A Practical Guide to Building Your First ETL Data Pipeline
Build a robust ETL data pipeline from the ground up. This guide covers architecture, tools, and modern strategies for real-time data integration.
An ETL data pipeline is a set of automated steps that pull data from various sources, reshape it into a consistent format, and then load it into a destination, usually a data warehouse. Think of it as the plumbing for your company’s information. It ensures that raw, often messy, data from all over the business becomes a clean, reliable asset you can actually use to make decisions.
What Is an ETL Data Pipeline and Why Does It Matter?
Let’s use an analogy. Imagine your business is a gourmet restaurant and your data points are the raw ingredients. An ETL pipeline is your entire kitchen operation. It sources ingredients from different suppliers (databases, apps, APIs), preps them by washing, chopping, and measuring (transformation), and then neatly organizes everything in the pantry (your data warehouse). This way, the chef (your analyst or data scientist) can easily grab what they need to cook up incredible insights.
This process is the bedrock of modern business intelligence. Without it, your data is just stuck in silos—your CRM has customer info, your marketing platform has campaign stats, your sales software has deal data. Each system holds a piece of the puzzle. An ETL pipeline is what brings all those pieces together to give you the full picture, creating a single source of truth.
For a deeper dive, you can check out our detailed guide on what an ETL pipeline is and how it functions.
The Three Core Stages of an ETL Pipeline
At its heart, an ETL pipeline is designed to get raw data ready for analysis. This is about far more than just copying files. The magic really happens in the “transform” step, where the data is cleaned, validated, and restructured for a specific purpose.
The table below breaks down the three essential stages of any ETL pipeline, outlining what each one does and the common hurdles teams face.
| Stage | Primary Function | Common Challenges |
|---|---|---|
| Extract | Pulls raw data from multiple sources like databases (e.g., PostgreSQL, MySQL), SaaS apps (e.g., Salesforce), and logs. | Handling different data formats (JSON, CSV, etc.), managing API rate limits, and dealing with inconsistent source schemas. |
| Transform | Cleanses, standardizes, and enriches the data. This includes removing duplicates, converting data types, and joining datasets. | Ensuring data quality and consistency, complex business logic, and handling large volumes of data efficiently. |
| Load | Delivers the processed, analytics-ready data to a target system, such as a cloud data warehouse (e.g., Snowflake, BigQuery). | Managing schema changes in the destination, ensuring transactional integrity, and optimizing load performance for speed. |
Ultimately, a well-designed pipeline makes data consolidation, quality improvement, and confident decision-making possible.
Why ETL Is More Important Than Ever
The need for smart data integration is absolutely booming. The ETL data pipeline market was valued at $8.85 billion in 2025 and is on track to hit $18.60 billion by 2030. What’s driving this? A massive explosion in data from everywhere—IoT sensors, social media, and countless business applications.
An effective ETL pipeline turns data chaos into clarity. It’s the foundational layer that transforms scattered, messy information into the clean, structured fuel required for meaningful business intelligence and advanced analytics. Without it, you’re navigating with an incomplete map.
Designing a Resilient ETL Pipeline Architecture
Alright, let’s move past the theory and get our hands dirty with the actual blueprint of a modern ETL pipeline. A truly resilient architecture isn’t just a diagram on a whiteboard; it’s a living system where every piece works together to move data reliably and efficiently from point A to point B. This structure is what turns a messy collection of data points into a powerful asset for your analysts.
The journey always starts at the data sources. Think of all the places your information lives: the transactional databases like PostgreSQL or MySQL that run your apps, third-party SaaS platforms like Salesforce, or even simple CSV files sitting on an FTP server. The first hurdle is just tapping into these disparate systems, each with its own API, data format, and access quirks.
This diagram lays out the fundamental journey data takes in a classic ETL workflow.
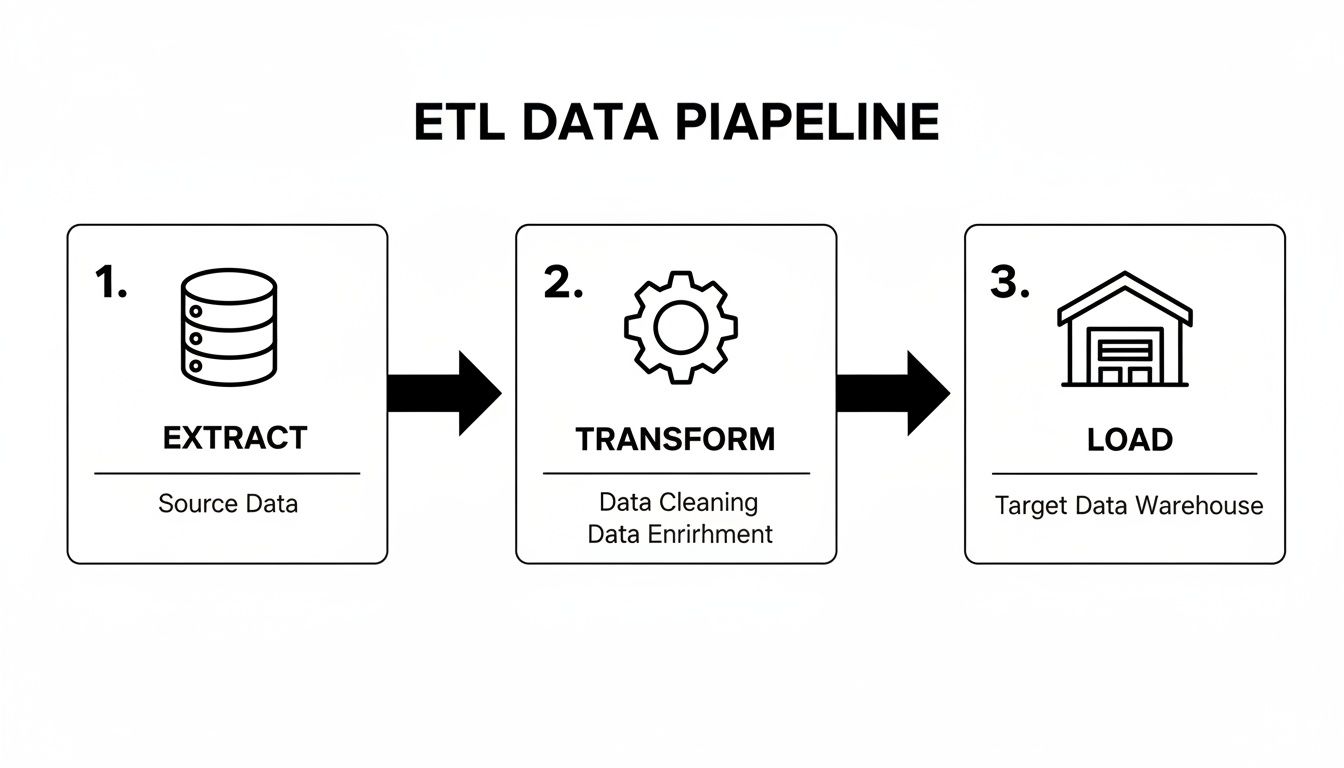
As you can see, it’s a straightforward path: pull the raw data out, apply your business rules and logic to clean it up, and then load the finished product into a warehouse where it can be analyzed.
The Core Components of Your Pipeline
After you’ve extracted the data, it lands in a staging area. I like to think of this as a chef’s prep station. It’s a temporary holding spot—often just a simple database or a cloud storage bucket—where raw data sits before you start making changes. This separation is key because it shields your original source systems from the heavy lifting of the transformation process.
Next up is the transformation engine, which is really the brains of the whole operation. This is where you clean, validate, standardize, and enrich the raw data. Transformations can be as simple as fixing date formats or as complex as joining a dozen different datasets to build that coveted 360-degree customer view. The performance of this engine has a direct impact on the speed and scalability of your entire pipeline.
Finally, the polished data reaches its destination. Most of the time, this will be a cloud data warehouse like Snowflake or Google BigQuery, which are built for lightning-fast analytical queries. But it could also be a data lake for storing massive volumes of structured and unstructured data, or even another operational application that needs the enriched information.
Choosing Your Architectural Pattern
Not all ETL pipelines are created equal. The architectural pattern you land on will depend entirely on your needs for data freshness, volume, and, of course, cost. Two of the most common patterns you’ll run into are traditional batch and micro-batch processing.
- Traditional Batch Processing: This is the old-school, tried-and-true method. Data is gathered and processed in big chunks on a fixed schedule—think nightly or hourly. It’s incredibly efficient for huge volumes and often the most budget-friendly option for analytics that don’t need to be up-to-the-minute.
- Micro-Batch Processing: This approach carves up the work into smaller, more frequent batches, maybe every five minutes. It’s a nice middle ground, giving you fresher data than traditional batching without jumping into the full complexity of real-time streaming.
The dominance of these patterns is undeniable. ETL commands a massive 39.46% share of the data pipeline tools market, which itself was valued at $12.09 billion and is on track to hit a staggering $48.33 billion by 2030. A lot of that growth is being fueled by the need to handle streaming data from IoT devices and other real-time sources, where automated ETL is a must.
A robust architecture always plans for failure. By separating components like the staging area and the transformation engine, you build a system that’s far easier to debug, maintain, and scale. A hiccup in one part doesn’t have to grind the entire data flow to a halt.
To make sure your pipeline design holds up in the real world, you absolutely need to incorporate effective project management practices from day one. This discipline is what helps you wrangle the complexity, get all your stakeholders on the same page, and actually deliver a resilient system on time. Picking the right architectural pattern is your first major step toward building a pipeline that works not just today, but for the long haul.
Choosing the Right Tools for Your ETL Pipeline
Picking the right tools for your ETL data pipeline can feel like you’re staring at a map with a thousand different roads. The market is absolutely flooded with options, and every single one claims it will solve all your data headaches. But here’s the secret: there is no single “best” tool. The only thing that matters is finding the best tool for your specific situation—your team’s skills, your budget, and how much you expect your data needs to grow.
Get this choice wrong, and you could be looking at months of frustration, a blown budget, and a pipeline that creates more problems than it solves. To cut through the noise, we can group the options into three main categories: open-source solutions, commercial platforms, and cloud-based services. Each one comes with its own set of strategic trade-offs.
Open-Source ETL Tools
Open-source tools give you the ultimate in flexibility and control. Think of it like a professional chef’s kitchen, stocked with every imaginable gadget and ingredient. You have total freedom to build a completely custom workflow that’s perfectly tailored to your unique data recipes.
Tools like Apache Airflow, Talend Open Studio, and the Singer specification are heavy hitters in this space. They’re free to use, which is a huge draw for companies that already have a strong in-house engineering team. If you’re dealing with weird transformation logic or need to connect to an obscure data source, the ability to write your own code is a game-changer.
Of course, that freedom isn’t exactly free.
- High Technical Overhead: You’re on the hook for everything. That means setup, hosting, maintenance, security updates, and figuring out how to scale the infrastructure yourself.
- Steeper Learning Curve: These aren’t point-and-click tools. They demand real technical chops, often in languages like Python, plus a solid grasp of data engineering fundamentals.
- No Dedicated Support: When something inevitably breaks at 2 AM, it’s up to your team to dig through community forums and documentation to find a fix.
This path makes the most sense when you have a skilled engineering team ready to invest the time and your needs are so specific that an off-the-shelf tool just won’t do the job.
Commercial ETL Platforms
Commercial platforms are the all-inclusive resorts of the data world. They package everything you need into a single, polished solution with powerful features, enterprise-level security, and a support team you can actually call.
Industry veterans like Informatica PowerCenter and IBM DataStage have been staples in this arena for years. These platforms are built for the complexities of large-scale enterprises where things like data governance, compliance, and rock-solid reliability are non-negotiable. They often feature graphical user interfaces (GUIs), which can empower less-technical users to build and manage pipelines, speeding up development.
The real value of a commercial platform is often the support and reliability. When you’re dealing with data that’s critical to your business, having an expert on the phone who can help you solve a problem in the middle of the night is worth its weight in gold.
The big things to watch out for here are the price tag and the risk of vendor lock-in. Licensing fees can be hefty, and because these platforms are so specialized, moving to a different solution later on can be a massive undertaking. They’re a great fit for large organizations with deep pockets and strict regulatory demands.
Cloud-Based ETL Services
Cloud-based services are the modern, pay-as-you-go answer to ETL. These are fully managed platforms that take care of all the messy infrastructure behind the scenes, letting your team focus on what actually matters: the data logic. It’s like a meal-kit delivery service—you pick the recipe, and all the pre-portioned ingredients show up at your door, saving you the trip to the store.
Services like AWS Glue, Google Cloud Dataflow, and modern data movers like Fivetran or Integrate.io live in this category. Their biggest selling point is how fast you can get up and running. You can often connect your sources and destinations and start moving data in minutes, not months.
- Managed Infrastructure: Forget about servers, scaling, or maintenance. The cloud provider handles all of that for you.
- Usage-Based Pricing: You only pay for the data you process or the compute you use, which makes it incredibly cost-effective for startups and growing businesses.
- Pre-Built Connectors: These services come with huge libraries of connectors for popular SaaS apps and databases, which dramatically cuts down on development time.
The trade-off? You usually give up some of the deep customization you’d get with an open-source tool. While they handle the vast majority of common use cases with ease, you might hit a wall if you have highly specialized transformation needs. This category is perfect for teams that value speed and efficiency and would rather not get bogged down in managing infrastructure.
To help you see how these categories stack up, here’s a quick comparison of what you can expect from each.
Comparison of ETL Tool Categories
| Tool Category | Best For | Key Advantages | Key Considerations |
|---|---|---|---|
| Open-Source | Teams with strong engineering skills and highly custom requirements. | Total control and flexibility; no licensing fees; strong community support. | High setup and maintenance overhead; requires deep technical expertise; no dedicated vendor support. |
| Commercial | Large enterprises with complex data governance and compliance needs. | Enterprise-grade reliability; dedicated support; robust security and governance features. | High licensing costs; potential for vendor lock-in; can be less agile than other options. |
| Cloud-Based | Teams that prioritize speed, ease of use, and minimal infrastructure management. | Fast time-to-value; pay-as-you-go pricing; managed infrastructure; large connector libraries. | Less customizable than open-source; costs can scale unexpectedly with high volume. |
Ultimately, the right tool is the one that aligns with your team’s capabilities, budget, and long-term data strategy. Each approach has its place, and understanding these trade-offs is the first step toward building a pipeline that truly works for you.
Optimizing Pipeline Performance and Efficiency
A poorly optimized ETL pipeline is a lot like a traffic jam on your data highway. It doesn’t just slow down insights; it burns through resources, inflates your cloud bills, and can even bring source systems to a crawl. Building a pipeline that’s both fast and cost-effective isn’t a “set it and forget it” task—it demands constant attention and a clear-eyed view of all the costs involved.
Simply moving data isn’t the real goal. You want a system that’s lean, efficient, and ready to scale. This means digging deeper than basic extraction and loading to focus on the techniques that make your pipeline truly robust under pressure. A slow or expensive pipeline completely undermines your data strategy, turning a powerful asset into a frustrating bottleneck.
Strategies for High-Performance Pipelines
To keep data flowing smoothly, engineers have a few key tricks up their sleeves. These strategies are all about reducing processing time, minimizing the load on source databases, and making the final data much easier for analysts to query.
- Parallel Processing: Instead of tackling a massive dataset as one single job, you can break the work into smaller, independent chunks that run at the same time. This is a game-changer for the ‘Transform’ stage, dramatically cutting down the total run time for large-volume ETL jobs.
- Incremental Loading: Why reload an entire dataset every single time? With incremental loading (sometimes called delta loading), you only process records that are new or have changed since the last run. This massively reduces the strain on source systems and shrinks the data volume, leading to much faster and cheaper runs.
- Data Partitioning: When loading data into your warehouse, you can physically organize it into smaller segments, or partitions, often based on something like a date or category. When someone queries that data, the system only has to scan the relevant partitions instead of the entire table, leading to dramatically faster query performance.
Understanding Total Cost of Ownership
The sticker price of an ETL tool is just the tip of the iceberg. The Total Cost of Ownership (TCO) gives you a much more realistic picture of what your pipeline will actually cost over its lifetime. Forgetting to account for these hidden expenses is a classic recipe for budget overruns.
A pipeline’s true cost isn’t just the software license. It’s a combination of compute resources, developer hours spent on maintenance, and the business cost of downtime or slow data. Optimizing for TCO means finding the right balance between speed and expenditure.
To figure out your true TCO, you need to look at:
- Infrastructure Costs: The compute and storage your pipeline eats up, which can balloon as your data volume grows.
- Development and Maintenance: The engineering hours needed to build, monitor, troubleshoot, and update the pipeline. This is often the single largest ongoing expense.
- Licensing Fees: The direct cost of any commercial software or managed services you’re paying for.
Continuously monitoring and tweaking your system is a core part of effective data management. For more on this, check out these essential data engineering best practices. By actively hunting down and eliminating bottlenecks, you can make sure your ETL pipeline delivers maximum value without breaking the bank.
From Batch Processing to Real-Time Streaming
In a world where business decisions happen in moments, waiting hours for the next data update is a huge competitive disadvantage. The traditional ETL data pipeline, built on batch processing, was designed for a different era—one where nightly reports were good enough. Today, that delay creates a frustrating gap between an event happening and the business actually knowing about it.
This built-in lag means insights are often stale by the time they reach the people who need them. Imagine an e-commerce platform that only updates inventory once a day. A popular item could sell out by 10 AM, but the website keeps taking orders all afternoon, leading to a mess of angry customers and operational chaos. That’s the core problem with batch processing.
On top of that, these big, scheduled batch jobs can absolutely hammer your source systems. Running a massive data query on your main operational database during peak hours can slow down the very apps your customers and employees are trying to use.
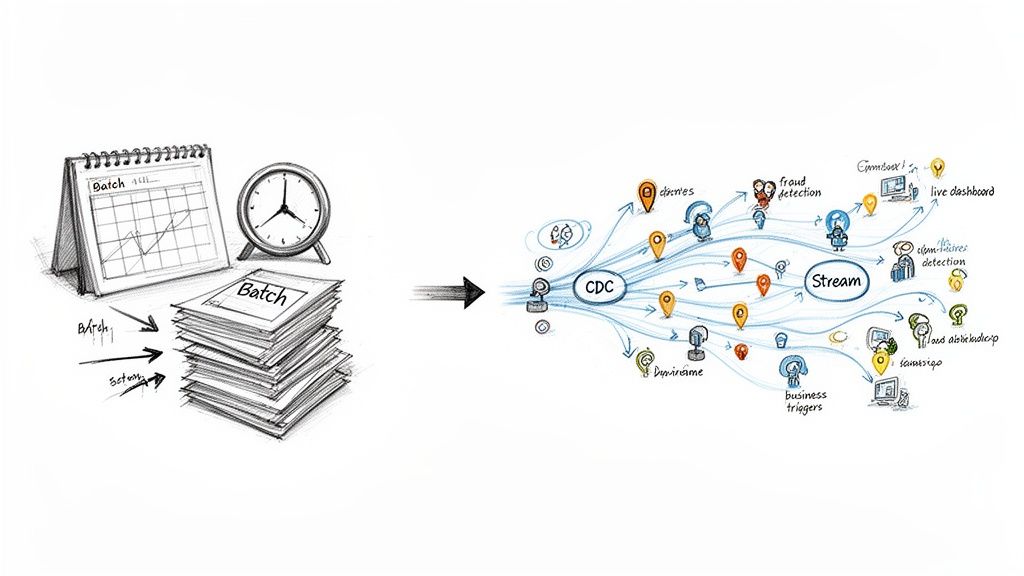
This diagram really shows the shift from pulling big chunks of data every so often to a continuous, low-latency flow that lets you act on events the second they happen.
The Rise of Change Data Capture
The answer to these problems is a much smarter way of getting data called Change Data Capture (CDC). Instead of grabbing entire tables on a schedule, CDC taps directly into the database’s transaction log—basically, a running list of every single change (insert, update, or delete) that happens.
Here’s a simple way to think about it: batch processing is like taking a full census of a city every single night just to see what’s different. CDC, on the other hand, is like having a live news feed that instantly reports every birth, every move, and every departure right as it occurs. It’s just a much more efficient and timely way to do things.
By capturing only the changes, CDC dramatically reduces the load on source systems and enables a continuous, low-latency stream of data. This technology is the cornerstone of the modern, real-time ETL data pipeline, closing the gap between event and insight from hours to milliseconds.
This shift allows businesses to react to events almost instantly, opening up a whole new world of powerful capabilities. Usually, the reasons for switching from batch to streaming are pretty clear and compelling.
When to Make the Move to Real-Time Streaming
The decision to move away from a traditional batch ETL pipeline to a real-time streaming model is almost always driven by business needs where the cost of stale data is just too high. If your operations rely on immediate information, streaming is no longer a “nice-to-have”—it’s a necessity.
Here are some common triggers:
- Instant Fraud Detection: Financial companies need to analyze transactions in milliseconds to block fraud before the transaction even completes.
- Real-Time Inventory Management: Retailers and logistics companies can keep perfectly accurate stock levels across all their channels, preventing overselling and making the supply chain run smoothly.
- Live Operational Dashboards: Teams can watch application performance, user activity, and system health with up-to-the-second data, letting them jump on issues right away.
- Personalized Customer Experiences: E-commerce sites can serve up dynamic recommendations and offers based on what a user is doing on the site right now, which can massively boost engagement and sales.
Simplifying the Transition with a Managed Platform
Let’s be honest, adopting real-time streaming with CDC can get complicated. It often requires deep expertise in managing distributed systems like Apache Kafka for moving data and stream processors like Apache Flink for transforming it on the fly. This is where a managed streaming platform like Streamkap really shines.
Streamkap handles all that complexity for you, giving you a zero-ops way to build a real-time ETL data pipeline. It uses powerful, open-source tech under the hood but wraps it in a user-friendly interface with things like automated schema handling and pre-built connectors. This lets your data team focus on creating business value instead of wrestling with infrastructure. For a deeper look at the trade-offs, our guide on stream processing vs batch processing breaks it all down.
By moving to a real-time model, you turn your data from a historical record into a live, actionable asset that makes your entire operation more responsive, intelligent, and competitive.
Building a Bulletproof Monitoring and Testing Strategy
An unmonitored ETL pipeline is a time bomb. It might look like it’s running just fine, but silent failures like data corruption or a slow, creeping performance decline can go unnoticed for weeks. By the time you find out, you’re dealing with flawed business intelligence and a serious loss of trust in your data.
A solid monitoring and testing strategy is what turns your pipeline from a black box into a transparent, reliable system. Think of it as mission control for your data operations. Without it, you’re flying blind and only find out something’s wrong when a critical report breaks or an executive starts questioning the numbers.

Core Pillars of Pipeline Monitoring
To get a complete picture, you need to track a few key metrics. These are your pipeline’s vital signs, giving you a real-time health check on your entire data flow.
- Data Throughput and Volume: Keep an eye on how much data is being processed over time. Sudden spikes or drops are often the first sign of trouble, whether it’s an issue with a source system or a bottleneck in your pipeline.
- Job Success and Failure Rates: This is straightforward but critical. You need to track the percentage of ETL jobs that run successfully versus those that fail. A rising failure rate is a massive red flag that needs immediate attention.
- Latency: Measure how long it takes for data to get from point A to point B. If latency starts to climb, your data is getting stale, which completely undermines the point of near-real-time analytics.
Metrics tell you what happened, but structured logging tells you the story behind the numbers. Good logs give you a detailed, step-by-step account of the pipeline’s execution, making it infinitely easier to debug a failure. Pair this with a smart alerting system, and you can notify the right people the moment a metric crosses a critical threshold—long before your users even notice.
A great monitoring setup tells you a job failed. An elite setup tells you why it failed and alerts the on-call engineer with a link to the exact log entry, all within 60 seconds of the event.
Implementing a Rigorous Testing Framework
Monitoring tells you what’s happening right now; testing ensures your pipeline will work as expected tomorrow and after every new code change. You really need a multi-layered testing strategy to catch bugs before they ever touch production data.
- Unit Tests: These are your first line of defense. They are small, laser-focused tests that validate a single piece of transformation logic, like checking if a function correctly formats a date or calculates a metric. They catch simple logic errors early.
- Integration Tests: This is where you check if the different parts of your pipeline can talk to each other. An integration test might verify that your extraction script can actually connect to the source database and pull data into your staging area.
- End-to-End Tests: This is the final dress rehearsal. An end-to-end test runs a small, controlled sample of data through the entire pipeline, from extraction all the way to loading, to confirm the whole system works together as one cohesive unit.
To truly harden your pipelines against threats, pursuing a certified cyber security professional course provides essential knowledge in data protection. When a pipeline is not only well-monitored and tested but also secure, you create a system the business can truly rely on.
Answering Your Top ETL Data Pipeline Questions
As you get deeper into data integration, a lot of questions naturally pop up. Let’s tackle some of the most common ones that teams run into when they’re building and maintaining their ETL pipelines.
What’s the Real Difference Between ETL and ELT?
The biggest difference boils down to one simple thing: when you transform the data.
With a classic ETL (Extract, Transform, Load) pipeline, you do all the cleaning, reshaping, and business logic before the data ever lands in its final destination, like a data warehouse.
On the other hand, ELT (Extract, Load, Transform) flips the script. You dump the raw, untouched data directly into a powerful cloud data warehouse first. All the transformation work then happens right inside the warehouse, taking advantage of its massive computing power. This ELT approach has become hugely popular with modern platforms like Snowflake because it gives data analysts the freedom to work with the original raw data whenever they need it.
How Do I Pick the Right ETL Tool for My Team?
There’s no single “best” tool, but you can find the right fit by looking at four key things: how much data you have (and how messy it is), your team’s technical chops, your budget, and how much you expect to grow.
- Managed cloud tools: These are often your best bet for smaller teams or projects where you just need to get moving fast. They handle all the infrastructure for you.
- Open-source solutions: If you have a strong engineering team and very specific needs, open-source gives you total control and flexibility.
- Commercial platforms: Big companies with strict security and governance rules usually lean this way. You get a robust, feature-rich tool with dedicated vendor support.
A bit of advice: Always figure out the business problem you’re trying to solve first. Only then should you go looking for a tool. This keeps you focused on results, not just a list of shiny features.
When Is It Time to Switch From Batch to Streaming ETL?
You’ll know it’s time to switch when the cost of using old data becomes too high. Think about it: if you’re working in fraud detection, managing a live inventory system, or personalizing customer experiences on the fly, you need data that’s seconds old, not hours. Batch processing just can’t keep up.
Another tell-tale sign is when your team starts spending more time fixing broken hourly batch jobs than they do building new things. That’s a huge red flag. It means your current process is holding you back, and it’s time to look at a real-time streaming approach, often powered by Change Data Capture (CDC), to meet the pace of your business.
Ready to leave slow batch jobs behind and get real-time insights? Streamkap makes the move to streaming ETL incredibly simple with a zero-ops, fully managed platform. You can build your first real-time pipeline in minutes.
Related resources
Batch-to-Streaming Migration Playbook: Parallel Running and Output Validation
A practical guide to migrating batch ETL jobs to streaming pipelines, covering prioritization frameworks, parallel-run architectures, output validation techniques, and safe cutover mechanics.
Real-Time Data Pipelines for AI Agents: Architecture, Patterns, and Implementation Guide
A practical guide to building real-time data pipelines that feed AI agents with fresh context. Covers architecture patterns, streaming transforms, and step-by-step implementation.
The Startup Guide to AI Agents: Ship Your First Real-Time Agent in a Weekend
A step-by-step guide for startup teams to build their first AI agent powered by real-time streaming data. Go from zero to a working agent in a weekend.