Build a Modern Data Ingestion Pipeline from Scratch
Learn how to build a scalable data ingestion pipeline. Explore batch vs. streaming, CDC, and the key components for real-time data flows.
A data ingestion pipeline is the system that automatically grabs raw data from all your different sources and funnels it to a central spot for storage and analysis. Think of it as the circulatory system for your company’s data, making sure the vital information created in one place gets to where it can actually be used to make smart decisions. This process is the absolute bedrock of modern analytics, business intelligence, and machine learning.
What Is a Data Ingestion Pipeline
Picture a sophisticated logistics network for a massive online retailer. Raw materials—in this case, data—are constantly arriving from a dizzying number of suppliers, which could be anything from production databases and SaaS tools to IoT sensors. This network doesn’t just pile everything into a single warehouse. Instead, it meticulously sorts, checks, and directs each piece of information to the right destination, whether that’s a data warehouse or a lakehouse.
That automated, intelligent network is exactly what a data ingestion pipeline does for data.
It wasn’t always this smooth. In the not-so-distant past, moving data was a grueling, manual job. Analysts would spend hours exporting CSV files from different systems, wrestling with them in spreadsheets, and then uploading them whenever they got a chance. That old-school approach was painfully slow, riddled with human error, and just can’t function in today’s world of massive, fast-moving data.
The Shift to Automated Data Movement
Modern companies have to make critical decisions in minutes, not days. A delay in spotting fraudulent activity, understanding a new customer trend, or fixing a supply chain snag can lead to real financial losses and blown opportunities. Waiting for a report from last night or last week just doesn’t cut it anymore.
A data ingestion pipeline automates this entire flow, bringing some game-changing benefits:
- Speed: It moves data continuously, often in real-time, so you can analyze and act on it immediately.
- Reliability: Automation drastically cuts down on manual mistakes, making your data more consistent and trustworthy.
- Scalability: A well-designed pipeline can handle huge amounts of data from a growing list of sources without breaking a sweat.
A great data ingestion pipeline turns data from a static, historical artifact into a living, real-time asset. It’s the difference between driving by looking in the rearview mirror and having a live GPS guiding your every turn.
This leap from slow, periodic data dumps to a continuous flow of information is a massive change in how businesses operate. We’ve gone from asking, “What happened last quarter?” to “What’s happening right now?” This lets companies get ahead of the curve, adapting instantly to what the market and their customers are doing.
At the end of the day, a data ingestion pipeline is much more than just a technical utility for moving bits and bytes. It’s a strategic engine that fuels the analytics, machine learning models, and operational dashboards that define a modern business. By delivering a constant, reliable stream of fresh data, it powers faster, smarter decisions across the entire organization.
Choosing Your Approach: Batch vs. Streaming Ingestion
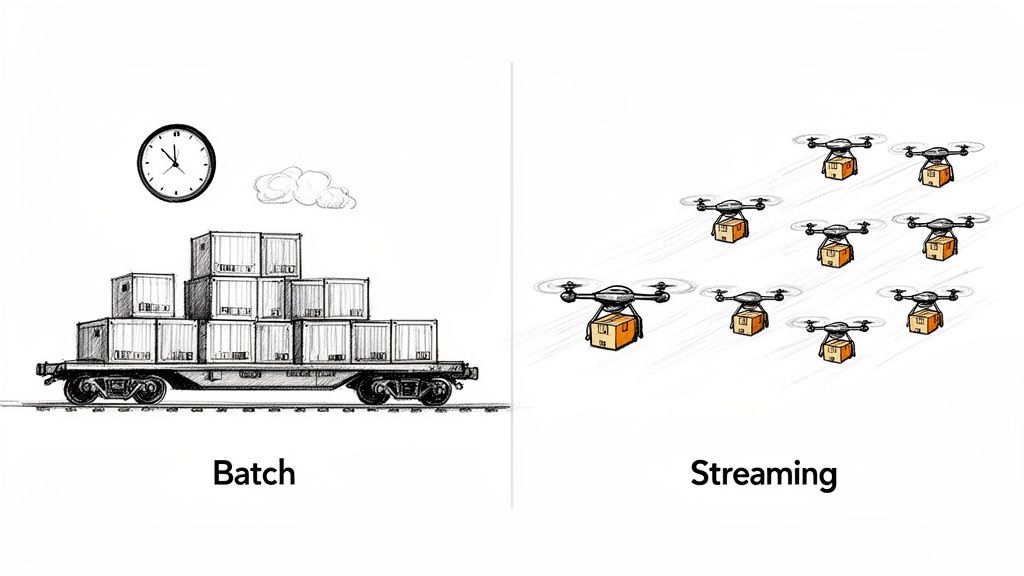
When you design a data ingestion pipeline, you’re immediately faced with a critical choice: do you move data in big, scheduled chunks (batch ingestion) or as a constant, live flow (streaming ingestion)? This isn’t just a technical detail—it’s a business decision that dictates how fast you can react and how current your insights will be.
Think of it this way: batch processing is like a freight train, while streaming is like a fleet of delivery drones. Both get the job done, but they’re built for completely different scenarios based on urgency and volume. Your data operates on the same principle.
Batch Data Ingestion: The Reliable Workhorse
Batch processing is the classic, time-tested method. It works by collecting data over a specific period—maybe every hour or once a day. When the time is up, it bundles everything into a large “batch” and processes it all at once.
This approach is incredibly efficient and cost-effective for handling huge datasets where real-time speed isn’t the priority. It’s the go-to for many foundational business operations.
Common use cases for batch ingestion include:
- Daily Sales Reporting: Crunching all of yesterday’s numbers to create an end-of-day report.
- Monthly Billing Cycles: Processing an entire month of usage data to generate customer invoices.
- Historical Trend Analysis: Loading years of data into a warehouse to spot long-term patterns.
The trade-off here is latency. By nature, batch data is historical. The insights are always a reflection of the past, not the present moment. If you’re weighing the pros and cons, this deep dive on batch processing vs stream processing can help clarify which is right for you.
Streaming Data Ingestion: Data in Real Time
Streaming ingestion is the modern alternative, built for the “now.” Instead of waiting to collect data, it processes each event or piece of information the instant it’s generated, moving it from source to destination immediately.
This gives you near-instant access to what’s happening, allowing your business to act on events as they unfold. The core benefit is incredibly low latency, which is non-negotiable for any system that needs up-to-the-second information.
Prime examples of streaming ingestion in action are:
- Fraud Detection: Spotting and blocking a suspicious credit card transaction in milliseconds, before the purchase goes through.
- Real-Time Inventory Management: Updating stock levels across your e-commerce site and physical stores the moment an item is sold.
- Live User Personalization: Tailoring product recommendations based on what a customer is clicking on right now.
To make the differences crystal clear, let’s look at a side-by-side comparison.
Batch vs Streaming Data Ingestion at a Glance
| Characteristic | Batch Ingestion | Streaming Ingestion |
|---|---|---|
| Data Scope | Large, bounded volumes | Individual events or micro-batches |
| Trigger | Scheduled (e.g., hourly, daily) | Event-driven (as data is created) |
| Latency | High (minutes to hours) | Low (seconds to milliseconds) |
| Throughput | High, optimized for bulk data | Varies, focused on speed |
| Cost | Generally lower per GB | Higher due to “always-on” nature |
| Ideal For | Analytics, reporting, payroll | Fraud detection, IoT, live monitoring |
Ultimately, the best choice is dictated by your business needs. While batch is a cost-saver for large, non-urgent workloads, the competitive edge that comes from real-time data often makes streaming a worthwhile investment. Many companies end up using a hybrid model: batch for deep historical analysis and streaming for immediate, operational decisions.
The Power of Real-Time Data and CDC
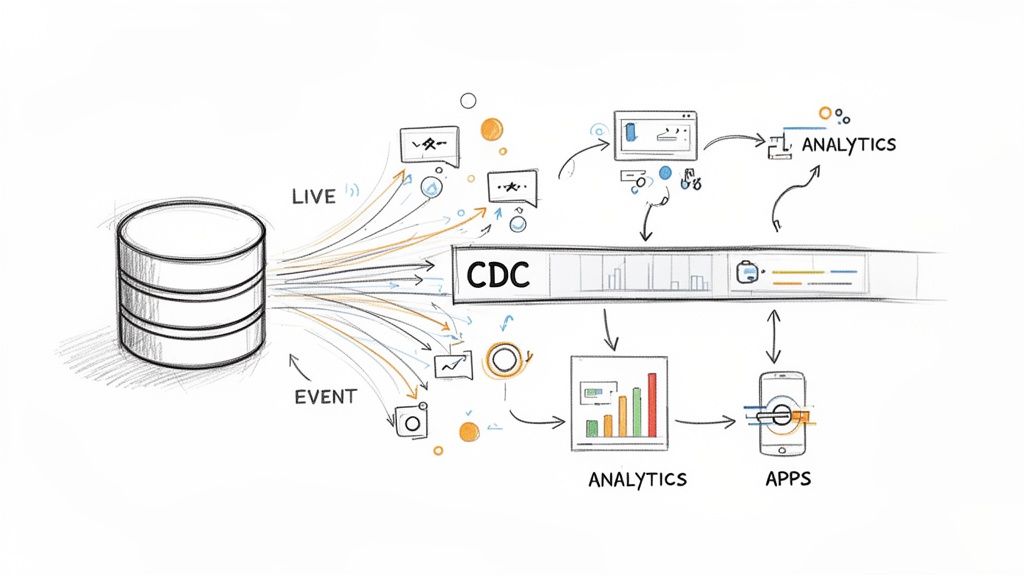
Sure, batch processing is still a solid, cost-effective choice for historical analysis. But in today’s world, businesses need instant answers. Whether it’s feeding generative AI the freshest context or personalizing a user’s experience on the fly, acting on data the moment it’s created isn’t just a nice-to-have—it’s a core requirement for staying competitive.
This is where streaming architectures come into their own. The big challenge, though, has always been how to spot new information without constantly hammering your source systems. The old way involved repeatedly querying a database, essentially asking, “Anything new yet? How about now?” This method, called polling, is terribly inefficient and puts a massive strain on production databases, often grinding them to a halt.
Introducing Change Data Capture
Enter Change Data Capture (CDC), the elegant solution that makes efficient, real-time data ingestion a reality. Instead of constantly asking for updates, CDC cleverly taps into the database’s transaction log—the internal, behind-the-scenes record of every single change (insert, update, or delete).
Think of CDC as a live news feed for your database. You subscribe once, and from that point on, you get an instant notification the moment any data changes. This event-driven approach is a game-changer for building a modern data ingestion pipeline. You can get a much deeper look into how this works in our guide on what is Change Data Capture.
By listening to the database’s internal log, CDC captures every event without placing any significant load on the source system. It’s the difference between calling a friend every five minutes to ask for news versus getting a text the second something important happens.
This method completely sidesteps the performance-killing queries of polling, ensuring your operational databases stay fast and responsive for the applications that depend on them. It’s the engine that powers modern, event-driven architectures and a foundational concept for any organization serious about using its data effectively.
Why CDC Is Essential for Modern Pipelines
The benefits of using CDC are about much more than just reducing database load. It opens up a whole new world of possibilities for pipeline design and reliability. Here’s why it has become so vital:
- Minimal Latency: CDC captures changes in milliseconds, giving you the near-instantaneous data needed for real-time applications like fraud detection, dynamic pricing, and live inventory management.
- Guaranteed Data Integrity: Because it reads directly from the transaction log, CDC captures every single change in the exact order it happened. This eliminates the risk of missing updates that can easily happen between the polling intervals of a batch system.
- Resource Efficiency: By avoiding expensive, full-table scans or constant queries, CDC drastically lowers the computational overhead on your source systems. This leads to more stable operations and, frankly, lower costs.
This shift toward real-time data ingestion pipelines is a huge deal, driven by fully managed, event-driven platforms with native CDC support. Companies like Confluent Cloud and Striim are leading the way, making it easier to connect databases, cloud stores, and AI feature stores for low-latency machine learning.
This evolution is a key reason the data pipeline tools market is projected to see a 21.8% compound annual growth rate, jumping from $11.24 billion in 2024 to $13.68 billion in 2025. The demand is clearly centered around real-time processing and cutting down data latency.
Ultimately, CDC transforms the data ingestion pipeline from a clunky, periodic chore into a smooth, continuous, and automated flow. It provides the fresh, reliable stream of data needed to power the most demanding analytics and operational systems, allowing businesses to react to opportunities and threats as they happen—not hours or days later.
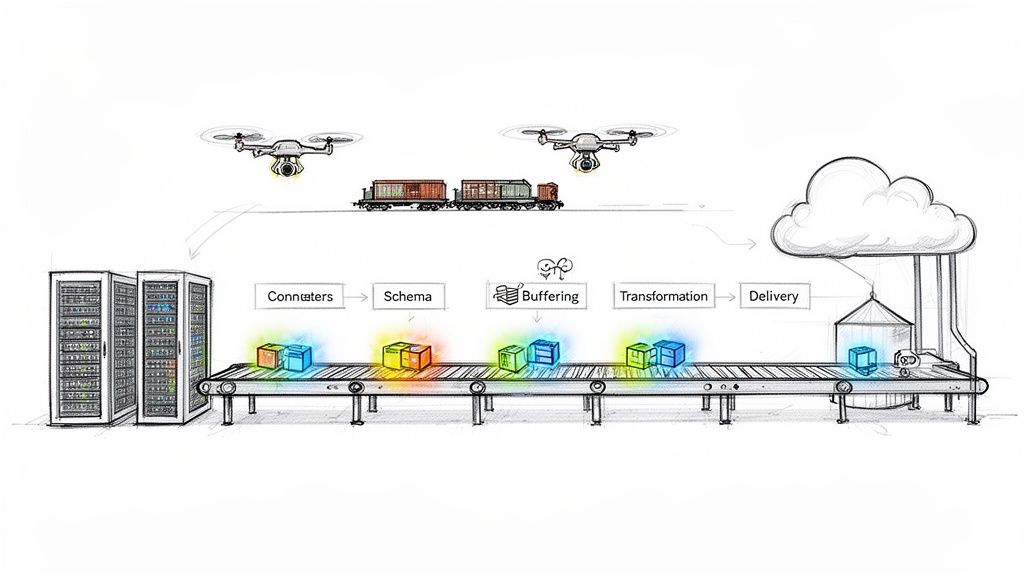
Anatomy of a Modern Data Ingestion Pipeline
Think of a modern data ingestion pipeline as a highly efficient assembly line, but for data. Raw, unprocessed information comes in one end, and a valuable, business-ready asset rolls out the other. Each station on this line has a specific job, and understanding these individual components helps show how they all work together to create a smooth, reliable data flow.
It all starts with getting the raw materials. Just like a factory needs parts from different suppliers, a pipeline needs to pull data from all sorts of systems. This is where connectors come into play.
Sourcing Data with Connectors
Connectors are the specialized workers on our assembly line, each one trained to get materials from a specific supplier. One might pull data from a PostgreSQL database, another from Salesforce, and a third from a fleet of IoT devices. Every source has its own quirks, formats, and ways of communicating.
Instead of writing custom code for every single source, connectors act as pre-built integrations that know how to handle these complexities. They reliably extract data, which means a good pipeline can easily adapt whenever the business needs to tap into a new source.
Ensuring Quality with Schema Management
Once the raw data arrives, it heads straight to quality control. In the world of data pipelines, this is schema management. A schema is simply the blueprint for your data—it defines the columns, data types, and how everything is structured. Problems start when a source system suddenly changes this blueprint, like adding a new field or altering an existing one. That kind of unexpected change can break everything downstream.
Good schema management acts like an alert supervisor. It automatically spots these changes (a process called schema evolution) and adapts the pipeline on the fly. This prevents data from getting lost and keeps the assembly line from grinding to a halt, ensuring every piece of data fits the expected structure before moving on.
For a deeper dive into overall pipeline design, check out our guide on data pipeline architecture.
Preventing Jams with Buffering
Any busy assembly line can get overwhelmed. A sudden surge in website traffic or a massive dump of sensor data can create a serious bottleneck. This is why we have buffering, which works like a temporary staging area to manage these spikes.
This component, often a system like Apache Kafka, holds incoming data in a queue. This allows the rest of the pipeline to pull data at a steady, manageable pace instead of being flooded all at once. It’s a simple concept that makes the whole system more resilient, preventing data loss and separating the source from the destination.
Refining Data with Transformations
With the data sorted and staged, it’s time for refinement. This is where transformations turn raw, messy data into something clean, consistent, and genuinely useful.
You’ll see a few common types of transformations:
- Filtering: Stripping out irrelevant or sensitive information, like PII.
- Enrichment: Adding more context by merging data from another source.
- Normalization: Standardizing formats, like making sure all dates follow the same ISO 8601 convention.
- Aggregation: Summarizing data, like rolling up individual transactions into a daily sales total.
A key part of this process is being proactive about data quality. Understanding and avoiding common data validation mistakes is crucial for ensuring the final output is trustworthy.
Finalizing with Data Delivery
The last stop is the shipping department. Data delivery is all about loading the fully processed, business-ready data into its final home. This could be a cloud data warehouse like Snowflake, a lakehouse like Databricks, or even a real-time analytics dashboard.
This final component makes sure the data lands safely, correctly, and efficiently, completing its journey from a raw event into a valuable insight.
Designing for Scale and Reliability
Getting a data ingestion pipeline up and running is one thing. Making sure it can handle the chaos of real-world production without breaking is another challenge entirely. A pipeline that silently drops data or collapses under a traffic spike isn’t just a technical glitch; it’s a direct threat to the business. To build something you can actually trust, you have to design for scale and reliability from day one.
This is where the idea of operational excellence comes in. It’s not just a buzzword. It’s the set of practices and tools that act as the mission control for your data, ensuring everything just works. Without it, even the cleverest pipeline is basically a ticking time bomb.
The Pillars of a Resilient Pipeline
To build a system that can take a punch, you need to bake in three core disciplines. Think of them as the legs of a stool—if one is weak, the whole thing topples over. Together, they turn a fragile process into a genuinely fault-tolerant system.
- Monitoring: This is your command center. Good monitoring gives you a live feed of your pipeline’s health. You’re tracking critical metrics like data latency (is my data fresh?), throughput (how much is flowing through?), and error rates. It’s how you spot trouble before it spirals out of control.
- Alerting: Things will go wrong. It’s inevitable. When they do, you need to know immediately. Alerting is the automated alarm that pages the right person when a metric crosses a dangerous threshold, like a sudden nosedive in data volume or a surge in processing failures.
- Governance: This is the rulebook that keeps your data safe and sound. It defines who gets to touch the data, how it’s handled to comply with regulations like GDPR, and what the standards are for quality and lifecycle management. It’s what ensures integrity from start to finish.
This is the fundamental flow that a reliable pipeline has to manage, day in and day out.
As data moves from all its different sources, through the pipeline, and into its final home, every single step needs to be watched for potential problems.
Planning for Common Failure Scenarios
Here’s a secret: a reliable pipeline isn’t one that never fails. It’s one that expects to fail and knows exactly how to handle it. You have to design for the messy reality of production. Since today’s pipelines often live in the cloud, having deep expertise in developing in the cloud is crucial for building systems that are both scalable and resilient.
So, what kind of disasters should you be planning for?
- Source Schema Changes: What happens when an upstream team adds a new column to a database table or changes a field from an integer to a string? A brittle pipeline will crash. A resilient one will detect the schema drift, alert you, and adapt on the fly without breaking.
- Network Hiccups: The network is not reliable. Connections will drop. Your system needs to have built-in retry logic and buffering to gracefully handle these temporary interruptions without losing a single byte of data.
- Bad Data In, Bad Data Out: Sometimes a source system just sends junk—corrupted records, incomplete fields, you name it. A smart pipeline has validation checkpoints that can identify and quarantine this “bad” data for review instead of letting it poison your data warehouse.
A truly scalable and reliable pipeline is designed with the assumption that things will break. Its strength lies not in avoiding failure, but in its ability to recover from it gracefully and predictably.
By making monitoring, alerting, and governance a core part of your design—and by planning for the inevitable failures— you build a system that delivers trustworthy, timely data, no matter what surprises production throws at it.
Why Old-School Data Pipelines Are Budget Killers
A data pipeline is supposed to be a core asset, but for many companies, it ends up being a financial black hole. Costs can spiral out of control, especially with traditional pipelines built on older architectures or clunky, self-managed systems. Before you know it, what was meant to be a strategic investment is just a massive, unpredictable line item that gives your CFO a headache.
The root of the problem is often a tangled mess of usage-based pricing models. Think about it: your cloud data warehouse, your ingestion tools, your processing engines—many of them bill you for compute time, the volume of data you push through, or the number of rows scanned. This ties your costs directly to your data growth, making your budget a moving target. A successful marketing campaign or a new feature launch can suddenly cause your monthly bill to skyrocket without warning.
The Hidden Costs That Really Sting
What you pay for the tools is just the tip of the iceberg. The real damage to your budget comes from the Total Cost of Ownership (TCO), which is loaded with hidden operational costs that most people don’t consider when they’re signing the initial contract.
These are the expenses that sneak up on you:
- Engineering Time Sinks: Your data engineers end up spending a huge chunk of their time building one-off connectors, untangling broken scripts, and manually dealing with schema changes. This isn’t just about salaries; it’s a massive opportunity cost. Your most skilled people are stuck doing plumbing work instead of building things that create real value.
- Infrastructure Babysitting: If you’re running self-hosted systems like Kafka or Flink, you need a dedicated team just to keep the lights on. They’re constantly patching, scaling, and troubleshooting to maintain uptime. Those infrastructure and personnel costs add up fast.
- The Price of Failure: When a brittle, legacy pipeline inevitably breaks, the fallout can be brutal. You’re not just dealing with the cost of downtime—you’re looking at lost revenue, eroding customer trust, and pulling everyone into an “all-hands-on-deck” fire drill to fix it.
The true cost of a traditional data pipeline isn’t just the software license. It’s the sum of all the hours spent on maintenance, the late-night firefighting, and the innovative projects that never get off the ground because your team is always busy fixing what’s broken.
Making the Financial Case for a Modern Approach
This isn’t an isolated problem; it’s a widespread pain point. Cost management has become one of the biggest challenges for data teams trying to manage an overly complicated tech stack. A recent survey highlighted just how serious the issue is: 44% of organizations are spending between $25,000 and $100,000 every single month on their data infrastructure, with usage-based tools eating up most of that budget.
What’s really shocking is that only 12% feel they’re getting a good return on that investment. It’s no surprise, then, that 41% are actively looking to consolidate their tools to rein in spending. You can dig into the details in the full report on the current state of data pipeline costs.
This is where modernizing your data ingestion comes in. By moving to efficient, fully managed solutions, you tackle these financial issues head-on. You offload the operational headaches and shift to a more predictable cost model. This doesn’t just lower your TCO—it frees your engineers to focus on work that actually moves the needle for the business. A smarter pipeline isn’t just a technical choice; it’s a strategic move toward a healthier bottom line.
Common Questions About Data Ingestion Pipelines
Getting data from point A to point B sounds simple, but as anyone in the field knows, the devil is in the details. When you’re building a new data ingestion pipeline or trying to improve an existing one, a handful of questions almost always come up. Let’s tackle some of the most common ones.
What’s the Difference Between a Data Pipeline and an ETL Pipeline?
This is a great starting point because the terms are often used interchangeably, but they aren’t the same thing.
Think of a data pipeline as the big picture—it’s any and every process that moves data from a source system to a destination. It’s the entire network of roads that data can travel on.
An ETL (Extract, Transform, Load) pipeline is just one specific type of data pipeline, like a particular route on that road network. In the classic ETL model, data is pulled out of a source, cleaned up and reshaped in a staging area, and then loaded into its final home, like a data warehouse. Increasingly, you’ll see this flipped to ELT (Extract, Load, Transform), where raw data gets loaded first, and the heavy lifting of transformation happens inside the powerful destination warehouse itself.
How Do I Choose the Right Data Ingestion Tool?
There’s no magic bullet here; the “best” tool is the one that fits your reality. Your business goals and technical constraints will guide you to the right choice. To narrow it down, ask yourself a few critical questions:
- How fast do you need the data? Is a daily batch dump good enough for your reports, or do you need up-to-the-second data powered by Change Data Capture (CDC) for real-time dashboards?
- Who is going to run this thing? Do you have an engineering team ready to manage the infrastructure (self-hosted), or would you rather offload that work to a fully managed platform?
- What does your tech stack look like? You need a tool with solid, pre-built connectors for your specific databases, SaaS apps, and data warehouses. Reinventing the wheel is no fun.
- What can your team realistically handle? A tool with a steep learning curve can stall a project for months. An intuitive, easy-to-use platform can mean the difference between a quick win and a long slog.
If your team is focused on real-time insights and wants to avoid getting bogged down in infrastructure management, a fully managed, CDC-based platform is almost always the straightest line to getting value from your data.
What Are the Main Challenges in Managing Data Pipelines?
Frankly, the biggest challenge is keeping the pipeline trustworthy and reliable. It’s one thing to build a pipeline; it’s another to keep it running smoothly day after day. The most common headaches usually boil down to a few key areas:
The primary challenges include ensuring data quality and accuracy, handling changes in data structure over time (schema evolution), preventing data loss during failures, scaling to accommodate growing data volumes, and controlling operational costs.
The secret isn’t building a pipeline that never breaks—because they all do eventually. The secret is building a resilient one. That means having proactive monitoring to spot trouble early, smart error-handling to prevent data loss when things go wrong, and solid governance to keep everything in check. A great pipeline isn’t one that’s perfect; it’s one that can handle imperfections gracefully.
Ready to build a real-time data ingestion pipeline without the operational headache? Streamkap offers a fully managed platform powered by Kafka and Flink, enabling you to stream data instantly with zero operational burden. Replace complex batch jobs with a simple, cost-effective streaming solution. Learn more at Streamkap.
Related resources
Real-Time Data Pipelines for AI Agents: Architecture, Patterns, and Implementation Guide
A practical guide to building real-time data pipelines that feed AI agents with fresh context. Covers architecture patterns, streaming transforms, and step-by-step implementation.
The Startup Guide to AI Agents: Ship Your First Real-Time Agent in a Weekend
A step-by-step guide for startup teams to build their first AI agent powered by real-time streaming data. Go from zero to a working agent in a weekend.
How to Give Your AI Agent Real-Time Database Access
Step-by-step guide to connecting AI agents to live database data using CDC and MCP. Build agents that act on current state, not stale snapshots.