<--- Back to all resources
A Guide to the Modern Data Streaming Platform
Explore how a modern data streaming platform transforms business with real-time data. This guide covers core technologies, architecture, and use cases.
For a long time, the standard way to handle data was through batch processing.For a long time, the standard way to handle data was through batch processing. Businesses would collect information over hours or even days, bundle it up, and then run their analysis. But today, a data streaming platform makes those insights available the second data is created, letting companies act immediately. This move from delayed analysis to real-time action is completely reshaping how modern businesses operate.
Why Batch Processing Is Fading and Real-Time Is Now
Think of batch processing like old-school film photography. You’re at a live event, snapping pictures, but you can’t see anything until you take the roll to get developed. Hours or days later, you finally see the photos and realize you missed the perfect shot. You’re always looking at the past and reacting to what’s already happened.
Data streaming, on the other hand, is like having a live video feed. You see events as they unfold, giving you the power to adjust your angle, zoom in, and capture everything perfectly in the moment. That’s the fundamental difference: a legacy system gives you a historical report, while a modern data streaming platform offers a live, dynamic view of your entire business.
The High Cost of Stale Data
Working with stale data isn’t just an inconvenience—it’s a real business risk. When your information is hours or days old, you’re flying with blind spots that can lead to costly mistakes and huge missed opportunities.
Delayed data creates several critical problems:
- Poor Customer Experiences: If a customer abandons their shopping cart, you need to follow up now, not a day later after they’ve already bought from your competitor.
- Missed Revenue Opportunities: A sudden spike in demand for a product is a chance to adjust pricing, but only if you know about it instantly. By tomorrow, the opportunity could be gone.
- Slow Operational Reactions: Fraud detection systems running on a batch schedule might not catch a suspicious transaction until long after the money has vanished.
These issues are all tied to the inherent limits of batch processing. The latency built into scheduled ETL jobs creates an unavoidable gap between when an event happens and when you can act on it. You can learn more about these differences in our guide on batch processing vs. stream processing.
The Rise of Instant Data Delivery
The market is clearly voting with its feet, moving aggressively toward real-time solutions. The growth of the global data streaming platform market says it all. For instance, the video streaming industry, a major user of this technology, was valued at USD 129.82 billion in 2024 and is expected to skyrocket to USD 871.92 billion by 2034. North America is at the forefront of this trend, holding a 32% market share as companies adopt event-driven systems to power instant analytics and smarter decision-making. You can explore more statistics on the growth of streaming services.
This explosive growth points to a simple truth: in the current economy, speed is a serious competitive advantage. Data streaming platforms are the engines designed to provide that speed, directly solving the latency problems that have held back older systems for years. They are the foundation for a business that can react, adapt, and innovate on the fly.
Understanding the Core Technologies That Power Streaming
A modern data streaming platform isn’t just one piece of software; it’s a dynamic ecosystem of technologies working in perfect sync. Think of it like a biological nervous system, with specialized parts that capture, transport, and process information the instant it happens. To really get a handle on the power of real-time data, you have to understand how these four core pillars fit together.
At its heart, event streaming is the network itself. It’s the web of nerves carrying a constant flow of data signals—what we call events—from every part of your business. An event can be anything, really. A customer adding a product to their cart, a new reading from a factory sensor, or a log entry from a server are all events.
H3: Change Data Capture: The Sensory Receptors
The first hurdle is always getting data out of its source without causing a meltdown. That’s where Change Data Capture (CDC) comes in. Think of CDC as the nervous system’s sensory receptors—it’s designed to detect every single change in your source databases as it occurs.
Instead of running slow, clunky queries that can drag your production systems to a crawl, CDC taps directly into the database’s internal transaction log. This log is a complete, ordered record of every insert, update, and delete. By reading this log, CDC captures changes with almost zero impact, keeping your databases humming along. For a much deeper dive, check out our complete guide on what Change Data Capture is and why it’s so critical for real-time pipelines.
H3: Messaging Queues: The Reliable Spinal Cord
Once an event is captured, you need a bulletproof way to get it where it needs to go. This is the job of messaging queues, and the undisputed king here is Apache Kafka. A messaging queue is the spinal cord of your platform—a central, durable highway for all your event data.
It’s built to ingest staggering volumes of events from countless sources and sort them into logical streams called topics. From there, different applications and services can “subscribe” to the topics they care about to get the data they need. This brilliant design decouples the systems producing the data from those consuming it, which gives you a much more flexible and scalable architecture.
A key function of a messaging queue like Kafka is ensuring data durability and fault tolerance. Events are written to a distributed log, which means even if a consuming application goes down, the data remains safely stored and can be processed once the application is back online.
H3: Stream Processing: The Brain of the Operation
Finally, with all this data flowing, you need a way to actually make sense of it. This is where stream processing engines like Apache Flink come in. They are the brain of the operation. They don’t just sit there and receive data; they actively interpret, analyze, and act on it in real time.
This is where the real power shows up. A stream processor can perform incredibly complex operations on the fly:
- Real-Time Analytics: It can calculate running totals, live averages, and other key metrics as the data arrives, perfect for powering live dashboards.
- Event-Driven Actions: It can spot specific patterns or anomalies in the data—like a potentially fraudulent credit card swipe—and trigger an immediate, automated response.
- Data Transformation: It can enrich events by combining them with data from other streams, filter out noise, or re-shape the data to fit its final destination perfectly.
To really see how these components work together, let’s break them down with a simple analogy.
Core Components of a Modern Data Streaming Platform
This table summarizes the key technologies we’ve discussed and their specific roles within a streaming architecture.
| Technology | Role In The Platform | Analogy |
|---|---|---|
| Change Data Capture (CDC) | Senses and captures data changes at the source with minimal impact. | The nervous system’s sensory receptors (eyes, ears, etc.). |
| Messaging Queue | Reliably transports massive volumes of event data from producers to consumers. | The body’s spinal cord —a central, durable data highway. |
| Stream Processing | Analyzes, transforms, and acts on data in real time as it flows through the system. | The brain , making sense of signals and triggering actions. |
| Event Streaming | The overarching concept of continuous data flow that connects everything. | The entire nervous system , enabling communication. |
Together, these four technologies—CDC, event streaming, messaging, and stream processing—form a powerful, integrated system. Of course, this all relies on a solid foundation. This guide, for instance, explores the fundamental network requirements for high-performance streaming, highlighting why speed and low latency are non-negotiable. Ultimately, these components work in concert to create a continuous flow of information, turning raw events into actionable intelligence the moment they happen.
Architectural Patterns for Building Data Pipelines
Once you have the core technologies of a data streaming platform in place, the real work begins: figuring out how to piece them all together. Building a solid data pipeline isn’t just about plugging in different tools. It’s about following a proven design pattern that can handle growth, stay reliable, and run efficiently. The way you structure your data flow has a massive impact on everything from late-night maintenance calls to how quickly you can get insights to the people who need them.
Two main architectural patterns have really defined how companies process data: the Lambda Architecture and the more modern Kappa Architecture. Each takes a different stab at a common problem—balancing the need for up-to-the-second insights with deep historical analysis. Getting a handle on their differences is essential for picking the right foundation for your data strategy.
The Complexity of Lambda Architecture
The Lambda Architecture was one of the first serious attempts to solve a tough challenge: how do you process huge datasets and get low-latency, real-time views at the same time? It tackles this by essentially creating two separate, parallel data paths.
Think of it like a restaurant with two separate kitchens. One kitchen is for slow-cooking large, historical batches—the batch layer—making sure every single ingredient is perfectly accounted for over the long haul. The other is a fast-food counter—the speed layer—that serves up quick, fresh bites based on the latest orders. A final serving layer then combines the results from both kitchens to give you a complete meal.
This dual-path setup involves:
- Batch Layer: This is where all incoming data is stored in its raw format. Periodically, large batch jobs run to create complete and accurate historical views of the data.
- Speed Layer: This path processes data in real time as it arrives. It provides immediate but sometimes less complete views of the most recent events.
- Serving Layer: This layer merges the pre-computed views from the batch layer with the real-time updates from the speed layer to answer queries.
While it works, this approach brings a ton of complexity. You’re forced to build, manage, and debug two entirely different codebases for your processing logic. This can easily double the engineering effort and lead to nagging consistency issues between the two paths.
The Simplicity of Kappa Architecture
The Kappa Architecture came about as a direct response to the operational headaches of the Lambda pattern. It posed a simple but powerful question: what if we could do everything in a single, unified stream? Instead of splitting data into two paths, the Kappa Architecture treats everything as an event stream from the start.
This streamlined approach uses one stream processing engine to handle both real-time analytics and historical reprocessing. Need to recalculate something from the past? No problem. You just replay the event stream from an earlier point in time through the exact same processing logic.
By getting rid of the separate batch layer, the Kappa Architecture dramatically cuts down on system complexity. This means less code to maintain, fewer systems to manage, and a single source of truth for all data processing logic. The result is simpler development and a lower total cost of ownership.
This diagram shows how a modern data streaming platform organizes these functions into a unified stack, which aligns perfectly with the principles of the Kappa Architecture.
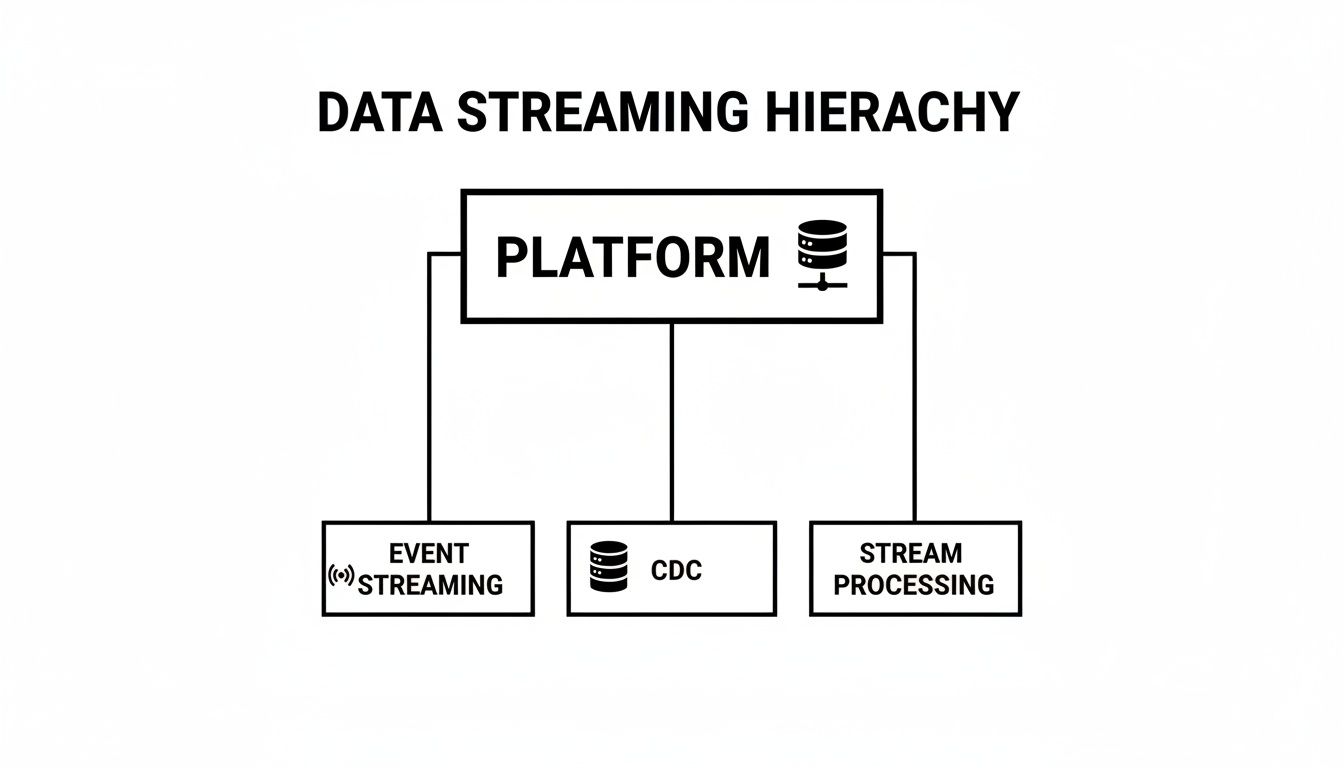
As you can see, a central platform integrates event streaming, CDC, and stream processing into one cohesive system. This avoids the messy, dual-path complexity of older models. While the best choice always depends on your specific needs, the industry is clearly shifting toward the operational simplicity of the Kappa pattern.
To dive deeper into these models, check out our detailed guide on data pipeline architectures.
Choosing Your Platform: Managed vs. Self-Hosted
One of the first big decisions you’ll face when diving into data streaming is whether to build the platform yourself or go with a managed service. This isn’t just a technical choice; it fundamentally shapes where your team spends its time, how you budget, and how quickly you can get real-time data flowing. It’s easy to get fixated on the initial price tag, but the real answer lies in looking at the entire picture of what it takes to run a high-performance streaming system 24/7.
A good way to think about it is this: the self-hosted, do-it-yourself (DIY) route is like building a custom race car from the ground up. You have absolute control over every single component, which is powerful. But it also means you need a crew of expert mechanics, a huge upfront investment in parts and tools, and you’re on the hook for constant, painstaking maintenance just to keep it on the track. It’s a project that never really ends.
On the other hand, a managed platform is like leasing a high-performance EV. You get all the incredible benefits—the instant acceleration, the advanced tech, the rock-solid reliability—without ever having to think about the complex engineering that makes it all work. The manufacturer handles all the updates, maintenance, and repairs. You just get to drive.
The True Cost of a DIY Platform
At first glance, self-hosting an open-source stack like Apache Kafka and Apache Flink seems like a bargain. After all, the software itself is free. But that’s just the tip of the iceberg. The Total Cost of Ownership (TCO) for a self-hosted platform almost always catches organizations by surprise as hidden costs start to add up.
And those costs go way beyond the initial setup:
- Hiring Specialized Talent: You’ll need a dedicated team of highly skilled—and expensive—engineers who live and breathe distributed systems like Kafka and Flink. Finding these specialists is tough, and it’s no wonder a recent report found that 68% of organizations struggle with inconsistent data, a problem that demands this exact kind of expertise to solve.
- Managing Infrastructure: You’re responsible for everything: provisioning servers, configuring networks, and maintaining storage. That includes all the patching, security hardening, and performance tuning, which is basically a full-time job for a whole team.
- Endless Operational Overhead: Your team will burn countless hours on monitoring, late-night troubleshooting, disaster recovery planning, and fixing things when they inevitably break. Every minute they spend on infrastructure is a minute they aren’t spending on building the products that actually make the company money.
Evaluating Key Decision Factors
When you’re weighing a managed service against a self-hosted setup, you need to be honest about the trade-offs. The right path really depends on your team’s current skills, your business goals, and how much operational pain you’re willing to tolerate. A clear-eyed evaluation now can save you from a world of hurt later on.
To make it clearer, here’s a head-to-head comparison of what you’re really choosing between.
Managed vs Self-Hosted Data Streaming Platform Comparison
This table breaks down the most important factors to consider when deciding between a fully managed service and a DIY solution.
| Consideration | Managed Platform (e.g., Streamkap) | Self-Hosted (e.g., Open-Source Kafka/Flink) |
|---|---|---|
| Time-to-Value | Rapid. You can have a production-ready pipeline running in hours or days, not months. | Slow. Requires extensive planning, hiring, development, and testing before launch. |
| Scalability | Automated. The platform scales elastically to handle traffic spikes without manual intervention. | Manual. Requires careful capacity planning and manual effort to add or remove resources. |
| Maintenance | Zero-Ops. All patching, updates, and security are handled by the provider. | Constant. Your team is responsible for all upkeep, including 24/7 on-call rotations. |
| Security & Governance | Built-in. Comes with enterprise-grade security features, compliance, and governance controls. | DIY. Security is entirely your responsibility, requiring specialized expertise to implement correctly. |
| Total Cost | Predictable. Subscription-based pricing makes budgeting straightforward. | High & Variable. Includes salaries, infrastructure, and hidden operational costs that are hard to predict. |
At the end of the day, the decision boils down to a simple, strategic question.
Do you want your best engineers spending their time keeping the lights on for a complex distributed system? Or would you rather they focus on using real-time data to build a competitive advantage?
By abstracting away the operational headaches, you free up your data teams to focus on innovation—building applications that directly grow revenue and create better customer experiences. For most companies, the speed, reliability, and predictable costs of a managed solution just make more sense.
Real-World Use Cases That Drive Business Value
Theory and architecture diagrams are great, but the real magic of a data streaming platform happens when you see it solving tough, high-stakes business problems. These platforms aren’t just about moving data around faster; they’re engines for creating immediate, tangible value. Whether it’s delighting customers or stopping fraud in its tracks, real-time data is the edge that separates the leaders from the rest.
Let’s get out of the weeds and look at some real stories of how data streaming directly impacts revenue, customer loyalty, and operational efficiency.
E-commerce Inventory Synchronization
Picture a huge e-commerce company in the middle of its biggest sale of the year. Thousands of orders are pouring in every second. With a traditional batch system, inventory levels might only get updated every fifteen minutes—or worse, every hour. In that time, the company could easily oversell a hot item, leading to a flood of canceled orders, angry customers, and a PR nightmare.
A data streaming platform completely flips that script.
- Real-Time Stock Levels: Every time a product is added to a cart, purchased, or returned, an event is generated and streamed instantly across the entire system.
- Instant Updates: The website, inventory databases, and warehouse management systems are all perfectly synchronized in milliseconds.
- No More Overselling: The second the last unit is sold, it’s immediately marked “out of stock” everywhere, cutting off new orders.
This isn’t just about damage control. This kind of accuracy allows for sophisticated, real-time promotions and flash sales, all while knowing the data is rock-solid. It builds enormous customer trust and protects the brand’s reputation when it matters most.
Financial Services Fraud Detection
In finance, speed is everything, especially when it comes to security. A batch-processing approach to fraud detection is dangerously outdated. It might review transactions in blocks, meaning a fraudulent purchase gets approved and the money is gone long before the system flags anything. By then, it’s too late.
Fintech leaders now use data streaming to fight fraud as it happens. When a credit card is swiped or a payment is initiated, that transaction becomes an event, instantly fed into a stream processing engine.
The platform can check the transaction against historical data, location information, and other live streams in just milliseconds. If it matches a known fraud pattern, the transaction is blocked before it ever goes through, saving millions in losses and protecting customers.
This proactive security is a powerful differentiator. It gives customers peace of mind, knowing their money is guarded by the most responsive technology out there.
Logistics and Supply Chain Optimization
For a global logistics firm, tiny inefficiencies snowball into massive costs. A driver’s route planned in the morning can become a total mess thanks to unexpected traffic, accidents, or bad weather. Sticking to static, pre-planned routes is a recipe for delays, wasted fuel, and unhappy customers.
Modern logistics run on a constant flow of real-time data.
- Live Data Ingestion: GPS data streams in continuously from every vehicle in the fleet.
- Data Enrichment: This location data gets layered with live streams from other sources, like traffic APIs and weather services.
- Dynamic Rerouting: A stream processing app crunches all this data to spot potential delays and automatically calculates a better route on the fly, sending updates straight to the driver.
This kind of dynamic optimization leads to huge fuel savings, better on-time delivery rates, and much happier customers.
The demand for these real-time capabilities is exploding everywhere. The adoption of data streaming has transformed business intelligence, with the live streaming market being a perfect example of the real-time demands that Streamkap solves with its CDC-powered synchronization. The global live streaming industry hit nearly $100 billion in 2024—a fourfold jump in just five years—and is on track to reach $345 billion by 2030.
Platforms like Twitch, which accounts for 61% of all live-streaming hours watched, and YouTube Live, used by 52% of viewers, depend on powerful data pipelines for everything from viewer analytics to ad targeting. It’s a clear showcase of the immense scale and necessity of managed streaming solutions. You can discover more insights about these live streaming trends and see the impact for yourself.
Letting Your Data—and Your Team—Reach Their Full Potential
After exploring all the complex architectures and patterns, a common thread emerges: engineering teams spend way too much time managing infrastructure and not enough time building things that matter. This is exactly where a managed data streaming platform changes the game. It’s designed to tackle the biggest headaches head-on: spiraling costs, mind-numbing operational complexity, and the development bottlenecks that kill momentum.
Opting for a zero-ops, managed service isn’t just a different path; it’s a strategic move to get value from your data faster. It takes the enormous effort of running distributed systems like Kafka and Flink off your plate. Think about it—no more 24/7 stress over patching, scaling, or troubleshooting. Your best engineers are freed up.
Shifting from Infrastructure Babysitting to Real Innovation
When you bring in a managed platform, you’re fundamentally changing what your data team works on. They can finally stop wrestling with cluster configurations and get back to what they do best: building the applications that actually move the business forward.
A DIY setup just can’t compete with the out-of-the-box advantages you get with a managed approach:
- Automated Schema Evolution: Data structures change. Instead of breaking your pipelines, a managed platform handles these shifts automatically, wiping out a huge source of maintenance pain.
- Limitless, Elastic Scalability: Need to handle a massive traffic spike? The platform scales up or down instantly without anyone lifting a finger. Performance stays solid, no matter what.
- Ready-Made Integrations: You get pre-built, fine-tuned connectors for top destinations like Snowflake, Databricks, and BigQuery. This turns what could be weeks of integration work into a few minutes of setup.
The core benefit is simple: a managed data streaming platform lets your organization stop pouring resources into just keeping the lights on. Instead, you can start using real-time data to build a real competitive advantage. Your data team becomes an innovation engine again.
Ultimately, this shift transforms how a business operates. The technical debt and surprisingly high total cost of ownership that come with self-hosted systems are replaced with predictable pricing and a much faster time-to-value. By eliminating all that operational friction, a managed solution like Streamkap finally unlocks what your data is capable of, letting you build smarter, more responsive applications faster than ever before.
Common Questions Answered
Diving into real-time data always brings up a few questions. Let’s tackle some of the most common ones we hear from teams exploring data streaming platforms.
How Is Data Streaming Different From ETL?
The biggest difference comes down to one word: timing.
Traditional ETL (Extract, Transform, Load) works in batches. It pulls data on a schedule—maybe once an hour or once a day—processes it all at once, and then loads it into a destination. It’s like getting your mail delivered once a day in a single bundle.
Data streaming, on the other hand, is continuous. As soon as a piece of data is created, it’s captured and processed. This real-time flow means you can act on information in seconds, not hours, closing the gap between an event happening and you knowing about it.
Isn’t This Just A Message Queue?
Not quite, though a message queue is a core part of the system. Think of a message queue like Apache Kafka as the superhighway for your data—it’s incredibly good at moving massive volumes of events from point A to point B reliably.
A true data streaming platform builds on top of that highway. It adds the “on-ramps” and “off-ramps,” like CDC for capturing database changes, and the “service stations,” like Apache Flink for processing and transforming the data while it’s in motion. It’s the complete, end-to-end solution.
A message queue is a core component. A data streaming platform is the entire integrated system, ready for sophisticated, real-time work right out of the box.
What’s The Real Business Impact Of Real-Time Data?
Having immediate access to data fundamentally changes how a business operates. Instead of looking in the rearview mirror at what happened yesterday, you can react to what’s happening right now.
Here’s what that looks like in practice:
- Fraud Detection: You can spot and block a suspicious transaction before the money ever leaves the account.
- Customer Experience: A customer adding an item to their cart can trigger an instant, relevant recommendation, not one that shows up in an email a day later.
- Smarter Operations: A logistics company can reroute drivers based on live traffic data, or a factory can adjust machinery based on real-time sensor readings to prevent a failure.
It’s about shrinking the time between insight and action, which is a massive competitive edge.
Are Data Streaming Platforms Only For Big Companies?
Not anymore. While huge enterprises were the first to build these systems, the game has completely changed with the rise of managed services. The barrier to entry has dropped dramatically.
Today, a small e-commerce brand can use real-time streaming to keep its inventory perfectly synced during a flash sale. A SaaS startup can power an in-app analytics dashboard without needing a dedicated team of data engineers to manage the backend.
Managed platforms handle all the heavy lifting of infrastructure and maintenance, making it financially and technically feasible for businesses of any size to compete on a level playing field.
Ready to stop wrestling with complex infrastructure and start innovating with real-time data? Streamkap offers a zero-ops, fully managed data streaming platform that puts your data to work instantly. See how Streamkap can simplify your data pipelines today.