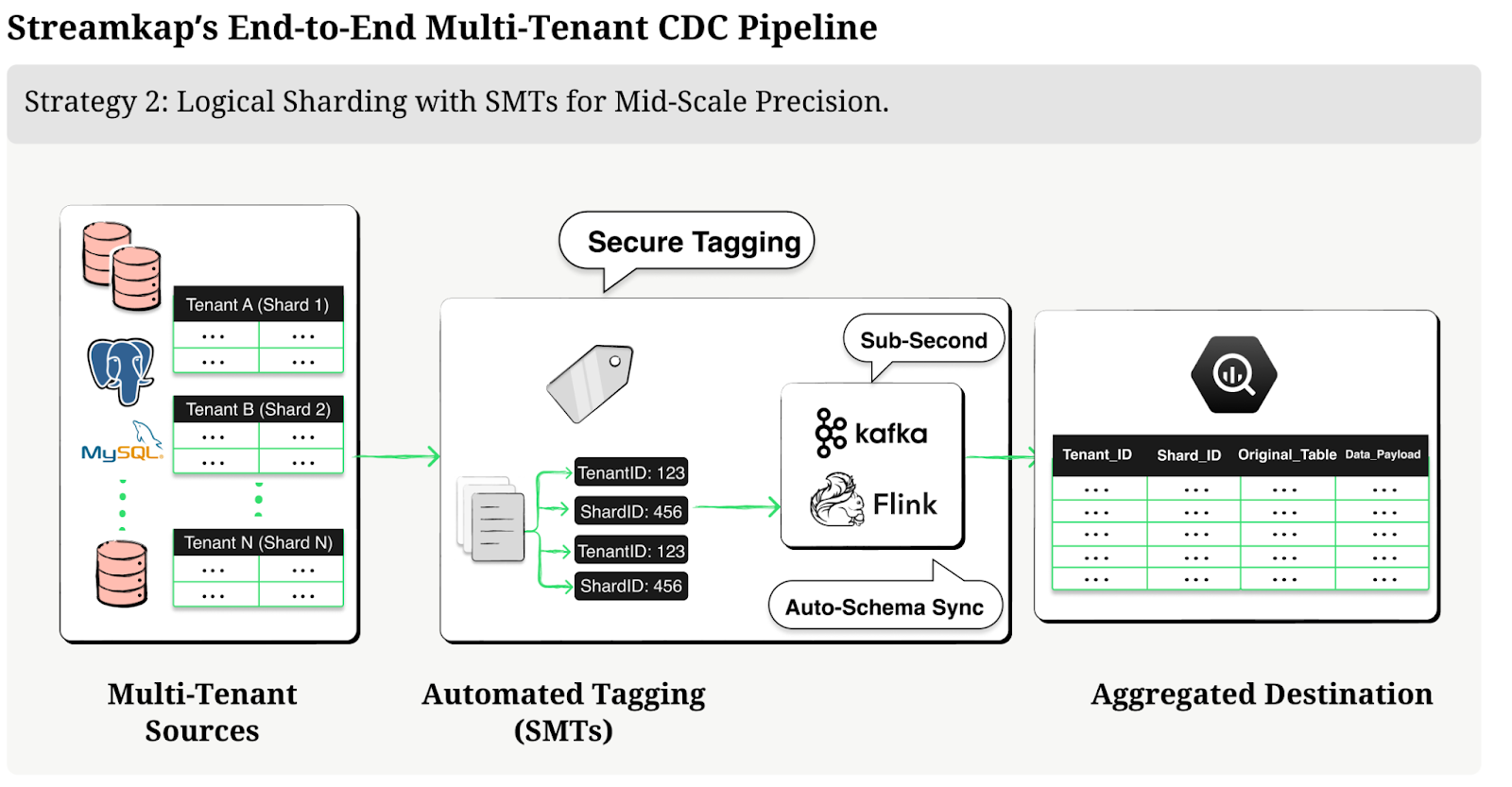
Strategy 2: Logical Sharding with SMTs for Mid-Scale Precision
For 25,000–40,000 tables in shared or hybrid models:
-
Source SMTs tag data with identifiers, supporting nuanced filtering.
-
Kafka topics namespace changes (e.g., “tenantX_shardY_table”), delivered sub-second.
-
Destination SMTs/Flink merge aggregates, preserving isolation.
A cell-based e-commerce platform leveraged this to stream from sharded Postgres to BigQuery, enabling real-time inventory dashboards with zero downtime.
[Placeholder: Insert flow diagram here: Multi-tenant sources → Automated Tagging → Kafka/Flink Processing → Aggregated Destination. Annotate with “Sub-Second,” “Auto-Schema Sync,” and “Secure Tagging.” Label it “Streamkap’s End-to-End Multi-Tenant CDC Pipeline.”]
Real-World Benefits: Why Data Teams Choose Streamkap
Streamkap’s approach delivers measurable value:
- Ultra-Low Latency for Real-Time Use Cases: Sub-second CDC powers live customer-facing and operational insights, ML models, and alerts—e.g., powering predictive maintenance across tenants instantly.
- Drastically Reduced TCO: Automation eliminates coding; efficient scaling means costs barely exceed standard deployments, even for 100k+ tables.
- Enhanced Security and Compliance: Tenant isolation, masking, and auditing minimize risks in expanded multi-tenant surfaces.
- Operational Stability: No glitches from schema drift or failovers; self-serve tools empower teams to iterate faster.
- Flexibility Across Ecosystems: Supports all SQL variants, hybrid setups, and integrations like Kafka Connect for custom extensions.
[Placeholder: Insert infographic here: Key metrics like “Latency: <1s,” “TCO Reduction: 50%+,” “Tenant Scale: 100k+,” “Setup Time: Hours.” Compare to traditional tools. Label it “Streamkap vs. Legacy CDC: Proven Advantages.”]

Conclusion: Empower Your Multi-Tenant Data Strategy with Streamkap
Multi-tenant databases drive SaaS innovation but demand sophisticated CDC to aggregate proliferated tables without compromise. Streamkap platform, powered by Kafka and Flink, solves this with sub-second latency, automated features, and low costs, turning fragmentation into unified, actionable intelligence.
Streamkap Team
LinkedInAuthor Bio
The Streamkap team builds modern real-time data infrastructure to help companies sync data between systems.
Published
January 6, 2026
Related blog posts

Batch Processing vs Real-Time Stream Processing
There is a big movement underway in the migration from batch ETL to real-time streaming ETL but what does that mean? How do these methods compare? While real-time data streaming has many advantages over batch processing, it is not always the right choice depending on the use case so let's take a loo

Change Data Capture for Streaming ETL
Change Data Capture refers to the process of capturing changes made to data in a source system such as a database, so that these change events can be used in the destination system, such as a data warehouse, data lake, data app, machine learning models, indexes, or caches.
DynamoDB ETL and Rockset migration with Streamkap
Let’s look at the advantages of DynamoDB ETL and Rockset migration with Streamkap.