<--- Back to all resources
What Is Data Synchronization and How It Works
Discover what is data synchronization and how it powers modern business by keeping data consistent across all systems for faster, smarter decisions.
Data synchronization is the ongoing, automated process of making sure that two or more separate systems hold the exact same data at the same time. Think about how your phone contacts, calendar, and computer stay perfectly aligned. When you add a new appointment on one device, it instantly appears on all the others, creating a single, reliable source of information.
Defining Data Synchronization
Picture your business data as a song played by a massive orchestra. Each musician—representing a database, a SaaS application, or a cloud service—needs the same sheet music, updated in real time. If the violin section has a different score than the brass section, you don’t get harmony. You get noise.
Data synchronization is the conductor making sure every system has the identical, up-to-the-minute version of the data. This is more than just making copies; it’s about establishing a single source of truth that powers accurate analytics, responsive customer experiences, and confident business decisions.
When a customer updates their shipping address in your mobile app, synchronization is what makes that change instantly appear in your CRM, your warehouse management system, and your marketing platform. No delays, no conflicts.
Why Consistency Matters
Inconsistent data is a recipe for operational chaos and lost customer trust. Without proper synchronization, different departments end up working from conflicting information, which leads to expensive mistakes and missed opportunities.
Imagine the sales team sees a customer’s old address while the logistics team sees the new one. The result? A failed delivery and a very unhappy customer.
Data synchronization eliminates these data silos by creating a cohesive, unified view of information across the entire organization. It transforms disparate data points into a powerful, harmonized asset.
This process is absolutely fundamental for how modern businesses operate. It ensures every part of your organization—from front-end apps to back-end analytics platforms—is running on the most current and accurate information available.
Let’s quickly break down the core principles that make data synchronization so essential.
Core Principles of Data Synchronization at a Glance
| Principle | What It Means | Why It Matters |
|---|---|---|
| Consistency | Ensuring data values are identical across all connected systems. | Prevents errors, confusion, and poor decision-making caused by conflicting information. |
| Timeliness | Updating data across systems in near real-time or at very low latency. | Enables immediate action based on the most current events, like fraud detection or inventory updates. |
| Integrity | Maintaining the accuracy and validity of data as it moves between systems. | Preserves the quality and trustworthiness of your data, preventing corruption or loss. |
| Automation | The process runs continuously and automatically without manual intervention. | Reduces human error, saves time, and ensures the system is always up-to-date and reliable. |
These principles work together to deliver some major benefits across the business.
Here’s how that plays out in the real world:
- Improved Decision-Making: Leaders can trust that their reports and dashboards reflect what’s happening in the business right now, not what happened yesterday.
- Enhanced Customer Experience: Customers get consistent information and service no matter how they interact with your company—website, app, or in-store.
- Increased Operational Efficiency: Automated updates get rid of tedious manual data entry and dramatically cut down on the risk of human error.
- A Foundation for Real-Time Analytics: It lets you analyze fresh data from operational systems as events happen, surfacing insights that would otherwise be hours or days late.
Ultimately, getting a firm grasp on data synchronization is the first step toward building a more agile, data-driven organization. It’s the essential plumbing that lets information flow freely and accurately, turning isolated data into coordinated business intelligence.
From Batch ETL to Real-Time Streaming: A Necessary Evolution
For decades, the gold standard for moving data was a process called batch ETL (Extract, Transform, Load). Picture a mail truck making its rounds only once a day, say at 5 PM. It’s a reliable system, but every piece of mail it delivers is inherently old—sometimes by a few hours, often by a full day.
This approach was perfectly fine when business decisions could afford to wait. Companies would schedule massive jobs to run overnight. They’d pull data from their operational databases, reformat it, and load it into a data warehouse. The next morning, analysts would have a fresh-ish report waiting for them.
But this old-school method has some serious downsides. Batch jobs are resource hogs, hammering production databases with heavy queries that can slow things down for actual users. More importantly, the built-in delay means that by the time anyone sees the data, it’s already a snapshot of the past.
The High Cost of Yesterday’s Data
In a world where customers expect instant gratification, making decisions on stale data is a recipe for disaster. You can’t effectively fight fraud, manage inventory during a flash sale, or personalize a customer’s experience if your information is stuck on a 24-hour delay. The mail truck analogy falls apart completely when you need to deliver a live news broadcast.
This demand for immediacy is what forced the shift away from slow, scheduled updates. Businesses realized they needed a way to see and react to things as they were happening, not long after the opportunity had passed.
The fundamental problem with batch ETL is its latency. It’s great at answering, “What happened yesterday?” But modern businesses need to know, “What is happening right now?”
This simple, powerful need cleared the path for an entirely new way of thinking about data movement: real-time streaming.
The Dawn of Real-Time Streaming and CDC
Instead of waiting to bundle data into large, infrequent batches, real-time streaming captures and processes data as it’s created, one event at a time. This slashes latency from hours down to seconds or even milliseconds. The engine behind this powerful shift is a technology called Change Data Capture (CDC).
If batch ETL is the mail truck, CDC is a live news ticker running at the bottom of your screen. It doesn’t waste time and resources by constantly asking the entire database, “What’s new?” Instead, it intelligently taps into the database’s transaction log—a running ledger of every single insert, update, and delete—and streams those changes out to other systems the moment they occur.
This approach is a major improvement for several reasons:
- Minimal Impact: Because CDC just reads the logs, it puts almost no extra load on the source database. This is a huge contrast to the heavy queries that bog down systems during batch runs.
- Guaranteed Accuracy: It captures every change, in the exact order it happened. This ensures complete data integrity without ever missing an event.
- Ultra-Low Latency: Changes are sent out almost instantly, making true real-time analytics and event-driven services possible.
The financial and operational impact here is massive. The data integration market, which is increasingly dominated by real-time sync, is expected to jump from $17.58 billion in 2025 to $33.24 billion by 2030. This isn’t just hype; moving to a streaming model can slash data processing times by 90%, a critical advantage when you’re generating mountains of data every day.
This is more than just a technical upgrade; it’s a strategic pivot. By adopting real-time streaming, companies can stop being reactive and start being proactive. They can build systems that understand and respond to the continuous flow of data in motion. This powers everything from immediate fraud alerts to dynamic pricing and deeply personalized customer journeys—all driven by data that is fresh, accurate, and available now.
3 Core Techniques for Modern Data Synchronization
So, we know data needs to stay in sync. But how does that actually happen? Under the hood, systems rely on a few key techniques to talk to each other and share updates. These methods have evolved quite a bit, moving from simple (and often inefficient) check-ins to incredibly sophisticated, real-time data streams.
This evolution is really a story about speed and efficiency, a journey from periodic batch jobs to the continuous, always-on operations that modern businesses demand. This diagram perfectly captures the leap from slow, scheduled data transfers to instant, event-driven streaming.
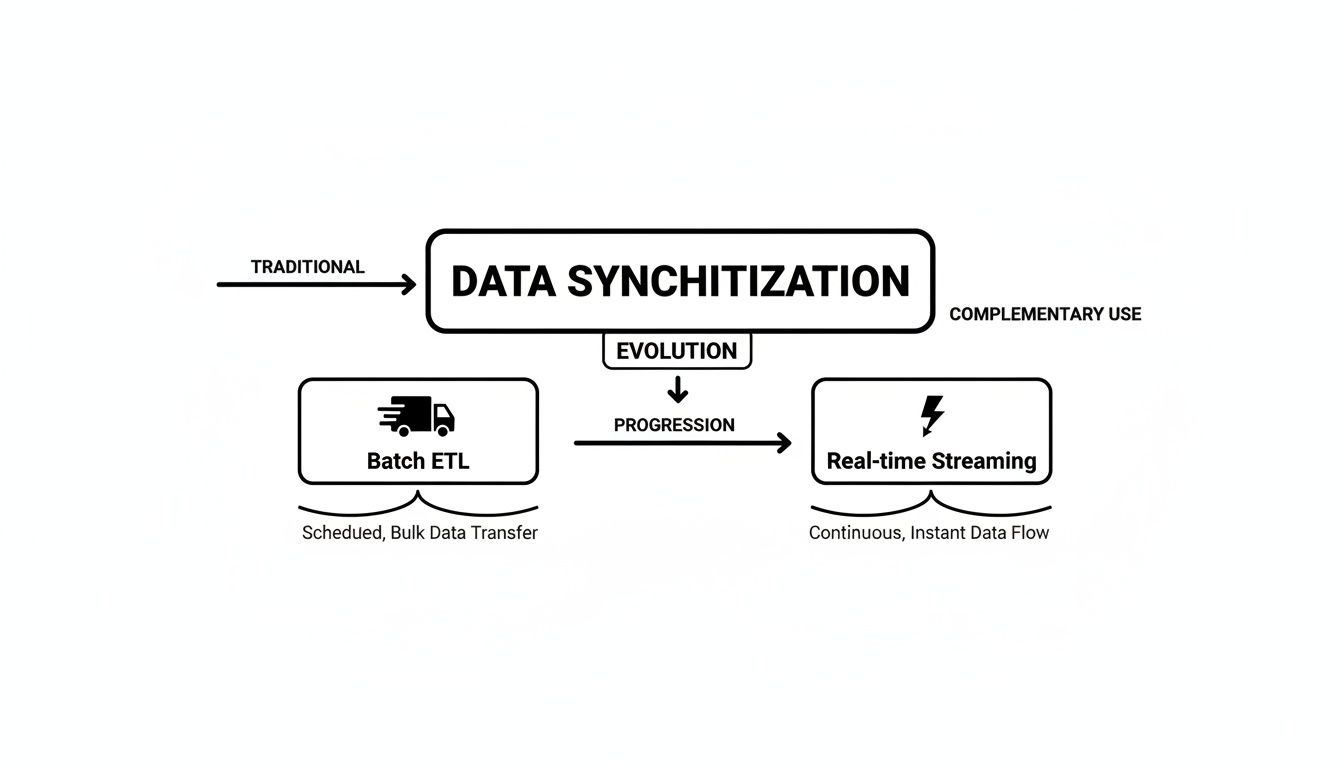
Think of it as the difference between a mail truck that delivers once a day (batch ETL) and the lightning bolt of a text message (real-time streaming). That shift is everything.
Let’s break down the main techniques that make it all possible.
Comparing Data Synchronization Techniques
To get a clearer picture, let’s look at the most common methods side-by-side. This table breaks down how each one works and, more importantly, what trade-offs you’re making in terms of performance, latency, and reliability.
| Technique | How It Works | Latency | Source System Load | Best For |
|---|---|---|---|---|
| Query-Based Polling | The destination system repeatedly queries the source database, asking for new or updated records since the last check. | High | Very High | Non-critical systems where data can be minutes or hours old without causing issues. |
| Event-Driven Webhooks | The source application automatically sends an HTTP notification (a “webhook”) to the destination when a specific event occurs. | Low | Low | Simple, specific event notifications between SaaS applications (e.g., a new sale in Shopify). |
| Change Data Capture (CDC) | The system reads the source database’s internal transaction log, capturing every single insert, update, and delete as it happens. | Near Real-Time | Minimal | Building high-performance, reliable data pipelines for analytics, microservices, and operational databases. |
As you can see, the choice of technique has a massive impact on your system’s performance and the freshness of your data. Let’s dig into the details of each.
1. Query-Based Polling: The “Are We There Yet?” Method
The most basic technique is query-based polling. Think of a kid in the back of a car on a road trip, asking, “Are we there yet?” every five minutes. That’s polling in a nutshell.
The destination system periodically sends a query to the source, essentially asking, “Hey, has anything changed since I last looked?”
While it’s simple to set up, this approach comes with some serious baggage:
- High Latency: Updates are only spotted at the next polling interval. If you poll every five minutes, your data is guaranteed to be up to five minutes stale.
- Heavy Source Load: Every single poll is a query that hits your production database. As you increase the polling frequency or add more tables, you can seriously drag down your primary system’s performance.
- Missed Deletes: Polling often relies on a
last_updatedtimestamp. This makes it nearly impossible to detect when a row has been deleted, leading to inconsistent data.
Polling might be fine for non-critical data where delays don’t matter, but it’s a non-starter for most real-time needs.
2. Event-Driven Webhooks: The Pager System
A step up from polling is using webhooks. This is like getting a pager at a busy restaurant. Instead of constantly walking up to the host to ask if your table is ready (polling), they give you a device that buzzes the second it’s your turn.
In this model, the source system sends an HTTP request—the webhook—to a specific destination endpoint whenever an event happens, like a new user signing up. This is way more efficient because data only moves when there’s actually something to report.
But webhooks aren’t foolproof. They fully depend on the source application to reliably trigger and send the event. If the source system is down or a network blip causes the webhook to fail, that update could be lost forever unless you’ve engineered a complicated retry system.
3. Change Data Capture: The Gold Standard
For true real-time synchronization, the most reliable and efficient technique is Change Data Capture (CDC). If polling is asking “what’s new?” and webhooks are notifications, CDC is like having a court stenographer recording every single word in a trial. It doesn’t miss a thing.
Change Data Capture works by reading the database’s own transaction log—the file a database uses internally to record every single insert, update, and delete. It’s how databases ensure their own consistency, and CDC simply taps into that stream.
This approach is incredibly low-impact. Instead of hammering the database with queries, CDC tools listen to this log file and stream every change to any destination in milliseconds. It captures everything—including deletes—in the exact order it happened. To streamline this process, modern pipelines might use tools like AI-powered data extraction engines to pull and structure data before it’s streamed.
This makes CDC the hands-down winner for building reliable, low-latency data pipelines. To really get into the nuts and bolts, check out our deep dive on what is Change Data Capture and see how it works in practice.
Where Does Real-Time Data Synchronization Actually Make a Difference?
It’s one thing to talk about data synchronization in theory, but where does the rubber meet the road? The real value isn’t just in moving data around; it’s about what that speed and consistency enables for a business. When data is live, it becomes a tool for boosting revenue, making customers happy, and streamlining operations.
Across totally different industries, companies are solving critical problems that were once unsolvable with their old, slow batch processes. Let’s look at a few powerful, real-world examples of how synchronized data is making a real difference.
E-commerce and Retail: No More “Sorry, We’re Out of Stock”
For any retailer, few things are more painful than overselling a hot item during a huge sale like Black Friday. This happens when your inventory data is stale. The website shows an item is available long after the last one was snagged in-store or through the mobile app. The result? Canceled orders, angry customers, and a serious hit to your reputation.
Real-time data synchronization puts an end to this nightmare by creating a single, trustworthy source of truth for inventory across all your sales channels.
- Instant Updates: The moment a product sells online, the inventory count is immediately updated in the warehouse, on the mobile app, and at the point-of-sale terminals in your physical stores.
- Pinpoint Accuracy: This completely prevents overselling. Your stock levels are always correct, no matter where or how a purchase is made.
- A Better Customer Experience: Shoppers can trust the “in stock” message they see, which means fewer support calls and a much smoother buying journey.
When every channel is perfectly aligned, retailers can run massive sales events with confidence. Their data becomes a reliable foundation for their business, not a ticking time bomb.
This instant consistency also opens the door to smarter strategies. Think dynamic pricing, where you can adjust prices on the fly based on real-time demand, competitor moves, and current stock levels.
Financial Services: Catching Fraud in the Act
In the world of finance, every second counts. A tiny delay can be the difference between stopping a fraudulent transaction and taking a major financial hit. Old-school systems that review transactions in batches are simply too slow to keep up with today’s sophisticated fraud schemes. This is where real-time sync provides a massive defensive advantage.
When a customer swipes their card, that transaction data is instantly streamed to a central analytics engine. In milliseconds, the engine compares the new purchase against the customer’s buying history, location, and known fraud patterns.
If the system spots something fishy—like a purchase in another country just minutes after a local one—it can automatically flag or block the transaction before it even goes through. This immediate response is only possible because the data is synchronized and analyzed in real time. For financial firms, this capability is so important that it has helped slash fraud detection times by up to 50%.
Internet of Things (IoT): From Sensor Data to Smart Decisions
The Internet of Things (IoT) is all about collecting a firehose of data from millions of sensors spread across factories, cities, or shipping networks. But that data is useless unless you can centralize and analyze it almost instantly. Picture a smart factory where sensors on a machine detect tiny vibrations that signal it’s about to fail.
With real-time synchronization, that sensor data flows straight to a central monitoring platform. An analytics model can immediately trigger an alert, getting a maintenance team on the job before the machine actually breaks down and causes expensive downtime. Without this live data flow, the warning signs would just be buried in a report hours later—long after the damage is done.
This explosion in connected devices is fueling a massive market for sync platforms. The edge data sync market, valued at $2.36 billion in 2025, is set to more than double to $5.16 billion by 2029. This growth is driven by the sheer scale of IoT, with global connections projected to jump from 18.8 billion in 2024 to 43 billion by 2030. You can dig into the numbers and trends driving this expansion on Research and Markets.
These examples from e-commerce, finance, and IoT are really just the tip of the iceberg. Real-time synchronization is also the engine behind personalized marketing campaigns, proactive supply chain management, and collaborative apps where everyone needs to see the same information at the same time. In every case, the principle is the same: turning data from a static, historical record into a dynamic, actionable asset.
Designing a Resilient Synchronization Architecture
Choosing the right tool for data synchronization is only half the battle. The real key to success lies in designing a smart, resilient architecture. Without a solid plan, your data pipelines can become brittle and unmanageable, no matter how powerful your software is.
A well-designed architecture is the foundation of a reliable business continuity strategy. It’s about building a system that anticipates failures and handles them gracefully, ensuring your data is always available and accurate, even when things go wrong.
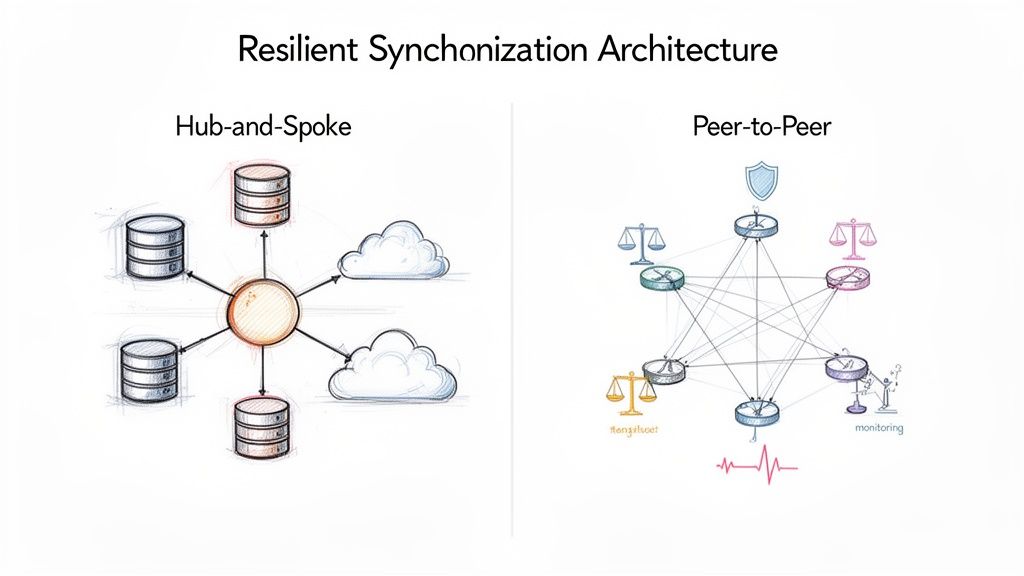
This means making deliberate choices about how your systems talk to each other and handle conflicts. Two of the most common patterns you’ll see in the wild are the hub-and-spoke and peer-to-peer models, each with its own set of trade-offs.
Choosing Your Synchronization Model
Your first big decision is picking a synchronization model. This choice fundamentally shapes how data moves between systems and how you deal with inevitable conflicts. The two main approaches offer very different ways to keep your data consistent.
- One-Way Synchronization: Think of this as a one-way street. Data flows from a single source of truth to one or more destinations. This unidirectional flow is perfect for things like replication of data from your production database to a data warehouse for analytics. The destination is strictly read-only, which keeps things simple.
- Two-Way Synchronization: This is a two-way street where traffic flows in both directions. Changes made in one system are pushed to all the others, and vice-versa. It’s a must-have for collaborative apps where multiple users need to update the same records, but it opens up a can of worms when it comes to resolving conflicting edits.
Your business needs will tell you which model to choose. A simple reporting pipeline can run perfectly well on a one-way sync. A complex customer service platform with multiple touchpoints, however, absolutely requires the complexity of two-way sync to function.
Common Architectural Patterns
Once you’ve settled on a model, you need to map out the communication routes. This is where architectural patterns come in, defining the actual network structure for your data flow.
Hub-and-Spoke Model
Imagine a wheel. In this model, a central hub is the master source of truth, and all other systems (the spokes) sync their data only with the hub. They never talk to each other directly. This centralized design makes management and conflict resolution much easier because the hub enforces a single set of rules. The obvious downside? If the hub goes down, everything stops.
Peer-to-Peer (P2P) Model
In a P2P setup, every system syncs directly with every other system. There’s no central boss. This makes the network incredibly resilient—the failure of one node doesn’t crash the whole system. The trade-off is complexity. As you add more systems, managing consistency and resolving conflicts across a web of independent nodes gets exponentially harder.
For most enterprise use cases, the hub-and-spoke model provides a more manageable and scalable foundation. The central hub offers a single point of control for monitoring, applying business logic, and ensuring data integrity across the organization.
The Role of Managed Streaming Platforms
Let’s be honest: building these architectures from scratch is a massive engineering lift. It takes deep expertise in distributed systems, message queues like Kafka, and stream processing. This is exactly where managed streaming platforms like Streamkap come in.
These platforms handle all that heavy lifting for you. Instead of wrestling with Kafka cluster configurations or managing Flink jobs, your data team can focus on what they do best: defining data flows and implementing business logic. Platforms like Streamkap take care of the fault tolerance, scalability, and day-to-day operations, which dramatically lowers the total cost of ownership (TCO) and lets you build reliable, real-time pipelines much faster.
7. Monitoring and Optimizing Your Synchronization Pipelines
Getting a data synchronization pipeline up and running is just the starting point. The real challenge is keeping it healthy, efficient, and reliable day in and day out. It’s the data equivalent of keeping the trains running on time.
Without a close eye on performance, even the best-designed pipelines can start to degrade. This leads to stale data, missed insights, and a slow, creeping loss of trust in your analytics. Effective monitoring isn’t about staring at a dashboard; it’s about tracking specific, actionable numbers that tell you exactly what’s going on.
This proactive approach moves you from constantly fighting fires to continuously fine-tuning your system, ensuring everyone in the organization gets the fresh, accurate data they depend on.
Key Metrics for Pipeline Health
To really understand how your pipeline is performing, you need to measure its speed, volume, and reliability. Think of these as the vital signs of your data flow. You don’t need dozens of metrics; just a few core ones will give you the most signal with the least noise.
Here are the essentials every data team should be watching:
- Data Latency: This is the big one. It’s the total time it takes for a change in the source system to show up in the destination. If this number starts to climb, the whole point of real-time sync is lost.
- Throughput: How much data is moving through the pipe? Usually measured in events per second or megabytes per minute, a sudden drop in throughput can be the first sign of a bottleneck or a source-side issue.
- Error Rate: This tracks the percentage of records that fail somewhere along the way. A rising error rate is a red flag, often pointing to corrupted data, network hiccups, or schema mismatches.
By tracking these metrics, you establish a baseline for what “normal” looks like. Once you know that, you can set up smart alerts that tell you when things are going wrong—long before they become a full-blown crisis that affects the business.
Diagnosing and Resolving Common Issues
So, what do you do when a metric veers into the red? The next step is playing detective to find the root cause.
A classic troublemaker is schema drift. This happens when someone changes the structure of the source data—adds a column, changes a data type—without updating the pipeline or destination. It’s a surefire way to break things.
Another common headache is a simple connection failure. The pipeline might lose contact with the source or destination temporarily. A well-built system should retry and recover on its own, but if failures keep happening, it’s time to investigate. Finally, as your data volume grows, you’ll inevitably run into bottlenecks, where one stage of the pipeline just can’t keep up, causing a traffic jam.
Setting up proactive alerts for these specific scenarios lets you jump on problems instantly. This keeps your data pipelines reliable and makes them a trustworthy asset, not a constant source of frustration.
Got Questions About Data Synchronization? We’ve Got Answers.
Even after you’ve got the basics down, a few tricky questions always pop up when you start thinking about how data synchronization will fit into your own systems. Let’s tackle some of the most common ones I hear from teams just getting started.
These are the details that often trip people up, so clearing them up now will save you a lot of headaches later.
What’s the Real Difference Between Data Synchronization and Data Replication?
It’s easy to see why these two get mixed up, but they solve different problems.
Think of data replication like making a high-quality photocopy. You’re creating an exact, one-way copy of your data somewhere else, usually for backup or to run analytics without touching the original. It’s a snapshot in time, a perfect replica.
Data synchronization, however, is more like a live, two-way conversation. It’s about making sure two or more independent systems are constantly kept in agreement. This often involves updates flowing in multiple directions and smart logic to handle any conflicts that might arise.
Simply put: Replication is about creating a static, identical copy. Synchronization is about maintaining a living, consistent state between active systems.
Will Change Data Capture Drag Down My Database Performance?
This is probably the number one concern, and a totally valid one. Nobody wants to slow down their production database. The good news is that modern Change Data Capture (CDC) is designed specifically to have a minimal impact on performance.
How? Instead of constantly hammering your database with queries to ask “what’s new?”, CDC quietly reads from the database’s transaction log. This log is a separate file that the database already uses to track every single change for its own recovery and consistency purposes. By tapping into this existing stream, CDC tools don’t interfere with the active queries serving your users. It’s an incredibly efficient, non-intrusive approach.
Can I Really Synchronize Data Between Different Kinds of Databases?
Absolutely. In fact, this is one of the most powerful use cases for modern data synchronization platforms. They act like a universal translator for your data.
You can, for example, stream changes directly from a row-based operational database like PostgreSQL into a columnar data warehouse like Snowflake or BigQuery. A good platform takes care of all the messy details under the hood, like:
- Schema Conversion: Translating the table structure from the source to a format the destination understands.
- Data Formatting: Mapping data types correctly (e.g., turning a timestamp into the right format).
- Decoupling: Creating a buffer that lets you swap out a source or destination later without having to rebuild the entire pipeline from scratch.
What Happens If the Network Goes Down in the Middle of a Sync?
Any serious synchronization platform is built for failure. This isn’t an “if,” it’s a “when.” Systems that use fault-tolerant technologies like Apache Kafka are perfectly designed for this.
When a change event is captured, it’s immediately written down and its position is bookmarked. If the network drops or a destination system goes offline, the process just pauses. As soon as the connection is back, it picks up right where it left off. This ensures zero data loss and guarantees that every last change makes it to the other side, no matter what happens in between.
Ready to move past slow, outdated batch ETL and embrace real-time streaming? Streamkap offers a managed, serverless platform built on Kafka and Flink that lets you build fault-tolerant data pipelines in minutes. Get real-time data synchronization without the operational headaches. Start your free trial today.