FAQ Apache Iceberg
Oli Dinov
July 1, 2025
TL;DR
• Apache Iceberg is an open table format that adds ACID transactions, schema evolution, and time travel to data lakes on S3/ADLS/GCS. • Iceberg unifies batch and streaming workloads-Netflix uses it at petabyte scale for both historical and streaming analytics. • Query historical states for auditing, evolve schemas without rewriting data, and use hidden partitioning for flexible data organization.
Table of Contents
How to connect Streamkap to Apache Iceberg?FAQ Apache Iceberg
What is Apache Iceberg, exactly?
Apache Iceberg is an open table format that makes files in your lake behave like real database tables. It adds ACID transactions, schema and partition evolution, time travel, and table-level metadata—without leaving S3/ADLS/GCS.
How does Apache Iceberg unify lakes and warehouses?
By giving you atomic, isolated table updates for both batch and streaming. The same table can serve BI, ML, and real-time jobs without brittle glue code. (Example: Netflix uses Iceberg at petabyte scale to unify historical and streaming analytics.)
Is Apache Iceberg cloud-native?
Yes. Iceberg is designed for object storage. It uses rich metadata (manifests, partition stats) to prune scans, so engines touch only the files they need—cutting latency and cost. (Example: Expedia runs Iceberg on S3 for cost-efficient travel analytics.)
Will Apache Iceberg fit my stack?
It’s vendor-neutral and widely integrated: Spark, Flink, Trino/Presto, Kafka (ingest/CDC), plus a growing ecosystem of query engines and orchestration tools. You’re not locked into one vendor or runtime.
Can Apache Iceberg handle real-time and CDC?
Yep. Streaming upserts and incremental planning let you land CDC from Kafka/Flink and query fresh data with low latency—while keeping the canonical table in your lake.
What about flexibility as needs evolve?
Iceberg’s metadata-driven design supports hidden partitioning and painless evolution (e.g., daily → hourly) without rewriting queries. Compaction/optimization jobs keep small files in check and storage costs under control.
How does Iceberg support Time Travel?
Iceberg’s immutable snapshots enable you to query historical states for auditing or debugging purposes.
Example:Note: Remember to expire snapshots to manage metadata.
Can I evolve my schema with Iceberg?
Yes. You can add, drop, or change columns without rewriting any data.
Example:
What is Hidden Partitioning?
This feature allows you to define partitions using metadata, so they can evolve without needing to migrate the data.
Example:
Use Case: Optimize streaming data pipelines by switching to hourly partitions.
Does Iceberg support ACID transactions?
Yes. Iceberg ensures data integrity even with concurrent writes.
Example:
How does Iceberg handle Row-Level Operations?
With support for both Merge-on-Read (MoR) and Copy-on-Write (CoW), Iceberg handles Change Data Capture (CDC) with equality deletes.
Example:
Use Case: Perform real-time transaction updates for financial systems.
How is metadata managed in Iceberg?
The hierarchical metadata scales with various catalogs like Rest, AWS, and Hive. You can learn more at the Iceberg documentation on catalogs.
How does Iceberg improve performance?
Iceberg improves performance through data compaction, which merges small files.
Example:
What are branching and tagging?
Iceberg supports isolated writes through branching and tagging.
Example:
How does Iceberg handle streaming data?
Iceberg unifies batch and streaming, allowing you to build real-time data lakes.
Example:
How to connect Streamkap to Apache Iceberg?
- Tutorial: MySQL → Iceberg – Enable CDC in MySQL, connect it in Streamkap, and stream changes directly into Iceberg tables.
- Documentation: Explore the official guides to master every detail of your Streamkap–Iceberg pipeline.
- Sign up: Create your Streamkap account now and start moving data in minutes.
Oli Dinov
LinkedInAuthor Bio
Product Marketing Manager at Streamkap
Published
July 1, 2025
TL;DR
• Apache Iceberg is an open table format that adds ACID transactions, schema evolution, and time travel to data lakes on S3/ADLS/GCS. • Iceberg unifies batch and streaming workloads-Netflix uses it at petabyte scale for both historical and streaming analytics. • Query historical states for auditing, evolve schemas without rewriting data, and use hidden partitioning for flexible data organization.
Related blog posts

Batch Processing vs Real-Time Stream Processing
There is a big movement underway in the migration from batch ETL to real-time streaming ETL but what does that mean? How do these methods compare? While real-time data streaming has many advantages over batch processing, it is not always the right choice depending on the use case so let's take a loo
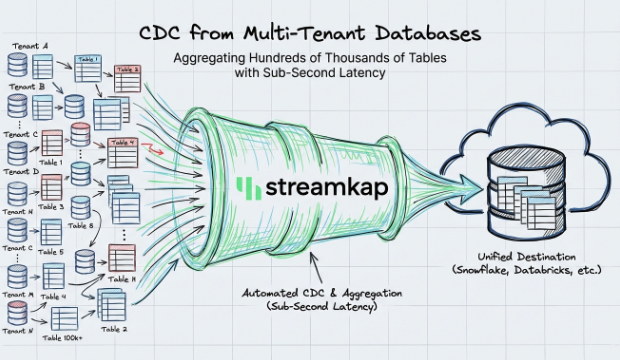
CDC from Multi-Tenant Databases with Sub-Second Latency
How Streamkap handles CDC at scale across multi-tenant databases with thousands of schemas, delivering sub-second latency without managing Kafka or Flink.

Change Data Capture for Streaming ETL
Change Data Capture refers to the process of capturing changes made to data in a source system such as a database, so that these change events can be used in the destination system, such as a data warehouse, data lake, data app, machine learning models, indexes, or caches.