<--- Back to all resources
What is message queuing: A Guide to Resilient, Scalable Apps
What is message queuing and how does it power resilient, scalable apps? Learn core concepts, real-world use cases, and essential patterns.
At its heart, message queuing is a way for different parts of a software application to talk to each other without having to wait for an immediate response. It’s a form of asynchronous communication that uses a middleman—the queue—to hold onto messages until the receiving service is ready to deal with them.
This setup prevents system overloads by breaking the direct link between the message sender and the receiver. It’s like a digital mailroom for your software, creating applications that are far more resilient and scalable.
Understanding Message Queuing With a Real-World Analogy
Let’s step into a busy coffee shop during the morning rush. If every customer just yelled their order directly at the baristas, it would be pure chaos. Orders would get lost, the baristas would be completely overwhelmed, and the whole operation would quickly grind to a halt.
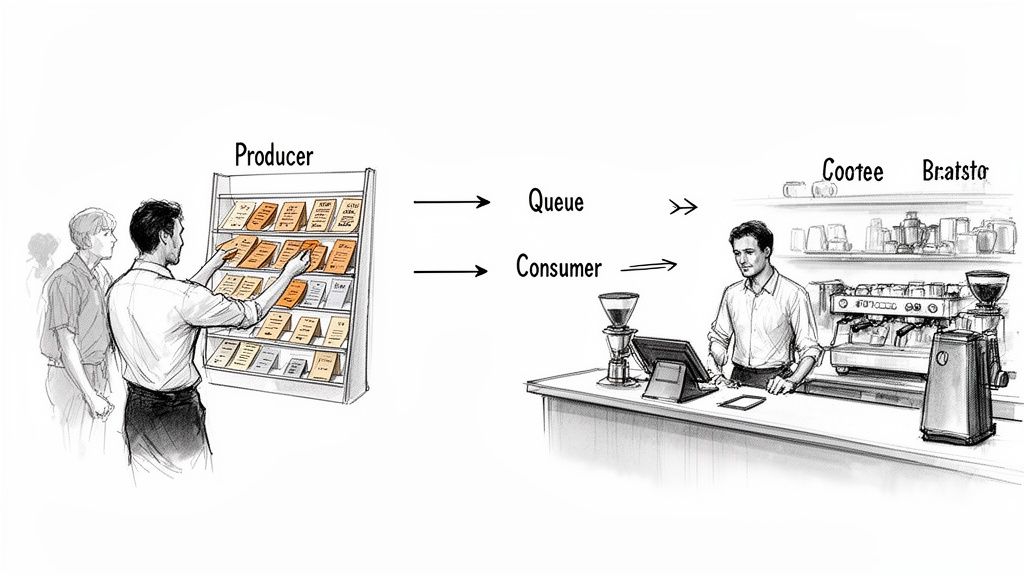
Instead, coffee shops use a simple, elegant system. The cashier takes an order, writes it on a ticket, and sticks it on a rail. That ticket is a message. The cashier who creates it is the producer. The baristas who grab the tickets to make the drinks are the consumers. And that ticket rail holding all the orders? That’s the message queue.
This familiar system brings a few key benefits that map perfectly to how modern software is built.
Decoupling the Producer and Consumer
In our coffee shop, the cashier (producer) has no idea which specific barista (consumer) will make the drink. They just add the ticket to the queue and are free to take the next customer’s order right away. Meanwhile, the baristas can work at their own pace, pulling tickets from the queue whenever they’re ready.
This separation is what we call decoupling. In the software world, it means the service sending a task (like “process this payment”) doesn’t have to sit around waiting for the processing service to finish. It can just drop the task into a queue and get back to other work, making the entire application feel much snappier to the end-user.
Enhancing Reliability and Resilience
Now, what if a barista has to stop to refill the espresso machine? With a queue in place, the cashier can keep taking orders and lining them up. No orders are lost. As soon as the machine is ready, the baristas can pick up right where they left off. The queue acts as a critical buffer, ensuring nothing gets dropped.
A message queue provides a temporary, reliable storage for messages. If a consumer service fails or needs to restart, the messages remain safely in the queue, ready to be processed once the service is back online. This prevents data loss and makes the entire system more fault-tolerant.
This simple analogy brings the core ideas of message queuing to life:
- Asynchronous Communication: Services don’t need to be available at the exact same time to communicate.
- Load Balancing: The queue naturally smooths out sudden spikes in demand, preventing services from getting overwhelmed.
- Scalability: If the line of tickets gets too long, you can just add more baristas (consumers) to clear the queue faster, all without changing the cashier’s workflow.
Breaking Down the Core Components of a Message Queue
Alright, let’s move past the coffee shop analogy and get into the technical nuts and bolts. To really understand message queuing, you need to know the three key players that make the whole system tick. These components work together to build that powerful, asynchronous communication backbone essential for modern applications.
Each piece of this puzzle has a specific job, making sure messages are created, stored safely, and eventually acted upon—no matter what the other services are doing.
The Producer
First up is the producer. This is simply the application or service that kicks things off by creating and sending a message. Its only job is to bundle up some data, format it into a message, and fire it off to a specific queue or topic managed by the broker.
Think about an e-commerce site. When you click “Buy Now,” the web application acts as the producer. It generates a message with all your order details—product IDs, quantities, shipping address—and sends it to a queue, let’s call it new-orders. The moment that message is sent, the web app can show you a confirmation page and move on to the next customer. It doesn’t know or care who processes the order or when; its work is done.
The Consumer
On the receiving end, we have the consumer. This is the application or service that connects to the queue, pulls messages off it, and does the actual work. In our e-commerce scenario, a separate “Order Fulfillment Service” would be the consumer.
This service connects to the new-orders queue, grabs a message, and gets busy:
- It updates the inventory database.
- It processes the credit card payment.
- It sends a notification to the warehouse to start packing the box.
Because the producer and consumer are completely separate, you can have multiple consumers working on the same queue. If orders start piling up during a flash sale, you just spin up more instances of the Order Fulfillment Service. They all pull from the same queue, clearing the backlog in parallel. That’s scalability in action.
The Message Broker
The message broker is the heart of the operation. It’s the intermediary software that manages the queues, accepts messages from producers, stores them reliably, and hands them off to consumers when they’re ready. It’s the dependable middleman that ensures nothing gets lost in transit.
Think of the broker as more than just a mailbox. It’s an intelligent hub that handles complex routing, message durability, and delivery confirmations. It guarantees that if a consumer service crashes mid-task, the message is safely kept in the queue, waiting for the service to come back online or for another consumer to pick it up.
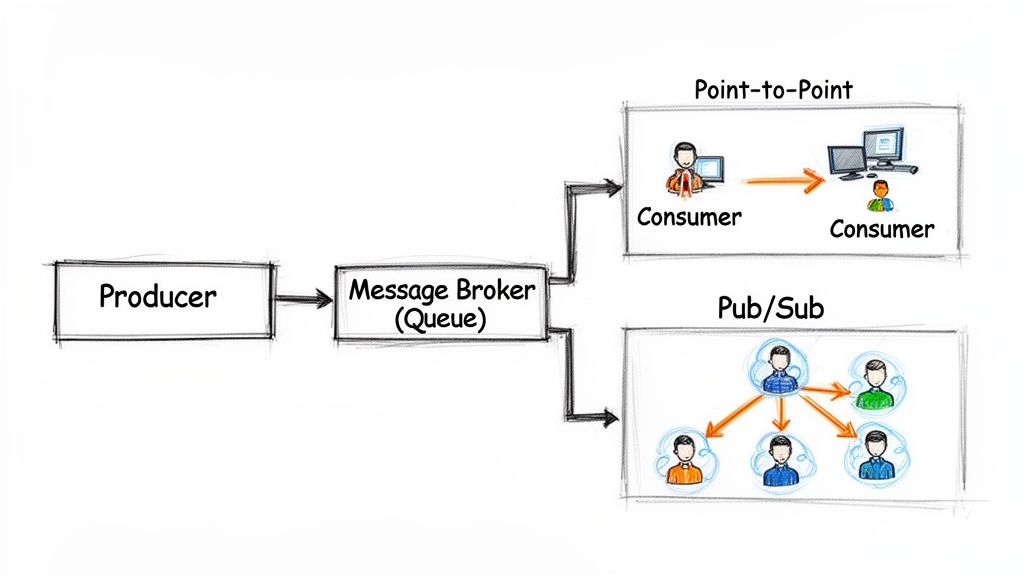
Communication Models: Point-to-Point vs. Publish/Subscribe
Brokers generally operate using two main communication patterns, each suited for different jobs.
-
Point-to-Point (P2P): In this classic model, a message from a producer is delivered to exactly one consumer, even if several are listening. This is perfect for task-oriented work where a job must be done only once—think processing a payment or updating a single user’s profile. Each message is a unique piece of work for a single worker.
-
Publish/Subscribe (Pub/Sub): Here, a message from a producer is broadcast to all consumers that have subscribed to a specific “topic.” Imagine a “user-signed-up” event. The producer publishes this message to a
new-userstopic. Multiple services need to react: an email service sends a welcome message, an analytics service logs the event, and a CRM service creates a new contact. All three subscribe to the topic, get their own copy of the message, and do their work independently.
Core Concepts for Building a Resilient Messaging System
Once you’ve got the basics down—producers, consumers, and brokers—it’s time to dig into the concepts that make a messaging system truly reliable. These aren’t just technical jargon; they’re the knobs and levers you’ll turn to define how your system behaves when things go wrong. Getting these right is the difference between an application that works and one that you can actually trust.
These principles have a direct, tangible impact on how your system handles everything from a brief network glitch to a full-blown server crash. Let’s break them down.
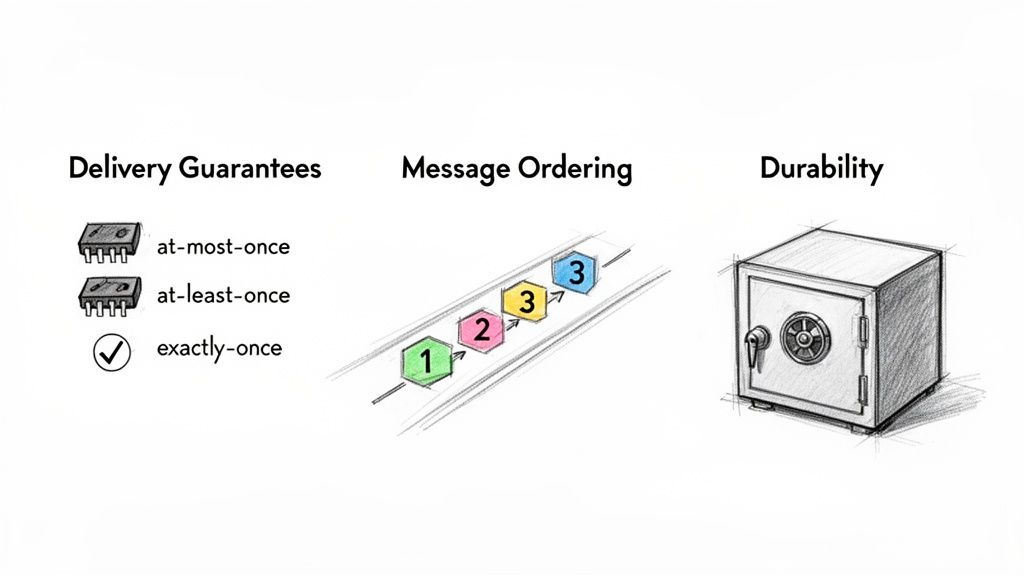
Navigating Delivery Guarantees
When a producer sends a message, how sure can it be that a consumer will actually process it? That’s the central question answered by delivery guarantees. Think of it as a contract between the broker and your applications, with three main options, each with its own trade-offs between performance and reliability.
-
At-Most-Once Delivery: This is the “fire-and-forget” model. A message is sent out, but there’s no check to see if it arrived. It’s blazing fast because there’s no overhead for acknowledgments, but it’s also the least reliable. If a consumer is down or a network issue occurs, the message is simply lost forever. This works well for non-critical data, like sending real-time analytics or logging metrics where losing a few data points isn’t a disaster.
-
At-Least-Once Delivery: Here, the system guarantees a message gets delivered at least one time, if not more. The producer or broker keeps resending the message until it gets a confirmation (an “ack”) from the consumer. This is great for preventing data loss, but it introduces a new challenge: duplicates. If a consumer processes a message but crashes before sending the ack, it will receive the same message again. To handle this, your consumers must be idempotent—designed to process the same message multiple times without causing side effects.
-
Exactly-Once Delivery: This is the holy grail of messaging. It promises that every message is delivered and processed precisely one time. No losses, no duplicates. As you can imagine, this is incredibly complex to achieve and comes with a significant performance cost, often requiring sophisticated coordination between the broker and your applications. It’s absolutely essential for critical workflows like financial transactions or e-commerce order processing, where you can’t afford any mistakes.
Choosing the right delivery guarantee is one of the most important decisions you’ll make. While exactly-once sounds perfect, the overhead is often too high. For most real-world applications, the sweet spot is at-least-once delivery paired with idempotent consumers, which provides a fantastic balance of reliability and performance.
The Importance of Message Ordering
In many systems, the sequence of events is everything. Think about a user’s lifecycle in your application: AccountCreated, SubscriptionAdded, AccountDeleted. If those events get processed out of order, you might try to delete an account before the subscription has even been registered, causing chaos.
Maintaining message order means ensuring that messages from a single producer are processed by consumers in the exact sequence they were sent. This sounds simple enough, but it gets tricky in a distributed system, especially as you add more consumers to handle a higher load.
Most message brokers only guarantee order within a specific partition or a single queue. This creates a classic trade-off: you can often get more processing power and parallelism, but at the cost of strict, global ordering.
Ensuring Durability and Persistence
What happens to your messages if the broker server suddenly reboots or crashes? If they only exist in memory, they’re gone for good. This is where durability and persistence come in to save the day.
Durability is the promise that once the broker accepts a message, it won’t be lost. The most common way to achieve this is through persistence, which means writing the message to disk.
You generally have two options for how messages are stored:
- Transient (In-Memory) Messages: Messages are kept in the broker’s RAM. This is incredibly fast, but if the broker process stops for any reason, all in-flight messages are lost.
- Persistent (On-Disk) Messages: Messages are written to a hard drive or SSD. This is slower than in-memory storage, but it ensures that messages survive broker restarts and crashes. This is the standard for any business-critical data.
By configuring your messages to be persistent, you’re building a durable system. You gain the confidence that important tasks—like a customer’s order or a payment request—are safe and will eventually be processed, even if the hardware fails. This resilience is one of the core reasons engineers turn to message queuing in the first place.
3. A Look at Popular Message Queuing Systems and Protocols
Now that we’ve got the core concepts down, let’s talk about the actual tools that make all this happen. The message queuing space is full of different systems and protocols, each built for a specific purpose. Knowing the key players is important for picking the right tool for the job, whether you’re building a massive enterprise system or connecting thousands of tiny IoT devices.
First, a quick word on protocols. Think of a protocol as the shared language that producers and consumers use to talk to the broker. It’s the set of rules ensuring everyone understands each other.
-
AMQP (Advanced Message Queuing Protocol): This is the heavyweight champion for enterprise messaging. It’s an open standard designed for reliability and interoperability, packed with features for complex routing, queuing, and security. It’s the protocol that powers brokers like RabbitMQ.
-
MQTT (Message Queuing Telemetry Transport): On the opposite end of the spectrum, MQTT is incredibly lightweight. It was built from the ground up for environments where network bandwidth and battery life are scarce, making it the go-to protocol for IoT devices and mobile apps.
These protocols lay the groundwork for the brokers themselves, each offering a different spin on asynchronous communication.
RabbitMQ: The Versatile and Mature Broker
RabbitMQ is one of the most popular and time-tested message brokers out there. It’s a powerful, multi-protocol workhorse that primarily speaks AMQP but can also handle MQTT and others through plugins. Its real superpower is its incredibly flexible and sophisticated routing logic.
RabbitMQ uses a concept called an “exchange” to direct messages to queues based on a set of rules you define. This makes it perfect for complex microservice architectures where different services need to listen for very specific types of messages. It’s a fantastic choice for traditional task queuing and running background jobs.
ActiveMQ: The Veteran in Enterprise Messaging
Apache ActiveMQ is another long-serving player, with deep roots in the Java enterprise world. It’s known for its wide-ranging support of industry standards like AMQP, MQTT, and JMS (Java Message Service), making it a solid bridge between legacy systems and modern applications.
ActiveMQ comes in two flavors: “Classic” and the newer, higher-performance “Artemis.” It truly shines in classic enterprise messaging scenarios, offering a stable and feature-rich solution that has earned the trust of countless organizations over the years.
Apache Kafka: The High-Throughput Streaming Platform
This is where things get interesting. While people often lump Apache Kafka in with message queues, it’s a completely different beast. At its core, Kafka is a distributed event streaming platform built around the idea of a permanent, replayable log.
Traditional brokers usually delete a message once it’s been processed. Kafka, on the other hand, holds onto messages for a set period, allowing different applications to read and re-read the data stream at their own pace. This unique design makes Kafka unbeatable for handling massive volumes of data in real time. It’s the undisputed king for building data pipelines, event-driven systems, and real-time analytics.
Want a deeper look into how Kafka works? We’ve got you covered in our complete guide on what is Apache Kafka.
Kafka isn’t really a task manager; it’s more like a distributed, indestructible log of everything that has ever happened in your system. This puts it in a whole different category, built for streaming data, not just offloading tasks.
Comparison of Popular Message Queuing Systems
To help you visualize the differences, here’s a quick breakdown of these powerful systems. This table highlights their core models and what they’re best at, making it easier to see where each one fits.
| System | Primary Model | Best For | Key Feature |
|---|---|---|---|
| RabbitMQ | Smart Broker / Dumb Consumer | Complex routing, microservices communication, and background jobs. | Advanced and flexible message routing via exchanges. |
| ActiveMQ | Traditional Broker | Enterprise messaging and integrating diverse or legacy systems. | Broad support for standard protocols like JMS and AMQP. |
| Apache Kafka | Dumb Broker / Smart Consumer | High-throughput data streaming, event sourcing, and real-time analytics. | A persistent, replayable, and partitioned commit log. |
As you can see, the choice between them really comes down to your specific use case—whether you need intricate routing logic, broad protocol support, or the raw power to handle massive data streams.
How Message Queues Power Modern Applications
Now that we have the mechanics down, let’s talk about where message queuing really shines. This is where theory hits the road, showing how these systems are the backbone for building software that’s resilient, scalable, and quick to respond. Message queues are the quiet workhorses behind everything from heavy background tasks to sprawling distributed systems.
These patterns aren’t just academic—they’re real-world solutions to common engineering headaches, helping businesses build better products and run smoother operations.
Processing Background Jobs Asynchronously
Think about an app that needs to do something heavy, like crunching a detailed financial report or blasting out a million marketing emails. If you make the user wait for that to finish after they click a button, your app will grind to a halt. It’s a recipe for a terrible user experience.
This is the classic scenario for background job processing. Instead of doing the work right away, the application just fires off a message—like “Generate report for User 123”—and drops it into a queue. On the other side, a dedicated set of worker services picks up these jobs and gets to work, completely separate from the main application. This keeps the user interface snappy and responsive.
Enabling Microservices Communication
These days, big applications are often built as a collection of smaller, independent services called microservices. You might have one for user logins, another for handling payments, and a third for tracking inventory. For this whole setup to work, these services need a reliable way to talk to each other.
Message queues act as the central nervous system here. When services communicate through a message broker, they don’t have to know anything about each other. The payments team can push an update or scale up their service without breaking the inventory service. This loose coupling is the secret sauce for moving fast, letting teams work independently and ship features faster.
A message queue allows each microservice to operate autonomously. If one service goes down, the others can continue to function, and messages simply wait in the queue until the failed service recovers. This design creates a far more resilient and fault-tolerant system.
This model also serves as a foundation for more complex systems. For a closer look at how solid backends are constructed for demanding applications like online games, including the architectural choices that drive scalability, check out this guide on Game Backend as a Service (BaaS).
Powering Event-Driven Architectures
Finally, message queuing is the absolute cornerstone of an event-driven architecture (EDA). In this model, services don’t make direct calls to one another. Instead, they just react to events as they happen. For example, when a customer places an order, an OrderPlaced event gets published to a topic.
From there, any interested service can listen and react in its own way, all at the same time:
- The Inventory Service sees the event and immediately decrements the stock count.
- The Shipping Service kicks off the fulfillment process.
- The Analytics Service updates the sales dashboards in real-time.
This reactive approach lets systems respond to changes instantly, which is perfect for everything from e-commerce platforms to IoT systems that need to process data from thousands of sensors. You can go much deeper on this by reading our guide on what is event-driven architecture.
The rise of these patterns is pushing the market forward in a big way. The Message Queuing as a Service (MQaaS) market is expected to grow from USD 1.41 billion in 2024 to USD 3.14 billion by 2029. This growth is heavily influenced by the adoption of microservices—now found in 85% of new apps—and the sheer volume of data coming from IoT devices.
When to Use Change Data Capture Instead of Message Queues
Message queues are fantastic tools for getting different parts of your application to talk to each other. Think of them as the perfect solution for handling application-level events—things like “send a welcome email” or “process a new payment.” They excel at decoupling the logic of your services, letting them work independently without getting in each other’s way.
But what happens when the event you care about isn’t a task, but a change happening deep inside your database? This is a totally different ballgame. You’re no longer dealing with application logic. You’re dealing with raw data events like, “a new user record was just inserted,” or “a product’s price was updated.” For that, you need a different tool.
The Critical Difference: Database vs. Application Events
Trying to use a message queue to track database changes is, frankly, an inefficient and often risky workaround. The common approach is to have your application write to the database and then publish a separate message to a queue. This pattern, known as a “dual write,” is notoriously fragile. What happens if the database write succeeds but publishing the message fails? You end up with data inconsistencies that are a nightmare to track down and fix.
This is exactly the problem Change Data Capture (CDC) was built to solve. CDC is a technology designed to capture every single change—every insert, update, and delete—as it happens, directly from the database’s own transaction log. It creates a reliable, real-time stream of everything that occurs in your data layer, completely bypassing the application logic.
Message queues manage the intent of your application (“do this task”), while CDC streams the outcome of those actions at the data level (“this record changed”). Using the right tool for the job is key to building a reliable data architecture.
This decision tree can help you quickly figure out which technology is the right fit for your needs.
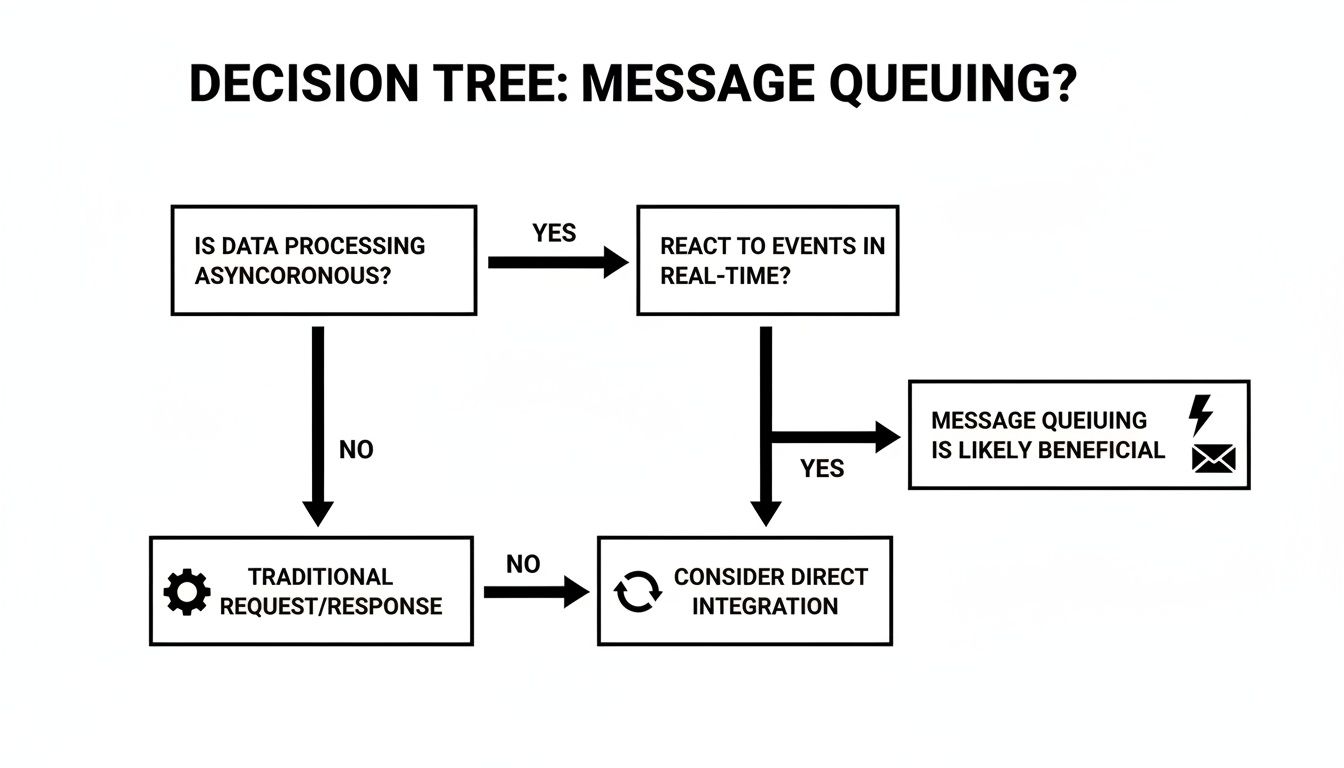
As you can see, if your goal is to process tasks or react to events your application generates, a message queue is the way to go. But if you need to mirror the state of your database, you need something more specialized.
Why CDC Is Superior for Data Movement
For streaming database changes, CDC isn’t just a different option; it’s a better one. Here’s why:
- Guaranteed Consistency: By reading directly from the database’s log, CDC ensures you never miss a change. The dual-write problem simply disappears.
- Minimal Performance Impact: It captures changes asynchronously without adding any extra load to your primary application or the database itself. Your app just does its job, and CDC handles the rest.
- Real-Time Data Replication: CDC provides a perfect, low-latency mirror of your database, which is a major advantage for real-time analytics, data warehousing, and synchronizing systems.
For a deeper dive into how this all works under the hood, check out our detailed guide on what is Change Data Capture.
When your goal is to build real-time data pipelines from a database like PostgreSQL or MySQL to a destination like Snowflake or Databricks, a managed CDC platform is the clear winner. This is where a solution like Streamkap, built on the power of Kafka and Flink, really shines. It’s a purpose-built tool for data movement that a generic message queue simply can’t match.
This push for real-time communication is driving huge growth. The global Message Queuing Service market was valued at USD 2.5 billion in 2024 and is projected to hit USD 6.8 billion by 2033. Platforms like Streamkap are at the forefront of this trend, offering managed Kafka and Flink to make real-time data movement simple and slash total ownership costs by up to 70% compared to a self-managed setup. You can explore the market trends in the full Message Queuing Service Market report from Verified Market Reports.
Common Questions About Message Queuing
As you dive into message queuing, a few common questions always seem to pop up. Let’s tackle them head-on to clear up any confusion and help you make better architectural decisions.
What’s the Difference Between a Message Queue and a Database?
Think of it this way: a message queue is like a post office for your applications, designed for temporary storage and reliable delivery. Its main job is to hold a message until a consumer is ready to process it, allowing your services to communicate without being tightly connected.
A database, on the other hand, is more like a library or an archive. It’s built for long-term, persistent storage where data is organized, indexed, and meant to be retrieved over and over again. While both store data, their purposes are worlds apart—one is for transient communication, the other is a permanent system of record.
Is Apache Kafka a Message Queue?
This is a great question, and the answer is nuanced. While you can use Apache Kafka as a message queue, it’s really a different beast altogether. It’s better described as a distributed event streaming platform.
Traditional message queues typically push messages to consumers and delete them once they’re processed. Kafka doesn’t work that way. It stores messages in a durable, append-only log, almost like a commit log for your entire system. This log can be “replayed” by different consumers, each tracking its own position in the stream. This fundamental difference makes it perfect for building data pipelines and real-time processing systems, which is a much broader scope than just simple task queuing.
Kafka’s log-based architecture shifts the model from a temporary task inbox to a durable, replayable record of events. This is a key distinction when evaluating what message queuing is for high-volume data streaming.
How Do I Choose the Right Message Queuing System?
There’s no single “best” system—the right choice always comes down to what you’re trying to build. Your specific needs around performance, data guarantees, and architectural patterns will point you to the right tool for the job.
Here’s a quick mental checklist to get you started:
- For complex routing and background jobs, especially in a classic microservices setup, a battle-tested broker like RabbitMQ is often an excellent choice. It’s flexible and feature-rich.
- For high-throughput, fault-tolerant event streaming and building real-time analytics pipelines, Apache Kafka is the undisputed leader. It’s built for massive scale.
- For lightweight messaging in IoT or mobile environments where network bandwidth and device power are limited, an MQTT-based broker like Mosquitto is usually the way to go.
Ready to move beyond application messaging and build real-time data pipelines from your database? Streamkap offers a managed Kafka and Flink solution, simplifying Change Data Capture (CDC) to stream data to destinations like Snowflake and Databricks with zero operational overhead. Learn more at https://streamkap.com.